Spring
1.java spring Start

Gradle은 의존관계가 있는 라이브러리를 함께 다운로드 한다.spring-boot-starter-web \- spring-boot-starter-tomcat: 톰캣(웹서버)spring-webmvc: 스프링 웹 MVCspring-boot-starter-thymelea
2.Spring 다이어그램
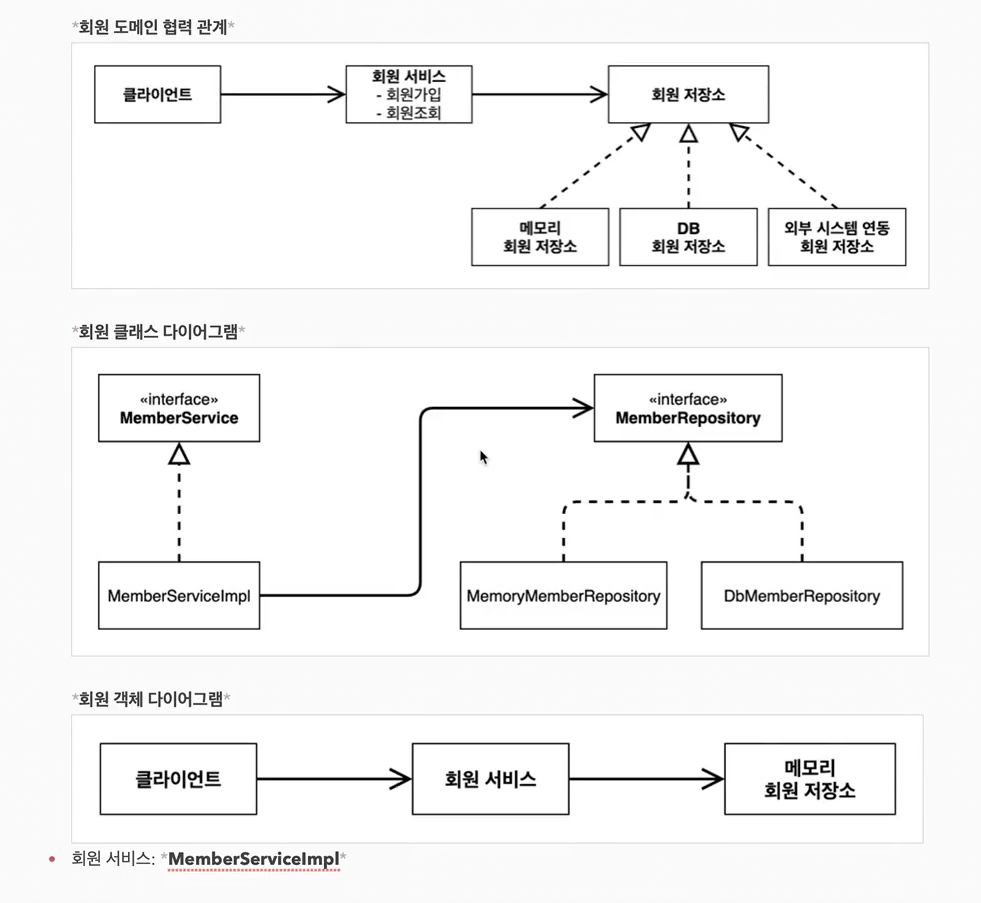
3.IoC, DI, 그리고 컨테이너
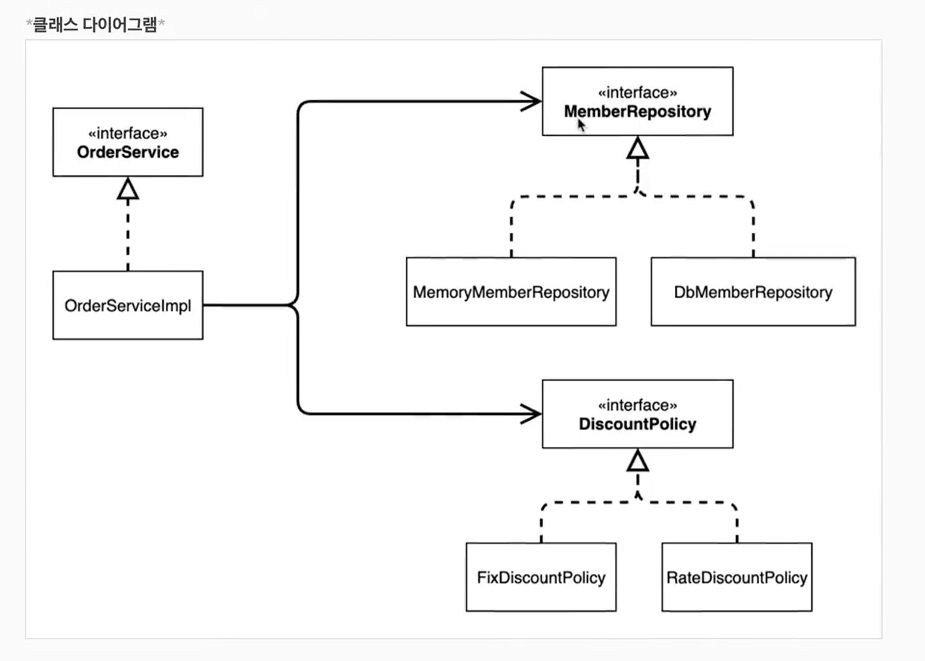
기존 프로그램은 클라이언트 구현 객체가 스스로 필요한 서버 구현 객체를 생성하고, 연결하고, 실행했다. 한마디로 구현 객체가 프로그램의 제어 흐름을 스스로 조종했다. 개발자 입장에서는 자연스러운 흐름이다.반면에 AppConfig가 등장한 이후에는 구현 객체는 자신의 로
4.스프링 컨테이너
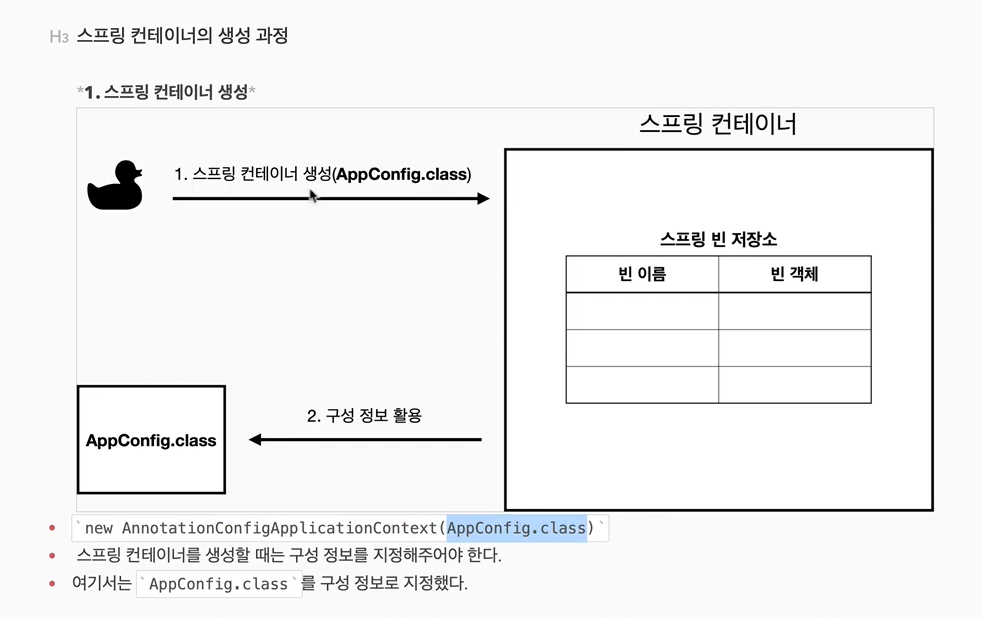
'ApplicationContext'를 스프링 컨테이너라 한다.기존에는 개발자가 'AppConfig'를 사용해서 직접 객체를 생성하고 DI를 했지만, 이제부터는 스프링 컨테이너를 통해서 사용한다.스프링 컨테이너는 '@Confuguration'이 붙은 'AppConfig
5.BeanFactory와 ApplicationContext
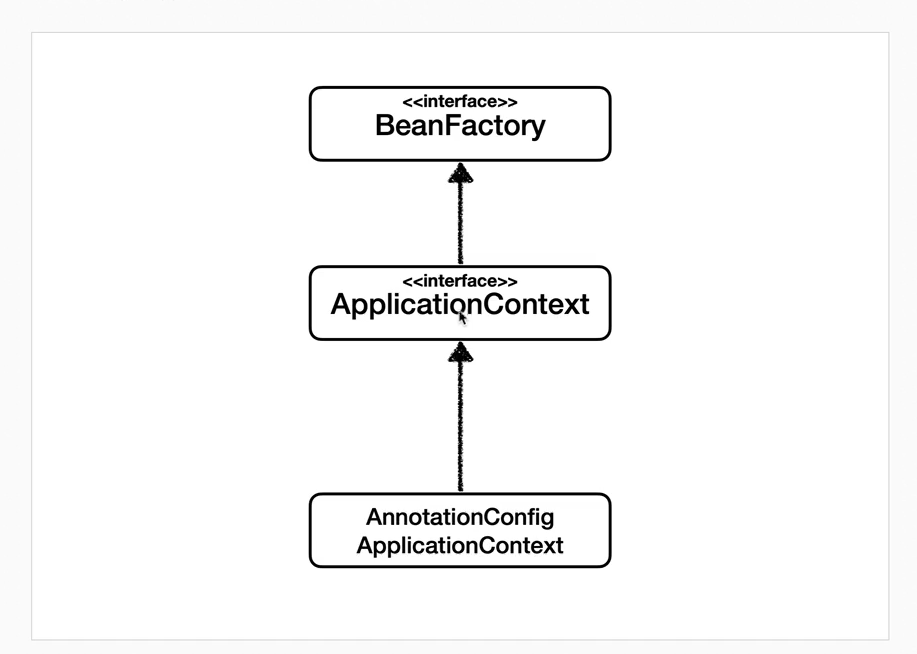
스프링 컨테이너의 최상위 인터페이스다.스프링 빈을 관리하고 조회하는 역할을 담당한다.'getBean()'을 제공한다.지금까지 우리가 사용했던 대부분의 기능은 BeanFactory가 제공하는 기능이다.BeanFacroty 기능을 모두 상속받아서 제공한다.빈을 관리하고 검
