1. What is Recursion?
리스트에 있는 수 다 더하기
리스트에 있는 수를 다 더하는 순서를 다음 괄호를 통해 표현할 수 있습니다.
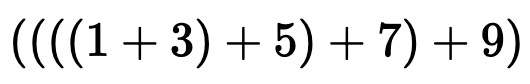
그런데 이렇게도 표현할 수 있습니다.
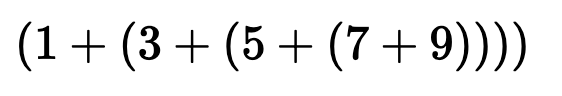
위와 같이 수열을 입력하면 합을 리턴하는 함수를 작성해 봅시다.
재귀적으로 리스트 합 구하기

위 그림을 볼까요? 리스트를 입력하면 합을 출력하는 함수가 있다면, 표시된 sub-list도 합을 출력해 줄 것입니다. 이 함수를 listsum()이라고 하겠습니다. 그러면 1과 listsum(sublist)가 리턴하는 값을 A + B로 나타낼 수 있으므로, 정답을 얻을 수 있습니다.

이제 listsum(list[1:])가 리턴하는 값을 알아볼까요?

이때에도 listsum은 3과 listsum(sublist)를 더하여 반환합니다.
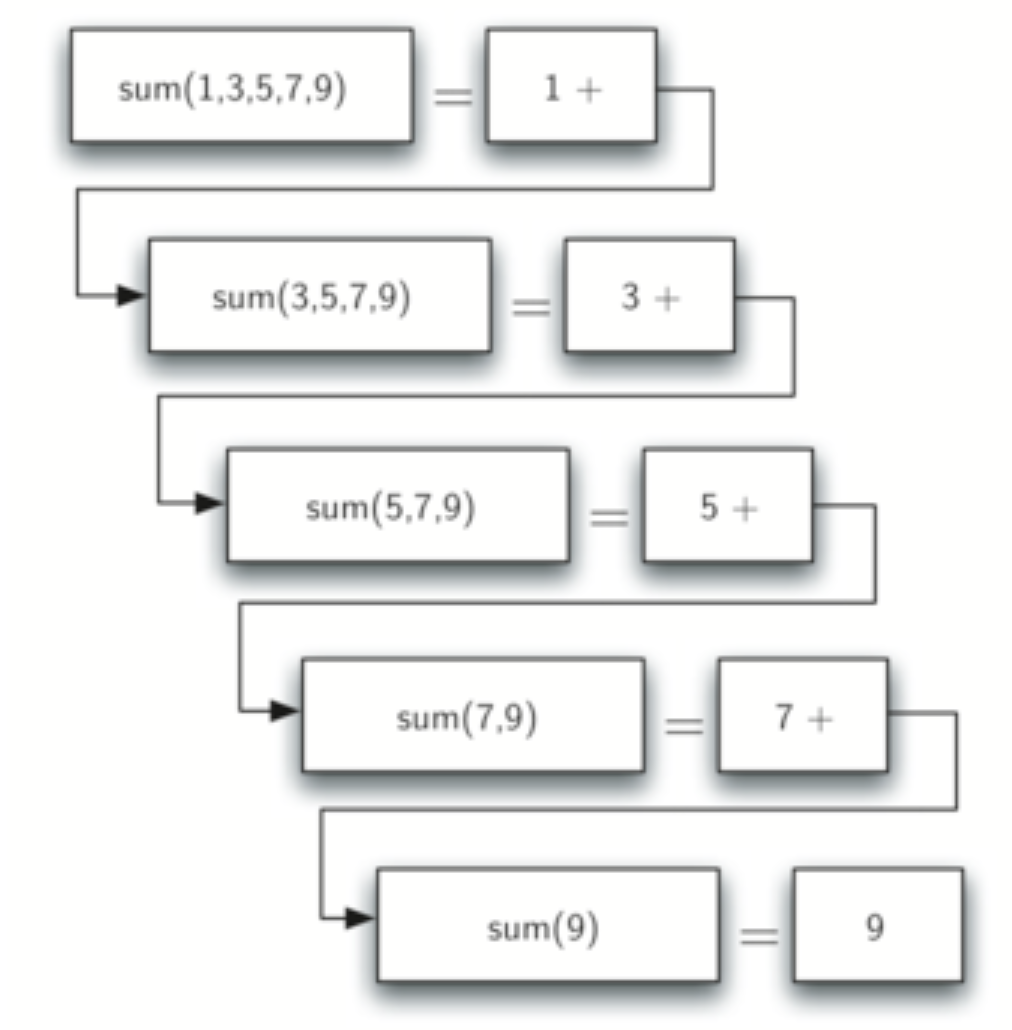
리스트에 수가 하나밖에 없다면, 더이상 A + B 형태로 쪼갤 수 없습니다. 그래서 listsum을 호출할 수 없고, 리스트에 있는 수를 그냥 리턴해야 합니다. 이렇게 리턴이 시작되면, 앞에서 호출했던 모든 listsum이 값을 갖게 되고, A + B 할 수 있습니다. 그 과정을 순서대로 나타낸 그림은 아래와 같습니다.
