- Transformer 구조를 활용한 language representation
- wiki data등 대용량 unlabeled data로 모델을 미리 학습시킨 뒤, 특정 task를 목적으로 하는 labeled data로 전이학습을 하기 위한 모델
- 이전의 언어모델은 undirectional하거나 shallow bidirectional하여 language representation이 부족함
- 특정 task를 해결하기 위해 추가적인 네트워크를 구성할 필요 없이 finetuning을 통해 해당 task의 SOTA 달성
Input
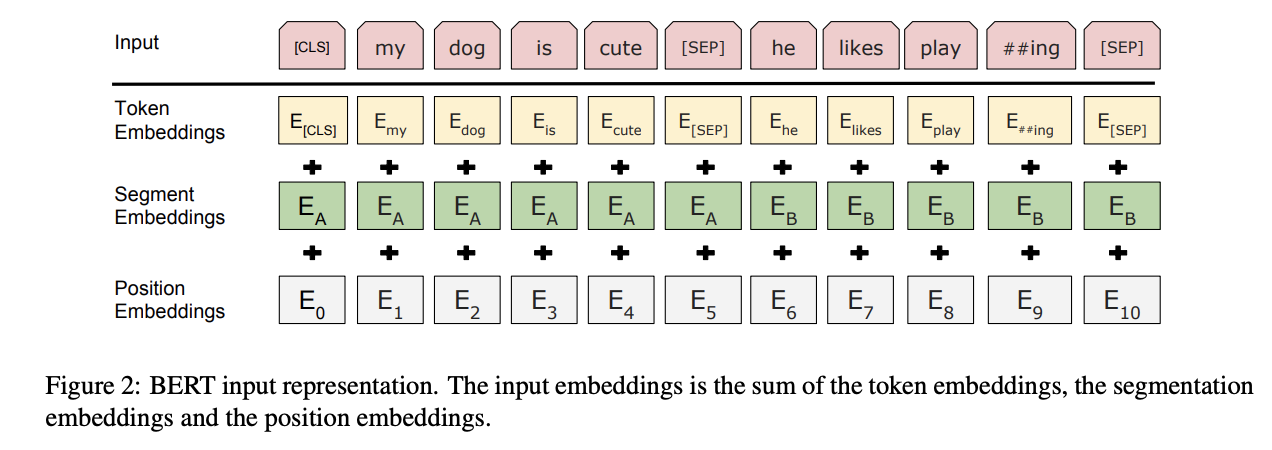
- token embedding Word Piece 임베딩 방식 사용 자주 등장하지 않는 단어는 분할하여 sub word로 만들어 사용
- segment embedding 문장에 대한 임베딩 두개의 문장을 [SEP] 토큰을 통해 분리하여 입력하는데 첫번째 문장(A)와 두번째 문장(B)에 대해 0/1의 임베딩 입력 기존 BERT는 하나의 세그먼트(두개의 문장)를 512 토큰으로 제한함
- position embedding 입력 토큰의 위치를 고려하는 임베딩 sin/cosin 함수를 사용한 임베딩으로 기존 트랜스포머에서 사용한 임베딩과 동일함
→ 위의 3가지 임베딩을 합쳐 사용하며 layer normalization과 dropout을 적용하여 입력으로 사용함
Pre-Training
-
사용 데이터
BookCorpus와 Wikipedia Data로 이뤄진 3.3억개의 대용량 corpus 사용
-
학습 과정
-
MLM
input 데이터 일부에 [MASK] 토큰을 활용하여 마스킹한 입력을 통해 학습
context만을 이용하여 masked된 단어의 id를 예측함
masking 기법
- 전체 문장에서 masking 대상이 될 15%의 토큰 선택
- 선택한 15%의 토큰 중
- 80% : [MASK] 토큰으로 대체
- 10% : 임의의 다른 단어로 대체
- 10% : 원래의 단어 그대로 놔두기
→ Transformer의 인코더는 어떤 단어를 predict해야하는지, 어떤 단어가 random word로 대체되었는지 알지 못함. 이를 통해 모든 토큰에 대해 distributional contextual representation가지도록 강제할 수 있음
→ random word로 대체되는 것은 전체 학습 데이터 중 1.5%에 불과함. 이는 모델의 language understading에 악영향을 미치기에는 역부족임
