RT-DETR 연구
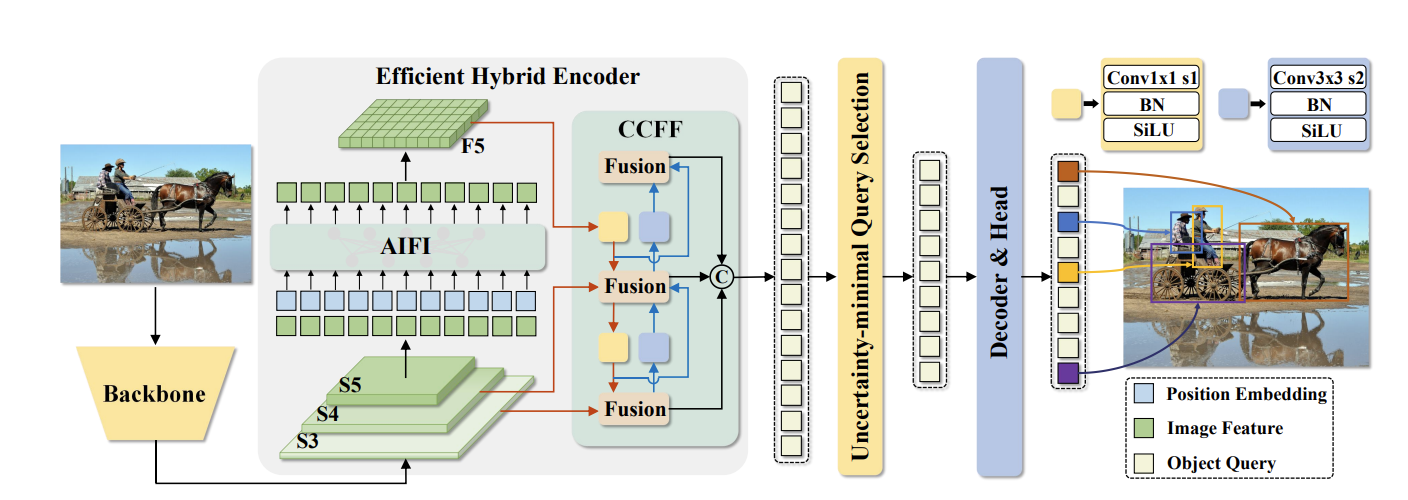
따라서 이번 프로젝트의 목적은 RT DETR에 대한 모델의 이해를 늘리고, 모델의 개선 방향성을 찾아 성능을 조금이라도 증가시키는 것이 목표이다. 그러기 위해선 RT DETR에 대한 핵심 아이디어에 대한 이해와 이를 개선하기 위한 방향성을 잡아야한다. RT DETR의 핵심 아이디어는 Efficient Hybrid Encoder와 Uncertainty-minimal Query Selection 2가지이다. Efficient Hybrid Encoder는 RT DETR이 참조한 모델인 Deformable DETR의 문제를 해결하기 위해 개발되었다. Deformable DETR은 Deformable attention으로 computation cost를 줄였지만, sequence length 문제로 인해 encoder에서 computation bottleneck문제가 발생하였다. 이를 해결하기 위해서 efficient hybrid encoder를 개발하여 이 문제를 해결하려고 하였다. 여러 유형의 인코더를 테스트해본 결과, Attention-based Intra-scale Feature Interaction (AIFI)와 CNN-based Cross-scale Feature Fusion (CCFF)인 2개의 모듈을 가지는 인코더가 가장 뛰어난 성능을 가졌다.
Uncertainty-minimal Query Selection는 DETR에서 object queries를 최적화하는 과정에서 불필요한 과정이나 부적합한 쿼리를 선택하는 경우를 줄이기 위해 개발하였다. 기존의 DETR에서는 인코더에서 confidence score을 기준으로 K개의 feature를 선택하여서 object query를 선정하였다. confidence score은 feature가 foreground object를 포함할 가능성을 나타내는데, 이 정보만 가지고 object query를 선정할 경우 category와 localization 정보가 정확하게 포함된 object query가 선정되지 않아 불확실성을 초래한다. 따라서 이 문제를 해결하기 위해서 feature uncertainty U를 정의하여 gradient-based optimization을 위한 loss function에 U를 추가하였다.
