안녕하세요.
오늘은 유니온 파인드(Union-Find) 알고리즘에 대해 알아보고, 직접 구현해보는 시간을 갖도록 하겠습니다.
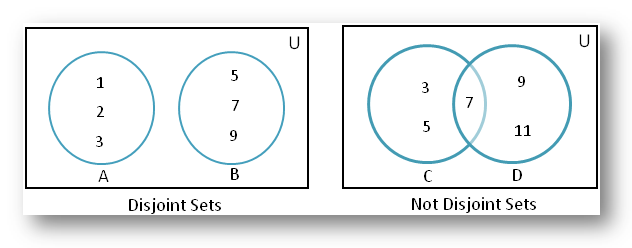
유니온 파인드?
유니온 파인드(Union-Find)는 서로소 집합을 표현할 때 사용하는 그래프 알고리즘으로, 임의의 두 노드(원소)가 서로 같은 그래프(집합)에 속하는지 판별하는 알고리즘입니다.
이때 서로소 집합(Disjoint-Set)이란 공통 원소가 없는 "상호 배타적인" 부분집합들로 나눠진 원소들에 대한 정보를 표현하는 자료구조입니다.
유니온 파인드의 주요 연산
유니온 파인드는 두 개의 그룹을 하나로 합치는 Union 연산과, 어떤 원소 x가 속한 그룹을 알아내는 Find 연산으로 이루어집니다.
- Union(x, y) : 와 가 속한 두 개의 집합을 합침.
