[NLP] ALBERT : A Lite BERT for Self-supervised Learning of Language Representations
DeepLearning
- BERT base, large 두가지 종류의 모델 존재 일반적인 language representation 모델은 layer 수, hidden size가 더 클때 보다 높은 성능을 보임 하지만 무작정 모델의 크기를 늘리는 것은 불가능 하며 부작용 또한 초래할 수 있음
ALBERT
Language Representation 모델의 크기가 클 때 발생할 수 있는 문제점
- Pretrained Language Representation 모델은 일반적으로 모델의 크기가 클 때 높은 성능을 보임
- 큰 모델로 먼저 학습하고 Knowledge Distillation과 같은 방식으로 모델 압축을 통해 모델의 크기를 줄이고는 함
- 모델의 크기를 무작정 키우는 것은 오히려 학습에 불리할 수 있음
- 메모리 부족
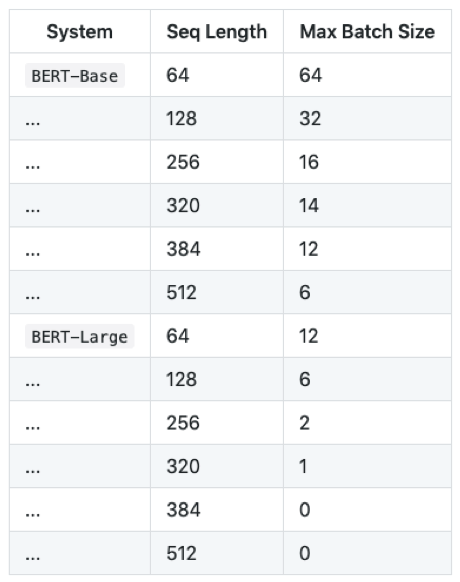
→ BERT large 모델의 경우 12GB의 GPU 메모리 사용을 가정할 때 Input sequence lengthrk 384 이상이 되면 학습은 물론 한 문장에 대한 inference도 불가능
- 매우 긴 학습 시간 소요
BERT 논문에 따르면,-
BERT base : 16개의 TPU로 4일의 학습기간 소요
-
BERT large : 64개의 TPU로 4일의 학습기간 소요
이를 GPU로 변경한다면,
-
BERT base : 16개의 V100 GPU 5일 이상의 학습 기간 소요
-
BERT large : 64개의 V00 GPU 8일 이상의 학습 기간 소요
-
- 일반적 사실과 달리 Language Representation모델 또한 너무 커지면 성능이 오히려 낮아지는 것을 실험으로 확인
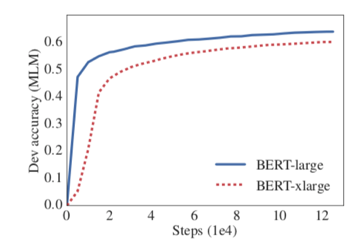
BERT large보다 hidden size가 2배 큰 BERT xlarge를 제작하여 실험 진행
-> 오히려 학습의 성능이 떨어지는 것을 확인할 수 있음
(논문에 성능 하락에 대한 원인 파악 없이 실험 결과만을 제시함)
- 메모리 부족
모델의 크기를 줄이고 성능은 높일 수 있는 방법 고안 필요
-
BERT 모델의 크기를 줄이기
-
fatorized embedding parameterization
-
BERT에서는 input token embedding과 hidden size의 크기가 동일함
-
ALBERT에서는 input token embedding size < hidden size로 설정하여 parameter의 수를 줄임
1) input token embedding은 입력 데이터의 각 토큰에 대한 정보를 담고 있는 벡터를 생성하지만 transformer 레이어의 output은 해당 토큰과 주변 토큰들 사이의 관계를 반영한 representation을 나타내므로 입력 임베딩이 보다 적은 정보량을 담고 있기 때문에 출력 결과물보다 크기가 작아도 된다는 것을 직관적으로 이해할 수 있음
2) 그러나 input token embedding과 hidden size의 크기가 달라지면 첫번째 trasnformer layer에서 차원이 맞지 않는 문제가 발생함. 이를 해결하기 위해 하나의 layer를 추가함.