이 2가지의 메인 아이디어를 명확하게 이해하고 코드를 팔로우하면서 쿼리 선정이나 하이브리드 인코더에 개선할 방향이 존재한다면, 이를 개선하는 방향으로 연구를 진행할 예정이다
model : RT-DETR-R50
epoch : 6x
Backbone : Resnet-50
inputshape : 640 의 결과
$ torchrun --nproc_per_node=1 tools/train.py -c configs/rtdetr/rtdetr_r50vd_6x_coco.yml -r output/rtdetr_r50vd_6x_coco_from_paddle.pth --test-only
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.531
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.712
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.577
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.347
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.577
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.701
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.390
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.655
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.721
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.547
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.765
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.880
역시 small에 대한 detection이 정확하지 않은 것을 파악 가능. 우선 성능 증가를 위해 내가 train한 모델을 하나 만들어야함.
python3.9 tools/train.py -c configs/rtdetr/rtdetr_r18vd_6x_coco.yml
Epoch: [71][29570/29571] eta: 0:00:00 lr: 0.000010 loss: 9.3660 (9.3799) loss_vfl: 0.7792 (0.7815) loss_bbox: 0.1615 (0.1760) loss_giou: 0.3722 (0.4642) loss_vfl_aux_0: 0.8699 (0.8531) loss_bbox_aux_0: 0.1992 (0.1856) loss_giou_aux_0: 0.4030 (0.4820) loss_vfl_aux_1: 0.8318 (0.8109) loss_bbox_aux_1: 0.1796 (0.1778) loss_giou_aux_1: 0.3844 (0.4683) loss_vfl_aux_2: 0.8682 (0.8513) loss_bbox_aux_2: 0.2234 (0.2244) loss_giou_aux_2: 0.4359 (0.5448) loss_vfl_dn_0: 0.4438 (0.4500) loss_bbox_dn_0: 0.2672 (0.3017) loss_giou_dn_0: 0.5240 (0.5616) loss_vfl_dn_1: 0.3880 (0.3882) loss_bbox_dn_1: 0.1760 (0.2154) loss_giou_dn_1: 0.3984 (0.4445) loss_vfl_dn_2: 0.3738 (0.3725) loss_bbox_dn_2: 0.1626 (0.2014) loss_giou_dn_2: 0.3832 (0.4249) time: 0.2105 data: 0.0147 max mem: 3874
Epoch: [71] Total time: 1:44:10 (0.2114 s / it)
Averaged stats: lr: 0.000010 loss: 9.3660 (9.3799) loss_vfl: 0.7792 (0.7815) loss_bbox: 0.1615 (0.1760) loss_giou: 0.3722 (0.4642) loss_vfl_aux_0: 0.8699 (0.8531) loss_bbox_aux_0: 0.1992 (0.1856) loss_giou_aux_0: 0.4030 (0.4820) loss_vfl_aux_1: 0.8318 (0.8109) loss_bbox_aux_1: 0.1796 (0.1778) loss_giou_aux_1: 0.3844 (0.4683) loss_vfl_aux_2: 0.8682 (0.8513) loss_bbox_aux_2: 0.2234 (0.2244) loss_giou_aux_2: 0.4359 (0.5448) loss_vfl_dn_0: 0.4438 (0.4500) loss_bbox_dn_0: 0.2672 (0.3017) loss_giou_dn_0: 0.5240 (0.5616) loss_vfl_dn_1: 0.3880 (0.3882) loss_bbox_dn_1: 0.1760 (0.2154) loss_giou_dn_1: 0.3984 (0.4445) loss_vfl_dn_2: 0.3738 (0.3725) loss_bbox_dn_2: 0.1626 (0.2014) loss_giou_dn_2: 0.3832 (0.4249)
Averaged stats:
Accumulating evaluation results...
DONE (t=24.68s).
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.453
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.621
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.492
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.280
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.489
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.617
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.360
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.610
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.679
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.486
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.726
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.847
best_stat: {'epoch': 66, 'coco_eval_bbox': 0.4537000238011947}
Training time 5 days, 6:17:25
이 모델을 기준으로 실행. 커스텀 데이터셋 / 모델 변경하면서 실험할 예정
IoU와 GIoU에 대한 설명
https://silhyeonha-git.tistory.com/3
한줄로 간단히 요약하자면, 기존의 IoU는 교집합 / 합집합
으로 구한다.
이런 경우 GT와 bbox가 겹치지 않을 경우 어느 정도의 오차가 존재하는지 알 수 없어 gradient vanishing 문제가 발생한다. 이러한 문제를 해결하기 위해 등장한 방법이 GIoU이다.
GIoU: IoU - (GT와 bbox를 모두 포함하는 가장 작은 box를 구하고, 그 box에서 GT와 bbox의 합집합을 뺀 영역) 을 통해 구한다.
하지만 horizontal과 vertical에 대한 정보 표현이 없기에 수렴 속도가 느리고 박스가 부정확하게 예측되기에 이에 대한 정보를 포함한게 DIoU이다. (GT의 중심점과 Bbos에 대한 L2 거리, Bbox와 GT를 포함하는 최소 박스의 대각 길이 포함)
여기에 aspect ratio(종횡비)의 일치성을 추가한게 CIoU가 된다.
Opitmal matching
DETR은 Query, GT 에 대한 매칭을 hungarian biipartite matching 알고리즘으로 수행한다.
