따로 정리했던 내용을 이제야 올리네요 :)
ㅇElastic Search
Elastic Search란?
-
ElsaticSearch는 뛰어난 검색능력과 대규모 분산 시스템을 구축할 수 있는 다양한 기능들을 제공하는 플랫폼
-
Apache Lucene 기반의 오픈소스
-
(near-) RealTime 분석 시스템
- 클러스터가 실행되고 있는 동안에 계속 데이터가 입력되고, 동시에 색인된 데이터의 검색, 집계 가능.
-
Full Text 검색 엔진 지원
- 역파일 색인 구조의 Document 형식의 데이터
-
Restful API 지원
-
멀티테넌시 지원
- 서로 다른 인덱스들을 별도의 커넥션 없이 하나의 질의로 묶어서 검색하고, 검색 결과들을 하나의 출력으로 도출할 수 있는 기능을 멀티테넌시라 함.
용어정리
검색기술을 다루다 보면 검색과 색인이라는 단어를 자주 만나게 됩니다. 특히 아파치 루씬, 그리고 Elasticsearch와 관련해서는 같은 단어가 여러 뜻으로 혼용되어 쉽게 헷갈릴 수 있으므로 혼란을 방지하기 위해 몇가지 중요한 개념의 용어들을 우선 정리하고 가도록 하겠습니다.
- 색인 (indexing) : 데이터가 검색될 수 있는 구조로 변경하기 위해 원본 문서를 검색어 토큰들으로 변환하여 저장하는 일련의 과정
- 인덱스 (index, indices) : 색인 과정을 거친 결과물, 또는 색인된 데이터가 저장되는 저장소입니다. 또한 Elasticsearch에서 도큐먼트들의 논리적인 집합을 표현하는 단위
- 검색 (search) : 인덱스에 들어있는 검색어 토큰들을 포함하고 있는 문서를 찾아가는 과정
- 질의 (query) : 사용자가 원하는 문서를 찾거나 집계 결과를 출력하기 위해 검색 시 입력하는 검색어 또는 검색 조건입니다. 이 책에서는 질의 또는 쿼리라고 표현
ElasticSearch 환경설정
-
ElasticSearch의 실행 환경에 대한 설정 은
elasticsearch.yml에서 관리합니다.Brew에서 설치시 : /usr/local/Cellar/elasticsearch-full/7.11.2/libexec/config
- yml 에서 하는 주요설정은 다음과 같습니다.
cluster.name: "<클러스터명>"
- 클러스터명을 설정할 수 있습니다.
- 노드들은 클러스터명이 같으면 같은 클러스터로 묶입니다.
- 클러스터명이 다르면 동일한 물리적 장비나, 바인딩이 가능한 네트워크상에 있더라도 서로 다른 클러스터로 바인딩 됩니다.
- 디폴트 클러스터명은 elasticsearch
node.name: "<노드명>"
- 실행중인 각각의 elasticsearch 노드들을 구분할 수 있는 노드의 이름을 설정.
- 설정하지 않으면 7버전 이상부터는 호스트명, 6.x 이하 버전에서는 UUID의 첫 7글자가 노드 명으로 설정
node.attr. : "value"
- 노드별로 속성을 부여하기 위한 일종의 네임스페이스를 지정
- 이 설정을 이용하면 hot/warm 아키텍쳐를 구성하거나 물리 장비 구성에 따라 샤드 배치를 임의적으로 조절하는 등의 설정 가능
path.data : ["<경로>"]
- 색인된 데이터를 저장하는 경로를 지정합니다.
- Default : Es설치경로/data
- 배열형태로 여러개의 경로값의 입력이 가능하기 때문에 한 서버에서 디스크 여러개를 사용할 수 있습니다.
path.logs: "<경로>"
- ElasticSearch 실행 로그를 저장하는 경로 지정,
- Default : Es설치경로/logs
- 실행중인 시스템 로그는
<클러스터명>.log형식의 파일로 저장되며, 날짜가 변경되면 날짜가 추가됨.
bootstrap.memory_lock: true
- Elasticsearch가 사용중인 힙 메모리 영역을 다른 자바 프로그램이 간섭 못하도록 미리 점유하는 설정
- true 권장
network.host : <ip주소>
-
ES가 실행되는 서버의 ip 주소
-
Default : 127.0.0.1
-
주석 처리 혹은, 루프백인 경우 개발모드로 실행
-
이 설정을 실제 IP 주소로 변경시, 운영 모드 실행되며, 부트스트랩 체크 시작
-
network.host는 서버의 내/외부 주소를 모두 지정하는데 만약 내부망에서 사용하는 주소와 외부망에서 접근하는 주소를 다르게 설정하고자 하면 아래의 값 들을 이용해서 구분이 가능
network.bind_host: 내부망network.publish_host: 외부망
-
다음은 network.host 설정에 사용되는 특별한 변수값
- _local_ : 루프백 주소
127.0.0.1과 같습니다. Default값 - _site_ : 로컬 네트워크 주소로 설정, 실제로 클러스터링 구성시 주로 설정하는 값
- _global_: 네트워크 외부에서 바라보는 주소로 설정
실제로 클러스터를 구성할 때 설정을 network.host: _site_ 로 해놓으면 서버의 네트워크 주소가 바뀌어도 설정 파일은 변경하지 않아도 되기 때문에 편리.
- _local_ : 루프백 주소
http.port : <포트 번호>
- Elasticsearch가 클라이언트와 통신하기 위한 Http 포트를 설정,
- default : 9200
- 포트가 이미 사용중인 경우 9200~9299 사이의 값을 차례대로 사용
transport.port: <포트 번호>
- ElasticSearch 노드들끼리 서로 통신하기 위한 tcp 포트를 설정
- default : 9300
- 포트가 이미 사용중인 경우 9300~9399 사이의 값을 차례대로 사용.
discovery.seed.hosts: ["<호스트-1>", "<호스트-2>", ...]