- Find(x) : 가 속한 집합의 대표 원소(루트)를 찾음.
Union 예시

처음에 자기 번호를 그룹 번호로 갖는다고 해보겠습니다.

-
Union(1, 5) == 1번 원소가 속한 그룹에 5번 원소가 속한 그룹을 합치기.
-> 5번 원소의 그룹을 1로 바꾸기 -
Union(2, 3) == 2번 원소가 속한 그룹에 3번 원소가 속한 그룹 합치기.
-> 3번 원소의 그룹을 2로 바꾸기
이 상태에서, 1번 원소가 속한 그룹과 3번 원소가 속한 그룹을 Union하면 어떻게 될까요?

- Union(1, 3) == 1번 원소가 속한 그룹에 3번 원소가 속한 그룹 합치기.
-> 3번 원소는 2번 원소와 그룹이기 때문에, 2번 원소도 1번 그룹으로 바꿔야 함.
트리 구조로 살펴보기
유니온 파인드 알고리즘의 핵심은 각각의 집합을 하나의 트리로 나타내는 것입니다.

실제로는 처음에 그룹 번호를 -1로 초기화 합니다. -1은 루트 노드임을 뜻합니다.
Union(1, 5)
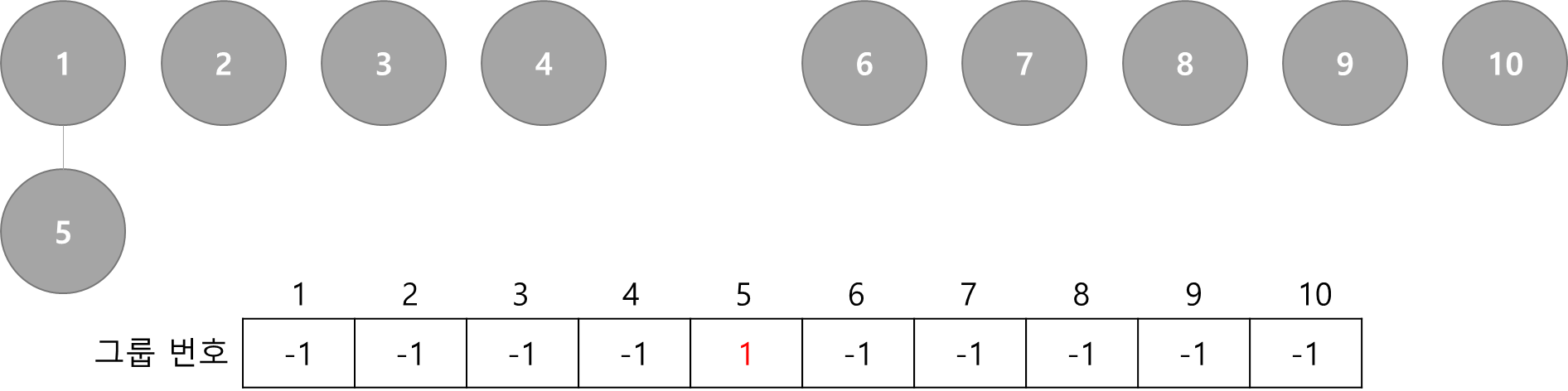
- 5번 원소가 속한 그룹을 1번 원소가 속한 그룹으로 합치기
Union(2, 3)
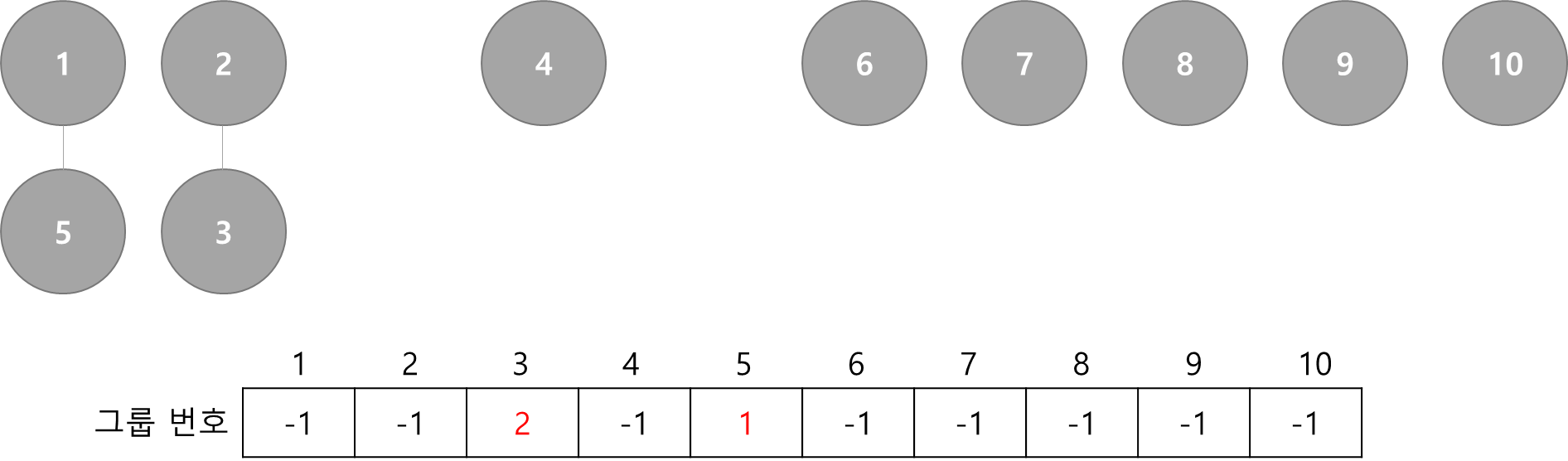
- 3번 원소가 속한 그룹을 2번 원소가 속한 그룹으로 합치기
Union(1, 3)
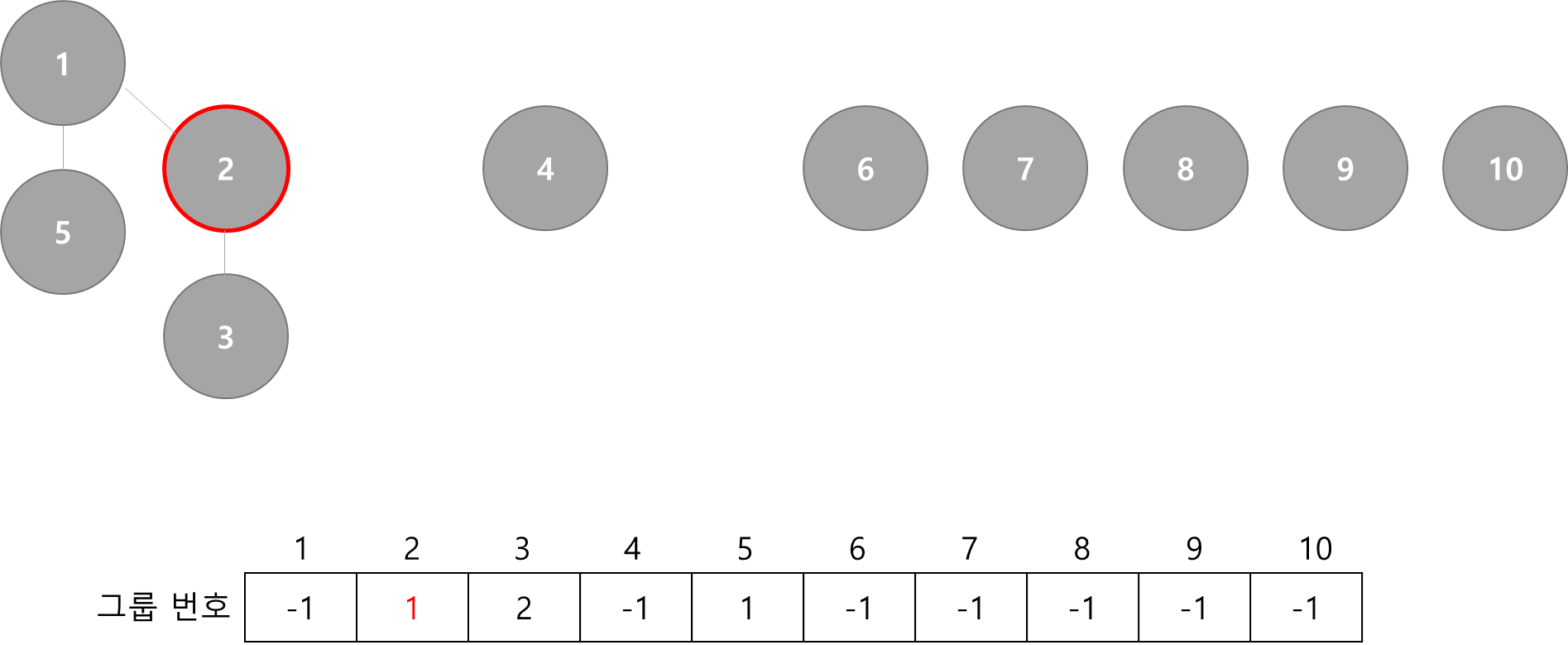
- 3번 원소가 속한 그룹을 1번 원소가 속한 그룹으로 합치기
- 3번의 대표(루트)를 1번의 대표(루트)에 합치면, 3번 그룹에 속한 모든 노드를 바꾸지 않고 그룹화 할 수 있음
Union(1, 6)
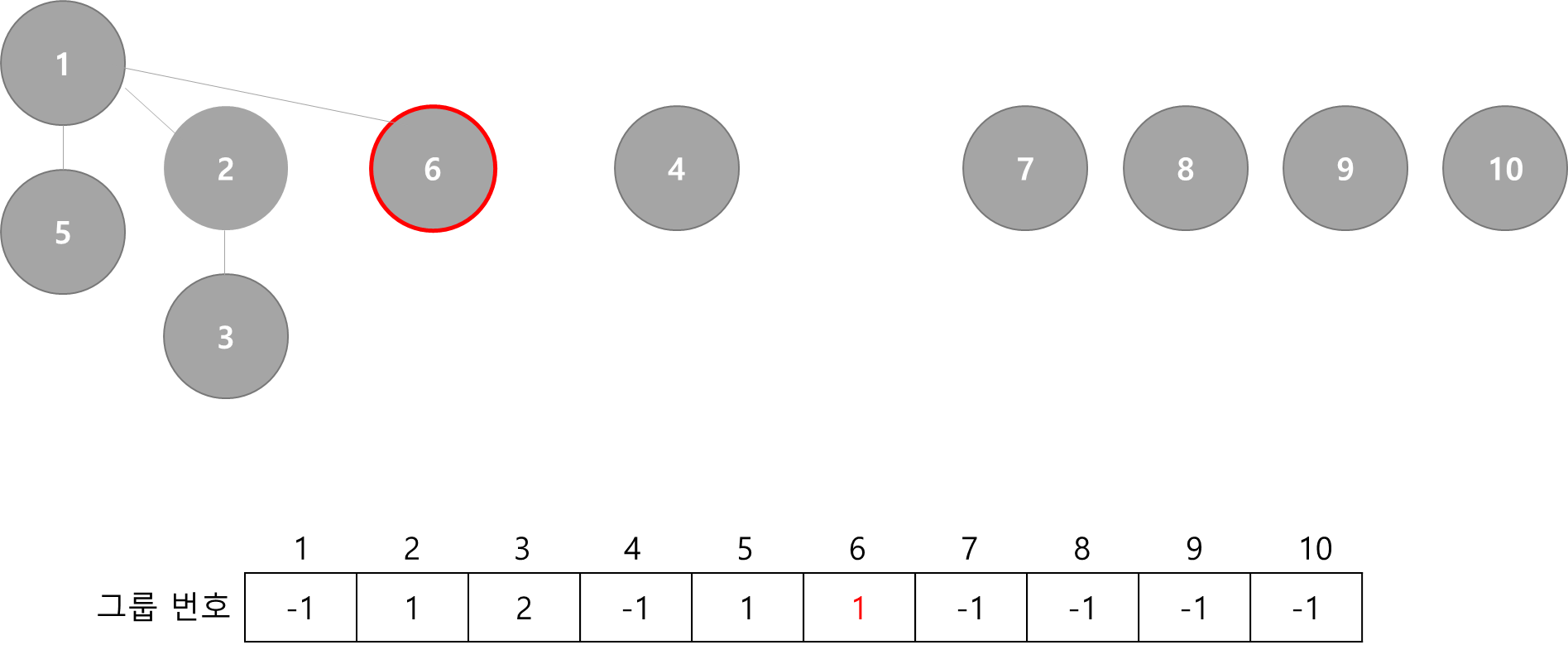
