05. 데이터 가공하기
05-1. dplyr 패키지
dplyr란?
r로 개발된 plyr패키지보다 빠른 C++언어로 개선하여 만든 패키지
- 패지키 설치 및 로드
install.packages("dplyr")
library(dplyr)패키지 내의 함수들
- 행 추출하기: filter() 함수
filter(데이터, 조건문)
ex) 실린더 개수가 4기통인 자동차만 추출
filter(mtcars, cyl == 4)- 열 추출하기: select() 함수
select(데이터, 변수명1, 변수명2, ...)
ex) 변속기와 기어 데이터만 추출하고 head()를 활용해 데이터 앞부분 값 확인
head(select(mtcars, am, gear))- 정렬하기: arrange() 함수
arrange(데이터, 변수명1, 변수명2, ...) -> 오름차순정렬
arragne(데이터, 변수명1, 변수명2, ..., desc(변수명)) -> 내림차순정렬
ex) 무게 기준으로 오름차순 정렬한 후 head()함수로 상위 데이터 출력
head(arrange(mtcars, wt))- 열 추가하기: mutate() 함수
mutate(데이터, 추가할 변수 이름 = 조건1, 조건2, ...)- 중복 값 제거하기: distinct() 함수
distinct(데이터, 변수명)- 데이터 전체 요약하기: summarise() 함수
summarise(데이터, 요약할 변수명 = 기술통계 함수)- 그룹별로 요약하기: group_by() 함수
group_by(데이터, 변수명)- 샘플 추출하기: sample_n(), sampleA_frac() 함수
sample_n(데이터, 샘플 추출할 개수)
sample_frac(데이터, 샘플 추출할 비율)- 파이프 연산자: %>%
데이터 세트 %>% 조건
계산 %>% 데이터 세트05-2. 데이터 가공하기
데이터를 정렬하고 병합하는 일련의 과정을 모두 데이터 가공이라고 통칭한다.
데이터 가공의 4단계
- 필요한 데이터 추출하기
- 데이터 정렬하기
- 데이터 요약하기
- 데이터 결합하기
데이터 결합
2개 이상의 테이블을 결합하여 하나의 테이블로 만드는 과정
- 세로 결합
bind_rows(테이블명, 테이블명)- 가로 결합
- left조인 : 지정한 변수와 테이블1을 기준으로 테이블2에 있는 나머지 변수들을 결합한다.
left_join(테이블1, 테이블2, by ="변수명")- inner조인 : 테이블1과 테이블2에서 기준으로 지정한 변수 값이 동일할 때만 결합한다.
(교집합 느낌)
inner_join(테이블1, 테이블2, by ="변수명")- full조인 : 테이블1과 테이블2에서 기준으로 지정한 변수 값 전체를 결합한다.
(합집합 느낌)
full_join(테이블1, 테이블2, by ="변수명")확인문제 2번 풀어보기
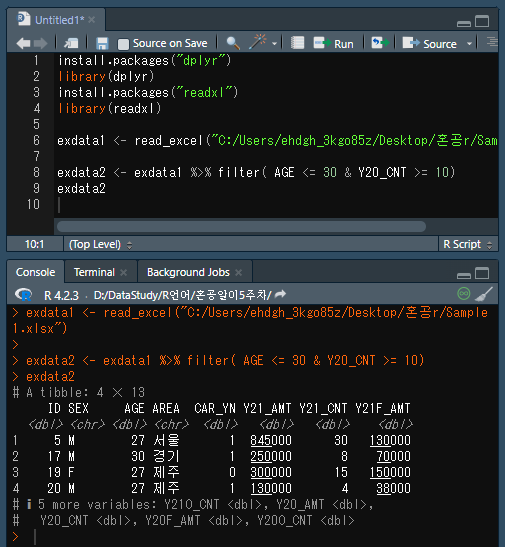
- 225쪽에서 가져온 exdata1 테이블에서 AGE가 30세 이하이면서 Y20_CNT가 1-건 이상인 데이터를 exdata2 테이블로 생성하는 코드를 작성하여 실행 결과처럼 출력해 보세요.(파이프 연산자를 사용해보세요.)
05-3 데이터 구조 변형하기
동일한 데이터가 있더라도 목적에 따라 분석 기준이 달라지며, 그에 따라 데이터 구조를 변형해야 할 때가 있다. 이를 '데이터 재구조화'라고 한다.
reshape2 패지키
- 넓은 모양 데이터를 긴 모양으로 바꾸기: melt() 함수
melt(데이터, id.vars = "기준 열", measure.vars = "변환 열")- 긴 모양 데이터를 넓은 모양으로 바꾸기: cast() 함수
- dcast() 함수
# 데이터프레임 형식으로 반환
dcast(데이터, 기준 열 ~ 반환 열)- acast() 함수
acast(데이터, 기준 열 ~ 반환 열 ~ 분리 기준 열)확인문제 4번 풀어보기
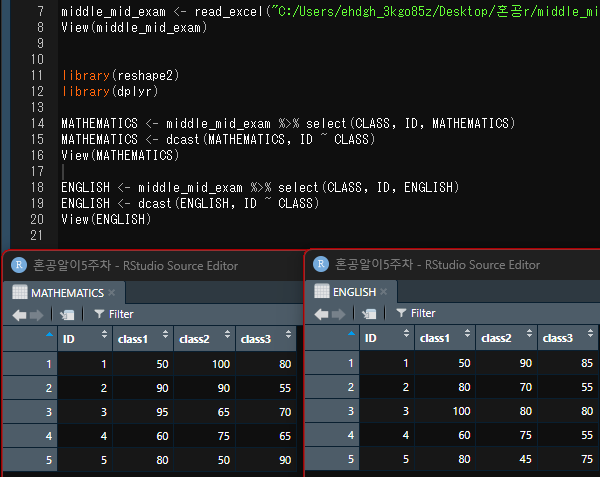
- 1학년 1반, 2반, 3반 학생 5명씩의 중간고사와 기말고사 성적이 기록된 엑셀 파일을 가져온 후 다음 실행 결고와 같이 반별 수학 점수와 영어 점수를 각각 출력해 보세요.