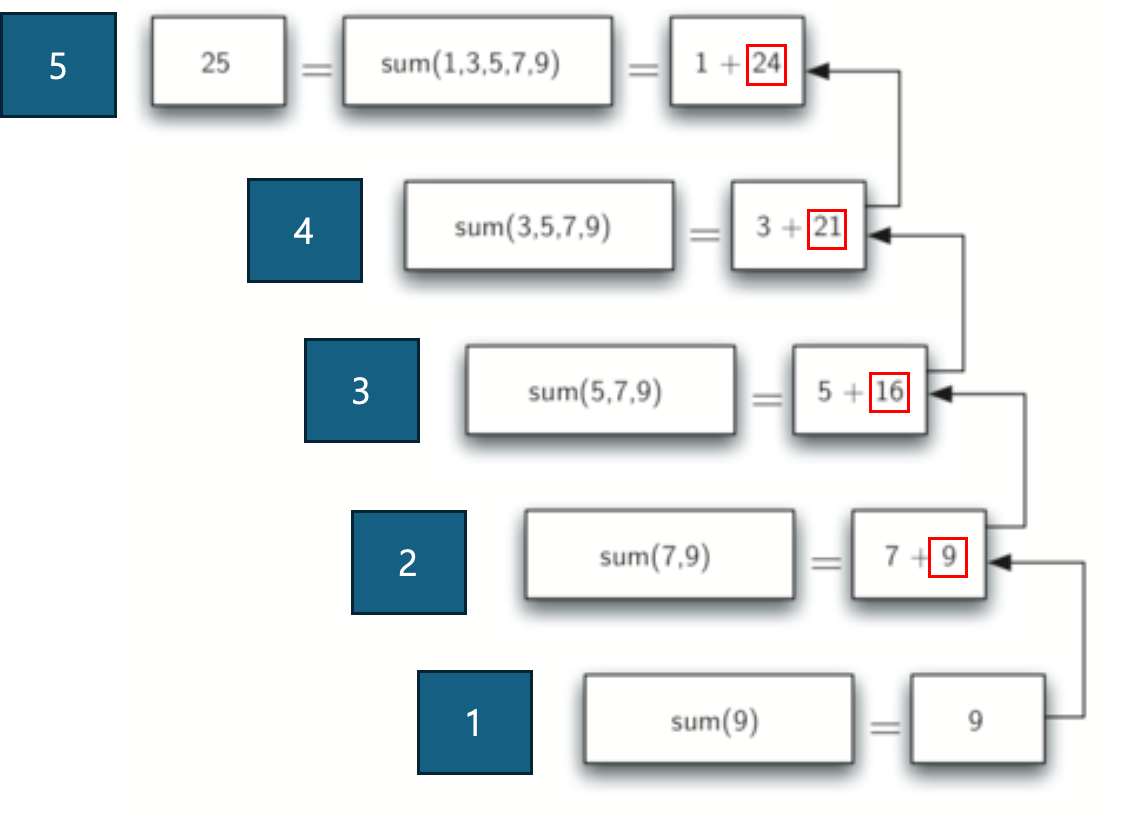
2. Three Laws of Recursion
앞선 예제를 통해서도 예상해볼 수 있겠지만, 재귀함수를 작성할 때는 세 가지 규칙을 지켜야합니다.
1. 기저 조건(base case)을 가져라
2. 기저 조건으로 이동하며 상태를 바꿔라
3. 자기 자신을 호출하라.