6.스프링 빈 설정 메타 정보 - BeanDefinition
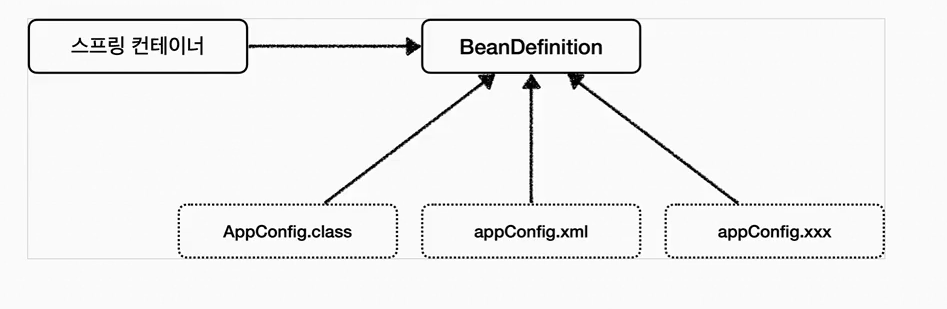
스프링은 어떻게 이런 다양한 설정 형식을 지원하는 것일까? 그 중심에는 'BeanDefinition'이라는 추상화가 있다.쉽게 이야기해서 <역할과 구현을 개념적으로 나눈 것> 이다! \-XML을 읽어서 BeanDefinition을 만들면 된다 \-자바 코드를
7.웹 애플리케이션과 싱글톤
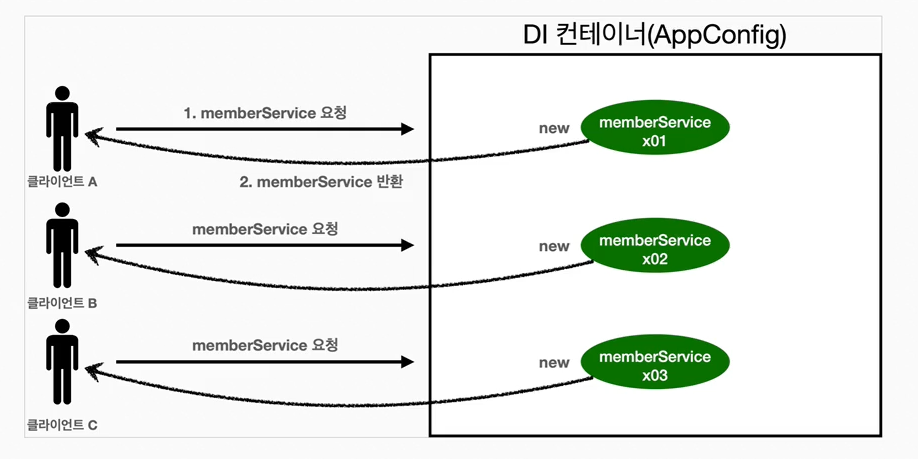
스프링은 태생이 기업용 온라인 서비스 기술을 지원하기 위해 탄생했다.대부분의 스프링 애플리케이션은 웹 애플리케이션이다. 물론 웹이 아닌 애플리케이션 개발도 얼마든지 개발할 수 있다.웹 애플리케이션은 보통 여러 고객이 동시에 요청을 한다.위에서 만든 스프링 없는 순수한
8.싱글톤 컨테이너(Spring)
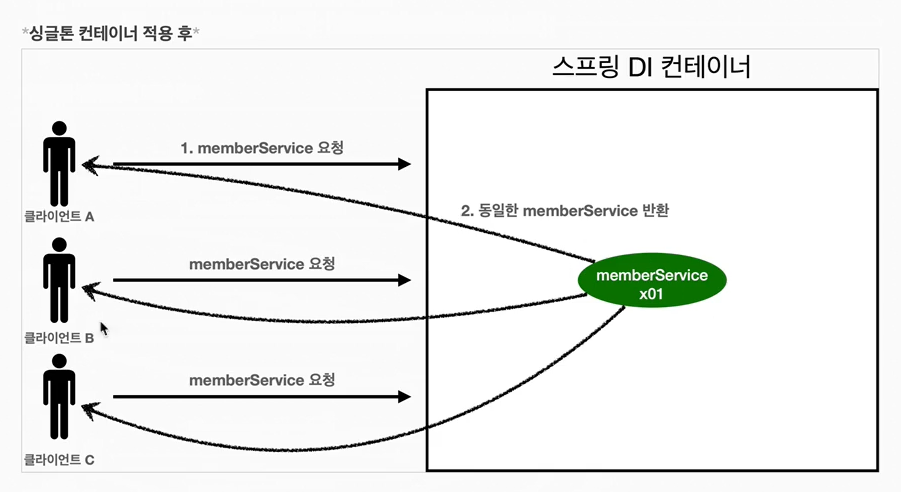
스프링 컨테이너는 싱글톤 패턴의 문제점을 해결하면서, 객체 인스턴스를 싱글톤(1개만 생성)으로 관리한다. 지금까지 우리가 학습한 스프링 빈이 바로 싱글톤으로 관리되는 빈이다.스프링 컨테이너는 싱글턴 패턴을 적용하지 않아도, 객체 인스턴스를 싱글톤으로 관리한다. \-이
9.싱글톤 방식의 주의점
싱글톤 패턴이든, 스프링 같은 싱글톤 컨테이너를 사용하든, 객체 인스턴스를 하나만 생성해서 공유하는 싱글톤 방식은 여러 클라이언트가 하나의 같은 객체 인스턴스를 공유하기 때문에 싱글톤 객체는 상태를 유지(stateful)하게 설계해서는 안된다.무상태(stateless)
10.@Configuration과 바이트코드 조작의 마법