따라서, fixed-size의 N개를 prediction set으로 설정해야하고, 그 N의 크기는 dataset에서 한 image에 object 개수가 가장 많은 image의 개수보다 큰 N값을 가져야 한다.
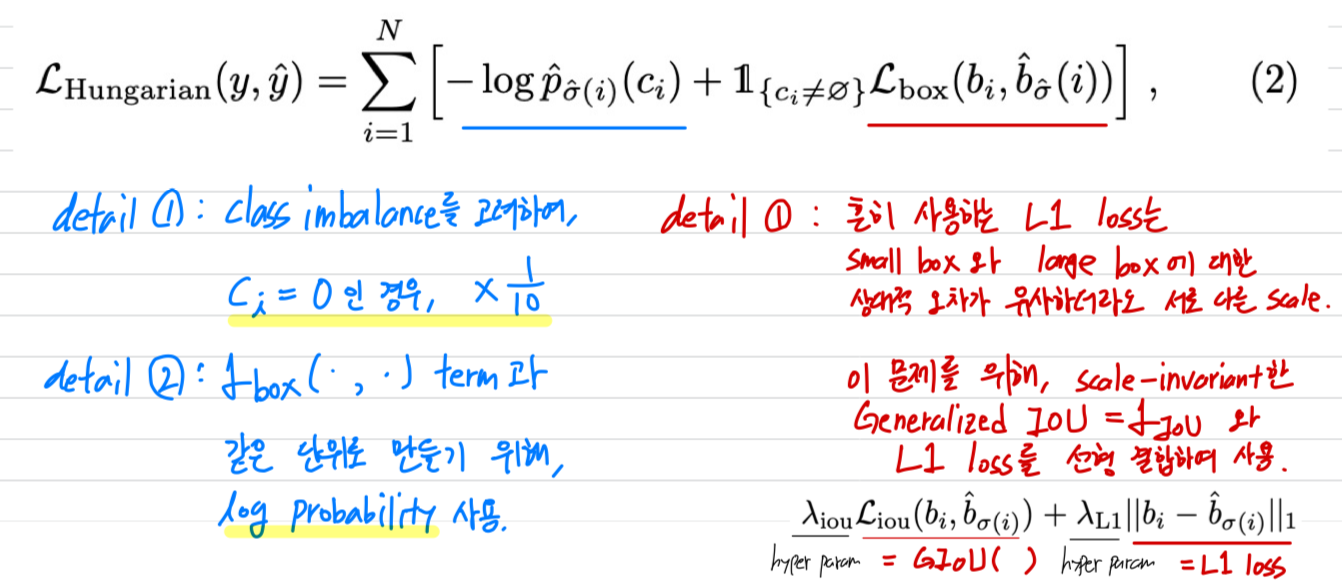
여기서 에 대한 수식은 L1 loss + GIoU loss를 통해 계산 된다. L1 loss는 실제 bbox와 예측한 bbox의 중심 좌표, 너비, 높이 등의 L1 distance 로 계산된다.
은 if 문으로 {}안이 참이면 1의 값을 곱하고, 거짓이면 0을 곱해서 를 계산하지 아니한다.
backbone
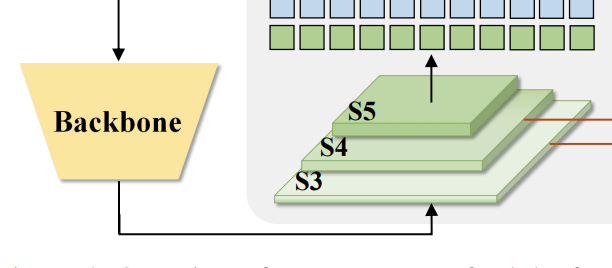
presnet50 을 이용해서 S3,S4,S5 의 feature들을 추출.
multi-scale features의 도입은 training convergence를 가속화하고 성능을 향상시킨다[45].
그러나 deformable attention이 computational cost를 줄여도,
급격히 증가한 sequence length로 인해 encoder가 computational bottleneck이 되는 문제는 여전히 존재한다.
Lin et al. [19]에 따르면, encoder는 GFLOPs의 49%를 차지하지만 Deformable-DETR에서 AP의 11%만 기여한다. (cost 증가에 비해 낮은 성능 증가)
이 bottleneck을 극복하기 위해, 우리는 먼저 multi-scale Transformer encoder에 존재하는 computational redundancy를 분석했다.
➡️ 직관적으로,
object에 대한 풍부한 의미 정보(rich semantic information)를 포함하는 high-level features가 low-level features에서 추출되기 때문에
연결된 multi-scale features들에 대한 feature interaction을 수행하는 것은 redundant를 만든다.
(s3,s4,s5 의 모든 feature에서 information에 대해 AIFI를 적용하는 것은 redundancy가 생긴다. 따라서 s5에서만 feature interaction을 수행하여 f5를 만든다.)


