
Introduction
현재까지의 NLP모델 아키텍쳐인 RNN, LSTM, GRN등은 태어날때부터 sequential하게 태어남. 즉 parallelism을 활용하기 어려워서 sequence length가 길어질수록 메모리 등의 문제로 batching도 제한된다. 이를 해결하기 위한 다양한 노력은 있었으니 sequential computation은 태생이 문제였다. Attention mechanism은 RNN등에서 bottleneck문제를 해결하는 mechanism으로 잘 먹혔는데, recurrent network에 적용되어 전술한 문제를 해결한 것은 아님.
본 논문에서 프로포즈하는 Transformer는 recurrency를 회피하고 attention mechanism에만 의존한다. 이를 통해 ‘significantly more parallization’을 이뤘음.
Model Architeciture
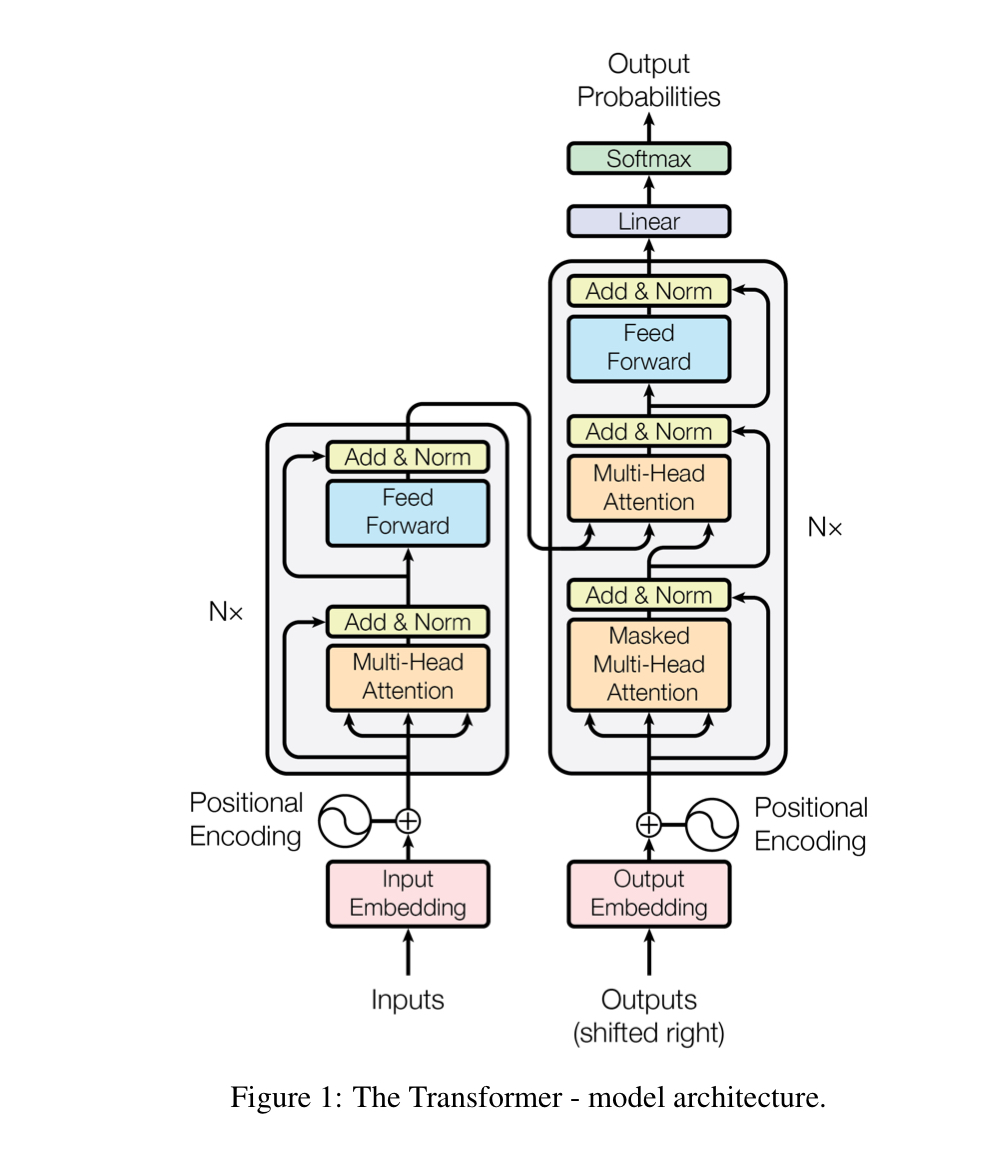
기존의 encoder-decoder structure와 어떻게 다른지 보자.