- 6번 원소가 속한 그룹을 1번 원소가 속한 그룹으로 합치기
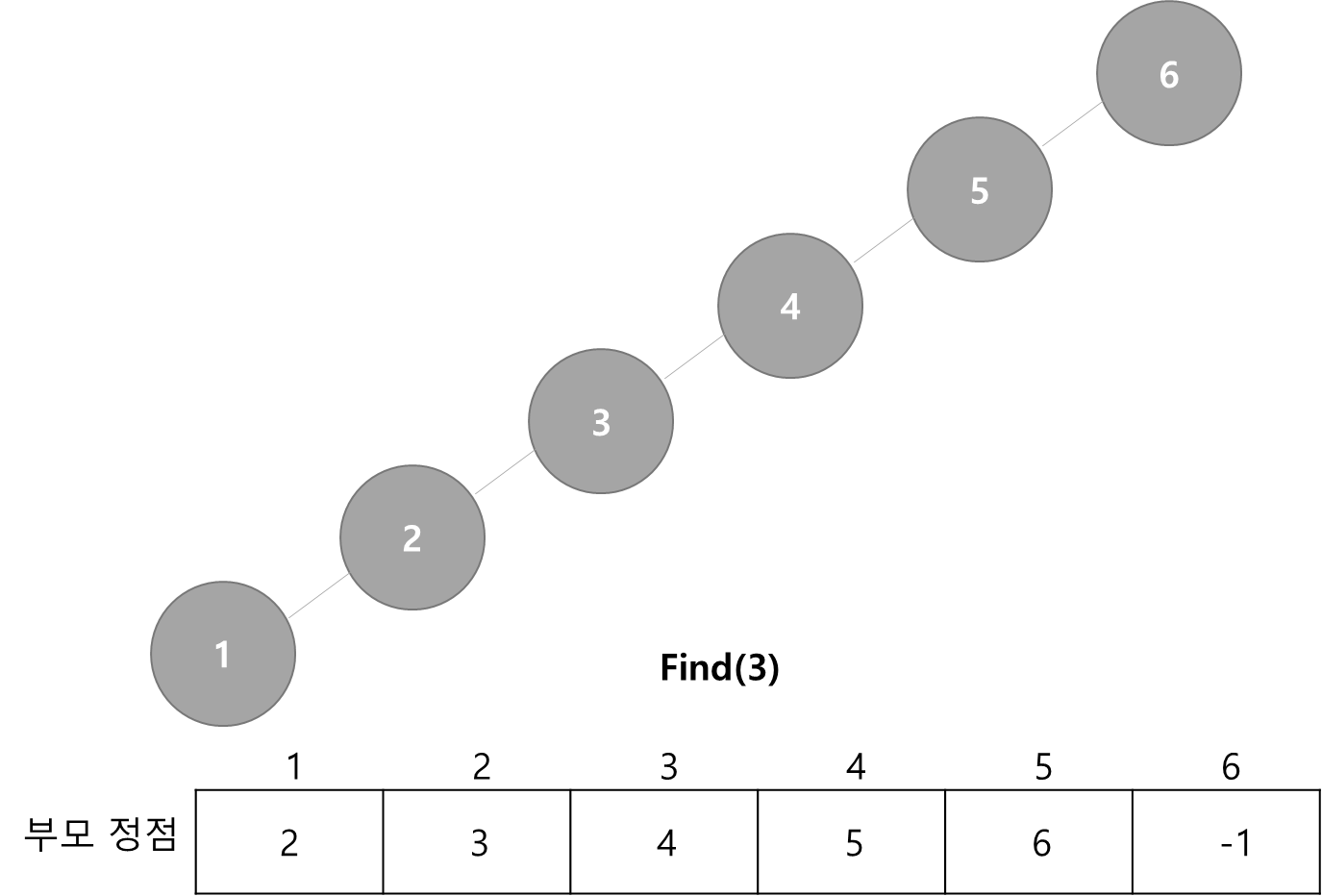
Find(3)
- 3번 원소부터 부모 노드를 타고가다보면 -1을 만나는데, 그룹 번호가 -1인 노드가 루트 노드임
- 이 루트 노드의 번호를 그룹 번호로 출력
코드 구현
vector<int> p(11, -1);
int find(int x){
while(p[x] > 0){
x = p[x];
}
return x;
}
bool uni(int x, int y){
u = find(x);
v = find(y);
if(u == v) return false;
p[v] = u;
return true;최악의 경우 시간복잡도
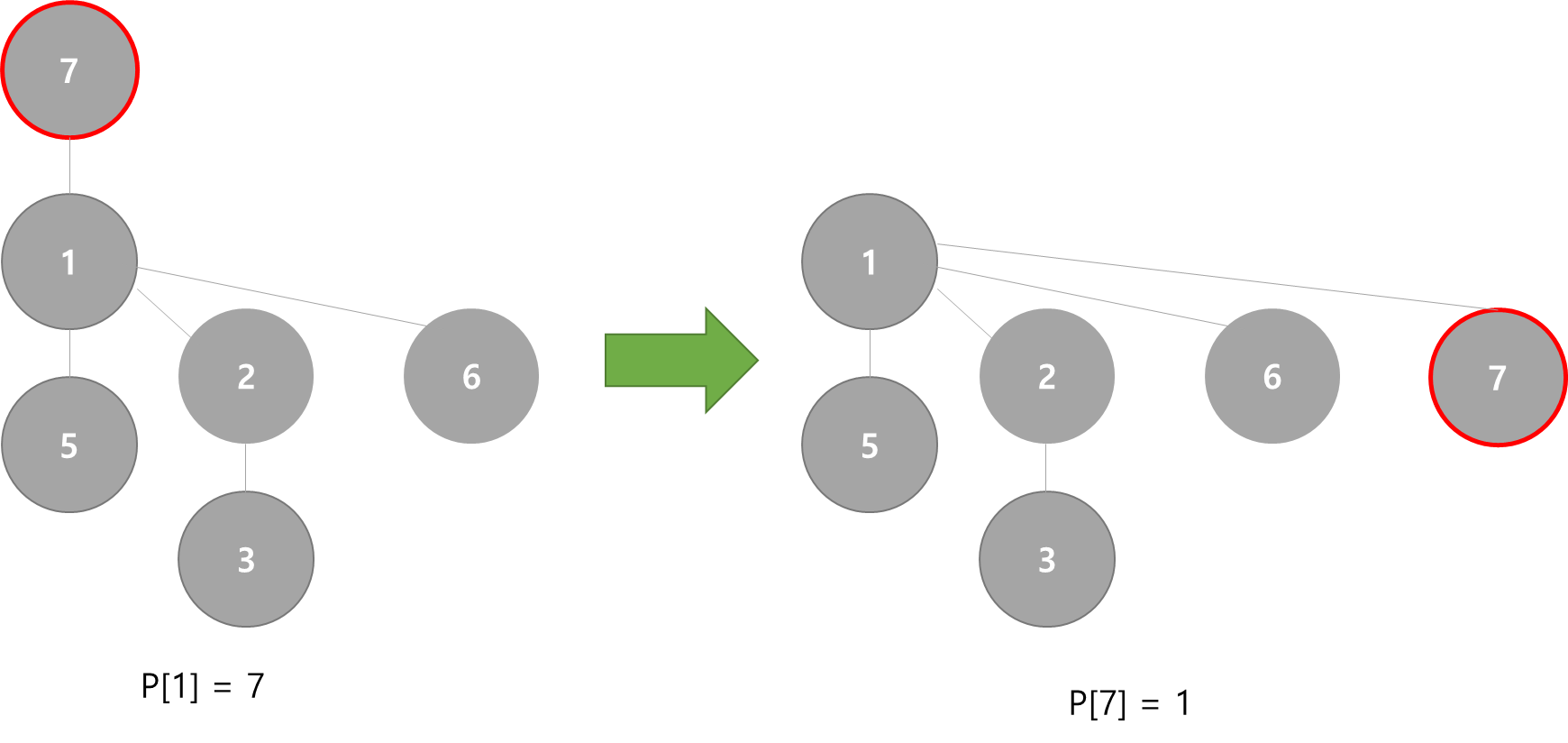