Law 1. 기저 조건을 가져라
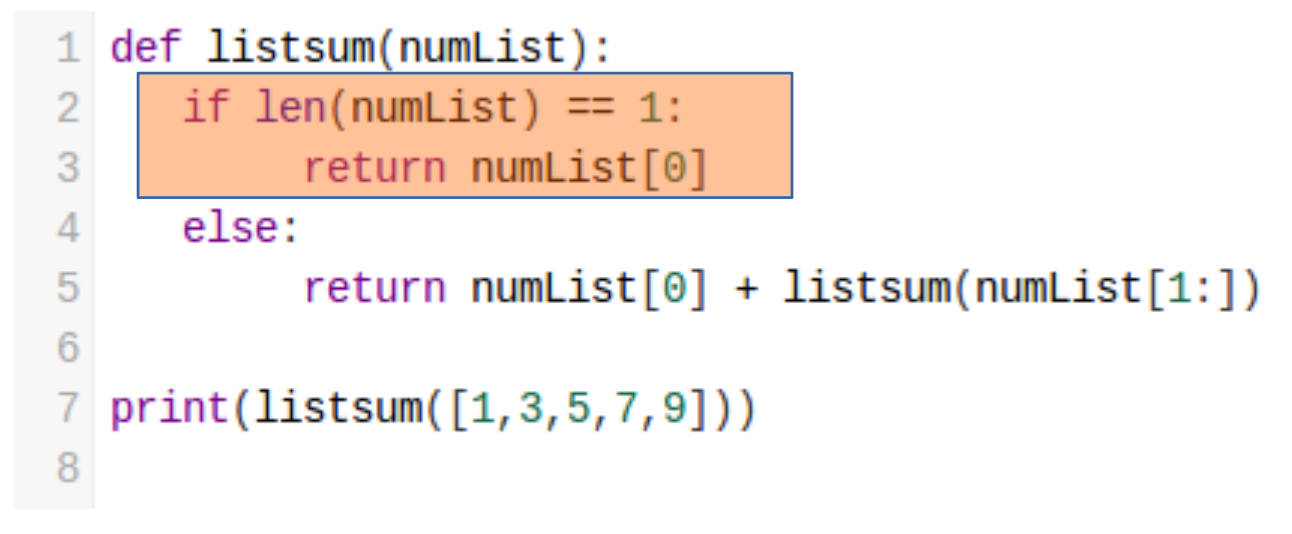
기저 조건은 sub-problem이 충분히 작아 재귀가 끝날 때의 조건을 뜻합니다.
앞선 예시에서 기저 조건 바로 리스트의 길이가 1이될 때입니다.
Law 2. 기저 조건으로 이동하며 상태를 바꿔라
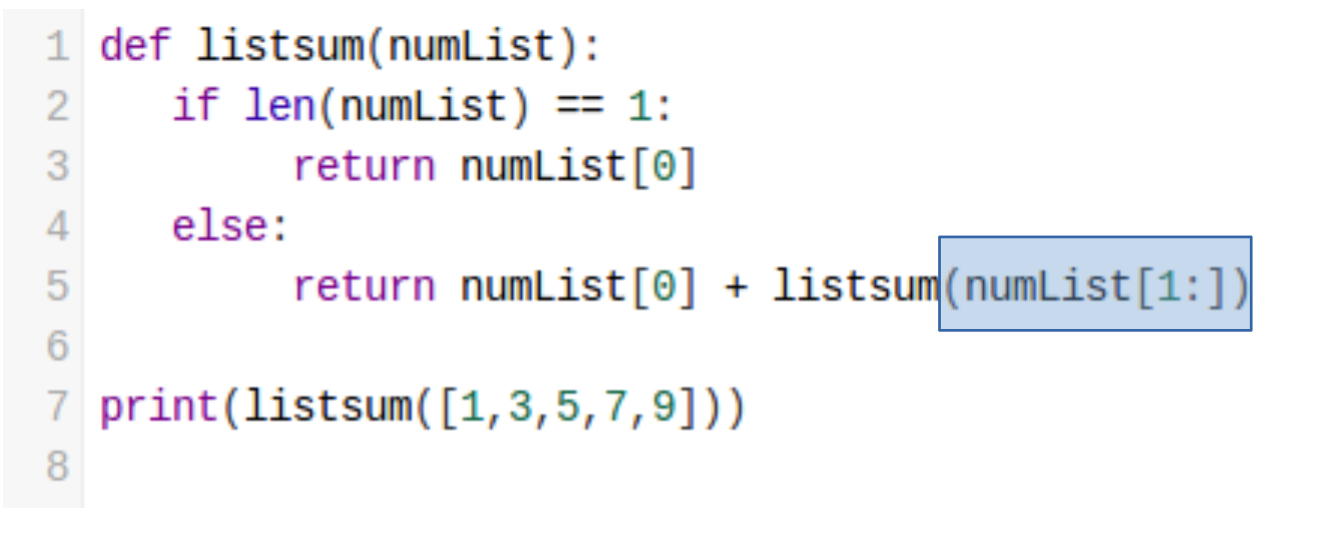
state change는 data가 계속 작아지는 것을 뜻합니다.
