문제
문자열 s가 주어졌을 때 중복이 없는 문자열 중 가장 긴 문자열의 길이를 찾는 문제이다.
첫번째 풀이
지나번에 풀었던 Minimum Size Subarray Sum와 비슷해 sliding window로 해결하였다.
문자가 반복된 횟수를 카운팅하면서 현재까지의 substring이 중복이 없는 문자열이면 right를 증가시켜 문자열의 길이를 늘린다. 반대로 중복이 포함된 문자열이면 중복이 없는 문자열이 될 때까지 left를 증가시키며 문자열을 줄인다.
여기서 고민은 반복된 횟수를 카운팅하기위해 어떤 방법을 사용할 것인가였다. 알파벳(대문자, 소문자를 구분하는지 명확하지 않았다.)을 포함한 숫자, 공백, 심볼 등이 포함된 문자열이기 때문이다.
나는 Set, Map과 같은 자료구조의 사용을 고려도 해봤지만 입력 문자들이 ASCII 문자임을 가정하고 반복 횟수 배열(repeat)을 128길이(ASCII는 0~127번까지 존재)의 int형 배열로 선언하였다. 그리고 문자의 ASCII 코드의 10진수 값을 repeat 배열의 인덱스로 사용해 반복 횟수를 관리하였다.
class Solution {
public int lengthOfLongestSubstring(String s) {
int len = s.length();
if (len == 0) {
return 0;
}
int[] repeat = new int[128];
int left = 0, right = 0;
repeat[s.charAt(left)]++;
int answer = 0;
while (left != len || right != len) {
if (isAvailable(s, repeat, left, right)) {
answer = Math.max(answer, right - left + 1);
if (right == len - 1) {
break;
}
repeat[s.charAt(++right)]++;
} else {
repeat[s.charAt(left++)]--;
}
}
return answer;
}
private boolean isAvailable(String s, int[] repeat, int left, int right) {
for (int i = left; i <= right; i++) {
int val = s.charAt(i);
if (repeat[val] > 1) {
return false;
}
}
return true;
}
}시간복잡도는 이며 공간복잡도는 이다.
두번째 풀이
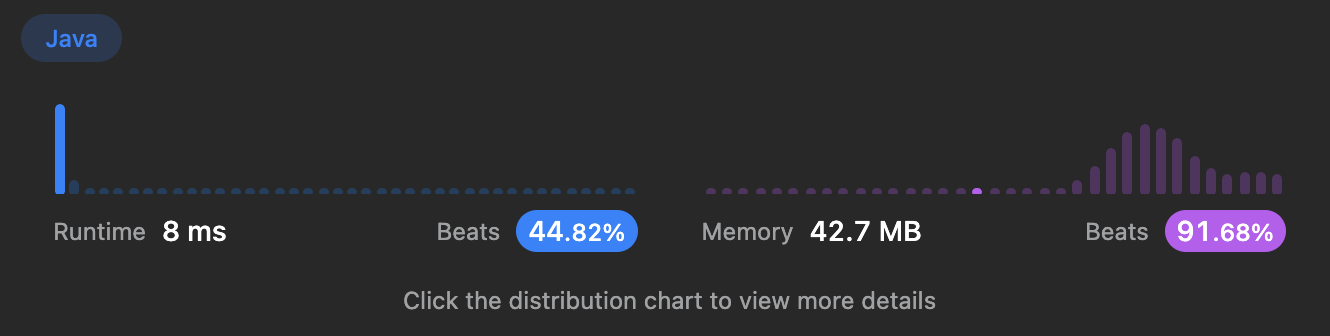
첫번째 풀이에서 결과가 8ms로 다른 사람들에 비해 낮게 나왔다. 이유는 isAvaliable() 함수라고 생각했다. left부터 right까지 탐색하며 중복이 없는 문자열인지 검사하는 과정을 매 반복마다 수행하기 때문이다.
두번째 풀이는 이 중복이 없는 문자열인지 검사하는 함수를 없앤 풀이이다. 없앨 수 있었던 것은 repeat이 변하는 순간은 문자를 넣고 뺄때가 유일하기 때문이다. 문자열을 늘릴 때 새로 들어오는 문자가 중복되지 않았을 때 문자열을 늘리도록 하면 항상 중복이 없는 문자열로 유지할 수 있다.
