
문제
이전에 풀었던 문제와 거의 동일하다. 접두사 검색이 존재하지 않는 대신 검색어에 .으로 와일드카드가 사용될 수 있다. 문제는 문자열 삽입과 검색하는 함수를 구현하면 된다.
첫번째 풀이
삽입 함수는 이전 문제와 동일하게 구현했다.
문제는 검색어에 와일드 카드가 존재하는 검색 함수 구현이다. 처음에는 와일드 카드가 존재하므로 여러 갈래로의 탐색을 위해 child를 Map으로 사용해야 한다고 생각했다.
Map.values()를 사용해 해당 노드에 존재하는 모든 자식 노드를 가져올 수 있기 때문에
또한, 재귀(DFS) 방식으로 구현하는게 구현시에 편리할 것이라 생각해 재귀로 구현하였다.
와일드 카드에 대한 구현 방법은 기존 검색인 경우 다음 검색 문자가 정해져있어 해당 노드만 탐색하면 되지만 .인 경우 어떤 문자든지 올 수 있으므로 현재 노드의 모든 자식 노드를 탐색하며 or 연산을 사용해 하나라도 존재하는 경우가 발생하면 함수를 종료하도록 하였다.
class WordDictionary {
private Node root;
public WordDictionary() {
root = new Node();
}
public void addWord(String word) {
Node current = this.root;
for (char ch : word.toCharArray()) {
Node child = current.getChild(ch);
if (child == null) {
child = new Node();
current.addChild(ch, child);
}
current = child;
}
current.endOfWord();
}
public boolean search(String word) {
return search(this.root, word, 0);
}
private boolean search(Node current, String word, int idx) {
if (current == null) {
return false;
}
if (idx == word.length()) {
return current.isEndOfWord();
}
char ch = word.charAt(idx);
if (ch == '.') {
boolean ret = false;
for (Node child : current.getChilds()) {
ret |= search(child, word, idx + 1);
if (ret) {
break;
}
}
return ret;
} else return search(current.getChild(ch), word, idx + 1);
}
private class Node {
private Map<Character, Node> child = new HashMap<>();
private boolean isEndOfWord;
public void addChild(char key, Node child) {
this.child.put(key, child);
}
public Node getChild(char key) {
return child.get(key);
}
public List<Node> getChilds() {
return new ArrayList<>(child.values());
}
public void endOfWord() {
this.isEndOfWord = true;
}
public boolean isEndOfWord() {
return this.isEndOfWord;
}
}
}
결과는 실행시간과 메모리 사용량 모두 하위권으로 나왔다.
두번째 풀이
첫번째 풀이에서 실행시간이 낮게 나온 이유로 Node의 child에 Map을 사용했기 때문이라고 생각한다. 아무래도 접근이 배열보다 느리기 때문이다. 또한 getChilds()에서 child의 values로 새로운 리스트를 만드는 과정이 포함된 것도 영향이 있다고 생각하며 이 연산은 메모리의 사용량에도 영향을 미칠 수 있다.
이 두 문제를 개선하기 위해 Node의 child를 배열로 선언했다. 처음부터 배열로 선언하지 않은 이유는 검색 문자가 .인 경우 모든 자식 노드를 탐색해야하는데 이 과정에서 배열은 모든 인덱스를 접근해보아야하기 때문이었다.
하지만 이 문제 역시 소문자 알파벳으로 제한되어있어 길이가 26인 배열로 많은 영향을 미치지 않을 것이라 생각해 배열로 개선하게 되었다. 배열로 개선한 결과는
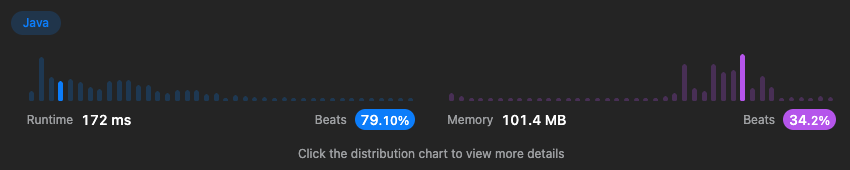
282ms → 172ms로 많이 줄었으며 메모리 또한 약 10MB 이상 줄였다. 하지만 메모리 사용량은 아직 하위권이다.
개선한 코드는 다음과 같다.
class WordDictionary {
private Node root;
public WordDictionary() {
root = new Node();
}
public void addWord(String word) {
// 첫번째 풀이와 동일
}
public boolean search(String word) {
return search(this.root, word, 0);
}
private boolean search(Node current, String word, int idx) {
if (current == null) {
return false;
}
if (idx == word.length()) {
return current.isEndOfWord();
}
char ch = word.charAt(idx);
if (ch == '.') {
boolean ret = false;
for (Node child : current.getChilds()) {
ret |= search(child, word, idx + 1);
if (ret) {
break;
}
}
return ret;
} else return search(current.getChild(ch), word, idx + 1);
}
private class Node {
private Node[] child = new Node[26];
private boolean isEndOfWord;
public void addChild(char key, Node child) {
this.child[key - 'a'] = child;
}
public Node getChild(char key) {
return this.child[key - 'a'];
}
public Node[] getChilds() {
return child;
}
public void endOfWord() {
this.isEndOfWord = true;
}
public boolean isEndOfWord() {
return this.isEndOfWord;
}
}
}세번째 풀이
여전히 메모리 사용량이 많은 이유는 재귀로 풀었기 때문에 스택에 함수가 많이 쌓이기 때문이라고 생각했다. 따라서 이를 개선하기 위해 재귀를 사용하지 않고 너비 우선 탐색을 활용해 풀이해봤다.
너비 우선 탐색을 사용해 문제를 풀이 했을 때 결과는 메모리 사용량이 두번째 풀이보다 약 15MB가 줄어든 약 86MB가 나왔다. 메모리 사용량만 놓고 보면 상위권에 속한다. 하지만 실행시간이 247ms로 두번째 풀이보다 두 배 이상 더 느리게 측정되었다.

너비 우선 탐색으로 풀이한 코드는 다음과 같다.
class WordDictionary {
private Node root;
public WordDictionary() {
root = new Node();
}
public void addWord(String word) {
// 첫번째 풀이와 동일
}
public boolean search(String word) {
Queue<Node> queue = new ArrayDeque<>();
queue.add(this.root);
int wordIdx = 0;
while (!queue.isEmpty()) {
int queueSize = queue.size();
if (wordIdx == word.length()) {
boolean ret = false;
while (!queue.isEmpty() && !ret) {
ret |= queue.poll().isEndOfWord();
}
return ret;
}
char ch = word.charAt(wordIdx++);
while (queueSize-- > 0) {
Node current = queue.poll();
if (ch == '.') {
for (Node child : current.getChilds()) {
if (child != null) {
queue.add(child);
}
}
} else {
Node child = current.getChild(ch);
if (child != null) {
queue.add(child);
}
}
}
}
return false;
}
private boolean search(Node current, String word, int idx) {
if (current == null) {
return false;
}
if (idx == word.length()) {
return current.isEndOfWord();
}
char ch = word.charAt(idx);
if (ch == '.') {
boolean ret = false;
for (Node child : current.getChilds()) {
ret |= search(child, word, idx + 1);
if (ret) {
break;
}
}
return ret;
} else return search(current.getChild(ch), word, idx + 1);
}
private class Node {
// 두번째 풀이와 동일
}
}