스프링 컨테이너는 싱글톤 레지스트리다. 따라서 스프링 빈이 싱글톤이 되도록 보장해주어야 한다. 그런데 스프링이 자바 코드까지 어떻게 하기는 어렵다. 저 자바 코드를 보면 분명 3번 호출되어야 하는 것이 맞다. 그래서 스프링은 클래스의 바이트코드를 조작하는 라이브러리를
11.Component Scan(Spring)

지금까지 스프링 빈을 등록할 때는 자바 코드의 @Bean이나 XML의 <'bean'> 등을 통해서 설정 정보에 직접 등록할 스프링 빈을 나열했다.등록해야할 빈이 수십, 수백개가 되면 일일이 등록하기도 귀찮고, 설정 정보도 커지고, 누락하는 문제도 발생한다.그래서
12.Component Scan2

컴포넌트 스캔에서 같은 빈 이름을 등록하면 어떻게 될까?자동 빈 등록 vs 자동 빈 등록수동 빈 등록 vs 자동 빈 등록컴포넌트 스캔에 의해 자동으로 스프링 빈이 등록되는데, 그 이름이 같은 경우 스프링은 오류를 발생시킨다. \-'ConflictiongBeanDefi
13.다양한 의존관계 주입 방법
의존관계 주입은 크게 4가지 방법이 있다.생성자 주입수정자 주입(setter 주입)필드 주입일반 메서드 주입이름 그대로 생성자를 통해서 의존 관계를 주입 받는 방법이다.지금까지 우리가 진행했던 방법이 바로 생성자 주입이다특징 \-생성자 호출시점에 딱 1번만 호출되는
14.옵션처리
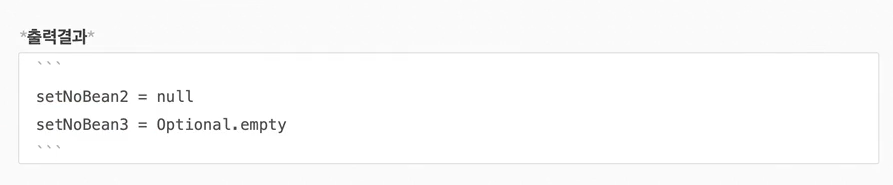
주입할 스프링 빈이 없어도 동작해야 할 때가 있다.그런데 '@Autowired'만 사용하면 'required'옵션의 기본 값이 'true'로 되어 있어서 자동 주입 대상이 없으면 오류가 발생한다.자동 주입 대상을 옵션으로 처리하는 방법은 다음과 같다.'@Autowire
15.생성자 주입을 선택해라!

