이전 편, error-c 라는 에러 메시지 관리 패키지를 만들었습니다.
이 편은 해당 패키지가 어떻게 만들어졌는지에 대한 이야기입니다.
이 패키지를 만들게 된 아이디어 계기
타입스크립트 공부 중 우연히 소스코드 중 이런 부분을 봤다.
type TSVersion = "4.1.2";
type ExtractSemver<SemverString extends string> =
SemverString extends `${infer Major}.${infer Minor}.${infer Patch}` ?
{ major: Major, minor: Minor, patch: Patch } : { error: "Cannot parse semver string" };
type TS = ExtractSemver<TSVersion>;아래 코드에서 TS 타입은 컴파일러가 어떻게 추존할까?
정답은 ["4", "1", "2"] 타입으로 추론한다.
무려 제네릭만으로 "4.1.2" 리터럴을 ["4", "1", "2"]형태로 전환한다.
이걸 이뤄내는 마법은 typescript의 infer 구문이다.
위 코드보다 간단한 기능을 구현하기 위해서 나는 다음과 같은 코드를 짯다.
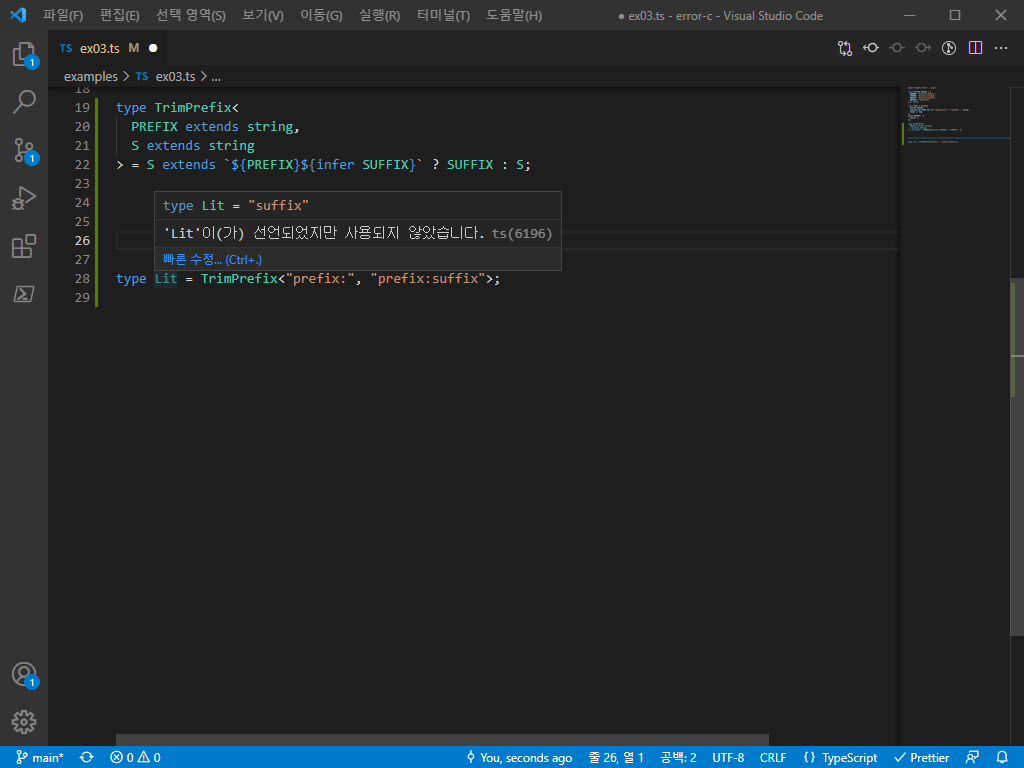
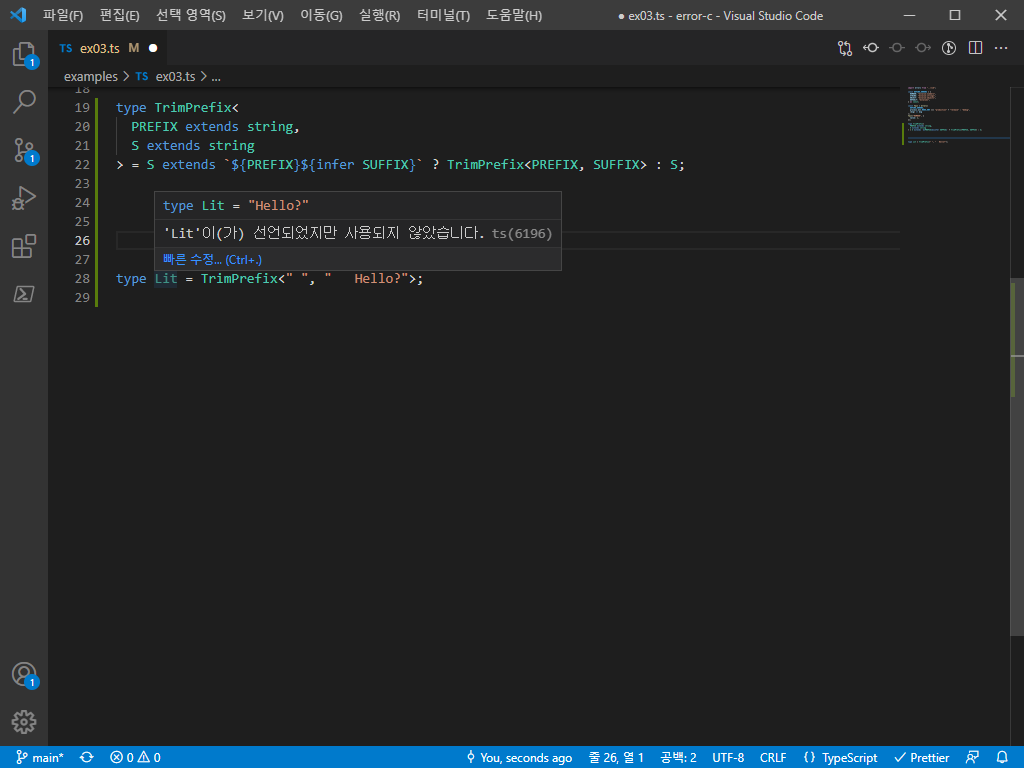
TrimPrefix는 접두사를 받아 없애주는 타입 제네릭이다.
위를 보면 이를 이용해서 원래 "prefix:suffix"였던 literal type을 suffix로 바꾸어 버린 것을 알 수 있다.
리터럴의 필드 정적 분석
위 infer 기능을 이용하면 이런 코드 작성이 가능해진다.
