초성을 아무리 더해도 카운트가 1로 뜬다고? (swift, Unicode Hangul Jamo & and Hangul Compatibility Jamo)
스위프트 공부

ㅇㅎㄱㅈㅁㄹㄷㅎㄴㄷㅋㅇㅌㄱㅇㅇㄲㅇ".count == 1????????
위 초성이 뭔지 궁금하시면 글을 읽어주세요. ㅋㅋㅋ
Intro
스위프트에서 한글 자모음을 분리하는 방법에 대해 블로깅한 적이 있습니다. 그때 스위프트가 자체적으로 제공하는 메서드를 활용하면 Hangul Jamo: U+1100–U+11FF 타입으로 분해가 되고, 그냥 스위프트에 바로 적은 자모음은 Hangul Compatibility Jamo: U+3130–U+318F 타입으로 인식한다는 것을 알 수 있었는데요.
오늘은 여기에 더해서 분해한 한글, 특히 초성을 분해하면서 알게된 내용을 짧게 다뤄보려고 합니다.
카운트가 1이라고?

"왜한글자모를더하는데카운트가일일까요" 라고 하는 문자열이 있습니다. 이 문자열의 초성만 분리해서 새로운 문자열을 만들었다고 해볼께요. 여러가지 방법이 있겠지만 저는 분해와 재결합을 쉽게 하기 위해 문자열을 배열로 바꾸어준 뒤에 reduce 메서드를 활용해 보았습니다.
import Foundation
let name: String = "왜한글자모를더하는데카운트가일일까요"
let nameArray = Array(name)
// 주어진 이름을 분해하고 이름의 초성만 뽑아 결합
let initial: String = nameArray.reduce(into: "") { characters, character in
guard let unicodeFirst = String(character).decomposedStringWithCompatibilityMapping.unicodeScalars.first else {
return
}
characters += String(unicodeFirst)
}
print(initial) // "ᄋᄒᄀᄌᄆᄅᄃᄒᄂᄃᄏᄋᄐᄀᄋᄋᄁᄋ"
print(initial.count) // 1이렇게 분해해서 재결합한 문자열의 길이는 과연 몇일까요? 기존 문자열의 길이가 18이니 이 문자열의 길이도 당연히 18이 될 거라고 추측해 볼 수 있습니다.
물론 결과가 그렇지 않기 때문에 이 글을 쓰고 있겠죠? 놀랍게도 initial.count 를 프린트해보면 전체 길이가 1로 출력되는 것을 알 수 있습니다.
여러가지로 실험을 해봤는데요. 이번에도 이 문제는 동일한 이유 때문이었습니다. Hangul Jamo 에 대응되는 유니코드의 초성을 활용하게 되면, 아무리 더해도 count 가 1이 되는 것이었죠. 별도로 초성을 직접 입력한 경우에는 기존에 기대한 것처럼 정상적으로 18이라는 카운트를 보여줍니다.
