인덱스 머지 VS 결합인덱스

-
인덱스 머지인 경우는 각각 단 하나의 컬럼으로 구성된 인덱스가 하나의 테이블에 2개 이상 있었을 때, 그 인덱스를 동시에 사용해 돌아가는 현상을 가리킨다. ROWID가 다른 경우는, ROWID가 작은쪽을 SCAN해가면서 ROWID가 같은 값을 찾아가고자 INDEX를 계속 번갈아가면서 사용한다. 따라서, 상당히 비효율적인 측면이 많이 있다.
-
결합인덱스인 경우는 두 컬럼을 모두 결합해서 하나의 인덱스로 만든 이상, 두 컬럼의 데이터가 이미 결합된채로 존재하는 것을 알 수 있다. 프로세스가 인덱스 머지에 비해 매우 간단하다.
결합인덱스의 구성
결합인덱스 컬럼 선택
- WHERE절에서 AND 조건으로 자주 결합되어 사용되면서 각각의 분포도보다 2개 이상의 컬럼이 결합될 때 분포도가 좋아지는 컬럼들
- 다른 테이블과 조인의 연결고리로 자주 사용되는 컬럼들
- 하나 이상의 키 칼럼 조건으로 같은 테이블의 컬럼들이 자주 조회딜 때, 이러한 컬럼을 모두 포함(결합)
결합인덱스의 컬럼 순서 결정
- Where절 조건에 많이 사용되는 컬럼 우선(자주 사용되는 것)
- Equal('=')로 사용되는 컬럼 우선(자주 사용되는 것중 =을 사용하는 것)
- 분포도가 좋은 컬럼 우선(=조건으로 하되, 찾아가는 범위가 좁은 것)
- 자주 이용되는 Sort의 순서로 결정
- 고정된 Sort의 순서를 가진 SQL문이 자주 사용되는 경우에는 3과 4의 비중이 바뀔 수 있음
결합인덱스 사용 방법
결합인덱스 사용 가능한 예

- 결합인덱스가 만들어졌다 보고, 이와 같은 결합인덱스가 사용되기 위해서 sql작성을 어떻게 해야할것인가?
INDEX SKIP SCANNING
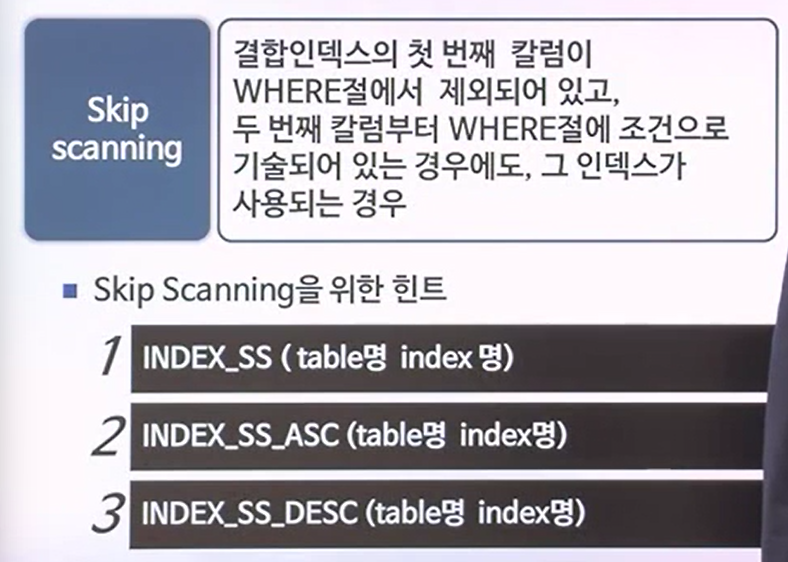
- CBO에서 첫번째 컬럼이 누락된 경우에 한해서, 어떤 현상이 일어나냐면, SKIP scanning이 일어날 수 있다. 이 부분을 강제로 제어할 수 있는 부분이 다소 존재한다. 아래에 있는것처럼 힌트를 사용하면 된다. INDEX_SS(INDEX SKIP SCANNING)
결합인덱스 컬럼에 대한 '='의 의미
범위 제한 조건

- 인덱스 사용상에서 범위를 바로 좁혀갈 수 있는 =들을 범위제한조건이라 정의한다. =이 조건으로 사용되는 한 속도를 고민할 필요가 없다.
체크 조건