과거에는 수정자 주입과 필드 주입을 많이 사용했지만, 최근에는 스프링을 포함한 DI 프레임워크 대부분이 생성자 주입을 권장한다. 그 이유는 다음과 같다대부분의 의존관계 주입은 한번 일어나면 애플리케이션 종료시점까지 의존관계를 변경할 일이 없다. 오히려 대부분의 의존관계
16.롬복과 최신 트렌드

막상 개발을 해보면, 대부분이 다 불변이고, 그래서 다음과 같이 생성자에 final 키워드를 사용하게 된다. 그런데 생성자도 만들어야 하고, 주입 받은 값을 대입ㅂ하는 코드도 만들어야 하고.. 필드 주입처럼 편리하게 사용하는 방법은 없을까?다음 코드를 최적화해보자.최근
17.조회 빈이 2개 이상 - 문제
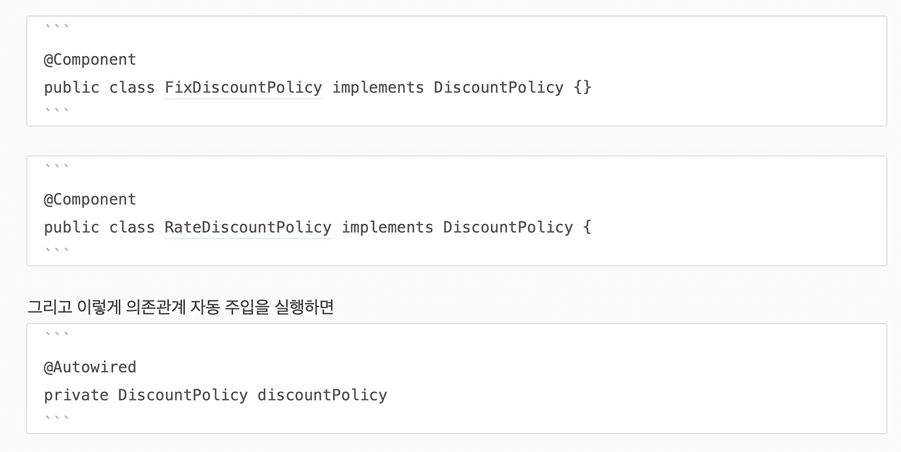
'@Autowired'는 타입(Type)으로 조회한다.타입으로 조회하기 때문에, 마치 다음 코드와 유사하게 동작한다.(실제로는 더 많은 기능을 제공한다.)'ac.getBean(DiscountPolicy.class)'스프링 빈 조회해서 학습했듯이 타입으로 조회하면 선택된
18.조회한 빈이 모두 필요할 때,List,Map

의도적으로 정말 해당 타입의 스프링 빈이 다 필요한 경우도 있다. 예를 들어서 할인 서비스를 제공하는데, 클라이언트가 할인의 종류(rate,fix)를 선택할 수 있다고 가정해보자. 스프링을 사용하면 소위 말하는 전략 패턴을 매우 간단하게 구현할 수 있다.Discount
19.자동, 수동의 올바른 실무 운영 기준
그러면 어떤 경우에 컴포넌트 스캔과 자동 주입을 사용하고, 어떤 경우에 설정 정보를 통해서 수동으로 빈을 등록하고, 의존관계도 수동으로 주입해야 할까?결론부터 이야기하면, 스프링이 나오고 시간이 갈 수록 점점 자동을 선호하는 추세다. 스프링은 '@Coomponent'뿐
20.빈 생명주기 콜백
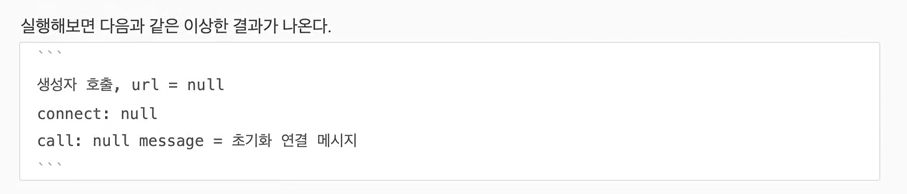
데이터베이스 커넥션 풀이나, 네트워크 소켓처럼 애플리케이션 시작 시점에 필요한 연결을 미리 해두고, 애플리케이션 종료 시점에 연결을 모두 종료하는 작업을 진행하려면, 객체의 초기화와 종료 작업이 필요하다.간단하게 외부 네트워크에 미리 연결하는 객체를 하나 생성한다고 가
21.빈 생명주기 콜백 @애노테이션