앞에서 구현했던 것처럼 직관적으로 union을 하면, 위 그림과 같은 불균형한 트리 구조가 만들어질 수 있습니다. 이러한 구조는 Find 시 의 시간복잡도로 동작합니다.
최적화를 위한 두 가지 방법으로, union by rank와 경로압축이 있습니다. 이 둘을 적용해야만 효율적으로 Union-Find를 구현할 수 있게 됩니다.
최적화1 : union by rank
- 두 그룹을 합칠 때, 더 작은 랭크(트리의 높이와 비슷한 가상의 개념)를 가진 그룹을 더 큰 랭크를 가진 그룹 아래로 붙이는 방법
- 이를 통해 트리가 깊어지는 것을 방지할 수 있음
예) Union(7, 2)
- 기존 방법은 7 아래에 2가 속한 그룹을 붙임
- 그런데 2가 속한 그룹 아래에 7을 붙이면 트리의 높이가 깊어지는 것을 방지할 수 있음
구현
- 이를 위해 각 루트 노드는 랭크를 기록하고 있어야 함.
- -1이 초기 상태이고, 랭크가 깊어질 때마다 -2, -3... 이렇게 기록하면 편함.
- 랭크 배열을 따로 만들어도 됨.
bool uni(int x, int y){
u = find(x);
v = find(y);
if(u == v) return false;
if(p[v] < p[u]) { // v의 랭크가 더 큰 경우(음수니까)
swap(u, v)
}
// 이제 랭크는 u >= v 임
if(p[u] == p[v]) {
p[u]--; // 랭크가 같으면 붙였을 때 랭크가 1 증가함
}
p[v] = u; // v를 u의 자식으로 만들기
return true;최적화2 : 경로 압축
- 예를 들어 위 그림에서 Find(3)을 한다고 하자
- 루트로 이동하면서 만나는 모든 노드의 정점을 6으로 수정하자.
- 그럼 다음과 같이 바뀌게 된다.