Conv 1x1, stride 1로 demension을 256으로 동일하게 만든다.
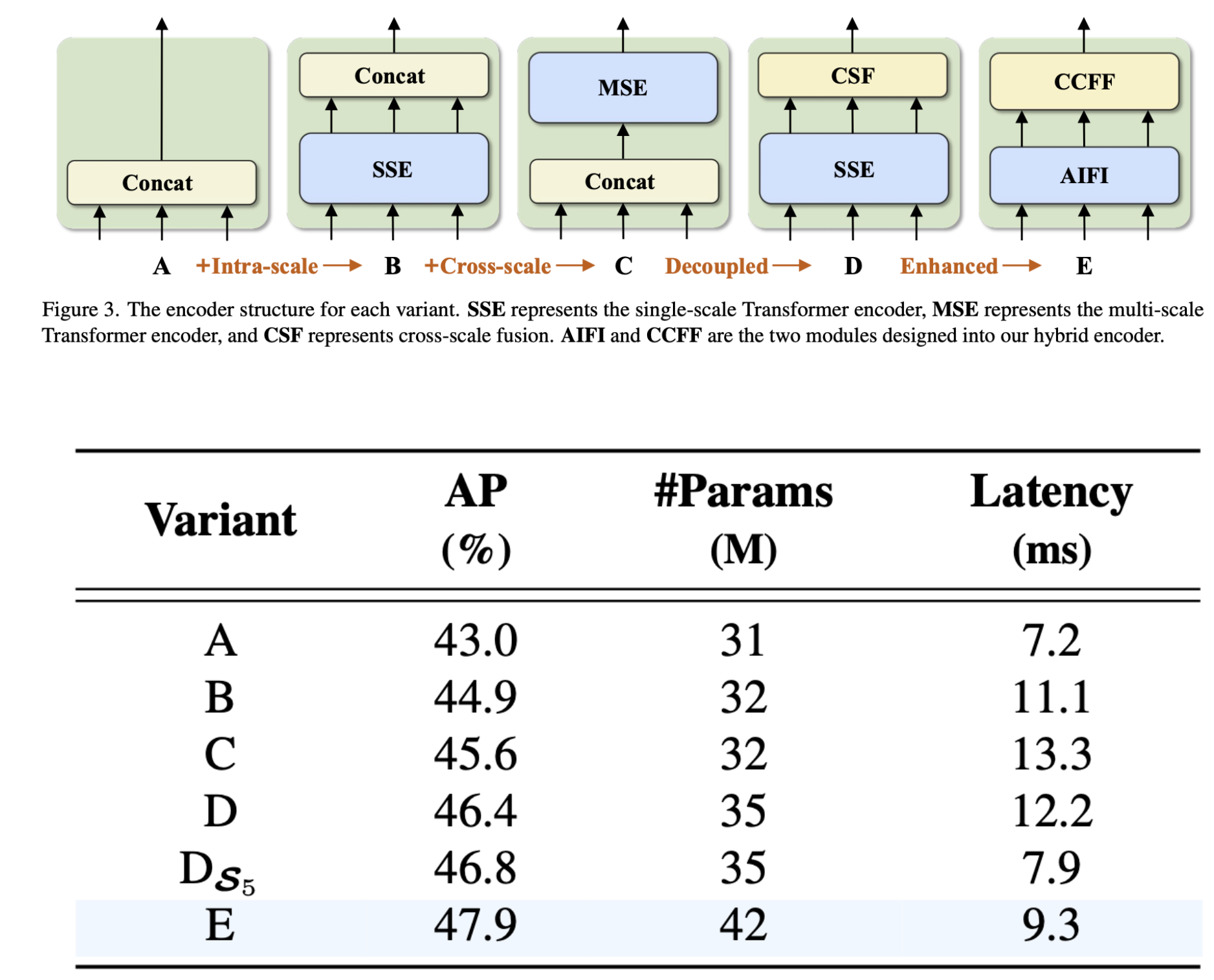
A : Transformer encoder in DINO-Deformable-R50
B : A에 single-scale Transformer encoder 삽입, encoder는 one layer of Transformer block 사용.
C : B에 cross scale feature fusion 도입.
D : intra-scale interaction에는 single-scale Transformer를,
cross-scale fusion에는 PANet-style structure를 사용하여
encoder를 decouple(분리)한다.
E : D를 기반으로 하고,
우리가 설계한 efficient hybrid encoder를 채택하여
D의 intra-scale interaction과 cross-scale fusion을 강화했다.
hybrid encoder
Attention-based Intra-scale Feature Interaction (AIFI)
구체적으로,
AIFI는 single-scale Transformer encoder를 사용하여 S5에서만 ntra-scale interaction을 수행함으로써
variant D를 기반으로 computational cost를 더욱 줄인다.
