인덱스를 사용하지 말아야 하는 경우
인덱스 스캔을 하면 무조건 빠른가?
-
조건에 의한 처리범위가 넓어짐으로 인해 분포도가 나빠지는 경우가 있는데, 이 경우 인덱스 스캔을 하는것보다는 FULL TABLE SCAN을 하는 것이 바람직함
-> FULL TABLE SCAN 시엔 한 번의 I/O때 마다 여러 개의 데이터 Blocks를 처리하기 I/O 횟수가 감소하게 됨
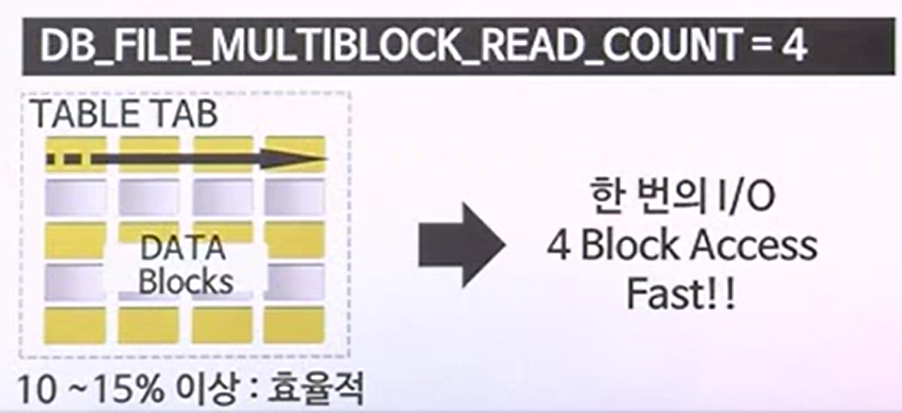
- 한번에 읽어낼 수 있는 BLOCK갯수 4개를 의미하는 것이 DB_FILE_MULTIBLOCK_READ_COUNT이다. FULL TABLE SCAN을 하게 되면 한번에 4개의 BLOCK씩을 읽게된다.