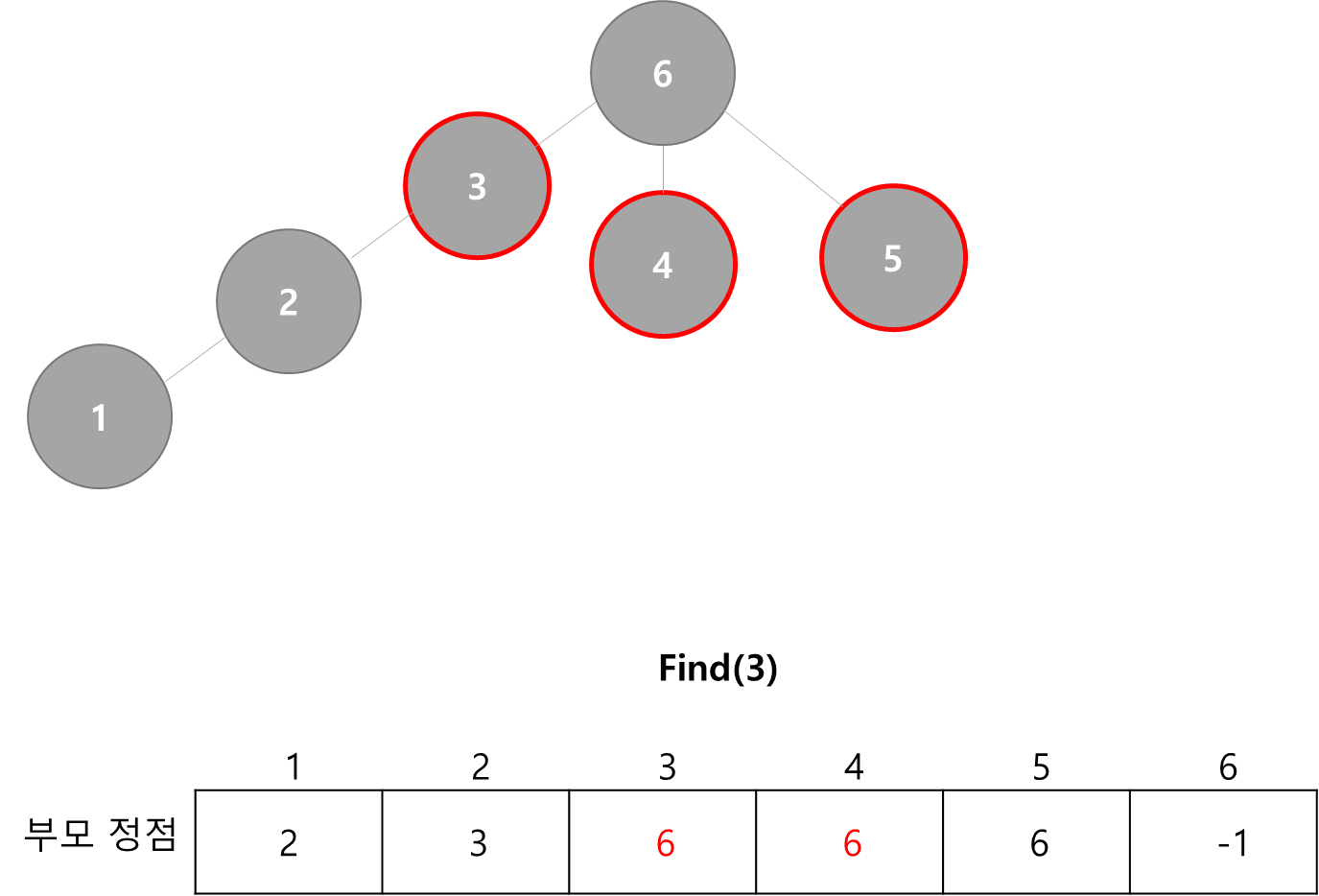
- 이렇게 하면 모든 노드가 루트를 6으로 하는 하나의 그룹임에 변함이 없고, 트리의 높이는 줄일 수 있음.
구현
- 재귀함수로 쉽게 구현할 수 있음.
vector<int> p(11, -1);
int find(int x){
if(p[x] < 0)
return x;
return p[x] = find(p[x]);시간복잡도 정리
| 내용 | 시간복잡도 |
|---|---|
| 최적화1 - Union by rank | |
| 최적화2 - 경로 압축 | Amortized |
| 최적화1 + 최적화2 | Amortized |
- 이 두 가지 기법을 모두 적용하면 유니온 파인드의 시간 복잡도는 거의 수준으로 동작
- 정확히는 아커만 함수의 역함수 O(α(N))의 시간 복잡도를 가지며, 실질적으로 에 가깝게 동작
마무리
Union-Find는 서로소 집합으로 나타낸 자료구조에서, 각 집합을 합치고 그 집합을 알아내는 알고리즘입니다. 직관적으로 구현했을 때 최악의 경우 시간복잡도 으로 동작하는데, 두 가지 최적화 기법 union by rank와 경로 압축을 적용하면 거의 만에 동작할 수 있습니다.
