
카프카 기본 개념 설명
카프카 브로커, 클러스터, 주키퍼
카프카 브로커란?
- 카프카 클라이언트와 데이터를 주고받기 위해 사용되는 주체
- 데이터를 분산 저장하여 장애가 발생하더라도 안전하게 사용할 수 있도록 도와주는 어플리케이션
- 하나의 서버 = 한 개의 카프카 브로커 프로세스
- 브로커 서버 1대로도 기본적인 기능 실행 가능하나, 3대 이상의 브로커 서버를 1개의 클러스터로 묶어 데이터를 안전하게 보관
데이터 저장, 전송
-
프로듀서로부터 데이터를 전달받으면 카프카 브로커는 프로듀서가 요청한 토픽의 파티션에 데이터를 저장
- 프로듀서로 전달된 데이터는 파일 시스템에 저장됨.
- 실습용으로 진행한 카프카에서 저장된 파일 시스템을 확인할 수 있다
ls /tmp/kafka-logs

- config/server.properties의
log.dir옵션에 정의한 디렉토리에 데이터를 저장한다. - 토픽 이름과 파티션 번호의 조합으로 하위 디렉토리를 생성하여 데이터를 저장한다.
- 파티션이 현재 1개 지정되어있어서 Topic-0 만 존재하는 것을 확인할수 있다.
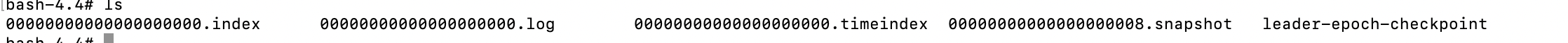
-
각 파티션에 대한 폴더에 들어가면 파티션에 존재하는 데이터를 확인할 수 있다.
-
log에는 메시지와 메타데이터를 저장한다. -
index에는 메시지의 오프셋을 인덱싱한 정보를 담은 파일이다. -
timestamp파일에는 메시지에 포함된 timestamp값을 기준으로 인덱싱한 정보가 담겨있다.- 0.10.0.0 버전 이후에는 메시지에는 timestamp값이 포함된다.
- timestamp값은 브로커가 적재한 데이터를 삭제하거나 압축하는데 사용된다.
-
-
컨슈머가 데이터를 요청하면 파티션에 저장된 데이터를 전달
-
카프카는 페이지캐시를 사용하여 디스크 입출력속도를 높이는 방법을 사용했다.
- 단순히 카프카가 메모리나, 데이터베이스에 저장하지 않으며 캐시메모리도 구현하지 않고 파일시스템에 데이터를 저장 하면서도 속도 이슈가 발생하지 않는 이유이다.
페이지캐시란 OS에서 파일 입출력의 성능향상을 위해 만들어 놓은 메모리 영역(캐시 영역)을 뜻하며, 한번 읽은 파일의 내용은 메모리의 페이징 캐시영역에 저장시킨다. 추후 동일한 파일의 접근이 일어나면 디스크에서 읽지 않고 메모리에서 이를 읽어 속도문제를 해결할 수 있다.- JVM위에서 동작하는 카프카 브로커가 페이지 캐시를 사용하지 않는다면 지금과 같이 빠른 동작을 기대할 수 없을 것이다. (카프카에서 캐시를 직접 구현해야 했을 것이고 지속적으로 변경되는 데이터 때문에 가비지 컬렉션이 자주 일어났을 것이고 이는 속도저하를 유발했을 것이다.)
- 위와 같은 이유로 카프카 브로커를 실행하는데 힙 메모리 사이즈를 크게 설정할 필요가 없다.
데이터 복제 싱크
-
데이터 복제(Replication)는 카프카를 장애 허용시스템으로 동작하도록 하는 원동력
- 일부 장애가 발생하더라도 데이터를 유실하지 않고 안전하게 사용가능
-
카프카의 데이터 복제는 파티션 단위로 이루어진다.
- 토픽을 생성할 때
파티션의 복제 개수(replication factor)도 같이 설정되는데 직접 옵션을 설정하지 않으면, 브로커에 설정된 옵션값을 따라감.