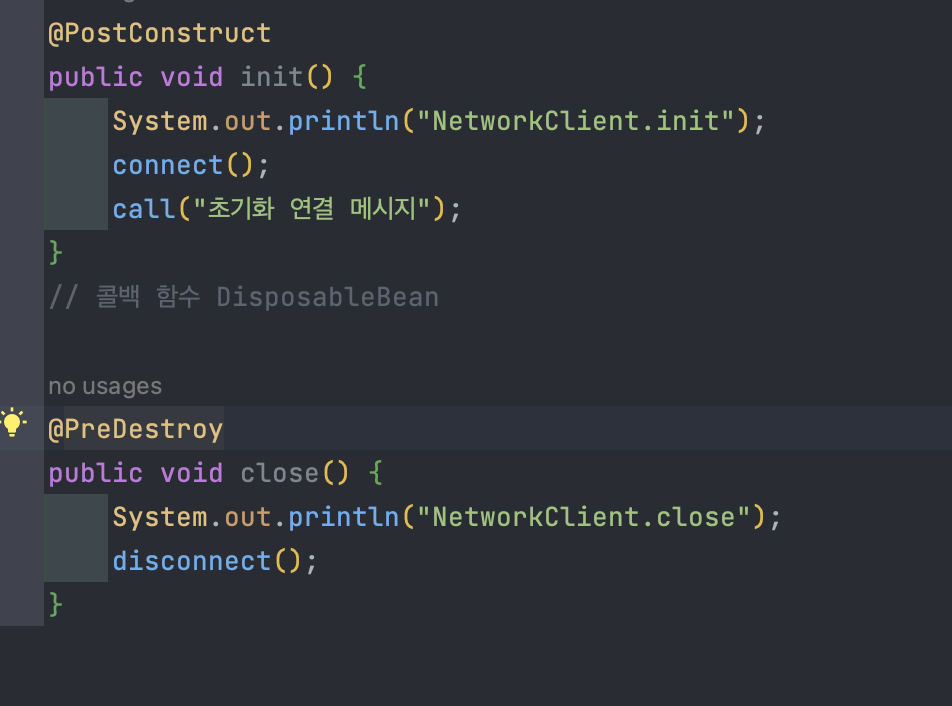
import javax... <- javax란 자바에서 공식적으로 지원한다는 것을 의미한다.'@PostConstruct','@PreDestroy'이 두 애노테이션을 사용하면 가장 편리하게 초기화와 종료를 실행할 수 있다.최신 스프링에서 가장 권장하는 방법이다.애노
22.빈 스코프(Spring bean)
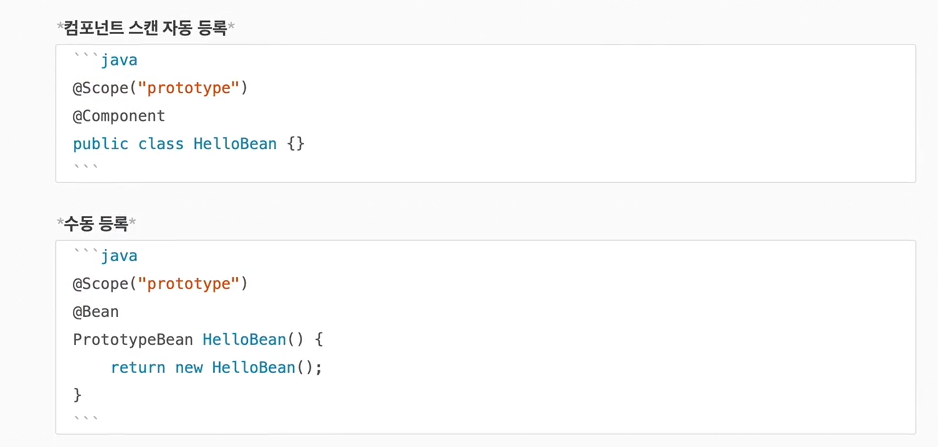
지금까지 우리는 스프링 빈이 스프링 컨테이너의 시작과 함께 생성되어서 스프링 컨테이너가 종료될 때까지 유지된다고 학습했다. 이것은 스프링 빈이 기본적으로 싱글톤 스코프로 생성되기 때문이다. 스코프는 번역 그대로 빈이 존재할 수 있는 범위를 뜻한다.싱글톤 : 기본 스코프
23.프로토타입 스코프 - 싱글톤 빈과 함께 사용시 문제점
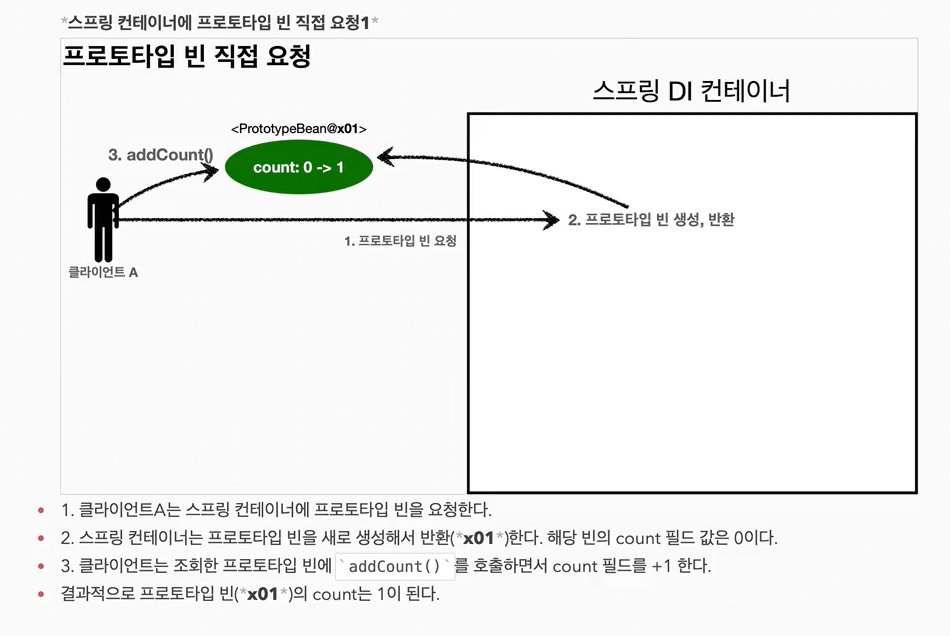
스프링 컨테이너에 프로토타입 스코프의 빈을 요청하면 항상 새로운 객체 인스턴스를 생성해서 반환한다. 하지만 싱글톤 빈과 함께 사용할 때는 의도한 대로 잘 동작하지 않으므로 주의해야 한다. 그림과 코드로 설명하겠다.먼저 스프링 컨테이너에 프로토타입 빈을 직접 요청하는 예
24.웹 스코프
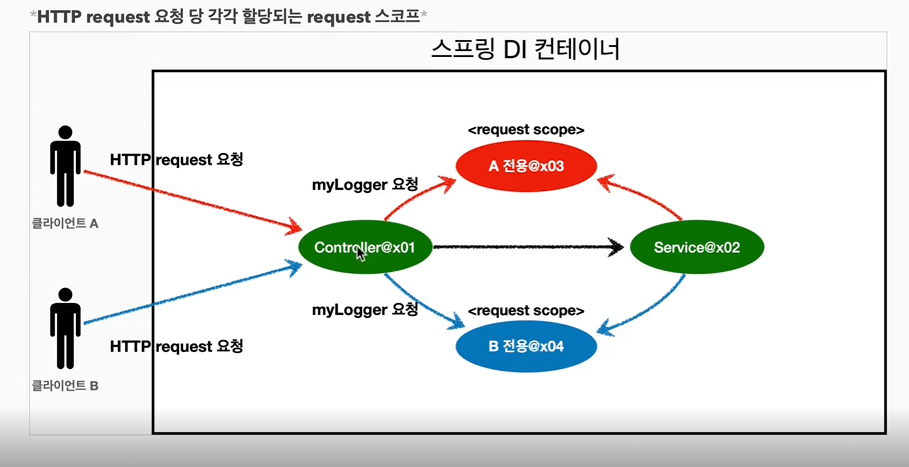
지금까지 싱글톤과 프로토타입 스코프를 학습했다. 싱글톤은 스프링 컨테이너의 시작과 끝까지 함께하는 매우 긴 스코프이고, 프로토타입은 생성과 의존관계 주입, 그리고 초기화까지만 진행하는 특별한 스코프이다.이번에는 웹 스코프에 대해 알아보자.웹 스코프는 웹 환경에서만 동작
25.조회 빈이 2개 이상 - 문제
'@Autowired'는 타입(Type)으로 조회한다. 타입으로 조회하기 때문에, 마치 다음 코드와 유사하게 동작한다.(실제로는 더 많은 기능을 제공한다.) 'ac.getBean(DiscountPolicy.class)' 스프링 빈 조회해서 학습했듯이 타입으로 조회하
26.Spring Entity, Repository 설명
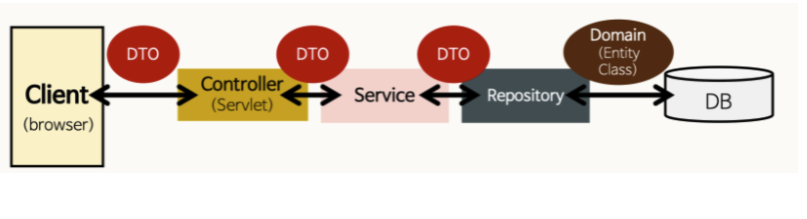