- 범위를 일부 다른 조건으로 선택해 들어가고 =을 추후에 활용하는 체크조건으로 해석되는 경우도 있다.
- 범위를 좁혀갈 수 있는 =이 아닌 체크조건으로 해석되는 경우이다. 즉, 첫번째 컬럼에 준 애매한 조건하나때문에 나머지 컬럼들의 =이 범위를 선택함에 있어서 바로 사용될 수 없다는 것이다.
- 첫번째 예제인 경우는 사실 상 인덱스 사용을 했을 때, 서라고 시작하는 '시'를 다 찾게 하고 말았다라고 할 수 있다. 그렇기에 강남구와 역삼동을 바로 찾지 못했다.
- 두번째 예제인 경우는 시는 서울시로 명시했지만 두번째 컬럼의 조건을 LIKE로 하고 세번째는 컬럼을 바로 찾았다. 문제는 역삼동이란 지역을 바로 못찾는다. 구보다 뒤에있는 동은 체크조건이었다라고 할 수 있다.
인덱스 매칭률

- =이 범위제한조건을 가지면 그만큼 속도를 낸다는 의미이고, 그렇지 못한다면 속도를 내지 못한다.
- 범위제한조건을 인덱스 매칭률로 접근해보면 다음과 같다.
인덱스 매칭률 향상을 통한 속도 개선

-
첫번째 where절이 =이 아닌 이상 그 다음에 있는 컬럼들의 =들은 범위제한조건이 아닌 체크조건으로 해석된다. 따라서, 사실 상 첫번째 컬럼에 준 like 1가지만으로 해당 연도데이터를 다 찾아가게 만들었다라고 할 수 있다. 속도를 내기 위해서는 where절을 어떻게 바꾸어야 하나?
-
첫번째 컬럼에 부여된 조건을 =의 의미가 되도록 sql문을 다시 수정해야 한다.
-
where절 처음에 like로 줬을 때는 매칭률이 0/3이었다가 IN을 넣은 뒤, 2/3으로 개선되었다. 매칭률을 높였기 때문에 속도가 더 좋다라고 할 수 있다.
제시문

- 해당 where절의 처음이 =이 아니고 <이기 때문에 체크조건으로 들어가게된다.
실행결과

- 그렇기 때문에, I/O를 많이 나타내는 이유가 된다.
- 정작, 찾은 데이터는 얼마 안되지만 범위를 좁히지 못하여서 그만큼 시간적으로 많이 걸리게 된다.
수정문

튜닝결과
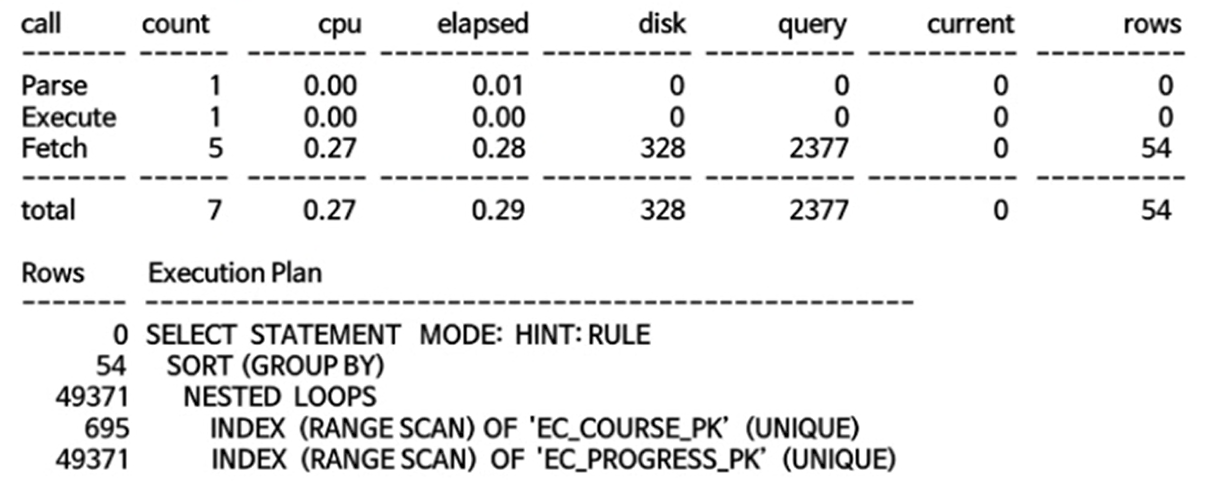
- 찾는 데이터는 아까와 동일하지만 효과가 커서 I/O(328 - disk,2377 - query)를 많이 줄이고 시간적(0.29 - elapsed)으로 많이 단축된 효과를 보여줄 수 있다.