- 토픽을 생성할 때
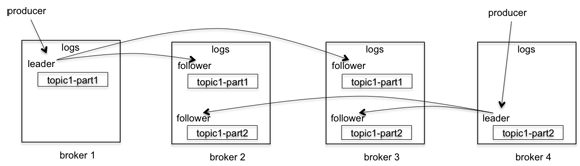
출처 : https://engineering.linkedin.com/kafka/intra-cluster-replication-apache-kafka
-
위 그림을 보면, 각 브로커마다 복제된 파티션을 볼 수 있다.
- 복제된 파티션은 리더(leader)와 팔로워(follower)로 구성된다.
- 리더파티션 : 프로듀서 또는 컨슈머와 직접 통신하는 파티션
- 팔로워 파티션 : 나머지 복제 데이터를 가지고 있는 파티션
-
팔로워 파티션은 리더 파티션의 오프셋을 확인하여, 자신이 가지고 있는 오프셋과 차이가 나는 경우 리더파티션으로부터 데이터를 가져와서 자신의 파티션에 저장, 이 과정을 복제(Replication)이라 한다.
-
복제 개수만큼 저장용량이 증가한다는 단점이 존재하지만, 데이터를 안전하게 사용할수 있다는 강력한 장점때문에 카프카를 운영할 때 2이상의 복제 개수를 정하는 것이 중요하다.
-
또한 브로커1에서 장애가 발생한다면, 브로커2나 브로커3중의 파티션 하나가 리더 파티션 지위를 넘겨받는다.
데이터가 일부 유실되어도 무관하고 데이터 처리 속도가 중요하다면 1또는 2로 설정
금융권 정보와 같이 유실이 일어나면 안되는 데이터의 경우 복제 개수를 3으로 설정하여 최대 2개의 브로커에서 동시에 장애가 발생하더라도 데이터를 안정적으로 유지할 수 있도록 한다.
컨트롤러(controller)
- 클러스터의 다수 브로커 중 한 대가 컨트롤러의 역할을 한다.
- 컨트롤러는 다른 브로커들의 상태를 체크하고, 브로커가 클러스터에서 빠지는 경우 해당 브로커에 존재하는 리더 파티션을 재 분배한다.
데이터 삭제
- 카프카는 컨슈머가 데이터를 가져가더라도 토픽의 데이터를 삭제하지 않는다.
- 또한, 컨슈머나 프로듀서가 데이터 삭제를 요청할 수 없다.
- 오직 브로커만이 데이터를 삭제 할 수 있다.
- 데이터 삭제는 파일단위로 이루어지는데, 이 단위를 로그 세그먼트(log segment)라고 한다.
- 이 세그먼트에는 다수의 데이터가 들어잇기 때문에 일반적인 데이터베이스처럼 특정데이터를 선별해서 삭제할 수 없다.
- 세그먼트는 데이터가 쌓이는 동안 파일 시스템으로 열려있으며 카프카 브로커에
log.segment.bytesehsmslog.segment.ms옵션에 값이 설정되면 세그먼트 파일이 닫힌다. - 세그먼트 파일이 닫히게 되는 기본값은 1GB 용량에 도달했을 때인데, 간격을 더 줄이고 싶다면 작은 용량으로 설정하면 된다.
- 그러나 너무 작은 용량으로 설정하면 데이터들을 저장하는동안 세그먼트 파일을 자주 여닫음으로써 부하가 발생할 수 있기 때문에
Trade off에 주의할 것.
- 그러나 너무 작은 용량으로 설정하면 데이터들을 저장하는동안 세그먼트 파일을 자주 여닫음으로써 부하가 발생할 수 있기 때문에
- 닫힌 세그먼트 파일은 log.retentions.bytes 또는 log.retention.ms 옵션에 설정값이 넘으면 삭제된다.
카프카는 데이터를 삭제하지 않고 메시지키를 기준으로 오래된 데이터를 압축하는 정책을 가져갈 수도 있다.
컨슈머 오프셋 저장
- 컨슈머 그룹은 토픽이 특정 파티션으로부터 데이터를 가져가서 처리하고 이 파티션의 어느 레코드까지 가져갔는지 확인하기 위해 오프셋을 커밋한다.
- 커밋한 오프셋은 __consumer_offsets 토픽에 저장한다. 저장된 오프셋을 토대로 컨슈머 그룹은 다음 레코드를 가져가서 처리한다.
코디네이터(coordinator)
- 클러스터의 다수 브로커 중 한 대는 코디네이터의 역할을 수행한다.