type ParseKey<S extends string> =
S extends `${infer PREFIX}\${${infer FIELD}}${infer SUFFIX}` ? FIELD : never;해당 식을 이용하면 ${}로 감싼 키를 얻을 수 있다.
여기서 이를 이용해 식을 계산해 보면
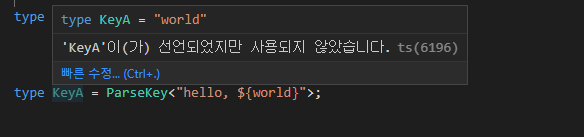
아래와 같이 문자열 타입에서 키 이름을 추출하는데 성공할 수 있었다.
이후 한 스트링에 여러 키가 있을 경우를 위해 ParseKey를 여러개 분석이 가능하도록
type ParseKey<S extends string> =
S extends `${infer PREFIX}\${${infer FIELD}}${infer SUFFIX}`
? FIELD | ParseKey<SUFFIX>
: never;이렇게 수정하면 여러 필드를 추출 가능해진다.
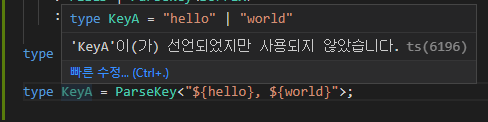
다만 아직 키에 문제가 있는데 ${} 사이에 띄워쓰기가 있으면 문제가 생긴다 아래 코드를 보자.
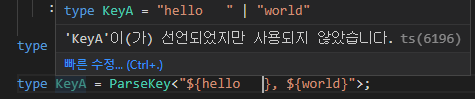
이를 없애기 위해서 다시 Trim이라는 함수를 만들어 보자.
type Trim<S extends string> = S extends ` ${infer SUFFIX}`
? Trim<SUFFIX>
: S extends `${infer PREFIX} `
? Trim<PREFIX>
: S;해당 타입 제네릭은 잘 안보이지만 앞 뒤로 띄어쓰기가 있는 경우 이를 재귀적으로 제거해 주는 타입이다.