- 클러스터 구성을 위해 바인딩 할 원격 노드의 IP 또는 도메인 주소를 배열 형태로 입력.
- 주소만 적는 경우 디폴트로 9300~9305 사이의 값을 검색
- tcp 포트가 이 범위 밖에 설정 된 경우 포트번호 까지 같이 적어줘야함.
- 이렇게 원격에 있는 노드들을 찾아 바인딩 하는 과정을 디스커버리 라고함.
discovery.seed_hosts 옵션은 7.0 이상 부터 추가된 기능
6.x 이전 버전에서는 젠 디스커버리를 사용
cluster.initial_master_nodes : ["<노드-1>", "<노드-2>"]
- 클러스터가 최초 실행될 때 명시된 노드들을 대상으로 마스터 대상으로 마스터 노드를 선출합니다.
cluster.initial_master_nodes 옵션 또한 7.0이상 부터 추가된 기능.
6.x 이전 버전에서는 최소 마스터 후보노드를 지정하기 위해 다음 옵션 사용
discovery.zen.minimum_master_nodes
7.0 버전 부터는 최소 마스터 후보 노드의 크기가 능동적으로 변경
노드의 역할 : Master, Data, Ingest, ML
- ES의 노드는 수행하는 역할들이 존재
- 각자 노드들이 서로 다른 역할을 하도록 클러스터 구성 가능
- 아래 설정들의 모든 디폴트 값은 true 이며 명시된 모든 역할을 수행
- 특정 값들을 false 설정 함으로써, 노드의 역할들을 구분지어 클러스터 구성
node.master : true
- 마스터 후보(master eligible) 노드 여부를 설정
- false 인 경우 마스터 노드 선출 불가능
- 모든 클러스터는 1개의 마스터 노드 존재하며, 마스터 노드가 다운 되거나 끊어진 경우 남은 마스터 후보 노드들 중에서 새로운 마스터 노드 선출
node.data : true
- 노드가 데이터를 저장하도록 함.
- false 인경우 이 노드는 데이터를 저장하지 않음
node.ingest: true
- 데이터 색인시 전처리 작업인 ingest pipeline 작업의 수행을 할 수 있는지 여부 지정
- false 인 경우 이 노드에서는 ingest pipeline 작업을 수행하지 않음.
node.ml : true
- 이 노드가 머신러닝 작업 수행을 할 수 있는지 여부를 지정.
커맨드 라인 설정