- 코디네이터는 컨슈머 그룹의 상태를 체크하고 파티션을 컨슈머와 매칭되도록 분배한다.
- 컨슈머가 컨슈머 그룹에서 빠지면 매칭되지 않은 파티션을 정상 동작하는 컨슈머로 할당하여 끊임없이 데이터가 처리될 수 있도록한다.
- 이렇게 파티션을 컨슈머로 재할당하는 과정을 리밸런스(rebalance)라고 한다.
여기까지 브로커의 역할에 대해 알아보았다. 그렇다면 카프카 클러스터를 운영할 때 주키퍼가 하는 역할은 무엇일까?
주키퍼는 카프카의 메타데이터를 관리하는데 사용된다. 어떤 데이터를 저장하는지 쉘 명령어를 통해 사용할 수 있는 내부 명령어들에 대한 설명은 주키퍼 공식 홈페이지에 확인할 수 있다. 주키퍼 쉘 명령어는 zookeeper-shell.sh로 실행할 수 있으며 bin 폴더 내에 존재.
토픽과 파티션
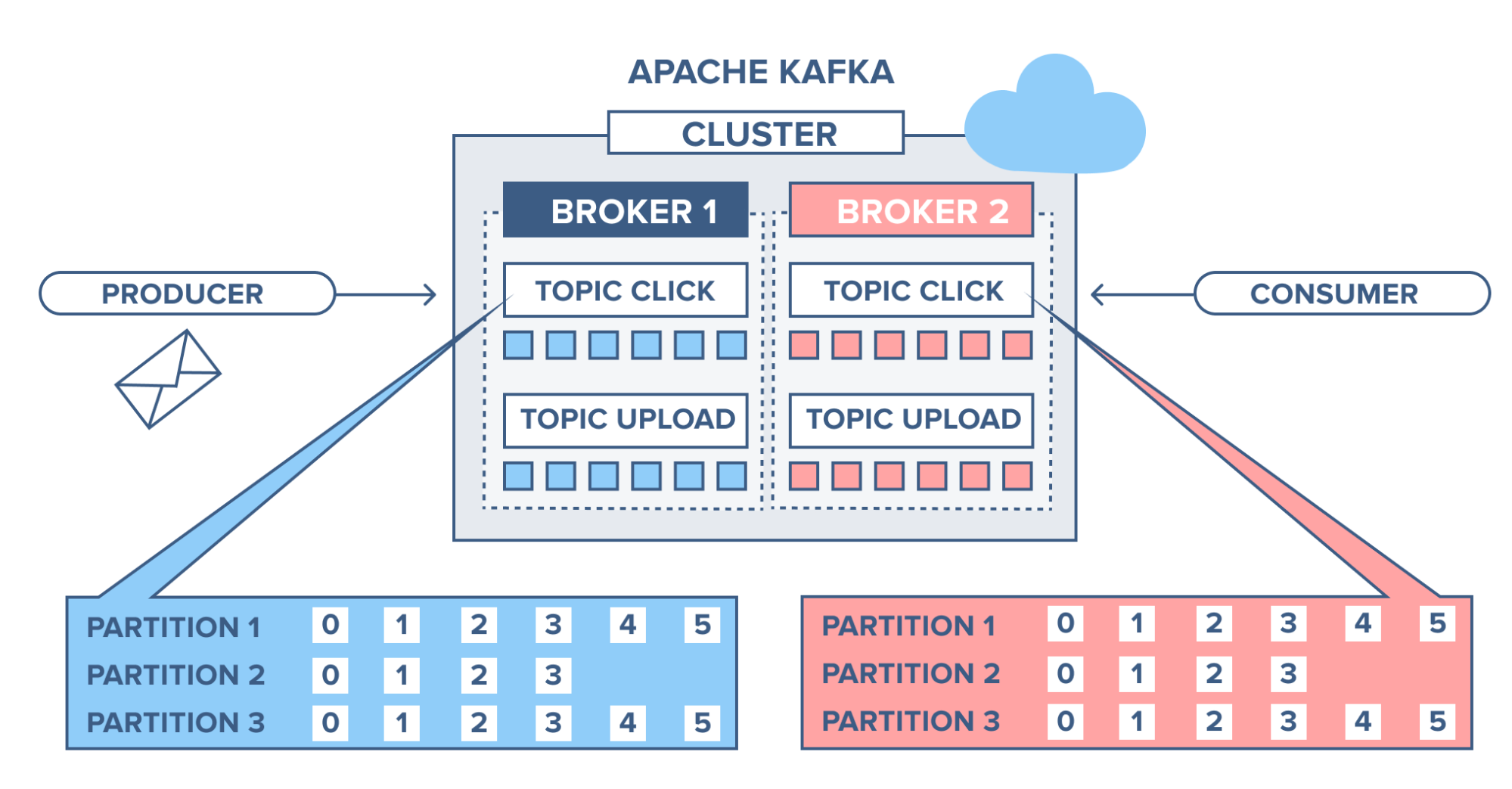
출처 : https://www.cloudkarafka.com/blog/part1-kafka-for-beginners-what-is-apache-kafka.html
- 토픽은 카프카에 데이터를 구분하기 위해 사용하는 단위이다.