이를 이용해 ParseKey를 고치면 이렇게 된다.
type ParseKey<S extends string> =
S extends `${infer PREFIX}\${${infer FIELD}}${infer SUFFIX}`
? Trim<FIELD> | ParseKey<SUFFIX>
: never;
type Trim<S extends string> = S extends ` ${infer SUFFIX}`
? Trim<SUFFIX>
: S extends `${infer PREFIX} `
? Trim<PREFIX>
: S;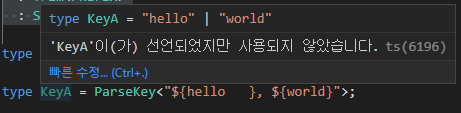
이제 키들은 띄어쓰기가 모두 제거된 채로 literal type의 union 이 된다.
이제 이것을 이용해 함수를 하나 만들 수 있는데 아래 함수를 보자.
function template<T extends string>(t: T, c: Record<ParseKey<T>, any>) { ... }해당 함수는 문자열 제네릭 T를 받아 해당 T를 ParseKey한 키를 지니는 Record 타입을 받게 만드는 함수이다.
이를 실제 사용한다면 T에 따라서 c가 어떻게 변할까?

위와 같이 c는 키로 hello, 혹은 world만 가질 수 있는 Record 타입이 된다.
Record는 typescript의 편의성 타입이다. 이는 여기서 찾을 수 있다.
이제 여기까지만 이해한다면 정적 리터럴을 이용해 매우 강력한 추론 기능을 구현 가능함을 알 수 있을 것이다.
다만 이 방법은 한계가 있다. 아래 코드는 의미상으로는 동일하지만 타입스크립트는 타입 추론을 할 수 없다.
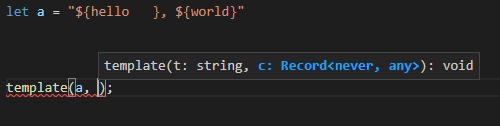
그러면 어째서 안되는 것일까?
아래 두 문장을 보자.
let a = "${hello }, ${world}";
const b = "${hello }, ${world}";간단한 타입스크립트 코드고 평범해 보이지만, 사실 둘은 타입은 다르다.
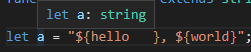
우선 let으로 선언한 변수는 타입이 string 타입이다.
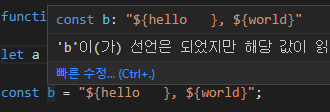
하지만 const로 선언한 변수의 타입은 자기 자신임을 알 수 있다. 즉 자기 자신의 리터럴이 자신의 타입이다.
일종의 문자 리터럴은
string의 부분집합? 혹은 요소라고 이해하면 될 것 같다.
여기서 큰 차이가 생기는데 바로 문자열의 내용으로부터 필드를 추론하기 위해서는 컴파일 타임에 문자열을 알 수 있어야 한다는 것이다.
타입스크립트는 const 변수들은 정적 컴파일 타임에 타입을 자기 자신으로 추론한다.
이 덕분에 위의 코드들은 동작하는 것이다.
주의사항
const a = {
b : "b-string",
}여기까지 온 분들은 이제 이 a 상수는 타입이
type A = {
"b" : "b-string",
}라고 생각할 지도 모른다. 그런데 그렇지 않다.
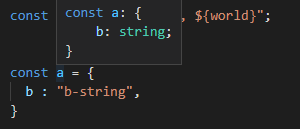
의도적인 컴파일러 동작으로 const는 object 안의 필드까지 const로 추론해주지 않는다.
이때 필요한 것이 타입스크립트 3.4 에 추가된 as const 키워드, 즉 constants assertion 이다.
이제 해당 문법을 적용해 a를 고치면 다음과 같다.
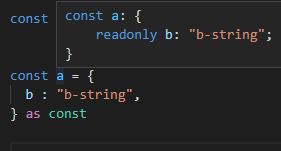
이제 a는 우리가 예상한 대로의 타입을 가지게 된다.
여기서 const 내부 필드가 const 가 아닌 이유를 추측할 수 있는데, 우리가 const object를 선언할 때는 주로 싱글톤 같은 이유로 const 변수를 선언하는데 만약 내부 필드가 모두 readonly라면 코딩에 제약이 생겨 불편할 것이다. 아무래도 개념적인 접근보다는 프로그래머 편의를 위해 이렇게 정의했을 것이라고 추측할 수 있다.