elasticsearch.yml 파일에 설정하는 것 외에도 Elasticsearch 실행 시 커맨드 명령에 -E <옵션>=<값> 을 이용해서 환경 설정이 가능합니다. 예를 들어 클러스터명은 my-cluster 노드명은 node-1로 노드를 실행하기 위해서는 다음과 같이 실행합니다.
# 클러스터명: my-cluster / 노드명: node-1 로 노드 실행
$ bin/elasticsearch -E cluster.name=my-cluster -E node.name="node-1"환경설정이 elasticsearch.yml 과 커맨드 명령 -E에 모두 있는 경우에는 -E 명령에서 한 설정이 더 우선 설정됨.
여러서버에 하나의 클러스터로 실행
- Elasticsearch의 노드들은 클라이언트와의 통신을 위한 http 포트(9200~9299), 노드 간의 데이터 교환을 위한 tcp 포트 (9300~9399) 총 2개의 네트워크 통신을 열어두고 있습니다. 일반적으로 1개의 물리 서버마다 하나의 노드를 실행하는 것을 권장하고 있습니다. 3개의 다른 물리 서버에서 각각 1개 씩의 노드를 실행하면 각 클러스터는 다음과 같이 구성
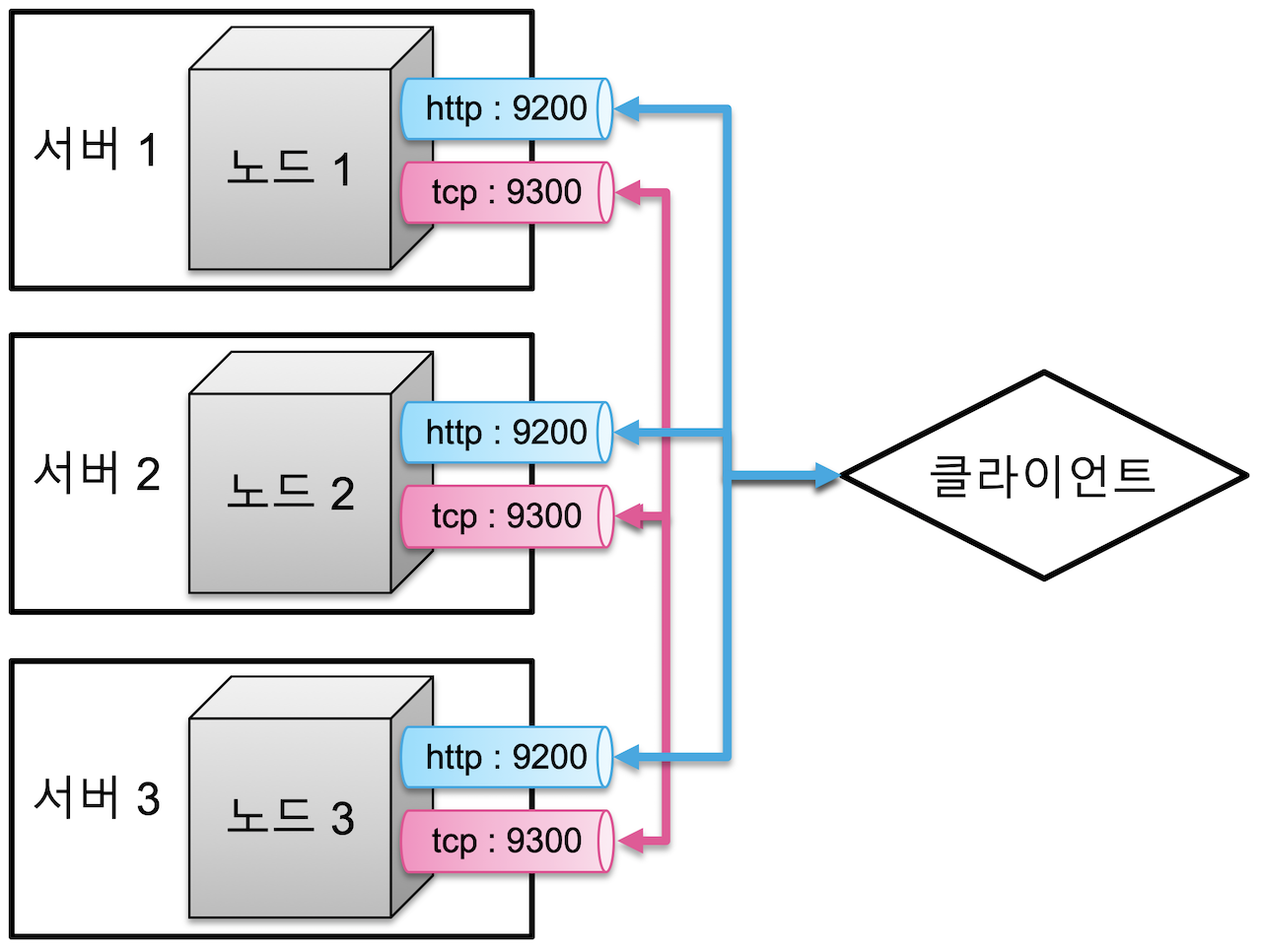
- 하나의 물리적인 서버 안에서 여러 개의 노드를 실행하는 것도 가능합니다. 이 경우에는 각 노드들은 차례대로 9200, 9201… 순으로 포트를 사용하게 됩니다. 클라이언트는 9200, 9201 등의 포트를 통해 원하는 노드와 통신을 할 수 있습니다. 만약에 서버1 에서 두개의 노드를 실행하고, 또 다른 서버에서 한개의 노드를 실행시키면 클러스터는 다음과 같이 구성됩니다.
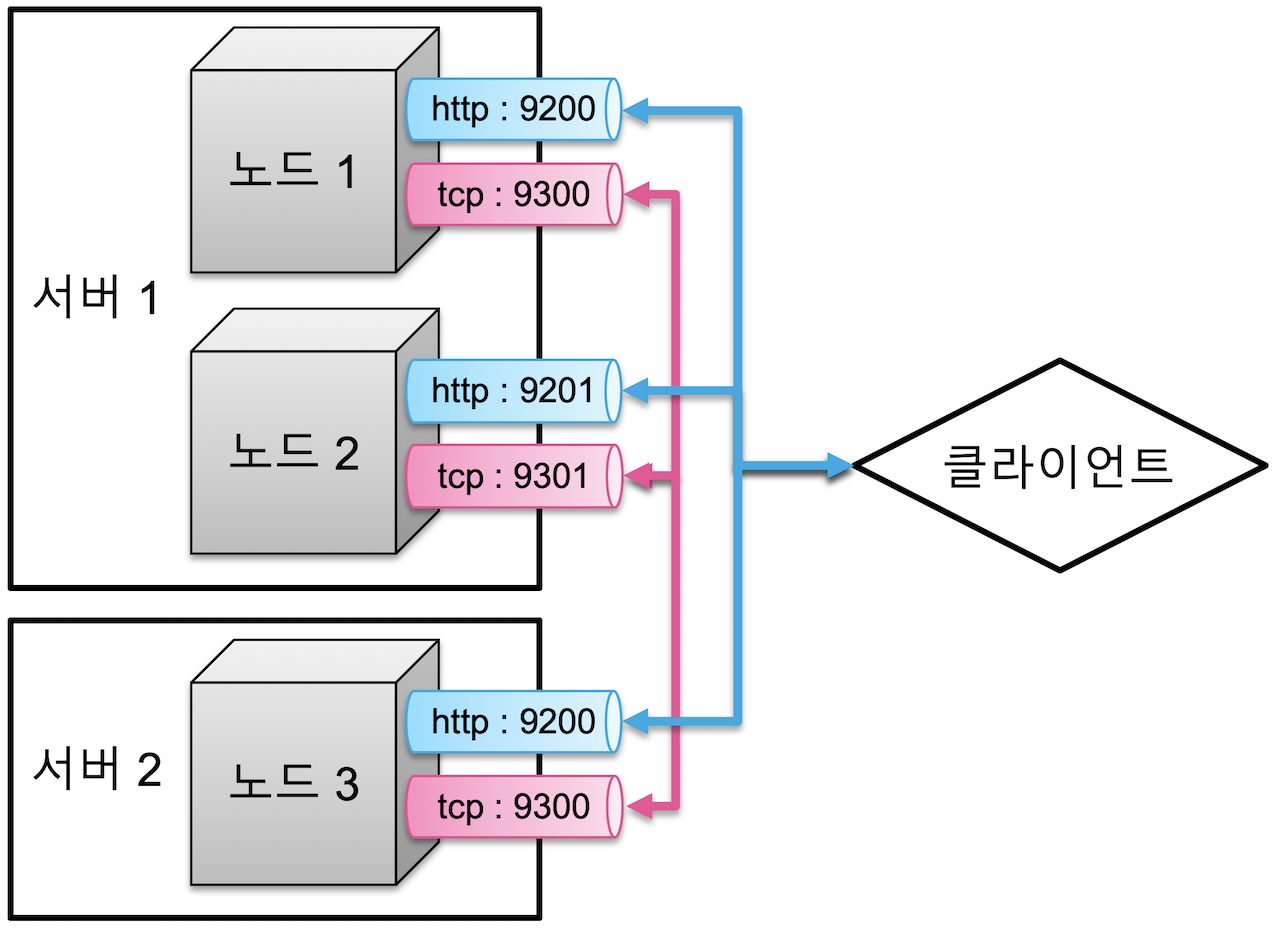
- 서버1에는 두개의 노드가 있기 때문에 서버 1의 두번째 노드는 실행되는 http, tcp 포트가 각각 9201, 9301 로 실행이 됩니다. 물리적인 구성과 상관 없이 여러 노드가 하나의 클러스터로 묶이기 위해서는 클러스터명
cluster.name설정이 묶여질 노드들 모두 동일해야 합니다. 같은 서버나 네트워크망 내부에 있다 하더라도cluster.name이 동일하지 않으면 논리적으로 서로 다른 클러스터로 실행이 되고, 각각 별개의 시스템으로 인식이 됩니다.