let chosung: String = "ㅇㅎㄱㅈㅁㄹㄷㅎㄴㄷㅋㅇㅌㄱㅇㅇㄲㅇ"
let chosungArray = Array(chosung)
let initial4: String = chosungArray.reduce(into: "") { characters, character in
characters += String(character)
}
print(initial4.count) // 18과연 복사붙여넣기를 한다면?
글을 작성하면서 흥미로운 점을 또 한가지 발견했습니다. 플레이그라운드의 콘솔 환경에 한글 자모와 한글 호환용 자모를 출력했는데요. 한글 자모의 초성을 복붙해 코드에 붙여넣기 하면 한글 자모로, 한글 호환용 자모를 복붙에 붙여넣기 하면 한글 호환용 자모로 인식을 하는 것을 확인할 수 있었습니다.
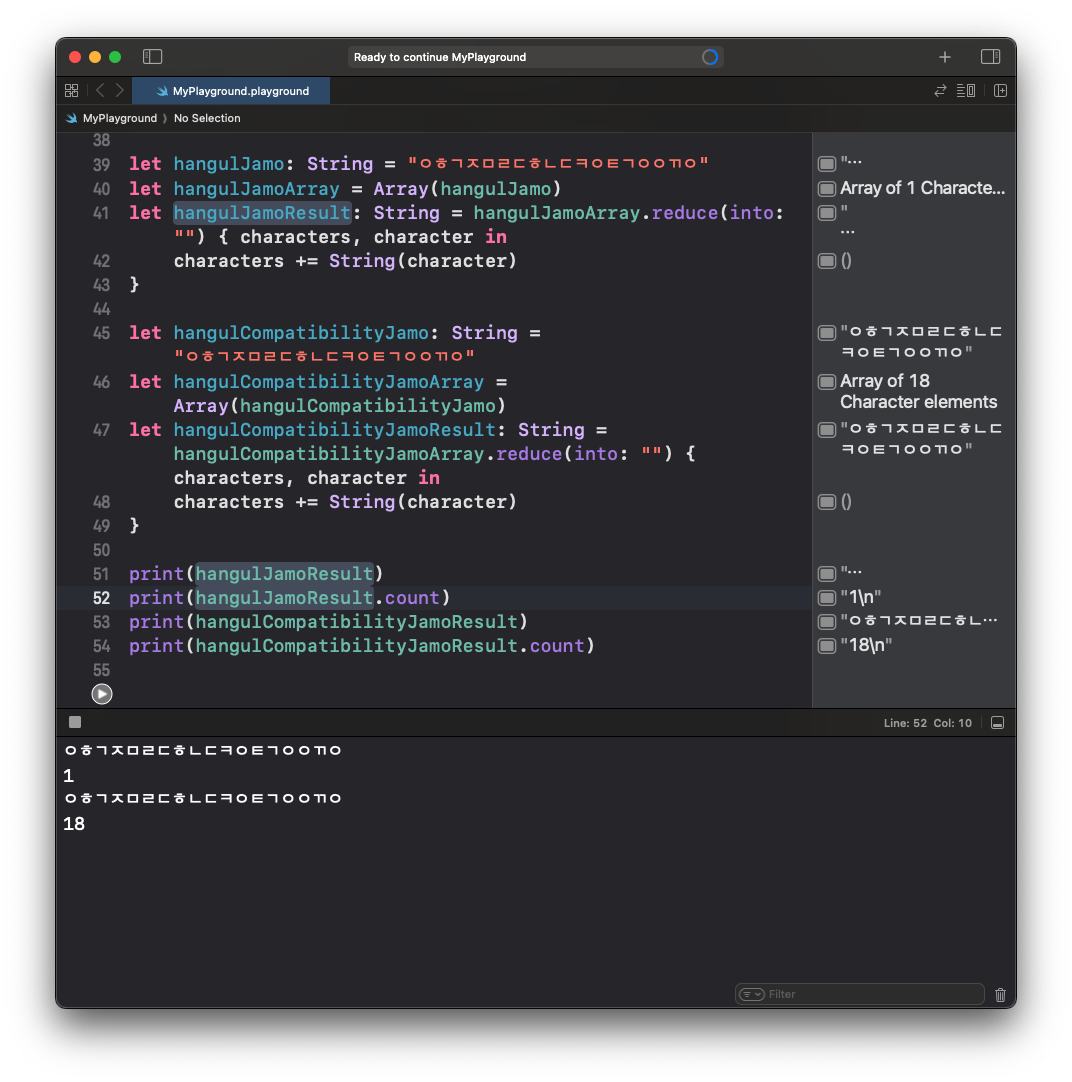
직접 테스트해보고 싶으신 분들을 위해 코드를 아래에 남겨두겠습니다.
let hangulJamo: String = "ᄋᄒᄀᄌᄆᄅᄃᄒᄂᄃᄏᄋᄐᄀᄋᄋᄁᄋ"
let hangulJamoArray = Array(hangulJamo)
let hangulJamoResult: String = hangulJamoArray.reduce(into: "") { characters, character in
characters += String(character)
}
let hangulCompatibilityJamo: String = "ㅇㅎㄱㅈㅁㄹㄷㅎㄴㄷㅋㅇㅌㄱㅇㅇㄲㅇ"
let hangulCompatibilityJamoArray = Array(hangulCompatibilityJamo)
let hangulCompatibilityJamoResult: String = hangulCompatibilityJamoArray.reduce(into: "") { characters, character in
characters += String(character)
}
print(hangulJamoResult)
print(hangulJamoResult.count)
print(hangulCompatibilityJamoResult)
print(hangulCompatibilityJamoResult.count)Outro
벨로그에 복붙해두면 과연 어떤 글자로 인식하게 될까요..? 브라우저 환경에서는 과연 이 두가지 자모를 분리해서 다루고 있는지 궁금하네요.
글을 올리기 전에는 알 수 없으니 저도 여기에 복붙해서 남겨만 보겠습니다.
한글 자모 : ᄋᄒᄀᄌᄆᄅᄃᄒᄂᄃᄏᄋᄐᄀᄋᄋᄁᄋ
한글 호환용 자모 : ㅇㅎㄱㅈㅁㄹㄷㅎㄴㄷㅋㅇㅌㄱㅇㅇㄲㅇ
과연 결과는...?

웹브라우저에서 복붙해서 가져와도 여전히 동일한 결과를 보여주네요!
혹시 다른 결과가 있으신 분이 있으시다면 공유해 주세요~!