- 토픽은 1개이상의 파티션을 소유하고 있다.
- 파티션에는 프로듀서가 보낸 데이터들이 들어가 저장되는데 이 데이터를 레코드라고 한다.
- 파티션은 카프카의 병렬처리의 핵심으로써 그룹으로 묶인 컨슈머들이 레코드를 병렬로 처리할 수 있도록 매칭된다.
- 컨슈머의 처리량이 한정된 상황에서 많은 레코드를 병렬로 처리하는 가장 좋은 방법은 컨슈머의 개수를 늘려 스케일 아웃하는 것이다.
- 컨슈머 개수를 늘림과 동시에 파티션 개수를 늘리면 처리량이 증가하는 효과를 볼 수 있다.
- 파티션은 큐와 비슷한 구조라고 생각하면 좋다.
- FIFO구조처럼, 먼저 들어간 레코드는 컨슈머가 먼저 가져가게 된다.
- 다만 일반적인 자료구조로 사용되는 큐는 데이터를 가져가면 레코드를 삭제하지만 카프카는 삭제하지않는다.
- 이러한 특징때문에 토픽의 레코드는 다양한 목적을 가진 여러 컨슈머 그룹들이 토픽의 데이터를 여러번 가져갈 수 있다.
토픽이름 제약조건
- 토픽 이름을 생성할때 제약조건이 있다.
- 빈 문자열 지원 X
- 토픽이름은 마침표 하나 또는 둘로 생성될 수 없다.
- 토픽 이름의 길이는 249자 미만이어야 한다.
- 토픽 이름은 영어 대소문자, 숫자, 마침표(.), 언더바(_), 하이픈(-) 조합으로 생성할 수 있다.
- 카프카 내부 로직 관리 목적으로 사용되는 토픽(
__consumer_offsets,__transaction_state)은 생성 불가능하다. - 내부적으로 사용하는 로직 때문에 토픽 이름에 마침표와 언더바가 동시에 들어가면안된다.
- 생성은 가능하나, 이슈가 발생할 수 있기 때문에
WARNING표시
- 생성은 가능하나, 이슈가 발생할 수 있기 때문에
토픽 작명 법
-
토픽이름을 모호하게 작성하면 유지보수시 큰 어려움을 겪을 수 있다.
-
따라서 토픽이름을 통해 어떤 개발환경에서 사용되는 것인지 판단하고, 어떤 데이터 타입을 다루는지 유추할 수 있어야 한다.
-
토픽 작명 예시
- <환경>.<팀-명>.<어플리케이션-명>.<메시지타입>
- dev.mybox-photo.face-consumer.json
- <프로젝트-명>.<서비스-명>.<환경>.<이벤트-명>
- commerce.payment.stage.notification
- <환경>.<팀-명>.<어플리케이션-명>.<메시지타입>
중요한 것은 토픽이름에 대한 규칙을 사전에 정의하고 그 규칙을 잘따르는 것이 중요하다.
레코드
- 레코드는
타임스탬프,메시지키,메시지 값,오프셋으로 구성되어있다. - 프로듀서가 생성한 레코드가 브로커로 전송되면 오프셋과 타임스탬프가 지정되어 저장된다.
- 브로커에 한번 적재된 레코드는 수정할 수 없으며, 로그 리텐션 기간 또는 용량에 따라서만 삭제 된다.
