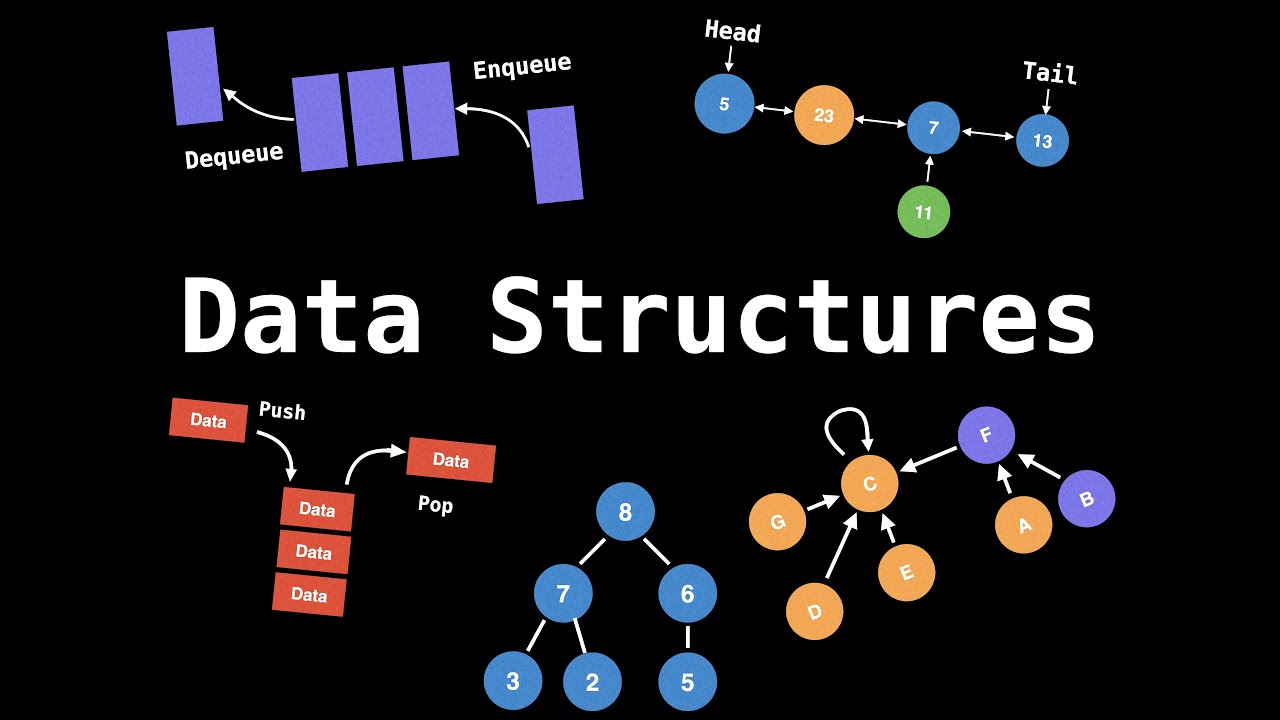
스택(Stack)이란?
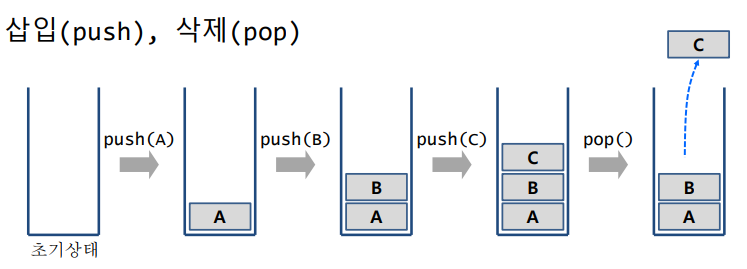
스택(Stack)은 자료 구조의 일종으로, 후입선출(Last-In-First-Out, LIFO)의 원리를 따른다. 후입선출이란, 말그대로 먼저 들어온 데이터가 먼저 나간다는 의미이다.