하나의 서버에서 여러 클러스터 실행
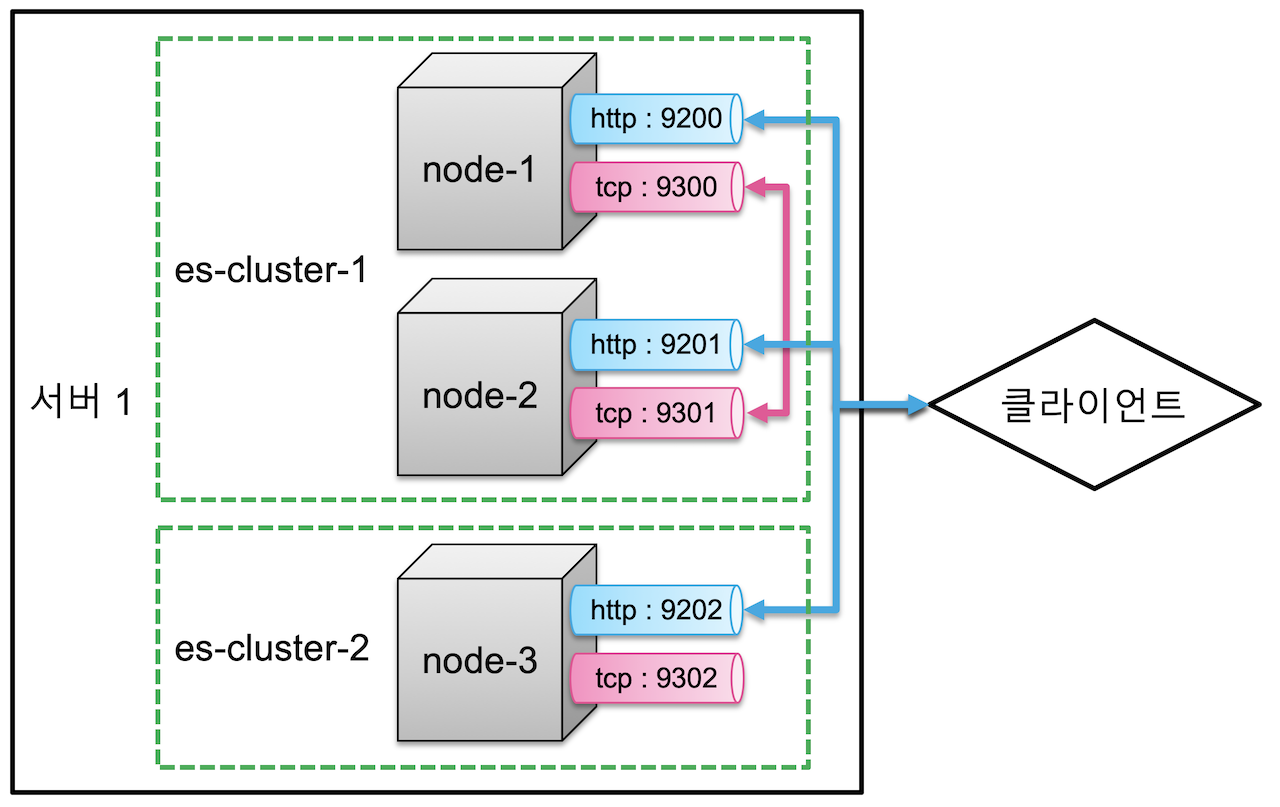
- 하나의 물리 서버에 3개의 노드를 실행시킨다고 가정하면 다음과 같음.
- 노드들의 이름은 각각 node-1, node2, node3
- node-1과 node-2의 클러스터명은 es-cluseter-1 이고, node-3의 클러스터명은 es-cluster-2로 실행
- 설정은 config/elasticsearch.yml 파일에서 아래와 같이 입력
#[node - 1] config/elasticsearch.yml
cluster.name: es-cluster-1
node.name: "node-1"
#[node - 2] config/elasticsearch.yml
cluster.name: es-cluster-1
node.name: "node-2"
#[node - 3] config/elasticsearch.yml
cluster.name: es-cluster-2
node.name: "node-3"node-1 과 node-2는 하나의 클러스터로 묶여있기 때문에 데이터 교환이 일어납니다.