- 레코드에 지정되는 타임스탬프에는 브로커 기준 유닉스 시간이 설정
- 컨슈머는 레코드의 타임스탬프를 토대로 레코드가 언제 브로커에 적재되었는지 알 수 있다.
- 다만 프로듀서가 레코드를 생성할 때 임의의 타임스탬프 값을 설정할 수 있다
- 메시지 키는 메시지 값을 순서대로 처리하거나 메시지 값의 종류를 나타내기 위해 사용
- 메시지 키를 사용하면 프로듀서가 토픽에 레코드를 전송할 때 메시지 키의 해시값을 토대로 파티션을 지정하게된다.
- 즉, 동일한 메시지 키라면 동일 파티션에 들어가는 것이다.
- 다만 어느 파티션에 지정될지는 알수 없고 파티션 개수가 변경되면 메시지키와 파티션 매칭이 달라지므로 주의해야한다.
- 만약 메시지 키를 선언하지 않으면 null로 설정된다.
- null로 선언시 프로듀서 기본 설정 파티셔너에 따라서 파티션에 분배되어 적재된다.
- 메시지 값에는 실질적으로 처리할 데이터가 들어있다.
- 메시지 키와 메시지 값은 직렬화되어 브로커로 전송되기 때문에 컨슈머가 이용할 대는 직렬화한 형태와 동일한 형태로 역직렬화를 수행해야한다.
- 만약 프로듀서가
StringSerializer로 직렬화한 메시지 값을 컨슈머가IntegerDeserializer로 역직렬화하면 정상적인 데이터를 얻을 수 없다. - 레코드의 오프셋은 0 이상의 숫자로 이루어져있다. 레코드의 오프셋은 직접 지정할 수 없고 브로커에 저장될 대 이전에 전송된 레코드의 오프셋 + 1 값으로 생성된다.
- 오프셋을 사용하면 컨슈머 그룹으로 이루어진 카프카 컨슈머들이 파티션의 데이터를 어디까지 가져갔는지 명확히 지정할 수 있다.
카프카 클라이언트
프로듀서 API
- 카프카에서 데이터의 시작점은 프로듀서이다.
- 프로듀서는 데이터를 전송할 때 리더 파티션을 가지고 있는 카프카 브로커와 직접 통신한다.
- 프로듀서는 데이터를 직렬화하여 카프카 브로커로 보내기 때문에 자바에서 선언 가능한 모든 형태를 브로커로 전송할 수 있다.
카프카 프로듀서 생성
- build.gradle
plugins {
id 'java'
}
group 'org.example'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
implementation 'org.apache.kafka:kafka-clients:2.7.0'
implementation 'org.slf4j:slf4j-simple:2.0.0-alpha0'
implementation 'org.projectlombok:lombok:1.18.18'
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.7.0'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.7.0'
}
test {
useJUnitPlatform()
}- Producer.java
@Slf4j
public class Producer {
private final static String TOPIC_NAME = "test";
private final static String BOOTSTRAP_SERVER = "localhost:9092";
public static void main(String... args) {
Properties configs = new Properties();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVER);
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(configs);
String messageValue = "testMessage";
ProducerRecord<String,String> record = new ProducerRecord<>(TOPIC_NAME,messageValue);
producer.send(record);
log.info("{}",record);
producer.flush();
producer.close();
}
}이제 카프카 프로듀서가 전송할 토픽을 생성하자
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic test --partition 3
프로듀서 주요 옵션
프로듀서 어플리케이션을 실행할 때 설정해야 하는 필수 옵션과 선택 옵션이 있다.
-
필수 옵션
옵션명 설명 bootstrap.servers 프로듀서가 데이터를 전송할 대상 카프카 클러스터에 속한 브로커의 호스트:포트를 1개이상 작성한다. key.serializer 레코드의 메시지 키를 직렬화하는 클래스를 지정한다. value.serializer 레코드의 메시지 값을 직렬화하는 클래스를 지정한다. -
선택옵션
옵션명 설명 acks 프로듀서가 전송한 데이터가 브로커들에 정상적으로 저장되었는지 전송 성공 여부를 확인하는데에 사용하는 옵션이다. 0,1,-1중 하나로 설정할 수 있다.