Transformer architecture는 stacked-self attention과 point-wise FCN을 encoder 및 decoder에 적용한다.
Attention
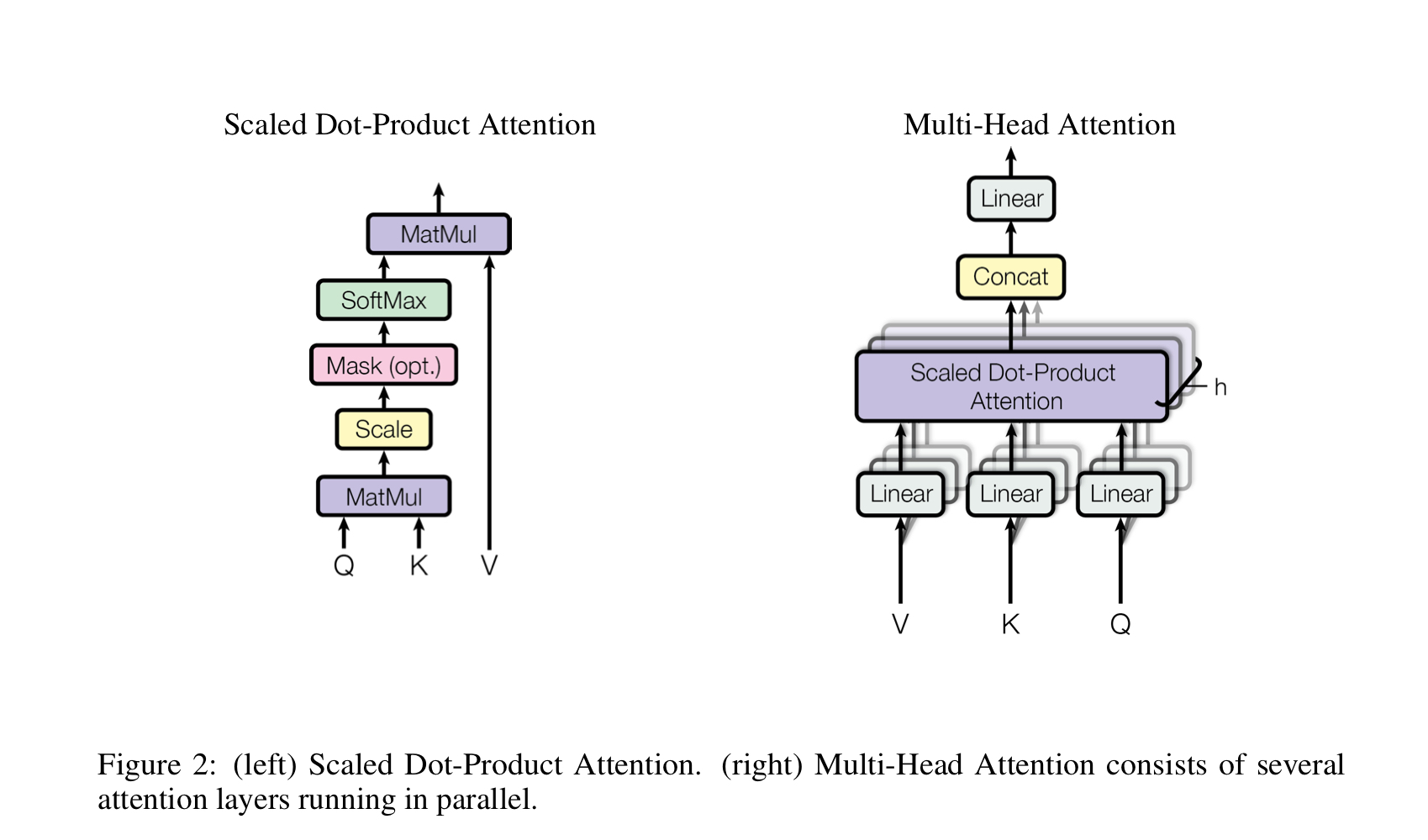
위는 scaled dot-product attention과 Multi-head attention의 구조를 나타낸 그림이다.