=> 가설 1) 그 이유는 더 풍부한 semantic concept을 가진 high-level features에
self-attention operation을 적용하면
conceptual entity들 간의 connection을 포착하여
subsequent modules이 object를 localization하고 recognition하는 데에 도움이 된다.
=>(가설 2) 하지만 low-level features의 intra-scale interaction은 semantic concept이 부족하고
high-level feature와의 duplication 및 confusion의 risk 때문에 불필요하다.
위 가설들을 증명하기 위해, 우리는 variant D에서 S5에서만 intra-scale interaction을 수행했다.
CCFF
cross-scale fusion module을 기반으로 optimized. 여러 conv layer로 구성된 fusion block을 fusion path에 삽입.
fusion block의 역할을 인접한 features를 새로운 feature로 fuse(융합). 구조는 Figure 5. fusion block 구조에 나와있다.
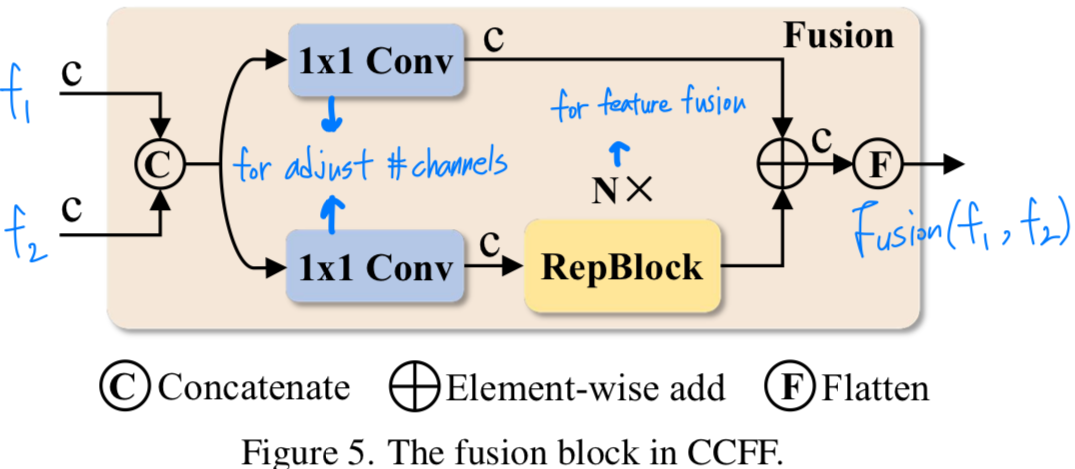