1 : 기본값으로써 리더 파티션에 데이터가 저장되면 전송 성공으로 판단
0 : 프로듀서가 전송한 즉시 브로커에 데이터 저장여부와 상관없이 성공으로 판단
-1 : 토픽의min.insync.replicas개수에 해당하는 리더 파티션과 팔로워 파티션에 데이터가 저장되면 성공하는 것으로 판단.buffer.memory 브로커로 전송할 데이터를 배치로 모으기 위해 설정할 버퍼 메모리양을 정한다. 기본값은 32MB retries 프로듀서가 브로커로부터 에러를 받고 난 뒤 재전송을 시도하는 횟수를 지정한다 기본값은 Integer.MAX batch.size 배치로 전송할 레코드 최대 용량을 지정한다. 너무 작게 설정하면 프로듀서가 브로커로 더 자주 보내기 때문에 네트워크 부담이 있고 너무크게 설정하면 메모리를 더 많이 사용하게 되는 점을 주의해야한다
default : 16384linger.ms 배치를 전송하기전까지 기다리는 최소시간이다. 기본값은 0이다 partitioner.class 레코드를 파티션에 전송할 때 적용하는 파티셔너 클래스를 지정한다. 기본값은 org.apache.kafka.clients.producer.internals.DefaultPartionertransactional.id 프로듀서가 레코드를 전송할 때 레코드를 트랜잭션 단위로 묶을지 여부를 설정한다. 프로듀서의 고유한 트랜잭션 아이디를 설정할 수 있다.
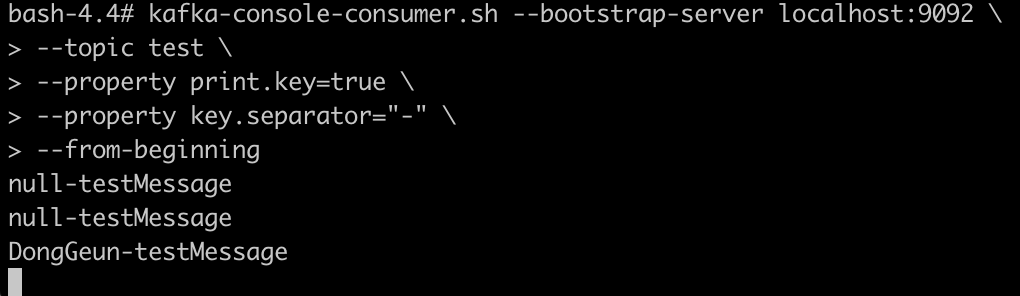
메시지 키를 가진 데이터를 전송하는 프로듀서
// Donggeun 이 key가 들어갈 자리
ProducerRecord<String,String> record = new ProducerRecord<>(TOPIC_NAME,"DongGeun",messageValue);
파티션을 직접 넣고 싶다면 다음과 같이 설정하면 된다.
int partitionNo = 0;
ProducerRecord<String,String> record = new ProducerRecord<>(TOPIC_NAME, partitionNo, messageKey, messageValue);커스텀 파티셔너를 가지는 프로듀서
프로듀서 사용환경에 따라 특정 데티러를 가지는 레코드를 특정 파티션으로 보내야 할때가 있다. 기본 설정 파티셔너를 사용할 경우 메시지 키의 해시값을 파티션에 매칭하여 데이터를 전송하므로 어느 파티션에 들어가는지 알 수 없다. 이때 Partitioner 인터페이스를 사용하여 사용자 정의 파티셔너를 생성하면 특정값을 가진 메시지키에 대해서 무조건 정해진 파티션으로 데이터를 전송하도록 설정할 수 있다.
public class CustomPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
if(keyBytes ==null){
throw new InvalidPartitionsException("Need message key");
}
//특정 파티션 값으로 보내도록
if(((String)key).equals("DongGeun")){
return 0;
}
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
//기본 값
return Utils.toPositive(Utils.murmur2(keyBytes) % numPartitions);
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}커스텀 파티셔너를 지정한 경우 ProducerConfig의 PARTITONER_CLASS_CONFIG을 사용자 생성 파티셔너로 설정하여 KafkaProducer 인스턴스를 생성해야 된다.