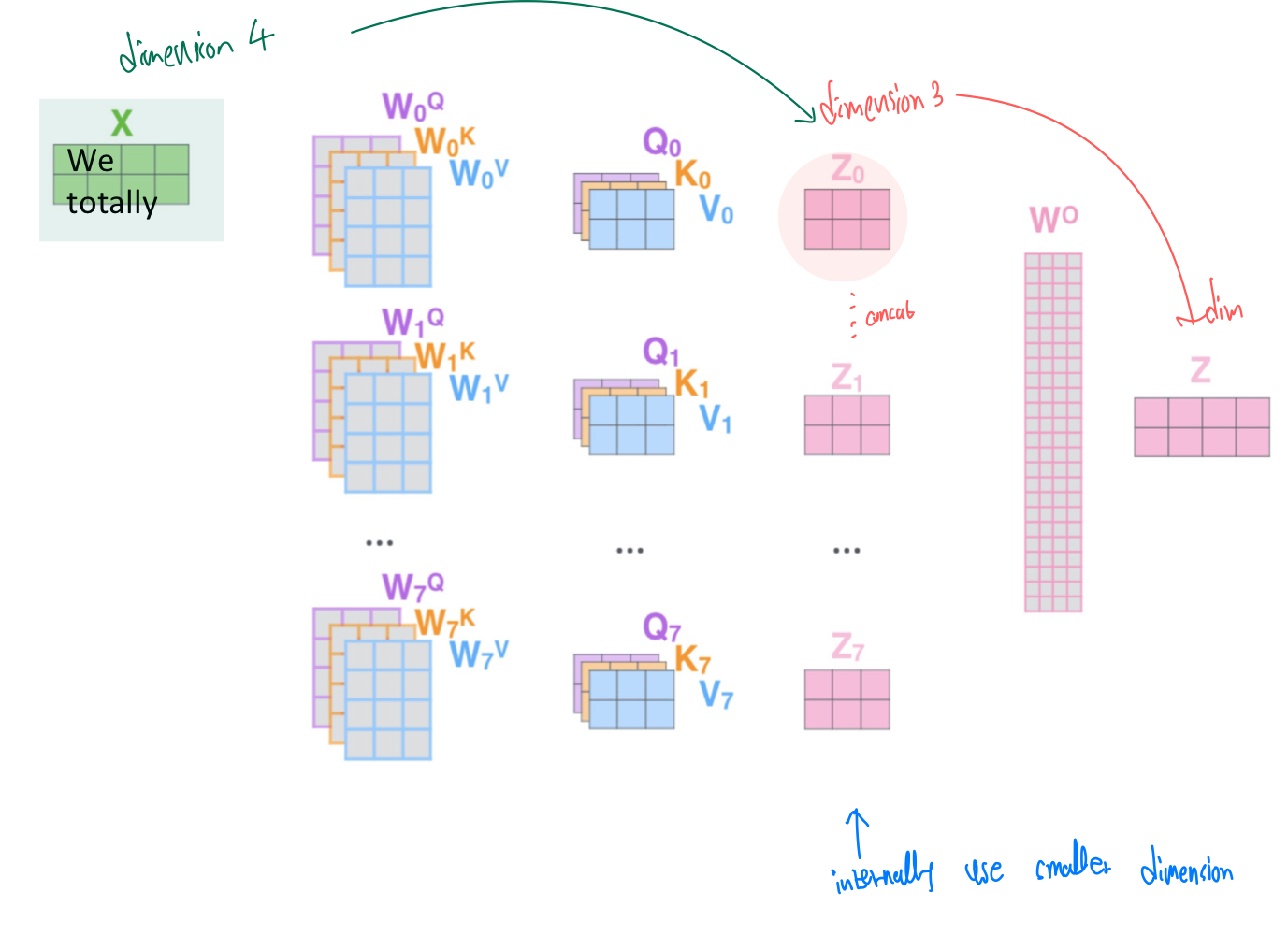
multi-head의 개수인 h에 해당하는 만큼 model dimensionality를 축소하고, (d_k = d_model/h) concat함으로써 본래의 dimensionality를 복구한다. 축소된 dim으로 scaled-dot product attention을 진행하기에 multi-head라고 computational cost가 h배 증가하는것은 아님!
Position-wise Feed-Forward Networks
attentio sub-layer에 이어 ReLU를 activation으로 사용하는 FCN이 붙는다.