스택은 데이터를 임시로 저장하거나, 함수 호출 시 함수의 호출 순서 등을 기억하는 등 다양한 분야에서 사용된다. 또한 스택은 컴퓨터의 메모리 구조에서도 중요한 역할을 한다. 함수 호출 시 함수 호출 정보나 지역 변수 등을 스택에 저장하여 함수 호출이 끝나면 해당 정보를 제거하는 등의 작업이 스택을 이용해 처리된다.
스택의 연산
size(): 현재 스택에 들어 있는 데이터 원소의 수를 구함isEmpty(): 현재 스택이 비어 있는지를 판단 (size() == 0?)push(x): 데이터 원소 x 를 스택에 추가pop(): 스택에 가장 나중에 저장된 데이터 원소를 제거 (후 반환)peek(): 스택에 가장 나중에 저장된 데이터 원소를 참조 (반환), 그러나 제거하지는 않음
큐(Queue)란?
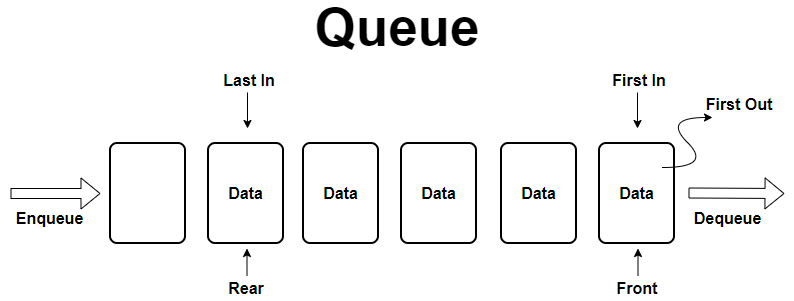
큐(Queue)는 데이터가 들어온 순서대로 처리되는 자료구조이다. 큐는 일반적으로 FIFO(First-In, First-Out) 구조를 따른다. 즉, 가장 먼저 들어온 데이터가 가장 먼저 처리된다.
큐는 다양한 분야에서 된다. 예를 들어, 네트워크에서는 데이터를 처리할 때 패킷을 큐에 넣어서 처리하는 경우가 많다. 또한, 운영체제에서는 프로세스 스케줄링을 위해 큐를 사용한다. 그리고 멀티 스레딩 환경에서도 큐는 스레드 풀(Thread Pool)에서 작업을 할당하는 데에 사용된다.
큐(Queue) 구현
큐는 배열(Array)이나 연결 리스트(Linked List)로 구현할 수 있다. 배열을 사용하면 인덱스로 바로 접근할 수 있기 때문에 빠른 접근이 가능하지만, 삽입과 삭제가 비효율적이다. 연결 리스트를 사용하면 삽입과 삭제가 효율적이지만, 인덱스로 바로 접근할 수 없기 때문에 특정 위치에 있는 데이터에 접근하는 데는 비효율적이다. 따라서, 큐의 구현 방법은 사용하는 상황에 따라 선택되어야 한다.
큐의 연산
size(): 현재 큐에 들어 있는 데이터 원소의 수를 구함isEmpty(): 현재 큐가 비어 있는지를 판단 (size() == 0?)enqueue(x): 데이터 원소 x를 큐에 추가dequeue(): 큐의 맨 앞에 저장된 데이터 원소를 제거(후 반환)peek(): 큐의 맨 앞에 저장된 데이터 원소를 반환(제거하지는 않음)
여러가지 큐
환형 큐(Circular Queue)
환형 큐(Circular Queue)는 일반적인 큐와 비슷하지만, 배열의 처음과 끝이 연결되어 원형으로 이루어져있다. 즉, 배열의 끝에 도달하면 다시 배열의 처음으로 돌아간다. 이를 통해 배열을 계속해서 재활용하면서 데이터를 저장할 수 있어 메모리 사용이 효율적이다.