Spring Entity, Repository는 DB와 관련된 항목들 중 몇 가지입니다.그 외에는 DAO, DTO, VO, Transaction등이 있다.Entitiy(엔티티)는 데이터베이스에 쓰일 필드와 여러 엔티티간 연관관계를 정의하는 역할을 의미한다. 테이블에 대
27.스프링 MVC 전체 구조
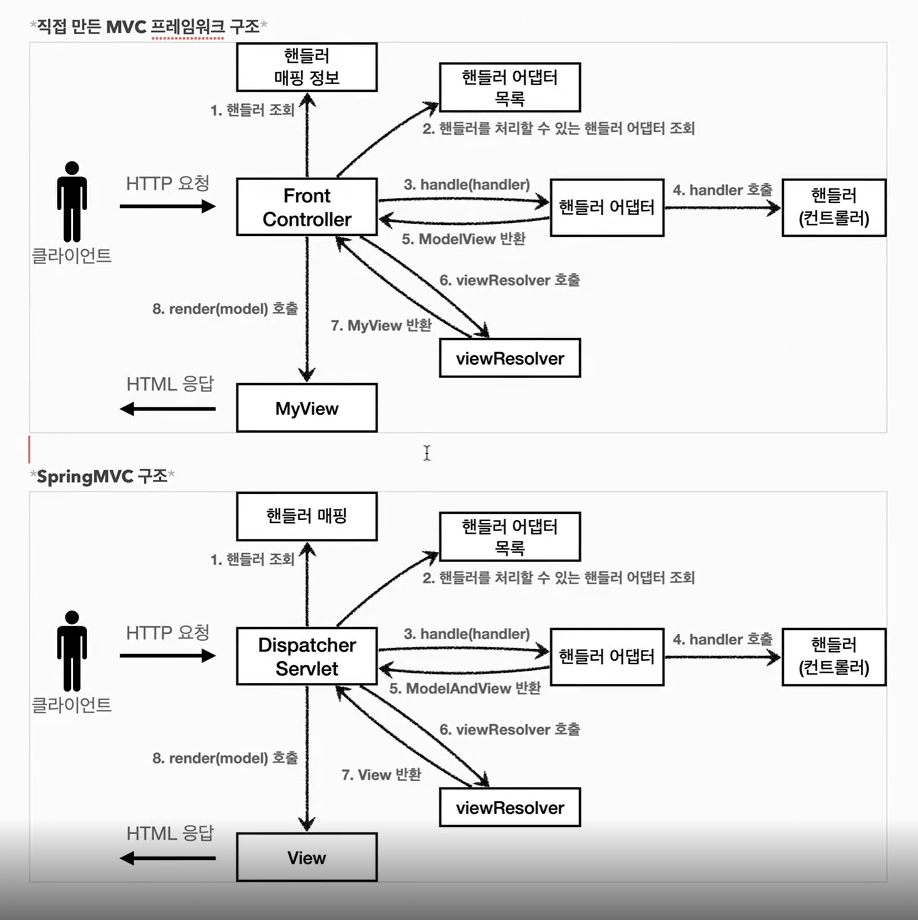
핸들러 조회 : 핸들러 매핑을 통해 요청 URL에 매핑된 핸들러(컨트롤러)를 조회한다.핸들러 어댑터 조회: 핸들러를 실행할 수 잇는 어댑터를 조회한다.핸들러 어댑터 실행: 핸들러 어댑터를 실행한다핸들러 실행 : 핸들러 어탭터가 실제 핸들러를 실행한다.ModelAndVi
28.Stomp 스프링

Simple Text Oriented Messaging Protocol은 메세징 전송을 효율적으로 하기 위해 탄생한 프로토콜이고, 기본적으로 pub/sub 구조로 되어있어 메세지를 전송하고 메세지를 받아 처리하는 부분이 확실히 정해져 있기 때문에 개발자 입장에서 명확하
29.매핑 정보
@Controller 는 반환 값이 'String'이면 뷰 이름으로 인식된다. 그래서 뷰를 찾고 뷰가 랜더링 된다.@RestController 는 반환 값으로 뷰를 찾는 것이 아니라, HTTP 메시지 바디에 바로 입력 한다. 따라서 실행 결과로 ok 메세지를 받을 수
30.HTTP 요청 파라미터 - 쿼리 파라미터, HTML Form
GET - 쿼리 파라미터 \- /url ?username=hello&age=20 \- 메시지 바디 없이, URL의 쿼리 파라미터에 데이터를 포함해서 전달 \- 예) 검색, 필터, 페이징 등에서 많이 사용하는 방식POST - HTML form \- content-
31.HTTP 요청 파라미터 - @ModelAttribute, 단순 텍스트
실제 개발을 하면 요청 파라미터를 받아서 필요한 객체를 만들고 그 객체에 값을 넣어주어야 한다. 보통 다음과 같이 코드를 작성할 것이다.스프링은 이 과정을 완전히 자동화해주는 '@ModelAttribute'기능을 제공한다.@Getter, @Setter, @ToStrin
32.HTTP 메시지 컨버터
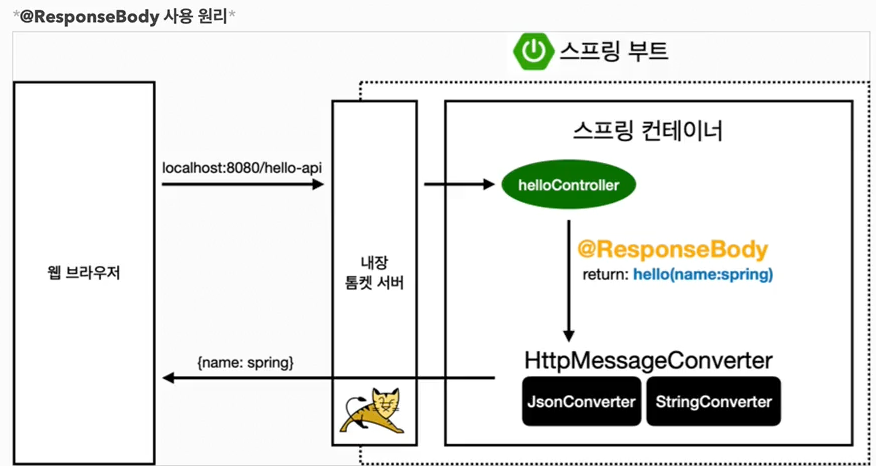