Node-1로 입력된 데이터는 node-2에서도 읽을 수 있으며 그 반대도 가능합니다. 하지만 node-3은 클러스터가 다르기 때문에, node-1, node-2에 입력된 데이터를 node-3에서 읽을 수는 없습니다.
- 위 코드를 그림으로 구성하면 다음과 같습니다.
Discovery
-
노드가 처음 실행될 때 같은 서버,
또는 discovery.seed_hosts: [ ]에 설정된 네트워크 상의 다른 노드들을 찾아 하나의 클러스터로 바인딩하는 과정을 디스커버리 라고 함. -
디스커버리는 다음과 같은 순서로 이루어짐
-
discovery.seed_hosts설정에 있는 주소 순서대로 노드가 있는지 여부를 확인- 노드가 존재하는 경우 >
cluster.name확인- 일치하는 경우 > 같은 클러스터로 바인딩 > 종료
- 일치하지 않는 경우 > 1로 돌아가서 다음 주소 확인 반복
- 노드가 존재하지 않는 경우 > 1로 돌아가서 다음 주소 확인 반복
- 노드가 존재하는 경우 >
-
주소가 끝날때까지 노드를 찾지 못한 경우.
- 스스로 새로운 클러스터 시작
-
클러스터에 노드가 무수히 많아도 보통 discovery.seed_hosts 설정에는 처음에 탐색할 노드 3~5개 정도만 설정하면 큰 문제 없이 클러스터가 바인딩 됩니다. 보통은 마스터 후보 노드들을 지정하게 되며 처음 탐색하는 대상 노드는 반드시 먼저 가동중이어야 합니다.
인덱스와 샤드 - Index & Shards
| 용어 | 뜻 |
|---|---|
| 도큐먼트(Document) | 단일 데이터 단위 |
| 인덱스(Index) | 도큐먼트를 모아놓은 집합 |
| 샤드(shard) | 인덱스의 기본 단위 &루씬의 단일 검색 인스턴스 |
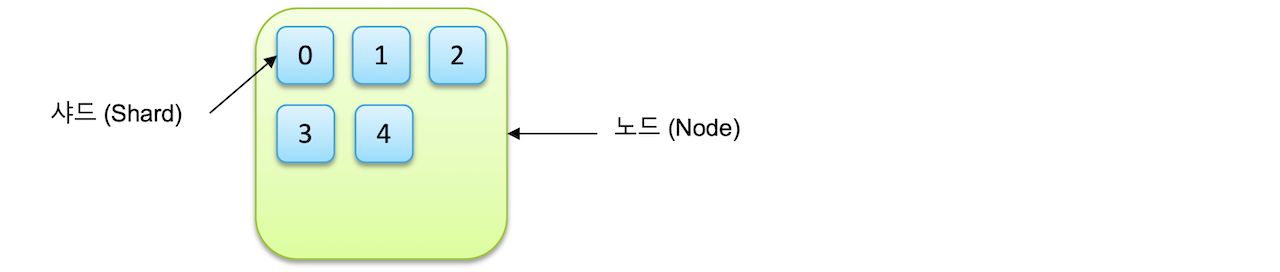
인덱스는 기본적으로 샤드(shard)라는 단위로 분리되고 각 노드에 분산되어 저장이 됩니다.
위 이미지는 하나의 인덱스가 5개의 샤드로 저장되도록 설정한 예
프라이머리 샤드(Primary Shard)와 복제본(Replica)
-
인덱스를 생성할 때 별도의 설정을 하지 않으면 7.0 버전부터는 디폴트로 1개의 샤드로 인덱스가 구성됨
- 6.x 이하 버전에서는 5개로 구성
-
클러스터에 노드를 추가하게 되면 샤드들이 각 노드들로 분산되고 디폴트로 1개의 복제본을 생성
-
처음 생성된 샤드를 프라이머리 샤드, 복제본을 레플리카(Replica) 라고 부릅니다.
-
예를들어 한 인덱스가 5개의 샤드로 구성되어있고 4개의 클러스터로 구성되어 있다고 가정하면
5개의 프라이머리 샤드와 복제본(Replica), 총 10개의 샤드들이 전체노드에 골고루 분배되어 저장.
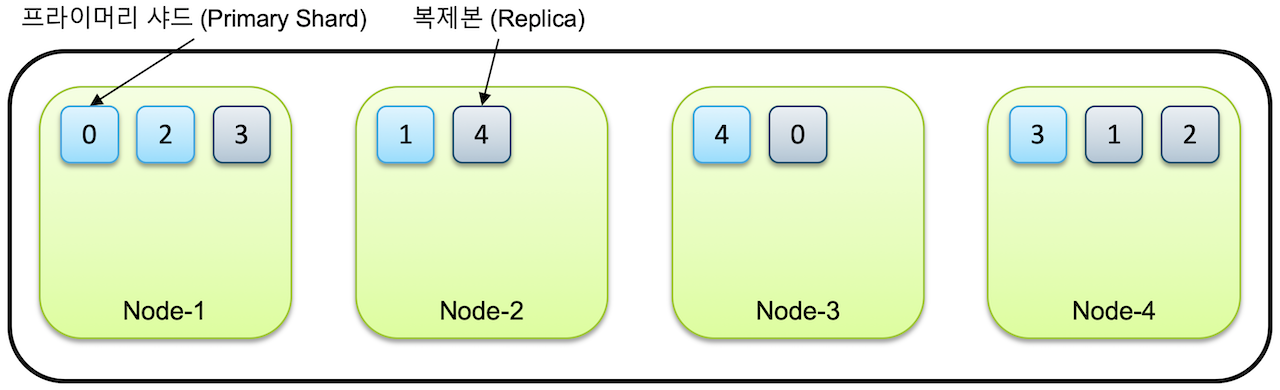
노드가 1개만 있는 경우 프라이머리 샤드만 존재하고 복제본은 생성되지 않습니다.
