빈 생명주기 콜백 시작
데이터베이스 커넥션 풀이나, 네트워크 소켓처럼 애플리케이션 시작 시점에 필요한 연결을 미리 해두고, 애플리케이션 종료 시점에 연결을 모두 종료하는 작업을 진행하려면, 객체의 초기화와 종료 작업이 필요하다.
간단하게 외부 네트워크에 미리 연결하는 객체를 하나 생성한다고 가정해보자. 실제로 네트워크에 연결하는 것은 아니고, 단순히 문자만 출력하도록했다. 이 'NetworkClient'는 애플리케이션 시작 시점에 'connect()'를 호출해서 연결을 맺어두어야하고, 애플리케이션이 종료되면 'disConnect()'를 호출해서 연결을 끊어야 한다.
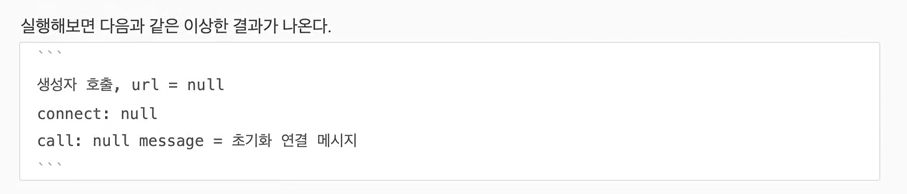
생성자 부분을 보면 url 정보 없이 connect가 호출되는 것을 확인할 수 있다.
너무 당연한 이야기지만 객체를 생성하는 단계에는 url이 없고, 객체를 생성한 다음에 외부에서 수정자 주입을 통해서 'setUrl()'이 호출되어야 url이 존재하게 된다.
스프링 빈은 간단하게 다음과 같은 라이프사이클을 가진다.
객체생성 -> 의존관계 주입
스프링 빈은 객체를 생성하고, 의존관계 주입이 다 끝난 다음에야 필요한 데이터를 사용할 수 있는 준비가 완료된다. 따라서 초기화 작업은 의존관계 주입이 모두 완료되고 난 다음에 호출해야 한다. 그런데 개발자가 의존관계 주입이 모두 완료된 시점을 어떻게 알 수 있을까?
스프링은 의존관계 주입이 완료되면 스프링 빈에게 콜백 메서드를 통해서 초기화 시점을 알려주는 다양한 기능을 제공한다. 또한 스프링은 스프링 컨테이너가 종료되기 직전에 소멸 콜백을 준다.
스프링 빈의 이벤트 라이프사이클
스프링 컨테이너 생성 -> 스프링 빈 생성 -> 의존관계 주입 -> 초기화 콜백 ->사용 -> 소멸전 콜백 -> 스프링 종료
- 초기화 콜백 : 빈이 생성되고, 빈의 의존관계 주입이 완료된 후 호출
- 소멸전 콜백 : 빈이 소멸되기 직전에 호출
스프링은 다양한 방식으로 생명주기 콜백을 지원한다.
참고: 객체의 생성과 초기화를 분리하자.
생성자는 필수 정보(파라미터)를 받고, 메모리를 할당해서 객체를 생성하는 책임을 가진다. 반면에 초기화는 이렇게 생성된 값들을 활용해서 외부 커넥션을 연결하는 등 무거운 동작을 수행한다. 따라서 생성자 안에는 무거운 초기화 작업을 함께 하는 것 보다는 객체를 생성하는 부분과 초기화 하는 부분을 명확하게 나누는 것이 유지보수 관점에서 좋다. 물론 초기화 작업이 내부 값들만 약간 변경하는 정도로 단순한 경우에는 생성자에서 한번에 다 처리하는게 더 나을 수 있다.
스프링은 크게 3가지 방법으로 빈 생명주기 콜백을 지원한다.
- 인터페이스(InitializingBean, DisposableBean)
- 설정 정보에 초기화 메서드, 종료 메서드 지정
- @PostConstruct, @PreDestory 애노테이션 지원
인터페이스 InitializingBean, DisposableBean
- InitializingBean,DisposableBean을 implements 해준 후 관련 함수를 오버라이드 해준다.
// 콜백 함수 InitializingBean
@Override
public void afterPropertiesSet() throws Exception {
connect();
call("초기화 연결 메시지");
}
// 콜백 함수 DisposableBean
@Override
public void destroy() throws Exception {
disconnect();
}
}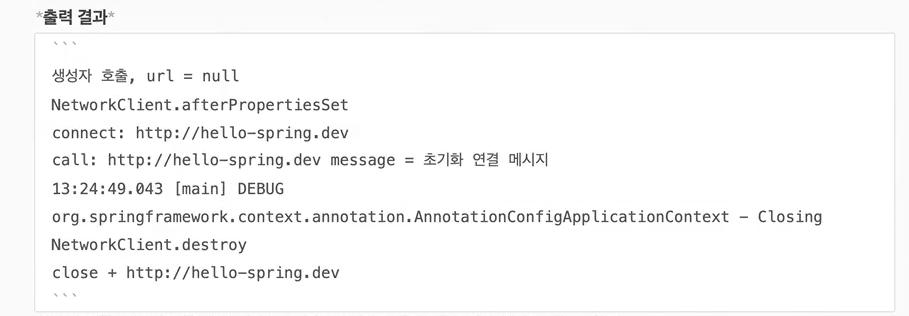
- 출력 결과를 보면 초기화 메서드가 주입 완료 후에 적절하게 호출 된 것을 확인할 수 있다.