뷰 템플릿으로 HTML을 생성해서 응답하는 것이 아니라, HTTP API처럼 JSON 데이터를 HTTP 메시지 바디에서 직접 읽거나 쓰는 경우 HTTP 메시지 컨버터를 사용하면 편리하다.'@ResponseBody'를 사용 \- HTTP의 BODY에 문자 내용을 직접
33.RequestMappingHandler 구조
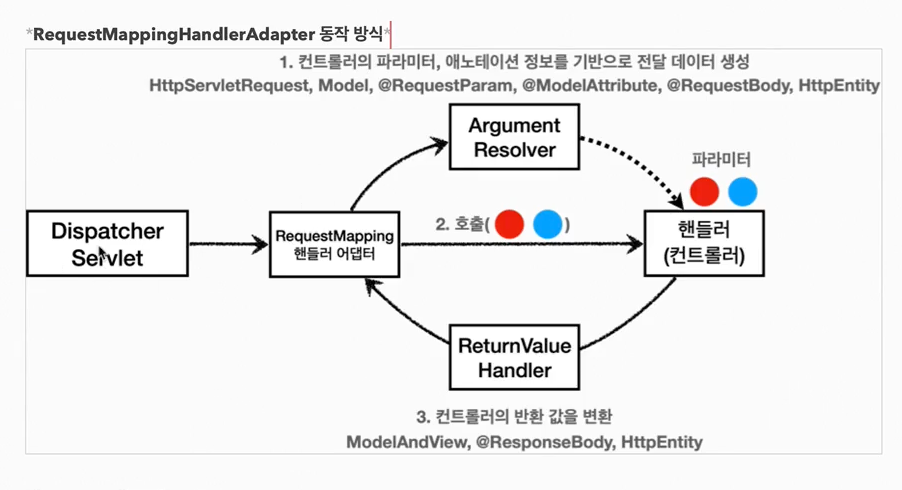
스프링은 다음을 모두 인터페이스로 제공한다. 따라서 필요하다면 언제든지 기능을 확장할 수 있다.'HandlerMethodArgumentResolver''HandlerMethodReturnValueHandler''HttpMessageConverter'
34.RedirectAttributes
PRG(Post-Redirect-Get)을 이용했을 때, Post행위가 잘 저장되었는지 확인하기 위해서 'RedirectAttributes'를 사용할 수 있다.itemId 인코딩도 진행해주며 아래에서 지정을 해주지 않은 status는 쿼리스트링으로 넘어가게 된다.실행해
35.Spring 웹 애플리케이션 계층 구조 (일반)
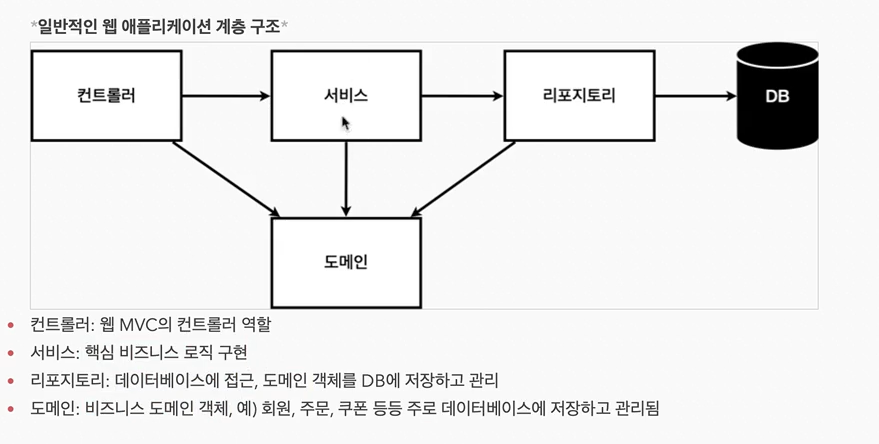
Controller : 웹 MVC의 컨트롤러 역할Service : 핵심 비즈니스 로직 구현Domain : 비즈니스 도메인 객체 예) 회원, 주문, 쿠폰 등등 DB에 주로 저장&관리 Repository : 데이터베이스에 접근, 도매인 객체를 DB에 저장 관리
36.JDBC 이해
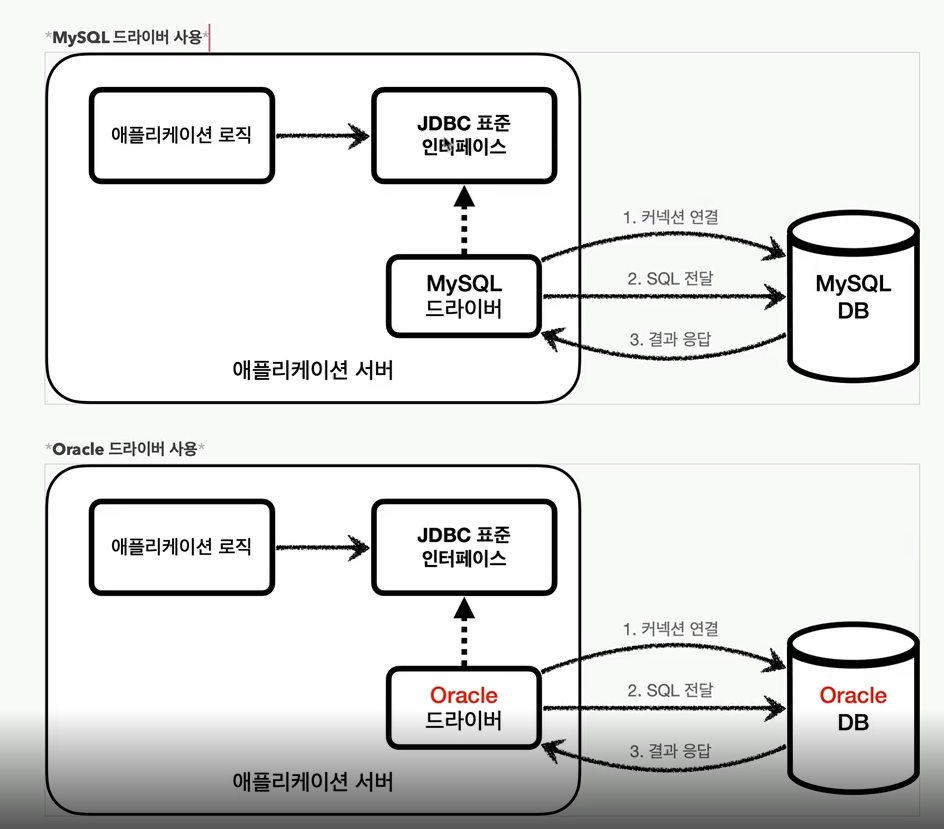
JDBC 등장 이유 애플리케이션을 개발할 때 중요한 데이터는 대부분 데이터베이스에 보관한다. 클라이언트가 애플리케이션 서버를 통해 데이터를 저장하거나 조회하면, 애플리케이션 서버는 다음 과정을 통해 데이터베이스를 사용한다. 커넥션 연결 : 주로 TCP/IP를 사용
37.JDBC와 최신 데이터 접근 기술
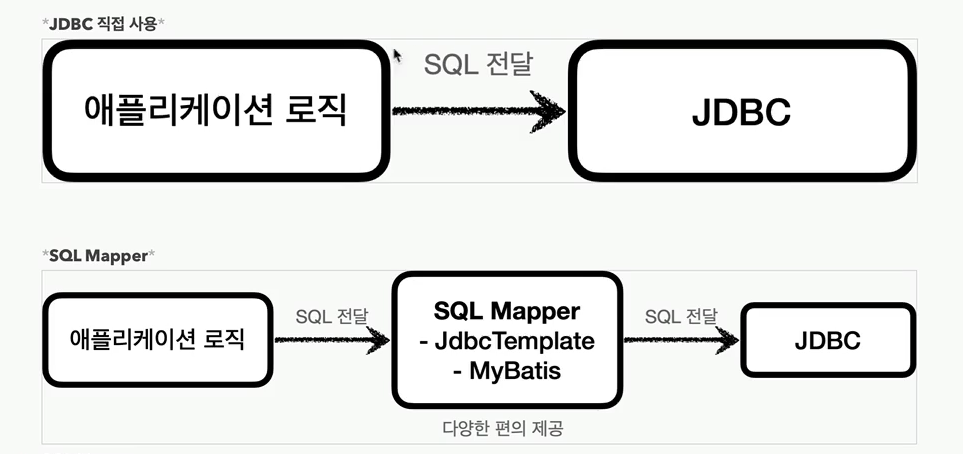
JDBC는 1997년에 출시될 정도로 오래된 기술이고, 사용하는 방법도 복잡하다. 그래서 최근에는 JDBC를 직접 사용하기 보다 JDBC를 편리하게 사용하는 다양한 기술이 존재한다. 대표적으로 SQL Mapper와 ORM 기술로 나눌 수 있다.SQL Mapper장점JD
38.커넥션 풀이란?