인덱스 사용이 불가능한 경우
- NOT 연산자 이용
- IS NULL, IS NOT NULL 사용
- 옵티마이저의 취사 선택
- External suppressing
- Internal suppressing
NOT 연산자 이용
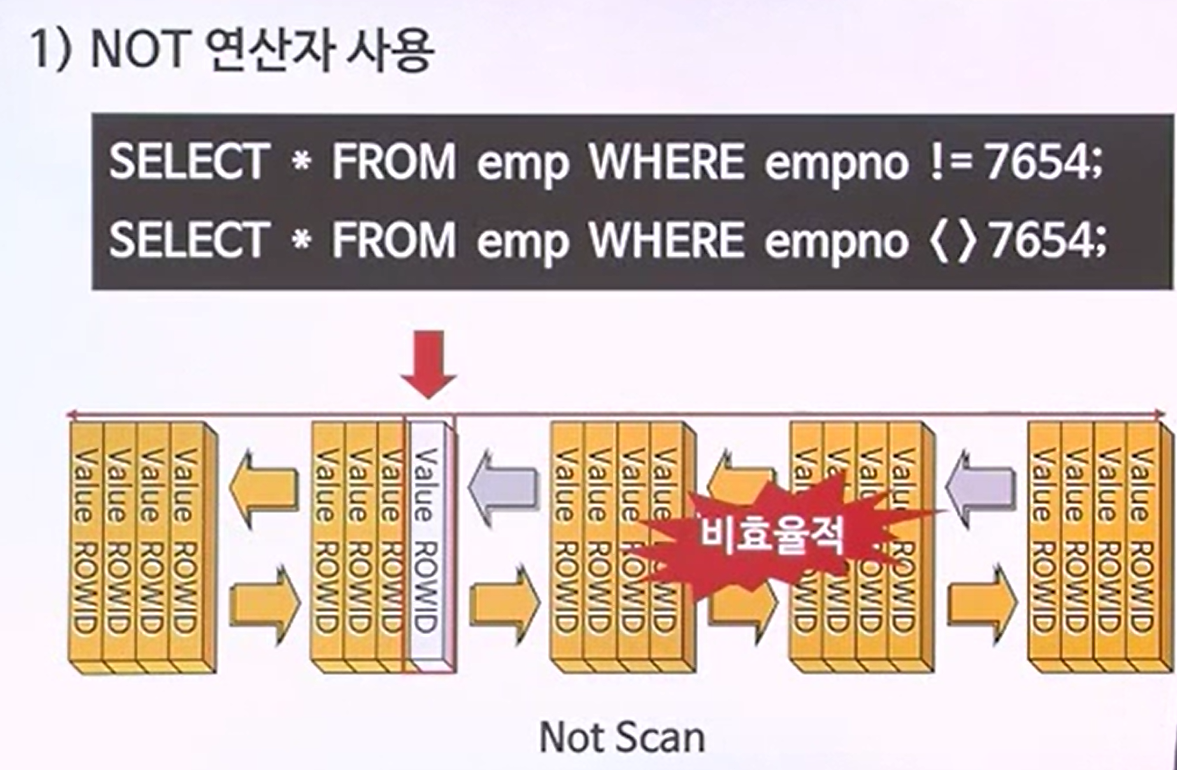
- 한건의 데이터를 제외하고 모든 데이터를 찾는다고 볼 때, 데이터의 15%를 찾게된다. 그렇기 때문에, 인덱스를 사용하지 않을 때 오히려 더 좋다.
IS NULL, IS NOT NULL 사용
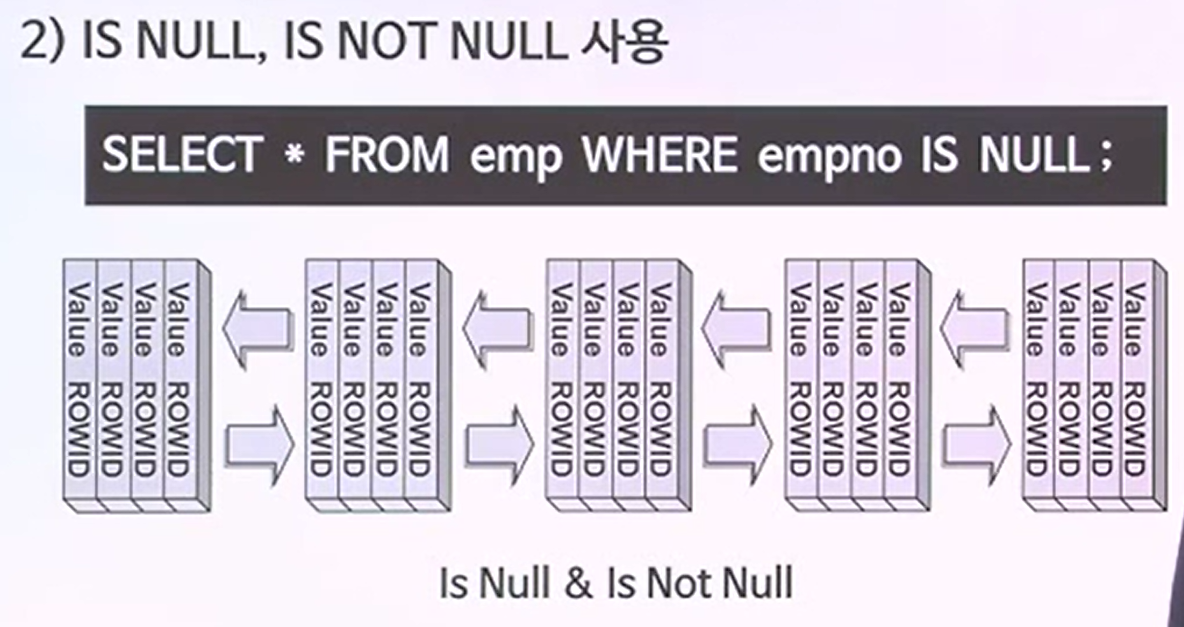
- INDEX에는 NULL값을 저장하지 않는다.
옵티마이저의 취사 선택