- 그리고 스프링 컨테이너의 종료가 호출되자 소멸 메서드가 호출 된 것도 확인할 수 있다
초기화, 소멸 인터페이스 단점
- 이 인터페이스는 스프링 전용 인터페이스다. 해당 코드가 스프링 전용 인터페이스에 의존한다.
- 초기화, 소멸 메서드의 이름을 변경할 수 없다
- 내가 코드를 고칠 수 없는 외부 라이브러리에 적용할 수 없다.
참고: 인터페이스를 사용하는 초기화, 종료 방법은 스프링 초창기에 나온 방법들이고, 지금은 다음의 더 나은 방법들이 있어서 거의 사용하지 않는다!!!
빈 등록 초기화, 소멸 메서드
설정 정보에 '@Bean(initMethod = "init", destroyMethod = "close")'처럼 초기화, 소멸 메서드를 지정할 수 있다.
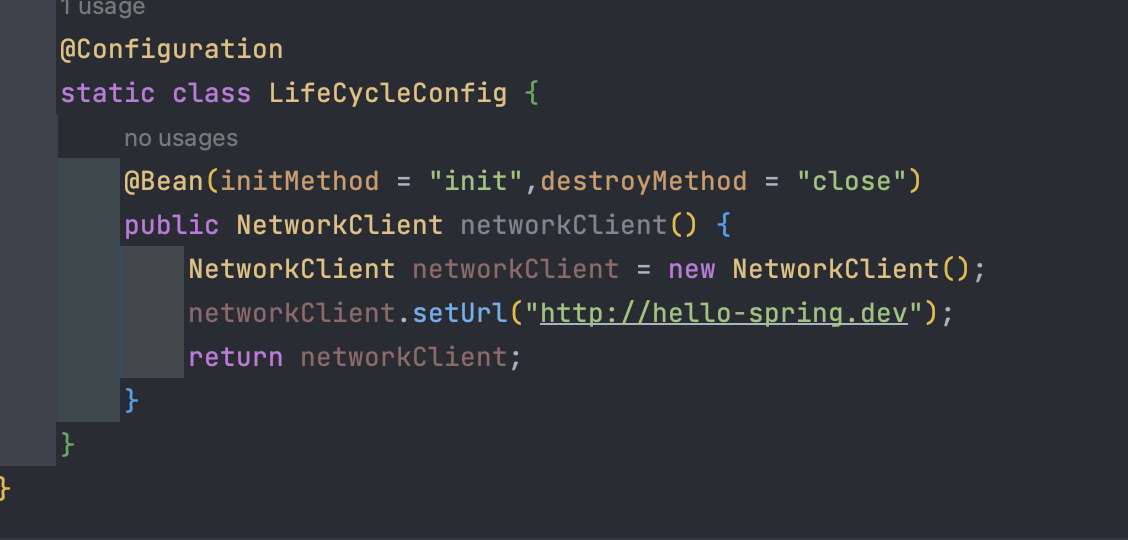
설정 정보 사용 특징
- 메시드 이름을 자유롭게 줄 수 있다.
- 스프링 빈이 스프링 코드에 의존하지 않는다
- 코드가 아니라 설정 정보를 사용하기 때문에 코드를 고칠 수 없는 외부 라이브러리에도 초기화, 종료 메서드를 적용할 수 있다.
종료 메서드 추론
- '@Bean의 destroyMethod'속성에는 아주 특별한 기능이 있다.
- 라이브러리는 대부분 'close','shutdown'이라는 이름의 종료 메서드를 사용한다.
- @Bean의 'destroyMethod'는 기본값이 '(inferred)'(추론)으로 등록되어 있다.
- 이 추론 기능은 'close','shutdown'라는 이름의 메서드를 자동으로 호출해준다. 이름 그대로 종료 메서드를 추론해서 호출해준다.
- 따라서 직접 스프링 빈으로 등록하면 종료 메서드는 따로 적어주지 않아도 잘 동작한다.
- 추론 기능을 사용하기 싫으면 'destroyMethod=""'처럼 빈 공백을 지정하면 된다.
출처:https://www.inflearn.com/course/http-%EC%9B%B9-%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC/dashboard