환형 큐의 동작 방식
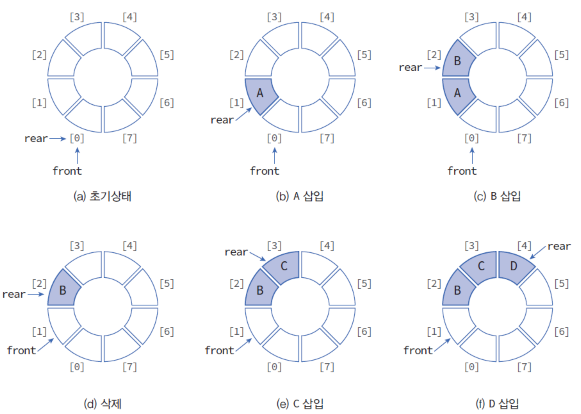
환형 큐는 Front와 Rear 포인터를 사용하여 큐의 상태를 관리한다. Front는 큐에서 가장 먼저 들어온 데이터의 위치를 가리키고, Rear는 가장 마지막에 들어온 데이터의 위치를 가리킨다. 환형 큐는 일반적인 큐와 달리, Rear 포인터가 배열의 끝에 도달하면 다시 배열의 처음으로 돌아가기 때문에, 배열의 모든 원소를 다 사용하지 않아도 계속해서 데이터를 삽입할 수 있다. 이를 위해 환형 큐에서는 배열의 끝에 도달하면 다시 배열의 첫 번째 원소로 돌아가는 과정을 구현해야 한다.
환형 큐는 배열을 사용하여 구현할 수 있다. 따라서, 배열의 크기가 고정되어 있기 때문에 배열의 크기를 동적으로 변경할 수 없는 단점이 있다. 따라서, 데이터가 자주 추가되거나 삭제되는 상황에서는 크기가 동적으로 변경될 수 있는 연결 리스트를 사용하여 큐를 구현하는 것이 더 효율적일 수 있다.
환형 큐의 연산
환형 큐는 일반적인 큐의 연산과 동일한 연산이 가능하다. 하지만 크기를 동적으로 변환하지 못하기 때문에 큐가 꽉 찼는지를 판단하는 연산이 추가적으로 필요하다.
isFull(): 큐에 데이터 원소가 꽉 차 있는지를 판단
우선순위 큐(Priority Queue)
우선순위 큐(Priority Queue)는 일반적인 큐와는 달리 데이터를 우선순위에 따라 처리하는 자료구조이다. 데이터를 삽입할 때, 해당 데이터의 우선순위를 지정하여 큐에 삽입하며, 데이터를 처리할 때는 우선순위가 가장 높은 데이터를 먼저 처리한다.
우선순위 큐 구현
우선순위 큐는 다양한 방법으로 구현될 수 있다. 배열, 연결 리스트, 힙(Heap) 등을 사용하여 구현할 수 있으며, 각각의 방법에 따라 구현 방법과 시간 복잡도가 달라진다.
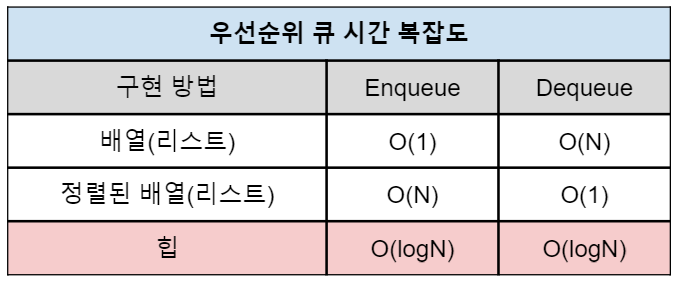
배열을 사용하여 구현하는 경우, 우선순위에 따라 데이터를 정렬해야 하기 때문에 삽입 연산의 시간 복잡도는 O(N)이고, 삭제 연산은 가장 우선순위가 높은 데이터를 찾아서 처리하기 때문에 O(1)의 시간 복잡도를 갖는다.
연결 리스트를 사용하여 구현하는 경우, 삽입과 삭제 연산 모두 O(N)의 시간 복잡도를 갖는다. 이는 삽입과 삭제를 위해 리스트를 순회해야 하기 때문이다.
힙을 사용하여 구현하는 경우, 삽입과 삭제 연산 모두 O(log N)의 시간 복잡도를 갖는다. 힙은 부모 노드와 자식 노드 간의 우선순위를 비교하여 데이터를 정렬하기 때문에, 우선순위 큐를 구현하는 데 가장 많이 사용되는 방법이다.