앞선 예시에서는 리스트의 길이가 계속해서 작아지는 것입니다.
Law 3. 자기 자신을 호출하라
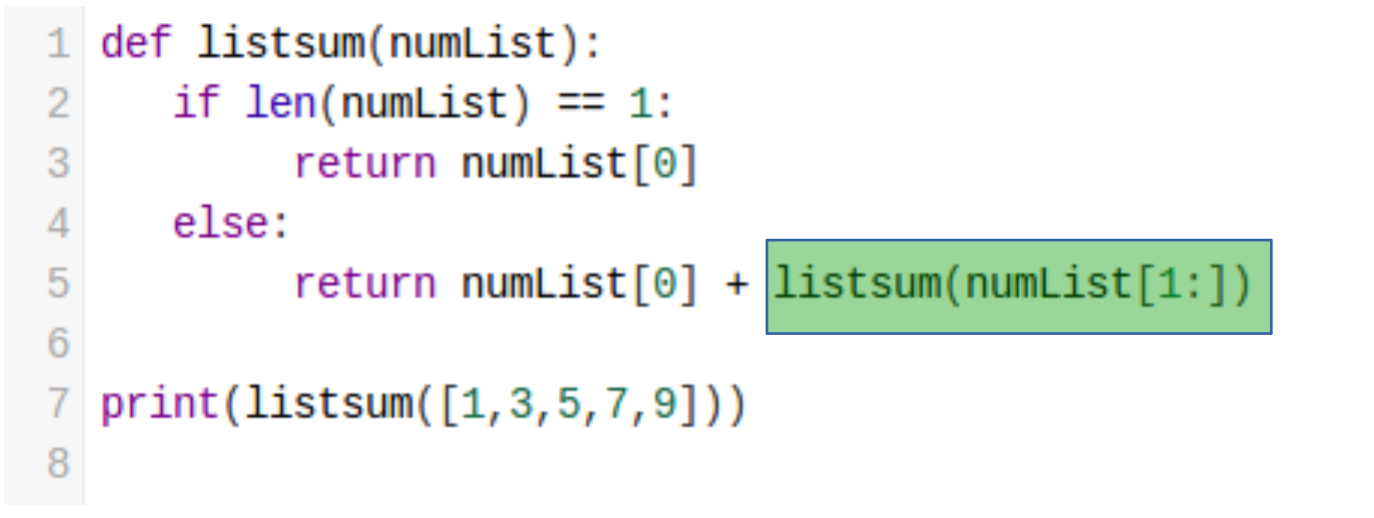
3. 재귀함수의 장단점
피보나치 수열
피보나치 수는 를 만족하는 수입니다. 이를 프로그래밍하면 다음과 같습니다.

굉장히 직관적이고 단순하지 않나요?
이 함수가 어떻게 동작하는지 fib(5)에 대한 function call을 그려보면 다음과 같습니다.