fusion block은 두 개의 1×1 convolution으로 channel수를 조절하고,
RepConv[8]를 구성하는 N개의 RepBlocks이 feature fusion을 위해 사용된다.
RepBlock
Re-parameterization Block.
training 시에 3x3 branch와 1x1 branch 연산을 거쳐 forwarding 된다. inference 시에는 1×1 branch와 residual connection이 제거되어 사용된다.
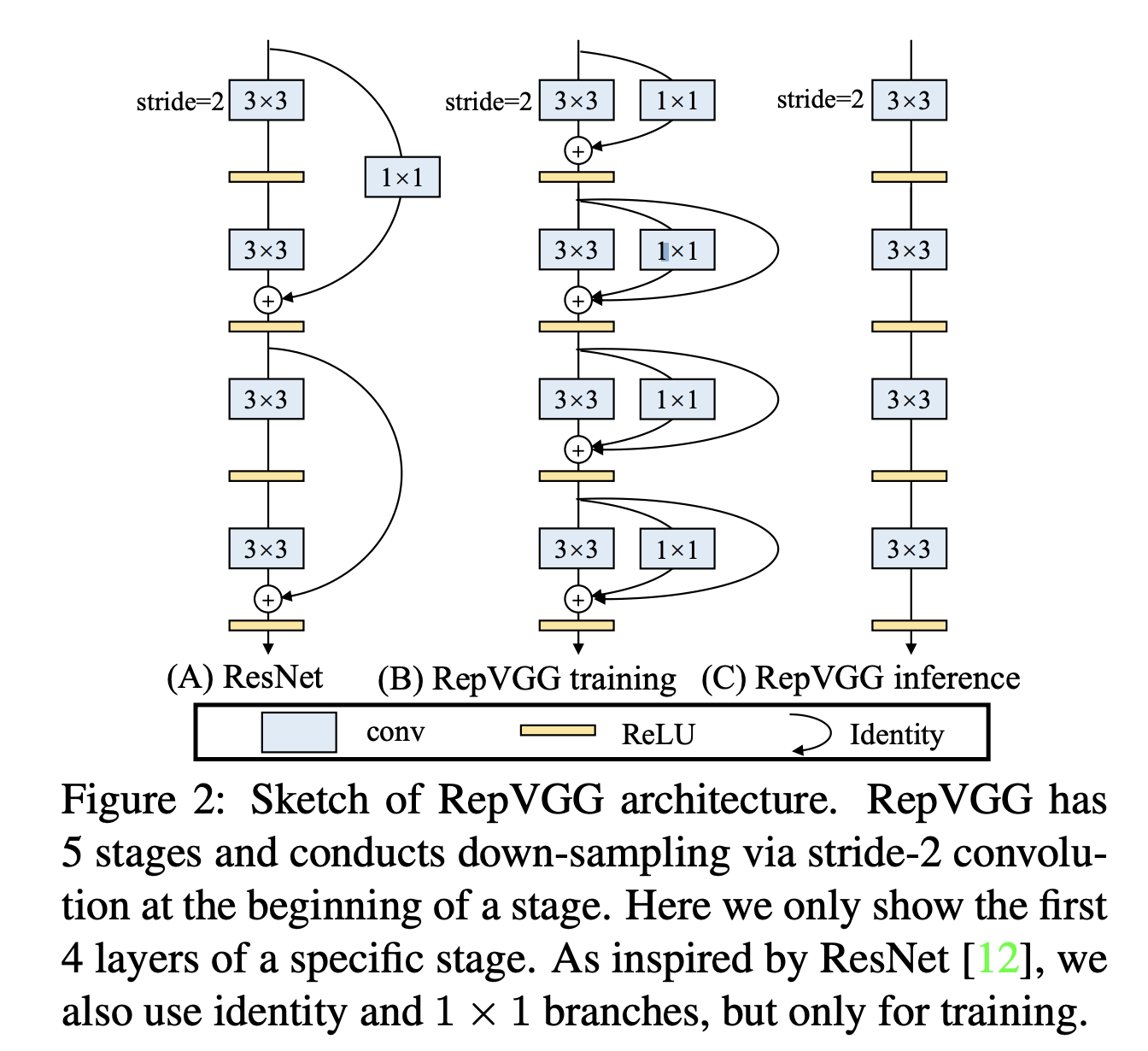
branch, convolution 차이
3x3 convolution인 경우, 3x3 kernel을 이용해서 feature를 파악하지만, 3x3 branch같은 경우 3x3 convolution을 포함한 여러 레이어를 포함하는 모듈임.

Flatten된 S5를 통해 Q,K,V를 추출
Q,K,V에 AIFI를 적용시켜서 F5 feature 생성
S3, S4, F5에 CCFF를 적용시켜서 최종 feature를 추출
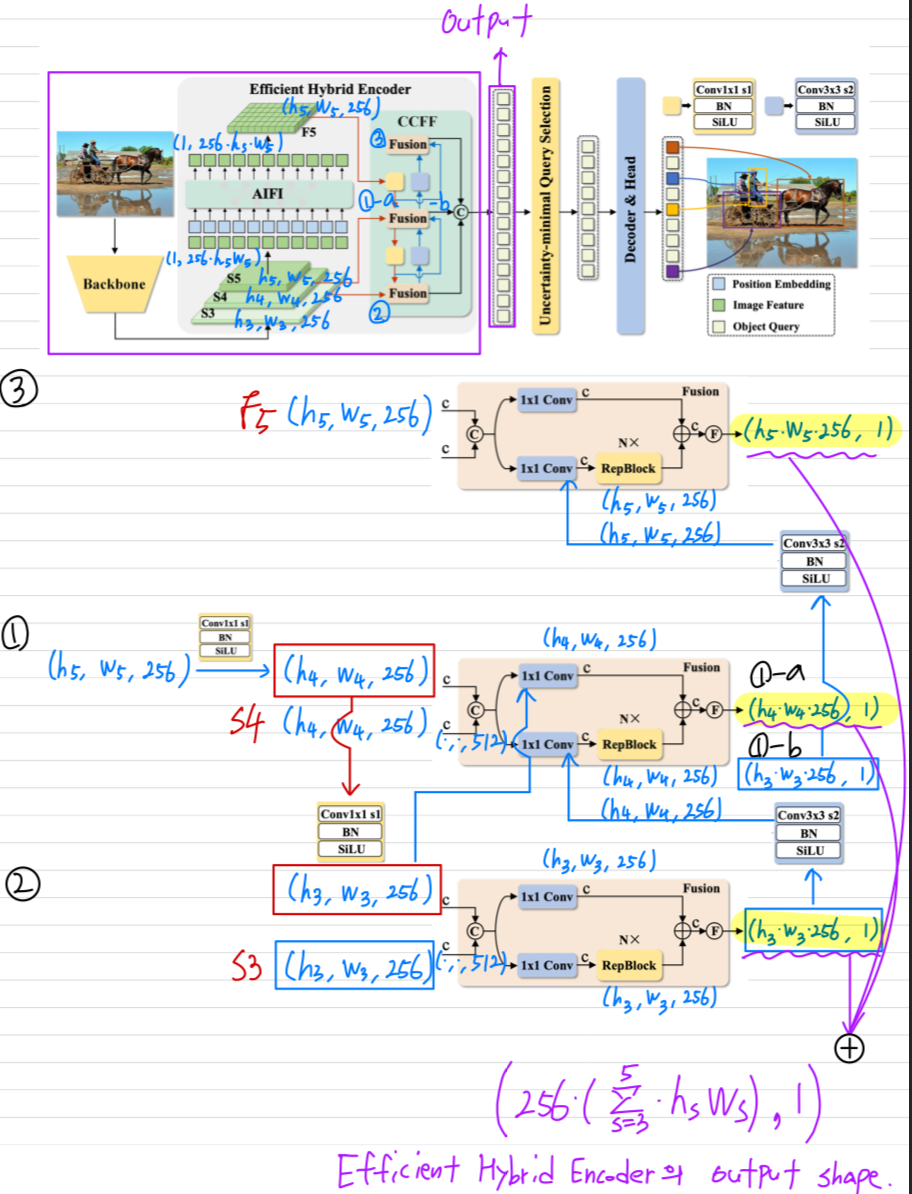
encoder code
backbone을 통해 feature map 추출 (차원은 1x1 conv를 통해 동일시 된다.)