Properties configs = new Properties();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVER);
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class);브로커 정상 전송 여부를 확인하는 프로듀서
KafkaProducer의 send() 메소드는Future객체를 반환한다.- 이 객체는
RecordMetadata의 비동기 결과를 표현하는 것으로 ProducerRecord가 카프카 브로커에 정상적으로 적재되었는지에 대한 데이터가 포함되어있다. - get() 메소드를 사용하면 프로듀서로 보낸 데이터의 결과를 동기적으로 가져올 수 있다.
ProducerRecord<String,String> record = new ProducerRecord<>(TOPIC_NAME, messageValue);
RecordMetadata metadata = producer.send(record).get();
logger.info(metadata.toString());- send()의 결과값은 카프카 브로커로부터 응답을 기다렸다가 브로커로부터 응답이 오면 RecordMetaData 인스턴스를 반환한다.

- 레코드가 정상적으로 적재되었다면,
토픽이름과파티션 번호,오프셋 번호가 출력된다.- 위 경우는 0번 파티션에 2번 오프셋인것을 알 수 있다.
- 하지만 동기로 프로듀서의 전송 결과를 확인하는 것은 빠른 전송에 허들이 될 수 있다. 프로듀서가 전송하고 난 뒤 브로커로부터 전송에 대한 응답 값을 받기 전까지 대기하기 때문이다.
- 따라서 비동기로 결과를 확인할 수 있도록 Callback 인터페이스를 제공하고 있다.
- 사용자는 사용자 정의 Callback 클래슬르 생성하여 레코드의 전송결과에 대응하는 로직을 만들 수 있다.
public class Consumer {
private final static Logger logger = LoggerFactory.getLogger(Consumer.class);
private final static String TOPIC_NAME = "test";
private final static String BOOTSTRAP_SERVERS = "localhost:9092";
private final static String GROUP_ID = "test-group";
public static void main(String... args) {
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
//컨슈머 그룹 ID 선언
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
//카프카 컨슈머 선언
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(configs);
//해당 bootstrap의 토픽 구독
consumer.subscribe(Collections.singletonList(TOPIC_NAME));
logger.info("{}","start");
while(true){
//초당 데이터를 가져와서
ConsumerRecords<String,String> records = consumer.poll(Duration.ofSeconds(1));
for(ConsumerRecord<String,String> record : records){
//로그로 뿌리는 역할
logger.info("{}",record.toString());
}
}
}
}컨슈머 그룹을 기준으로 offset을 관리하기 때문에
subscribe()메소드를 사용하여 토픽을 구독하는 경우 컨슈머 그룹을 선언해야 한다. 컨슈머가 중단되거나 재시작되더라도 컨슈머 그룹의 컨슈머 오프셋을 기준으로 이후 데이터 처리를 하기 때문이다. 컨슈머 그룹을 선언하지 않으면 어떤 그룹에도 속하지 않는 컨슈머로 동작하게 된다.


컨슈머 중요개념
토픽의 파티션으로부터 데이터를 가져가기 위해 컨슈머를 운영하는 방법은 크게 2가지가 존재.
- 1개 이상의 컨슈머로 이루어진 컨슈머 그룹을 운영하는 것
- 토픽의 특정 파티션만 구독하는 컨슈머를 운영하는 것
컨슈머 그룹으로 운영하는 방법
- 컨슈머를 각 컨슈머 그룹으로부터 격리된 환경에 안전하게 운영할 수 있도록 도와주는 방식.
- 컨슈머 그룹으로 묶인 컨슈머들은 토픽의 1개 이상 파티션들에 할당되어 데이터를 가져갈 수 있다.
- 컨슈머 그룹으로 묶인 컨슈머가 토픽을 구독해서 데이터를 가져갈때, 1개의 파티션은 최대 1개의 컨슈머에 할당 가능하다.
- 그리고 1개의 컨슈머는 여러개의 파티션에 할당될 수 있다.
- 이러한 특징으로 컨슈머 그룹의 컨슈머 개수는 가져가고자 하는 토픽의 파티션 개수보다 같거나 작아야 한다.
예를들어 컨슈머가 파티션 개수보다 많을 경우, 파티션은 컨슈머에 1대1로 할당되고 남는 컨슈머는 데이터를 처리하지 못하고 불필요한 스레드로 남게 된다.

카프카 궁금했는데 써주신 글들 대략 보며 개념을 잡았내요 감사합니다 !