External suppressing

- 인덱스로 구성된 컬럼의 변형을 가했을 때, 그로 인해서 해당 칼럼으로 구성된 인덱스를 사용하지 못하게 했을 때를 가리킨다. 코딩상 겉으로 드러나있는 External suppressing이다.
- 변형이 가해진 이상, 해당 컬럼을 더 이상 사용할 수 없다.
- 컬럼으로 함수를 제거하고 like를 사용해야만 한다.

- 선생님 얼굴 죄송합니다..

- 어떤 경우든, 컬럼에 변형을 가하면 인덱스 사용이 불가능하다.
Internal suppressing
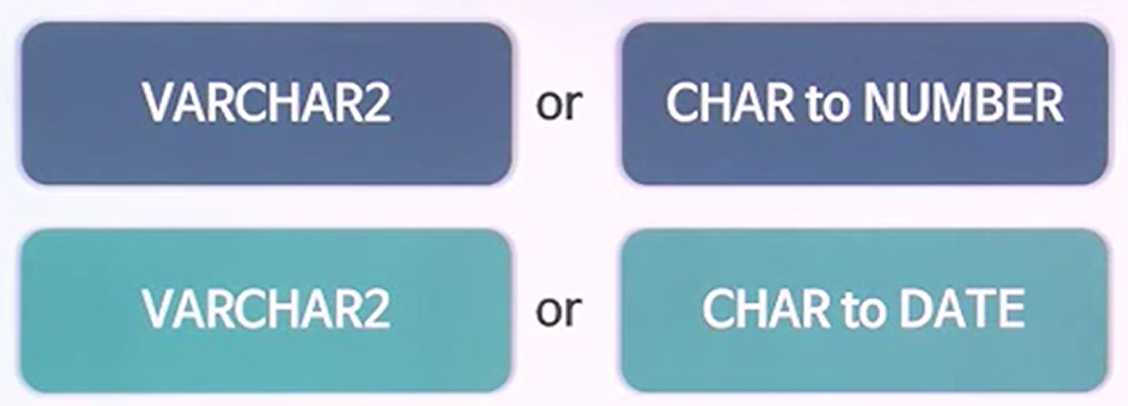
- 데이터 내부에서 스스로 존재하는 suppressing이 있다. 서로 다른 데이터 타입끼리 비교할 때 나타날 수 있다. 문자와 숫자를 비교한다거나, 문자와 데이터 타입을 비교한다고 할 때, 하나의 타입을 기준으로 해서 단 하나의 타입이 타입변환을 통해서 타입을 맞춰나간다라고 할 수 있다. 스스로 존재하는 supressing을 Internal suppressing이라고 한다.