Elasticsearch는 아무리 작은 클러스터라도 데이터 가용성과 무결성을 위해 최소 3개의 노드로 구성할 것을 권장
- 같은 샤드와 복제본은 동일한 데이터를 담고있으며 반드시 서로 다른 노드에 저장
- 만약에 위 그림에서 Node3 노드가 시스템 다운이나 네트워크 단절등에서 사라지면 이 클러스터는 Node3 에 있던 0번과 4번 샤드들을 유실하게 됩니다. 하지만 아직 다른 노드들, Node1, Node2 에 0번, 4번 샤드가 남아있으므로 여전히 전체 데이터는 유실없이 사용 가능합니다
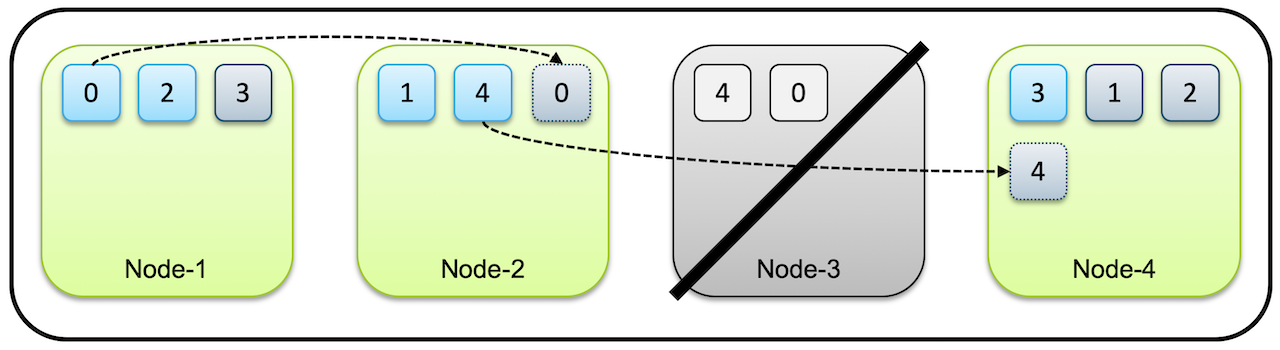
- 처음에 클러스터는 먼저 유실된 노드가 복구되기를 기다립니다.
- 하지만 타임아웃이 지나 유실된 노드가 복구되지 않는다고 판단하면 ElasticSearch는 복제본이 사라져 1개만 남은 0번,4번 샤드의 복제를 시작
- 처음에 4개였던 노드가 3개로 줄어도 복제가 끝나면 샤드와 복제본(Replica) 이 각각 5개씩 총 10개의 데이터로 유지됩니다.
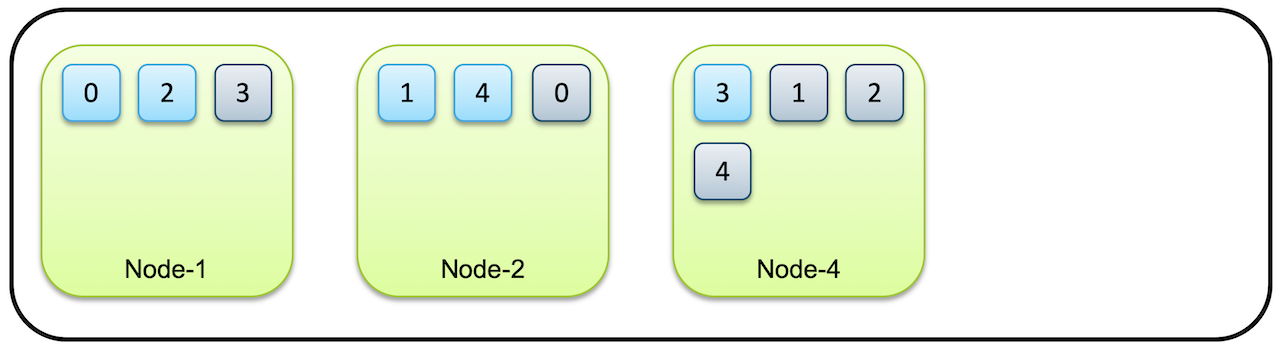
- 이렇게 프라이머리 샤드와 레플리카를 통해 ElasticSearch는 운영중에 노드가 유실되어도
샤드 개수 설정
- 샤드의 개수는 인덱스를 처음 생성할때 지정할 수 있습니다.
- 샤드의 개수는 인덱스를 재색인 하지 않는 이상 바꿀 수 없습니다.
- 다만 복제본의 개수는 나중에 변경이 가능합니다.
# 프라이머리 샤드 5, 복제본 1인 books 인덱스 생성
$ curl -XPUT "http://localhost:9200/books" -H 'Content-Type: application/json' -d'
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}'- books 인덱스의 복제본 수를 0으로 변경하려면 아래 명령으로 업데이트가 가능합니다.
# books 인덱스의 복제본 개수를 0으로 변경
$ curl -XPUT "http://localhost:9200/books/_settings" -H 'Content-Type: application/json' -d'
{
"number_of_replicas": 0
}'- 만약에 4개의 노드를 가진 클러스터에 프라이머리 샤드 5개, 복제본 1개인 books 인덱스, 그리고 프라이머리 샤드 3개 복제본 0개인 Magagine 인덱스가 있다고 하면 전체 샤드들은 아래와 같은 모양으로 배치 될 수 있습니다.