반대로 새로 들어오는 문자가 중복된 문자라면 이 중복된 문자가 빠질때까지 left를 증가시켜 문자열의 길이를 감소시킨다. 그 후 새로운 문자를 넣어 문자열을 늘리는 방식으로 답을 구할 수 있게 된다.
class Solution {
public int lengthOfLongestSubstring(String s) {
int len = s.length();
if (len <= 1) {
return len;
}
int[] repeat = new int[128];
int left = 0, right = 0;
repeat[s.charAt(left)]++;
int answer = 0;
while (true) {
if (right == len - 1) {
break;
}
if (right < len - 1 && repeat[s.charAt(right + 1)] == 0) {
repeat[s.charAt(++right)]++;
answer = Math.max(answer, right - left + 1);
} else {
repeat[s.charAt(left++)]--;
}
}
return answer;
}
}이 풀이도 첫번째 풀이와 마찬가지로 시간복잡도는 이며 공간복잡도는 이지만 중복이 없는 문자열인지 판별하는 함수(isAvailable())를 없애 기존 8ms에서 2ms까지 실행시간을 줄일 수 있었다.
몰랐던 풀이..
Solution에 메모리를 더 사용하지 않으면서 더 간단한 풀이가 존재했다. 느낌은 첫번째 풀이 + 두번째 풀이를 섞은 느낌이다.
String의 indexOf() 함수를 사용하는 방법으로 index(s.charAt(right), left)를 실행해 left 인덱스부터 시작해 가장 처음으로 right와 동일한 문자의 인덱스(index)를 구해 사용한다.
만약 이 index가 right와 동일하다면 그 중간에는 중복된 문자가 존재하지 않으며 반대로 동일하지 않다면 중간에 right와 동일한 문자열이 존재하기 때문에 left를 중복 문자를 제거하기 위해 index + 1로 초기화한다.
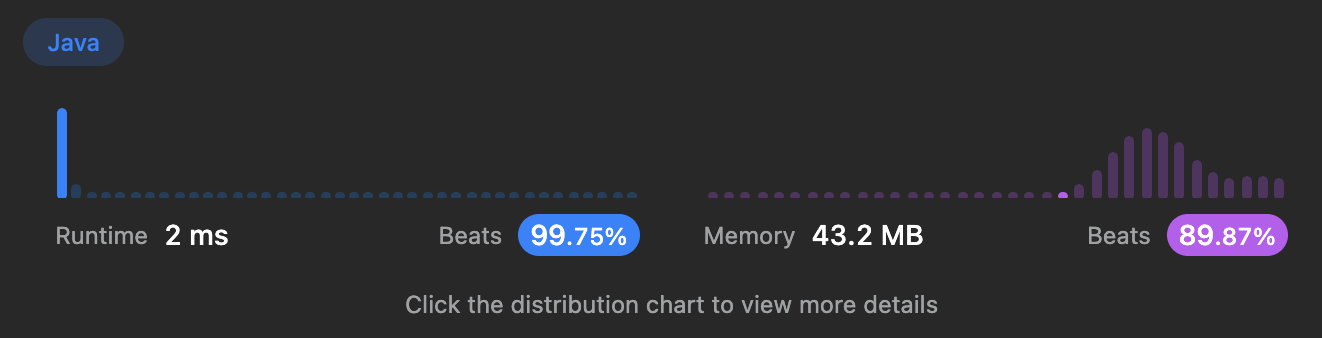
이를 반복하면서 가장 긴 중복이 없는 문자열의 길이를 찾는 방식이다. 시간복잡도, 공간복잡도는 동일하지만 문자의 반복횟수를 관리하는 배열이 필요하지 않기 때문에 두번째 풀이보다 메모리를 더 적게 사용할 수 있다.
class Solution {
public int lengthOfLongestSubstring(String s) {
int answer = 0;
int left = 0, right = 0;
while (right < s.length()) {
int index = s.indexOf(s.charAt(right), left);
if (index != right) {
left = index + 1;
}
answer = Math.max(answer, right - left + 1);
right++;
}
return answer;
}
}