- 첫번 째 where절은 index 사용이 가능하다.(컬럼의 변형이 아닌 이상) 입력받은 날짜정보는 문자로 입력받았기에 문자가 데이터로 변환이 이루어진다.
- 세번째 where절은 주민번호라는 컬럼에 대해서 인덱스가 존재하고 컬럼의 데이터 타입을 문자로 가정한 것이다. 입력받은 상수가 숫자타입이다라고 볼 수 있다. 그렇기에, 컬럼의 타입변환이 행해진다.
옵티마이저에 의한 선택 절차
- 특정 테이블에 대해서 SQL의 주어진 조건으로 인해 사용될 수 있는 인덱스가 두개 이상인 경우
- 옵티마이저는 조건에 가장 적절한 인덱스를 선택해서 사용해야 함
-
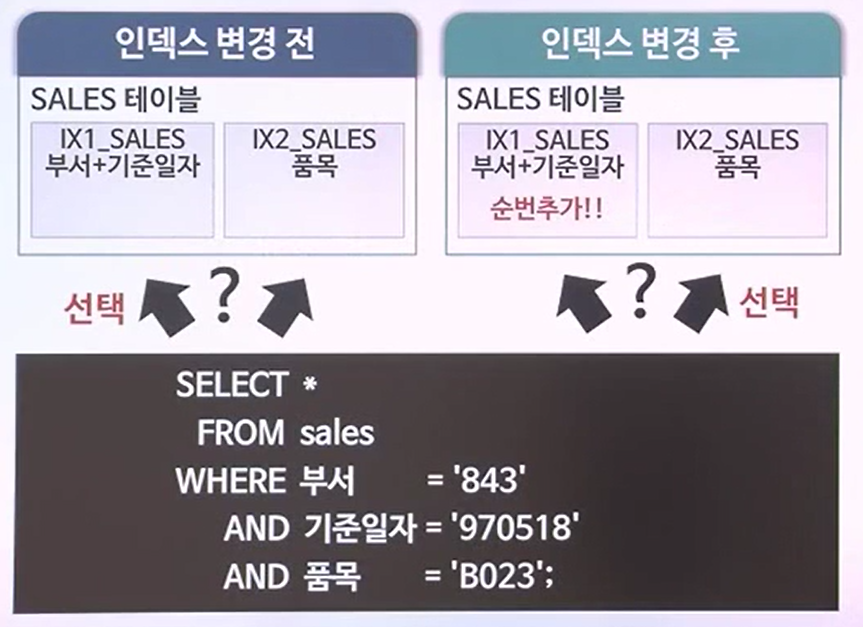
주어진 조건에 가장 적정한 인덱스를 선택하려 할 때, 일련의 절차에 따라 결정함
-
- 어떠한 절차에 따라서 인덱스가 위의 사진처럼 결정이 되는가?
옵티마이저의 인덱스 선택 시 판단 절차

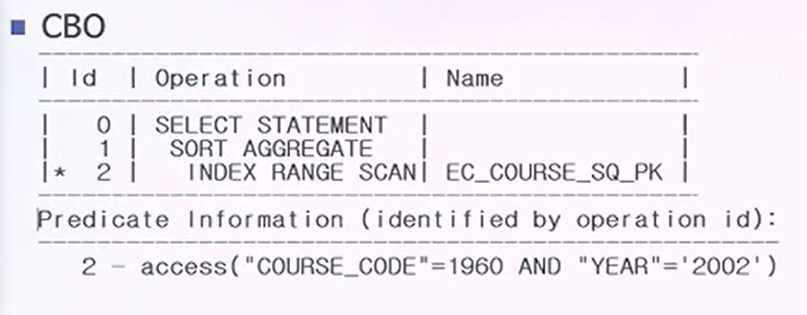
RBO와 CBO가 선택한 인덱스의 차이

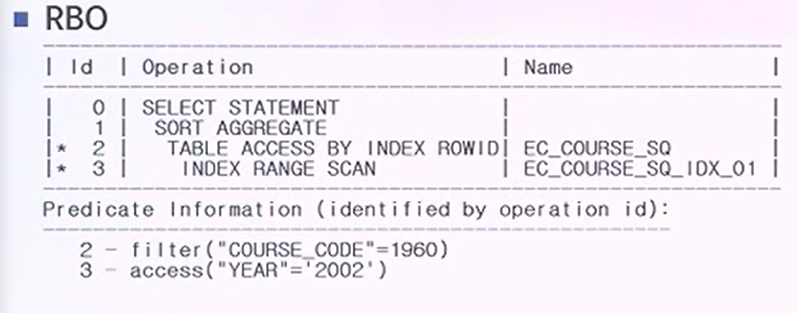
- RBO는 인덱스 매칭률을 이용할 때 사용되는 인덱스는 IDX_01이다. 왜냐하면 인덱스매칭률이 1/1이 이기때문이다.
- WHERE절에 두 조건을 사용해들어갈 수 있는 인덱스가 사실은 PK이다. 연도만으로 된것보다는 더 범위를 좁힌다고 봤을 때, 데이터 처리부분에 있어서 범위를 더 줄여나갈 수 있는 인덱스는 PK라고 봤을때, CBO는 비용을 고려한다 봤을 때 범위를 줄여나가는 PK를 사용하게 된다.
RBO 실행계획
CBO 실행계획