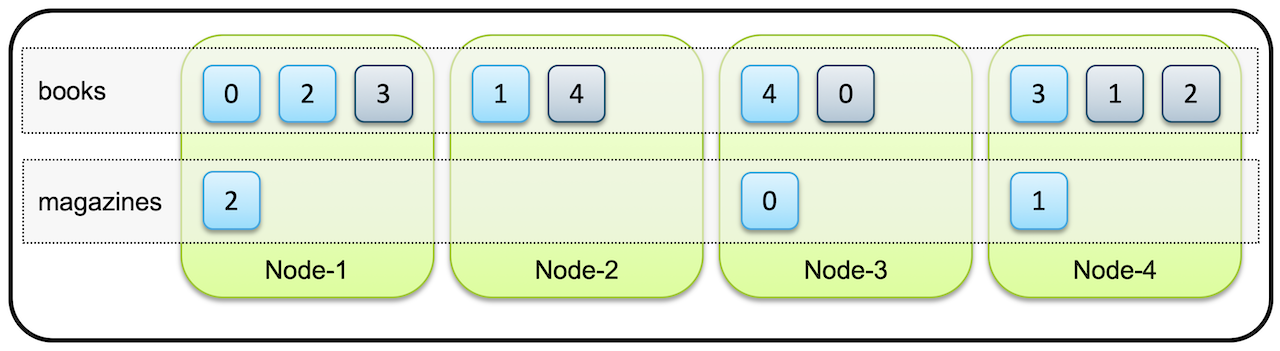
마스터 노드와 데이터 노드 - Master & Data Nodes
마스터 노드
-
Elasticsearch 클러스터는 하나 이상의 노드들로 구성
-
이 중 하나의 노드는 인덱스의 메타 데이터, 샤드의 위치와 같은 클러스터 상태 정보를 관리하는 마스터 노드의 역할을 수행
-
클러스터 마다 하나의 마스터 노드가 존재하며, 마스터 노드 역할을 수행할 수 있는 노드가 없을 경우 클러스터 정지
-
elasticsearch.yml에 디폴트 설정은 node.master: true로 되어 있습니다. -
기본적으로 모든 노드가 마스터 후보 노드 입니다.
-
마스터 노드가 끊어질 경우 다른 마스터 노드 후보중 하나가 마스터 노드로 선출되어 역할을 수행하게 됩니다.
데이터 노드
-
데이터 노드는 색인된 데이터를 저장하고 있는 노드
-
클러스터에서 마스터 노드와 데이터 노드를 분리하여 설정할 때 마스터 후보 노드들은
node.data:false로 설정하여 마스터 노드 역할만 하고 데이터는 저장하지 않도록 할 수 있음.이렇게 하면 마스터 노드는 클러스터 관리만 하게되고, 데이터 노드는 클러스터 관리작업으로부터 자유롭게 되어 데이터 처리에만 집중할 수 있음.
-
다음은 4개의 노드를 실행하는데 node-1은 마스터 역할만 실행하는 전용노드, node2,3,4는 데이터 노드 입니다.
#[node-1] config/elasticsearch.yml
node.master: true
node.data: false
#[node-2] config/elasticsearch.yml
node.master: false
node.data: true
#[node-3] config/elasticsearch.yml
node.master: false
node.data: true
#[node-4] config/elasticsearch.yml
node.master: false
node.data: true- 위와 같이 설정한 4개의 노드를 하나의 클러스터로 묶고 데이터를 입력하게 되면 데이터는 다음과 같이 node 2,3,4에만 저장이 됩니다.
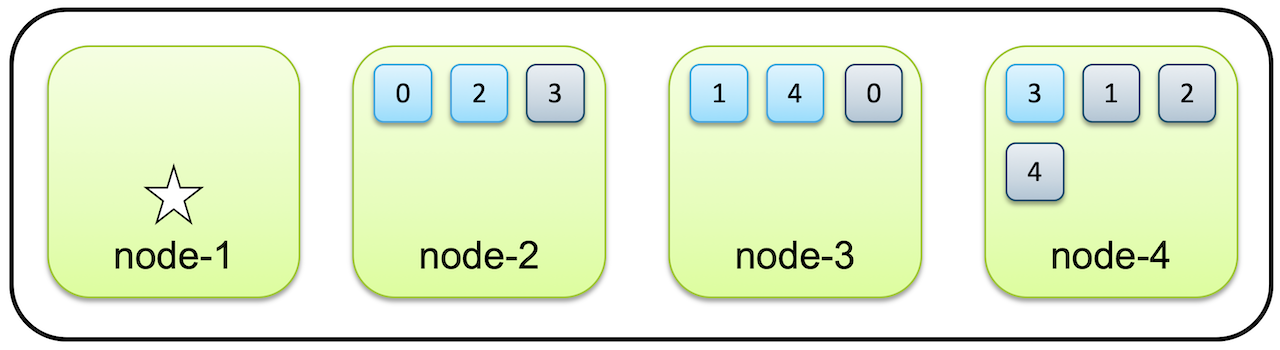
- 키바나에서는 다음과 같이 확인할 수 있습니다.