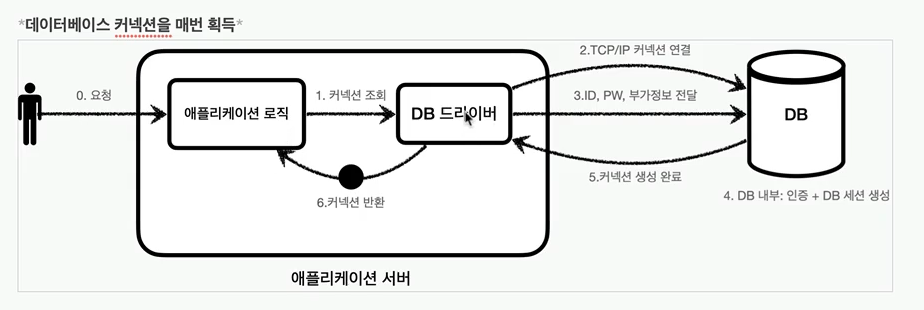
데이터베이스 커넥션을 획득할 때는 다음과 같은 복잡한 과정을 거친다.1\. 애플리케이션 로직은 DB 드라이버를 통해 커넥션을 조회한다.2\. DB 드라이버는 DB와 'TCP/IP' 커넥션을 연결한다. 물론 이 과정에서 3 way handshake 같은 'TCP/IP'
39.DataSource 이해
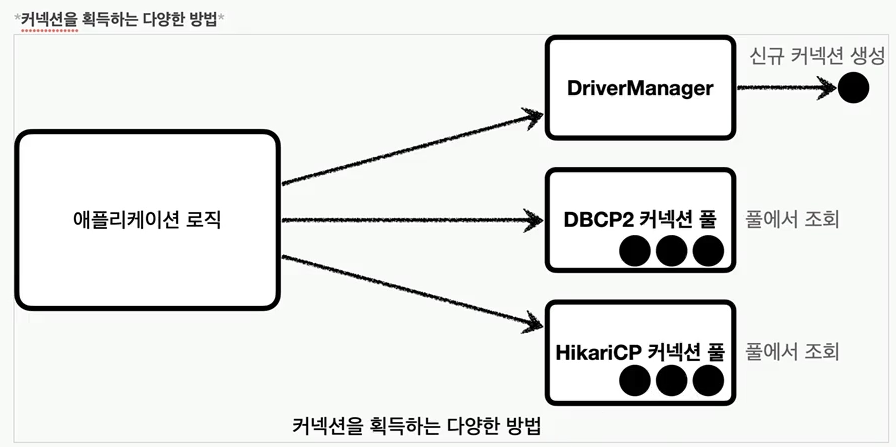
커넥션을 얻는 방법은 앞서 학습한 JDBC 'DriveManager'를 직접 사용하거나, 커넥션 풀을 사용하는 등 다양한 방법이 존재한다.대부분의 커넥션 풀은 'DataSource' 인터페이스를 이미 구현해두었다. 따라서 개발자는 'DBCP2 커넥션 풀', 'Hikar
40.DriverManager & DataSource

'DriverManager'는 커넥션을 획득할 때 마다 'URL','USERNAME', 'PASSWORD'같은 파라미터를 계속 전달해야 한다. 반면에 'DataSource'를 사용하는 방식은 처음 객체를 생성할 때만 파라미터를 넘겨두고, 커넥션을 획득할 때는 단순히 '
41.HikariPool Spring
HikariCP 커넥션 풀을 사용한다. 'HikariDataSource'는 'DataSource'인터페이스를 구현하고 있다.커넥션 풀 최대 사이즈를 10으로 지정하고, 풀의 이름을 'MyPool'이라고 지정했다.커넥션 풀에서 커넥션을 생성하는 작업은 애플리케이션 실행
42.트랜잭션
데이터를 저장할 때 단순히 파일에 저장해도 되는데, 데이터베이스에 저장하는 이유는 무엇일까? 여러이유가 있지만, 가장 대표적인 이유는 바로 데이터베이스는 트랜잭션이라는 개념을 지원하기 때문이다.트랜잭션을 이름 그대로 번역하면 거래라는 뜻이다. 이것을 쉽게 풀어서 이야기
43.데이터베이스 연결 구조와 DB세션
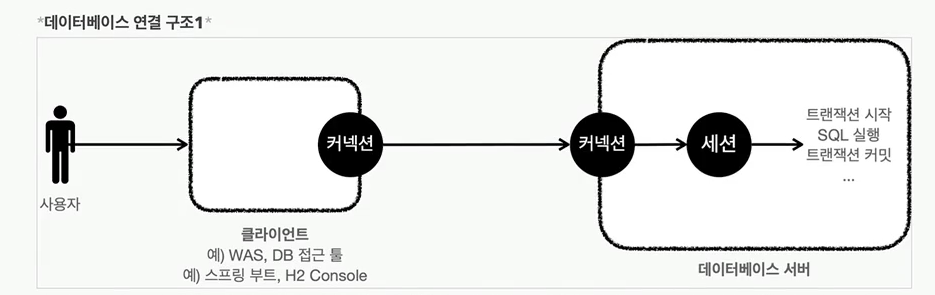
사용자는 웹 애플리케이션 서버(WAS)나 DB 접근 툴 같은 클라이언트를 사용해서 데이터베이스 서버에 접근할 수 있다. 클라이언트는 데이터베이스 서버에 연결을 요청하고 커넥션을 맺게 된다. 이때 데이터베이스 서버는 내부에 세션이라는 것을 만든다. 그리고 앞으로 해당 커
44.자동커밋 & 수동커밋
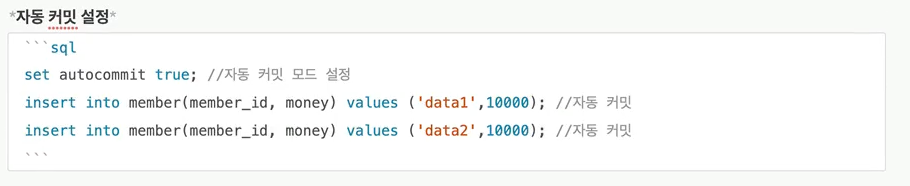
트랜잭션을 사용하려면 먼저 자동 커밋과 수동 커밋을 이해해야 한다.자동 커밋으로 설정하면 각각의 쿼리 실행 직후에 자동으로 커밋을 호출한다. 따라서 커밋이나 롤백을 직접 호출하지 않아도 되는 편리함이 있다. 하지만 쿼리를 하나하나 실행할 때 마다 자동으로 커밋이 되어버