오브젝트의 키에 따른 리터럴 분석
type EachTemplate<T extends Record<string, string>> = {
[K in keyof T]: ParseKey<T[K]>;
};위의 코드를 살펴 보면 T 타입을 받아 해당 타입이 키-값 구조가 string-string일 경우에 각 필드를 ParseKey 로 변환한다.
즉 Array.map을 타입에 적용해 준다.
이러면 아래 코드의 경우 최종 추론되는 a의 타입은 다음과 같다.
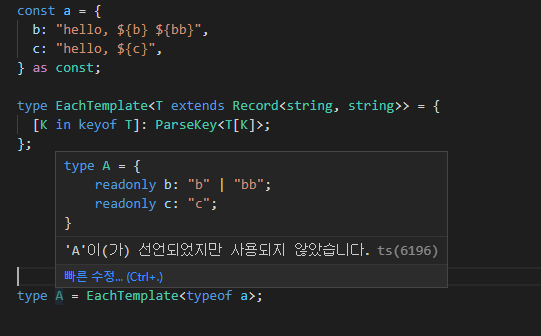
이제 이 타입을 이용해 미리 정의된 const object로 부터 메시지를 만드는 함수를 구상한다고 해 보자.
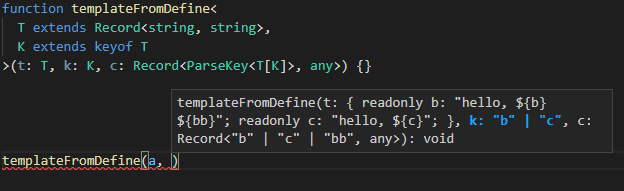
코드에서 보다시피, k는 b | c로 추론되고 c는 다양한 키가 모두 나오는데 이는 K가 추론되고 나면 자동으로 타입이 고정된다.
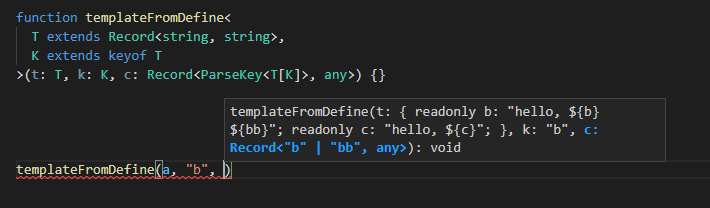
편의 기능, 메시지 생성 함수 만들기
위 함수도 충분히 사용 가능하지만, 보통 메시지 템플릿은 잘 변하지 않는다.
따라서 템플릿을 고정으로 만들어 주는 제네레이터 함수가 있다면 편리할 것이다. 그러니 아래 함수를 만들어 보자.
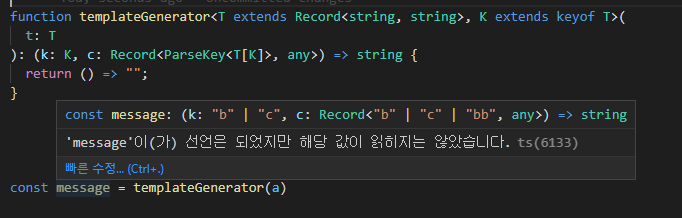
위와 같이 코드를 구성하면 키는 정의의 키만 사용하고 컨텍스트에 키에 따른 오브젝트를 사용하게 만드는 함수를 생성할 수 있게 만드는 함수를 제작 가능해 진다.
정말 타입스크립트는 독특한 언어같다.
이 코드와 유사한 코드를 짤 수 있는 언어는 내가 아는 한, c++와 rust 밖에 없다.
그리고 그 두 언어는 매크로나 전처리기, 템플릿 같은 일종의 빌드 스크립트적인 느낌으로 코드를 자동생성해주는 느낌에 가깝지, 이렇게 문법적으로 추적한다같은 느낌은 아니였다.
물론 지금은 언어적인 제약이라던가 불편한 점이 있지만, 지금 만으로도 에러라던가 실수를 막을 수 있는 유용한 테크닉으로 예상된다.
자바스크립트에는 literal template가 있으니 템플릿 라이브러리에 필요는 없겠지만 i18n 이라던가, 에러 메시지같은 통합된 한 파일에서 많은 템플릿이 와야 하는 경우에는 매우 유용하게 쓸 수 있을 것이라고 생각한다.