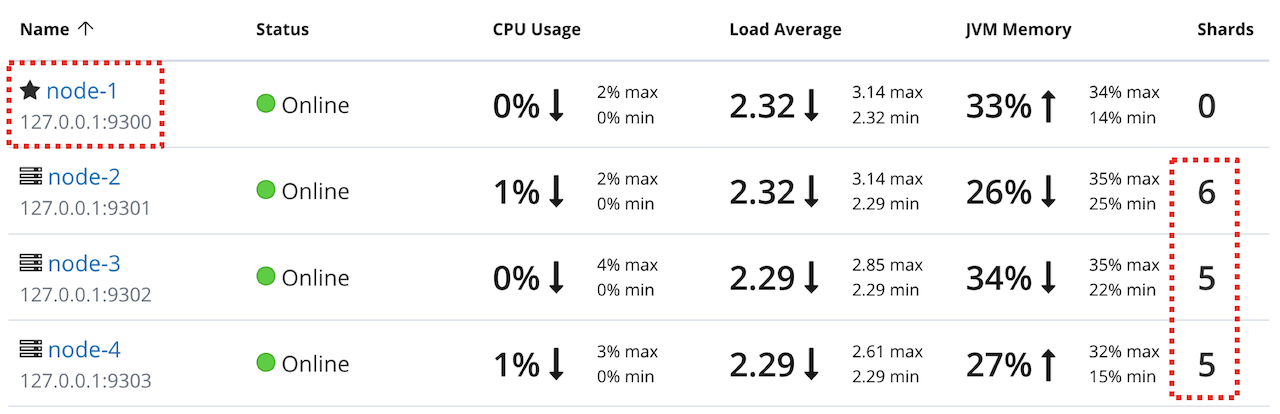
실제 운영환경에서는 위 예제처럼 마스터 후보를 노드 1개만 설정하면 안되고 최소 3개 이상의 홀수개로 설정해야합니다.
이유는 다음의 Split Brain 문제에서 설명
Split Brain
- 마스터 후보 노드를 하나만 놓게 되면 그 마스터 노드가 유실 되었을 때 클러스터 전체가 작동을 정지 할 위험 존재
- 그래서 마스터 후보 노드를 여러개 두는데 3개 이상의 홀수개를 권장
- 짝수개로 운영하는 경우 네트워크 유실상황에서 다음과 같은 상황이 발생할 수 있음.
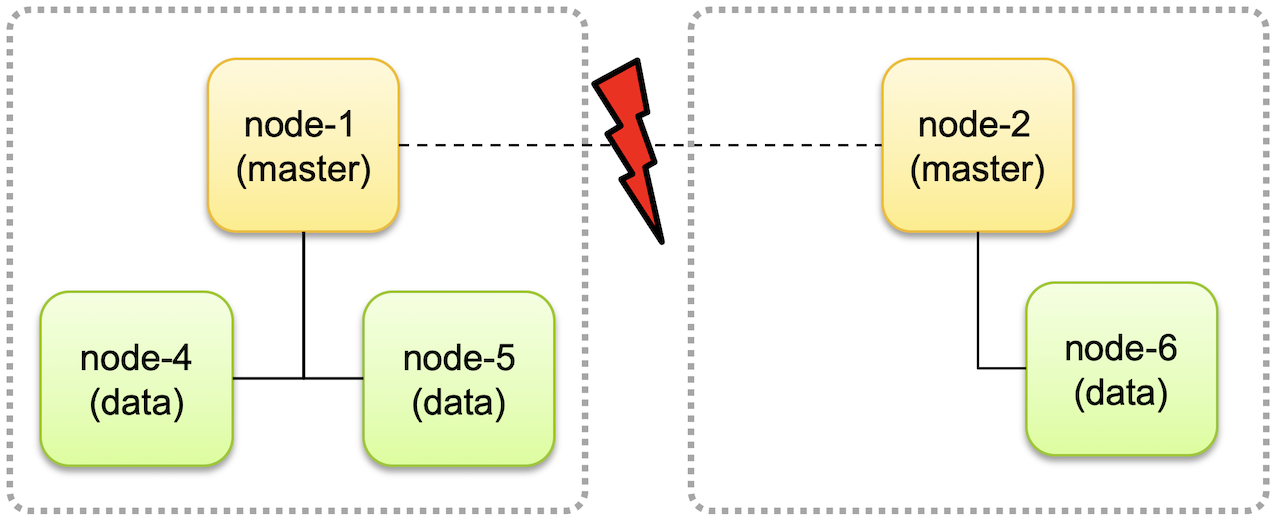
- 위와 같이 네트워크 단절로 후보 node1, node2가 분리되면서 서로 각자 다른 클러스터로 구성되어 동작하는 경우가 발생할 수 있음.
- 이러한 경우 각자의 클러스터에서 데이터가 추가되거나 변경되고 나면 나중에 네트워크가 복구되고 하나의 클러스터로 합쳐졌을때 데이터 정합성에 문제가 생기고 데이터 무결성을 유지할 수 없게 됩니다.
- 이런 문제를
Split Brain이라고 합니다.
- Split Brain을 방지 하기 위해서는 마스터 후보 노드를 3개로 두고 클러스터에 마스터 후보 노드가 최소 2개이상 존재하고 있을때에만 클러스터가 동작하고 그렇지 않은 경우 클러스터는 동작을 멈추도록 수정
- 6.x이하버전에서는
elasticsearch.yml에서discovery.zen.minimum_master_nodes설정을 이용하여 지정가능
#elasticsearch.yml
discovery.zen.minimum_master_nodes:2-
Minimum_master_nodes 값은
(전체 마스터 후보 노드 /2 ) + 1개로 설정되어야 합니다.마스터 후보 노드가 5개인 경우 3으로 설정합니다.
-
7.0 부터는
discovery.zen.minimum_master_nodes설정이 사라지고 대신node.master: true인 노드가 추가되면서 클러스터가 스스로 minimum_master_nodes 노드 값을 변경하도록 되었습니다.따라서 사용자는
cluster.initial_master_nodes: [ ]값만 설정하면 됩니다.