MLM의 목표 : 양방향의 context를 활용하여 representation이 가능하도록
이를 통해 deep bidirectional transformer의 pretraining 가능
- finetuning 에서는 [MASK] 토큰 사용하지 않음
-
NSP
두 문장이 주어졌을 때, 두 문장이 연결된 문장인지 아닌지 맞추는 방식으로 학습
MLM에서의 representation과 text pair representation을 합쳐서 학습에 활용
QA, NLI task는 language modeling으로 그 특징이 바로 capture되지 않기에 이를 위해 NSP task 추가
입력 데이터 중 50%는 IsNext 레이블을 갖는 연속된 문장, 50%는 NotNext 레이블을 갖는 연속하지 않는 문장
- 매우 간단한 학습 데이터 구성이나 QA, NLI에서 매우 유리하게 작용함
-
-
MLM, NSP의 중요성
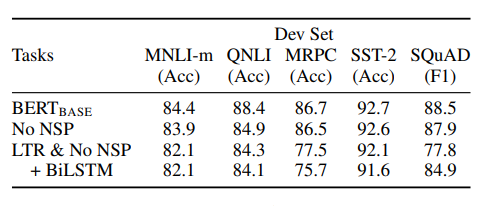
BERTbase : 12개의 레이어로 구성된 버트 베이스 모델
No NSP : BERT의 pretrain 과정 중 NSP 과정을 제외한 모델
LTR & No NSP : BERT의 pretrain과정 중 MLM & NSP 과정을 제외한 모델
LTR & No NSP + BiLSTM : BERT의 pretrain과정 중 MLM & NSP 과정을 제외한 모델에 bidirectional LSTM 구조를 추가한 모델
- BERT에서 제시한 MLM과 NSP task를 통해 양방향적인, context를 잘 담고있는 모델 학습을 해내었음을 확인할 수 있음
Transfer Learning
-
학습한 언어 모델을 전이 학습시켜 특정 NLP task를 수행하는 과정
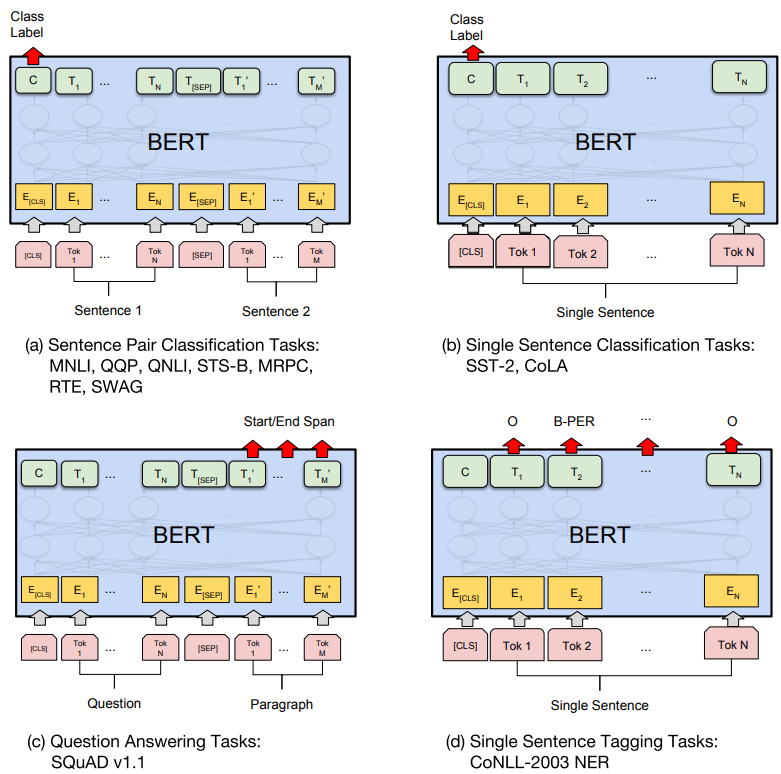
task에 따라 fine tuning 과정에서 사용하는 토큰의 구성이 상이함을 알 수 있음
ETC
- feature based approach with BERT
BERT 구조 전체를 학습시키는 것이 아니라 특정 단어에 대한 임베딩만을 추출하는 것이 가능한가?
→ 가능함!
ELMo와 같이 특정 문장만 입력하여 해당 문장의 임베딩 값만을 가져와서 사용하는 것이 가능함- 이를 통해 computational benefit을 얻을 수 있음
- 모든 task가 transformer encoder 구조로 쉽게 표현되는 것은 아니므로 task별 모델 아키텍처를 추가해야 하므로 이를 활용하지 않고 feature만을 추출할 수 있어야 함