S3 (H/8,W/8,256)
S4 (H/16,W/16,256)
F5 (H/32,W/32,256)
outs
shape :
value :
decoder
1. enc_topk_bboxes
input :
enc_topk_bboxes = F.sigmoid(reference_points_unact)reference_points_unact (encoder에서 추출한 참조점들을 이용해서 enc_topk_bboxes를 생성
Shape: [4, 300, 4]
배치 크기 4 (batch_size=4)
각 배치에 대해 300개의 상위 예측 박스 (num_queries=300)
각 박스는 4개의 좌표값을 가짐 (일반적으로 중심 좌표 cx, cy와 너비 w, 높이 h)
Values:
좌표값이 sigmoid 함수를 거친 결과로, 0~1 사이의 값.
예시:
첫 번째 박스: [0.0461, 0.7061, 0.0505, 0.0507]
중심 좌표 (cx=0.0461, cy=0.7061)
너비 및 높이 (w=0.0505, h=0.0507)
2. enc_topk_logits
input :
enc_topk_logits = enc_outputs_class.gather(dim=1, \
index=topk_ind.unsqueeze(-1).repeat(1, 1, enc_outputs_class.shape[-1]))
enc_outputs_class에서 상위 enc_topk_logits를 선택.
Shape: [4, 300, 80]
배치 크기 4
각 배치의 300개의 쿼리에 대해 80개의 클래스 점수를 포함 (80은 클래스 개수).
Values:
점수는 클래스별로 logits 형태로 표현되며, 값의 범위는 음수로 되어 있음.
예: [-4.1671, -3.5944, -3.9530, ..., -4.2104, -4.4524, -5.1099]
logits는 softmax를 거치지 않은 값으로, 상대적으로 큰 값이 높은 확률을 나타냄.
각 박스에 대해 80개의 클래스 점수 중 최댓값이 높은 것이 상위 클래스로 예측됨.
outputs :
if self.training and self.aux_loss:
out['aux_outputs'] = self._set_aux_loss(out_logits[:-1], out_bboxes[:-1])
out['aux_outputs'].extend(self._set_aux_loss([enc_topk_logits], [enc_topk_bboxes]))
out['aux_outputs']를 생성.
1. target 분석
target는 여러 샘플에 대한 정보를 포함하는 딕셔너리 구조이며, 주요 키와 값은 다음과 같습니다:
boxes:
객체의 바운딩 박스를 나타냅니다.
[x_center, y_center, width, height] 형식의 정규화된 좌표값입니다. 예를 들어, target[0]["boxes"]는 단일 객체의 바운딩 박스이고, target[1]["boxes"]는 여러 객체의 바운딩 박스 정보를 포함하고 있습니다.
labels:
각 객체의 클래스 레이블을 나타내는 텐서입니다.
예를 들어, target[1]["labels"]는 17개의 객체에 대한 클래스 정보를 담고 있습니다.
image_id:
각 이미지의 고유 ID입니다.
area:
각 객체의 바운딩 박스 면적입니다.
실제 면적으로 계산되어 있어 픽셀 수를 나타냅니다.
iscrowd:
객체가 군중(crowd)인지 여부를 나타내는 플래그입니다. 대부분 0으로 설정되어 있어 군중이 아닌 개별 객체임을 나타냅니다.
orig_size와 size:
원본 이미지 크기와 현재 이미지 크기를 나타냅니다. 예를 들어, target[0]["orig_size"]와 size는 (640, 480)으로 동일합니다.
