Intro
아이폰 연락처 앱은 성을 기준으로 정렬이 되어 있습니다. 특히 우측 사이드에는 "ㄱ~ㅎ, A~Z, 그리고 #(특수문자)" 순으로 원하는 범위로 빠르게 이동할 수 있는 인덱스가 있죠.
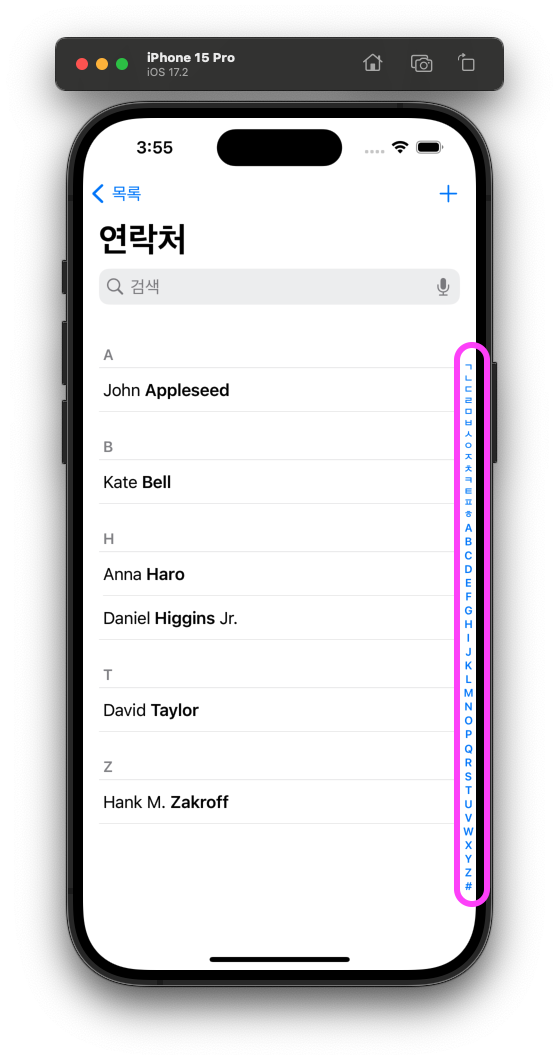
만약 이 기능을 구현해야 한다면 어떻게 할 수 있을까요? 스위프트의 Foundation 프레임워크는 이럴 때를 위한 아주 좋은 기능을 가지고 있습니다.
Unicode.Scalar
Unicode.Scalar 는 단일한 유니코드 scalar 값을 가지는 타입입니다.
import Foundation
let string: Unicode.Scalar = "김"
print(string.value) // 44608value 프로퍼티에 접근하게 되면 "김"이라는 글자의 값이 십진수로 44608 이라는 숫자와 대응한다는 것을 알 수 있습니다. 반대로 아래와 같이 십진수 값을 기반으로 대응하는 글자를 가져올 수도 있습니다.
let anotherString: Unicode.Scalar = Unicode.Scalar(44608)!
print(anotherString) // "김"자모음 분리하기
자모음을 분리하기 위해서는 먼저 한글 자모음이 어떻게 구성되어있는지를 알아야 합니다. 다행히 우리에게는 현대 사관들의 성지인 나무위키가 있죠.
나무위키의 한글/자모 문서를 보면 한글은 자음과 모음으로 나뉘며, 그 중에서 특별히 겹낱자는 일부는 초성으로, 일부는 받침으로 쓰인다는 것을 알 수 있습니다. 이러한 개념에 맞춰 컴퓨터에서 한글은 자음(초성), 모음, 그리고 받침으로 구성이 됩니다.
decomposedStringWithCompatibilityMapping.unicodeScalars
스위프트에서 한글 글자를 분해하기 위해 String 의 메서드로 제공되는 decomposedStringWithCompatibilityMapping 메서드에 .unicodeScalars 를 붙여 활용할 수 있습니다.
let string: String = "김"
for scalar in string.decomposedStringWithCompatibilityMapping.unicodeScalars {
print(scalar) // 순서대로 "ㄱ", "ㅣ", "ㅁ" 을 출력
}분해한 자모음 Scalar 값도 마찬가지로 value 프로퍼티에 접근하여 대응하는 유니코드의 값을 십진수 형태로 가져올 수 있습니다.
let string: String = "김"
for scalar in string.decomposedStringWithCompatibilityMapping.unicodeScalars {
print(scalar.value) // 순서대로 4352, 4469, 4535 출력
}여기에서 주의할 점은 Scalar 타입과 String 타입을 직접적으로 비교할 수 없다는 점입니다. 아래의 코드를 실행하면 세번 모두 비교가 불가능하다는 메시지를 얻게 됩니다.
for scalar in string.decomposedStringWithCompatibilityMapping.unicodeScalars {
if scalar == "ㄱ" {
print("비교가 가능합니다.")
} else {
print("비교가 불가능합니다.")
}
}그렇다면 만약 Unicode.Scalar 타입으로 할당한 "ㄱ" 과 Unicode.Scalar 생성자에 숫자를 넣어 만든 "ㄱ" 은 비교가 될까요?
let comparableScalar: Unicode.Scalar = "ㄱ"
print(comparableScalar == Unicode.Scalar(4352)!) // false당연히 비교가 될 것 같았는데 비교가 되지 않는 것을 알 수 있습니다. 왜 그런 것일까요? 문제를 확인하기 위해 comparableScalar 의 value 를 확인해봅시다.
print(Unicode.Scalar(4352)!) // "ㄱ"
print(comparableScalar.value) // 12593분명 분해할 때는 "ㄱ" 에 해당하는 값이 4352 라는 십진수 숫자였는데, 이번에는 12593 이라는 숫자를 돌려주고 있습니다. 분명 똑같은 "ㄱ" 이지만 뭔가 다른 점이 있는 것이죠.
유니코드와 한글
둘의 차이를 이해하기 위해서는 유니코드에서 한글을 어떻게 이해하고 또 다루고 있는지를 알아야 합니다. 유니코드 공식문서(15.0 버전 기준)에 보면 775페이지(링크 pdf 기준 39쪽)부터 한글을 다루고 있는데요.
decomposedStringWithCompatibilityMapping 로 분해한 요소에 대응하는 유니코드는 Hangul Jamo: U+1100–U+11FF 에 해당하는 값이라는 것을 알 수 있고, Unicode.Scalar 생성자에 할당한 "ㄱ" 은 Hangul Compatibility Jamo: U+3130–U+318F 에 해당하는 값이란 것을 알 수 있습니다.


즉, decomposedStringWithCompatibilityMapping 메서드를 활용해 분해할 때는 Hangul Compatibility Jamo 가 아니기 때문에 둘을 비교했을 때 우리가 기대하는 대로 동작하지 않는다는 것이죠.
Outro
Unicode.Scalar 는 기본적으로 한글을 다룰 때 Hangul Compatibility Jamo: U+3130–U+318F 의 범위에 해당하는 유니코드 값들을 활용한다는 것을 알 수 있습니다. 그러나 한글을 분해하기 위해 적용된 메서드가 돌려주는 값은 위 범위의 값이 아닌 Hangul Jamo: U+1100–U+11FF 값입니다.
한글을 분해해서 원하는 대로 정렬해서 활용하기 위해서는 이 점을 잘 알아두면 좋을 것 같습니다. 이 글이 도움이 되었기를 바랍니다!