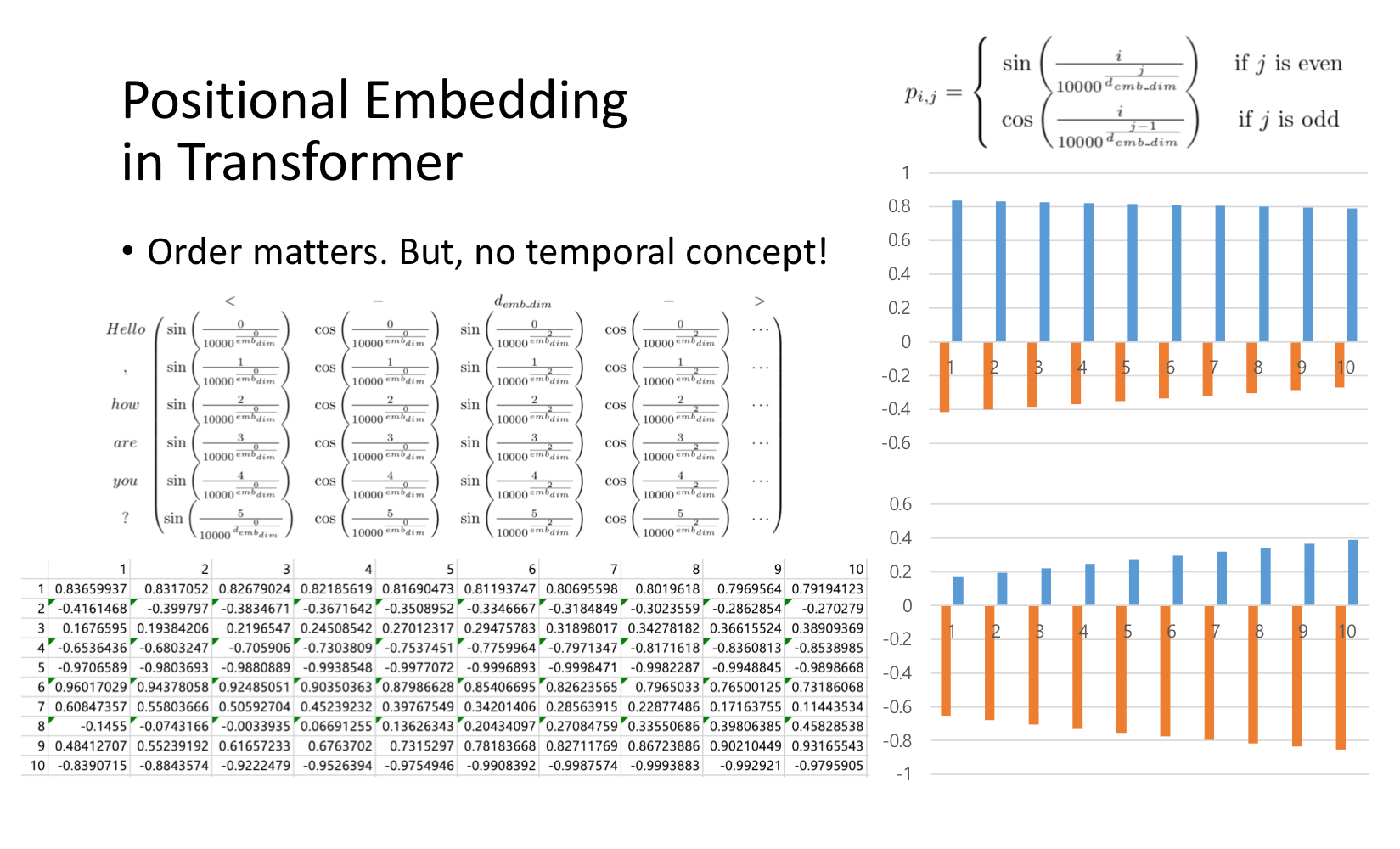
Positional Embedding
Tansformer구조는 recurrence 하지도 않으며 convolution을 사용하지 않기에(?), sequence를 반영할 수 있도록 하기 위해 relative 또는 absolute position에 의한 정보를 주입해줘야 한다.
Why Self-Attention
symbol representation 에서 latent representation 으로의 매핑을 위해 self-attention layer를 사용하는 이유는 무엇인가? (what is different from conv and rnn?)
- Total computational complexity per layer
- Amount of computation that can be parallelized
- Path length between long-range dependencies in the network
long-range dependencies(시퀀스 내에서 위치가 멀리 떨어져 있는 녀석들끼리의 dependency)를 학습하는 것이 많은 sequence transduction 태스크에서의 핵심이다! 그런 dependency를 잘 학습하기 위해 length of path(between forward-backward signal)이 짧을 수록 유리하다.
self-attention은 각 토큰을 모든 토큰에 대한 correlation information을 constant number of sequential operation( O(1) ) 으로반영한다. 반면 RNN구조는 O(n) sequential operation을 필요로 한다.
Experiment
본 논문 참조.

글이 잘 정리되어 있네요. 감사합니다.