- init_ref_points_unact 분석
Shape: [4, 490, 4]
4: 배치 크기
490: 각 배치에서 참조점의 수
4: 각 참조점의 속성 (x, y, width, height 또는 다른 특성)
Values: init_ref_points_unact는 주로 초기 참조점을 나타내는 텐서입니다.
각 값은 초기화된 좌표를 나타내며, 일부는 음수로 설정되어 보정이 필요함을 시사합니다.
각 샘플별 특징
target[0]:
단일 객체만 존재.
이미지 크기: (640, 480).
target[1]:
17개의 객체가 존재.
다양한 크기의 바운딩 박스를 가지고 있음.
이미지 크기: (500, 375).
target[2]:
19개의 객체가 존재.
객체의 크기가 다양한 분포를 가짐.
이미지 크기: (640, 427).
target[3]:
7개의 객체가 존재.
바운딩 박스 크기가 다른 샘플에 비해 상대적으로 크고 적음.
이미지 크기: (640, 480).
decoder
Layer 1 output:
이 값은 첫 번째 레이어의 출력을 나타냅니다. 이 출력은 텐서 형식으로 나타나며, 형태는 [4, 470, 256]입니다.
이 텐서는 4개의 배치(batch) 크기, 470개의 특성(feature), 그리고 256개의 값으로 구성되어 있습니다. 각 값은 네트워크의 필터가 입력에 적용된 후의 결과입니다. 이 출력은 모델의 피처 맵(특성 맵)으로, 다음 레이어에서 처리될 입력으로 사용됩니다.
Layer 1 predicted bbox (before inverse_sigmoid):
이 출력은 예측된 바운딩 박스(bounding box) 좌표를 나타냅니다. 이 텐서는 torch.Size([4, 470, 4])로, 4개의 배치에 대해 각각 470개의 바운딩 박스가 예측됩니다.
바운딩 박스는 보통 x_min, y_min, x_max, y_max와 같은 형태로 좌표가 나타납니다. 이 값은 아직 inverse_sigmoid 함수가 적용되지 않아서, 후속 단계에서 비율값을 나타내기 위한 변환이 필요합니다.
Layer 1 inverse_sigmoid(ref_points_detach):
이 출력은 ref_points_detach에 대해 inverse_sigmoid 함수가 적용된 결과입니다. inverse_sigmoid는 시그모이드 함수의 역함수로, 시그모이드의 출력값을 실제 값으로 변환하는 역할을 합니다.
이 값은 모델이 예측한 참조 포인트(reference points)들을 복원하는 과정의 일부입니다. 출력은 torch.Size([4, 470, 4])로, 각 배치에 대해 470개의 포인트에 대해 4개의 값이 있습니다.
Layer 1 inter_ref_bbox (after sigmoid):
이 출력은 바운딩 박스 예측에 시그모이드 함수를 적용한 후의 값입니다. 시그모이드 함수는 출력값을 [0, 1] 범위로 정규화합니다.
바운딩 박스 좌표가 시그모이드 함수 적용 후 비율 값으로 변환됩니다. 이 값은 후속 단계에서 실제 이미지 크기에 맞게 변환되어야 할 것입니다.
연구 내용
- rt detr 구조 파악
- 코드 분석 및 개선 방안 탐색 (query를 top_num : 300을 선택하는게 아닌, 다른 방법이 없을까)
- 그래서 SOTA 모델이 dfine 모델을 확인 후, bbox에 대한 확률 분포로 나타내고, 이를 decoder 모델에 적용시켜 볼려고 함. 모델의 enc_topk_bboxes
Shape: [4, 300, 4]
배치 크기 4 (batch_size=4)
각 배치에 대해 300개의 상위 예측 박스 (num_queries=300)
각 박스는 4개의 좌표값을 가짐 (일반적으로 중심 좌표 cx, cy와 너비 w, 높이 h)
enc_topk_binx,y,w,h
shape: [4, 300, 10]
좌표값이 sigmoid 함수를 거친 결과로, 0~1 사이의 값.
enc_topk_logits
Shape: [4, 300, 80]
실패 : 단순히 enc_top_bboxes, enc_topk_logits로 dec_out['pred_bboxes']가 구해지는 것이 아님. denoise, inter_ref_bbox,ref_points_detach 등 하나의 구조를 바꾸기 위해선 모든 코드의 수정이 필요.
- 따라서 rt detr에 dfine decoder를 연결해 구조를 만듬.input은 encoder의 feature map 구조만 변경하고, decoder의 outs는 추가적인 정보를 제공하고 형태는 동일.
의의 : 각 입출력들과 그 과정을 이해하고 값들을 변경을 해봄. 또한, decoder의 구조를 변경하면서 입출력을 맞춰봄.