→ 기존 BERT : Vocab size * Hidden Size를 활용하여 token embedding
→ ALBERT : Vocab size Input Token Embedding / Input Token Embedding Hidden Size 2개의 matrix를 연달아 곱하는 방식으로 Hidden Size의 토큰 임베딩 제작
→ BERT의 경우 Vocab size의 크기가 매우 크고, Input Token Embedding, Hidden Size의 크기는 작으므로 보다 적은 파라미터 수로 학습이 가능함 [Factorized Embedding]
-
-
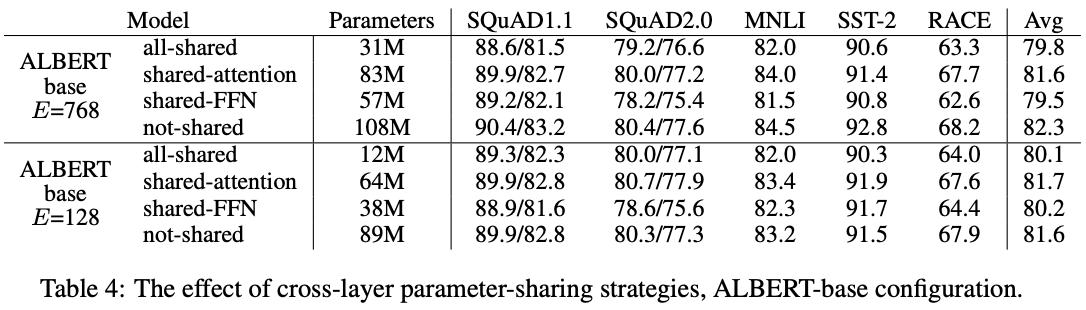
cross layer parameter sharing
-
transformer layer 사이에 같은 Parameter를 공유하여 사용하는 것
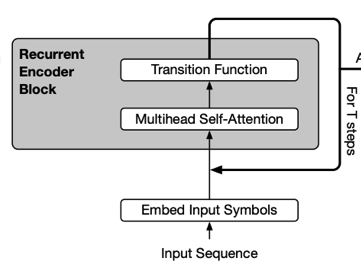
tranforemr 각layer의 결과물이 다시 입력으로 들어가는 형태, Recursive Transformer
-
논문에서는 실험 결과를 통해 layer간 파라미터를 공유하더라도 그 성능이 크게 떨어지지 않음을 밝혀냄. 그러나 feed forward network에서는 공유 시 성능이 다소 떨어지는 것을 확인할 수 있음
-
-
-
NSP보다 나은 학습 방식 고안
-
Sentence Order Prediction
→ 기존 NSP : 두번째 문장이 첫번째 문장의 다음 문장인지 유추하는 태스크로 학습 데이터 구성 시 절반은 실제 연속되는 문장, 나머지 절반은 임의의 문장으로 구성함. 이때 임의로 추출한 두번째 문장의 경우 첫문장과 완전이 상이한 주제의 문장일 가능성이 높으므로 문장 사이의 연관성에 대해 학습하기보다는 두 문장이 동일한 주제로 이뤄져있는지를 판단하는 topic prediction 태스크로 이해할 수 있음
→ SOP : 실제 연속인 두 문장과 그 문장의 순서를 바꾼 것으로 학습 데이터를 구성하여 문장의 순서가 올바른지 예측하는 방식으로 학습함. 이를 통해 기존 NSP에 비해 두 문장의 연관성에 대해 보다 잘 학습할 것이라 기대할 수 있음

→ SOP 학습 시 NSP에 대한 성능 어느정도 커버 가능하지만 NSP의 경우 SOP 태스크에 대해 낮은 성능 보이는 것을 확인할 수 있음.
→ 더불어 SQuAD, MNLI, RACE 등의 task에서 SOP를 적용할 경우 보다 높은 성능을 보임
-