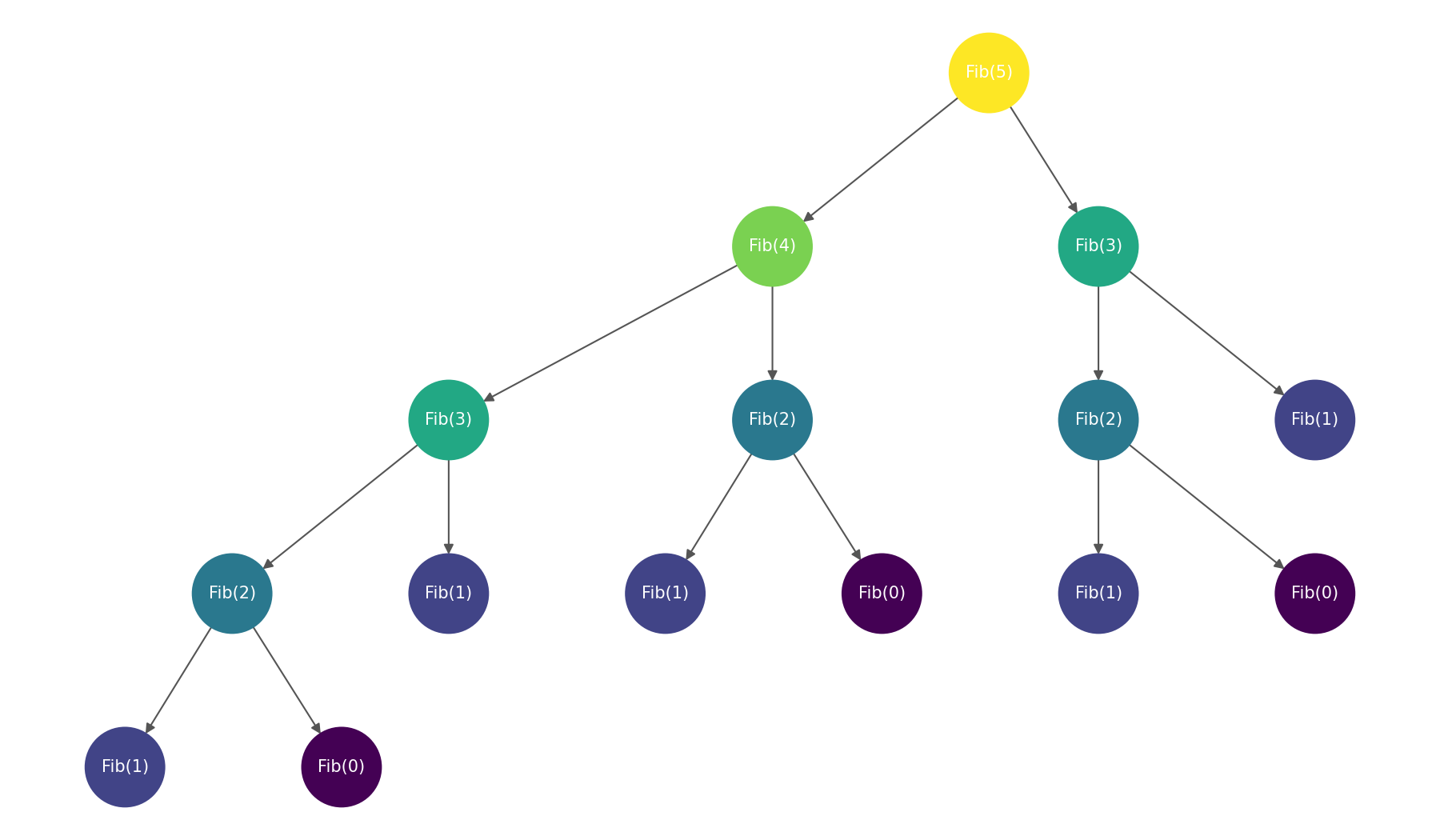
이미 한 번 호출한 경우를 다시 호출하여 중복된 호출이 일어나고 있습니다. 이처럼 재귀에는 장점과 단점이 명확합니다.
| 장점 | 단점 |
|---|---|
| • 간결한 코드 • 직관적이고 이해하기 쉬움 | • stacking으로 인한 추가 메모리 소비 • 잘못 설계 시 느린 실행 |
이때
stacking은 재귀 호출을 위해function call을 스택처럼 메모리 공간에 쌓아놓는 것을 뜻합니다. 예를 들어, fib(5)를 구하기 위해 fib(4)로 들어가는 순간, 현재 상태를 저장하고 들어가야 합니다. 그래야 재귀 호출이 종료되고 돌아왔을 때 리턴된 값을 현재 상태의 값과 연산할 수 있습니다.
