카프카 커넥트
- 데이터 파이프라인 생성 시 반복 작업을 줄이고 효율적인 전송을 이루기 위한 어플리케이션.
- 반복적인 파이프라인 생성작업시 매번 프로듀서 컨슈머 어플리케이션을 개발하고
배포,운영하는것은 비효율적 - 커넥트를 이용하면 특정한 작업 형태를 템플릿으로 만들어 놓은
커넥터를 실행함으로써 반복작업을 줄일 수 있음. - 커넥터는 프로듀서 역할을 하는 소스커넥터 와 컨슈머 역할을 하는 싱크 커넥터 2가지로 나뉜다.
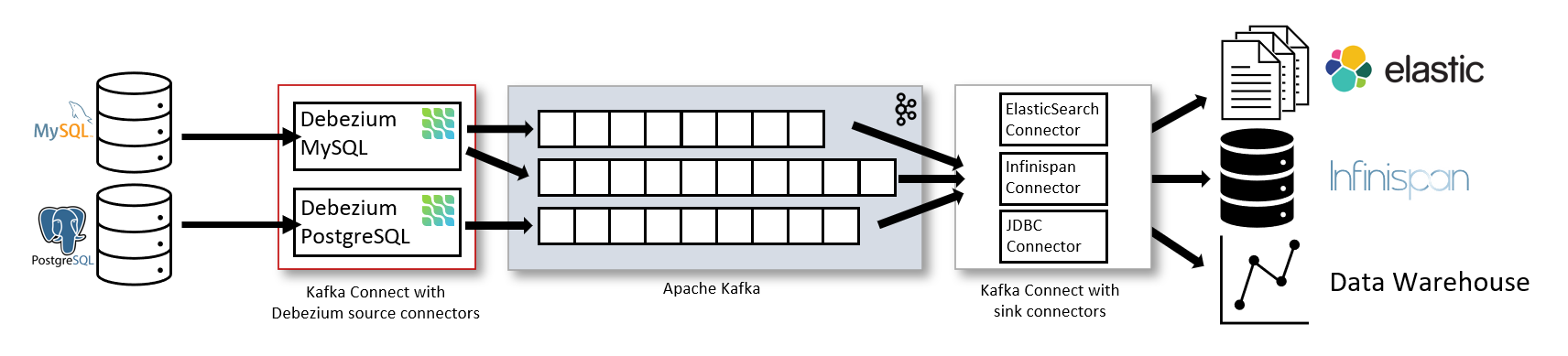
출처: https://debezium.io/documentation/reference/1.3/architecture.html
- 카프카 2.6버전 부터 클러스터 간 토픽 미러링을 지원하는 미러메이커 커넥터와, 파일 싱크 커넥터 , 파일 소스 커넥터를 기본 플러그인으로 제공한다.
- 이외에 추가하고 싶은 커넥터를 사용하고 싶으면 플러그인 형태로 jar파일을 추가하여 사용할 수 있다.
-
사용자가 커넥트에 커넥터 생성 명령을 내리면 커넥트는 내부적으로 커넥터와 태스크를 생성한다. 사용자가 커넥터를 사용하여 파이프라인을 생성할 때
컨버터와트랜스폼기능을 옵션으로 추가할 수 있다.- 반드시 필요한 부분은 아니지만, 데이터 처리를 쉽게 해줌.
- 컨버터의 경우 데이터 처리를 하기전 스키마를 변경하도록 도와줌.
JsonConverter,StringConverter,ByteArrayConverter를 지원하고 필요하다면 커스텀 컨버터를 작성할 수 있다. - 트랜스폼은 데이터 처리 시 각 메시지 단위로 데이터를 간단하게 변환하기 위한 용도로 사용된다. 예를들어, JSON 데이터를 커넥터에서 사용할 때 트랜스폼을 사용하면 특정 키를 삭제하거나 추가할 수 있다. 기본 제공 트랜스폼으로
Cast,Drop,ExtractField등이 있다.
오픈소스 커넥터
- 오픈소스 커넥터는 직접 커넥터를 만들 필요가 없으며 jar파일을 다운로드 하여 사용할 수 있다는 장점
- 종류로는
HDFS,AWS S3,JDBC 커넥터,엘라스틱서치 커넥터등이있다. - 자료는 컨플루언트 허브에서 구할 수 있다.
커넥트를 실행하는 방법
커넥트를 실행하는 방법은 크게 2가지가 존재한다.
단일 모드 커넥트
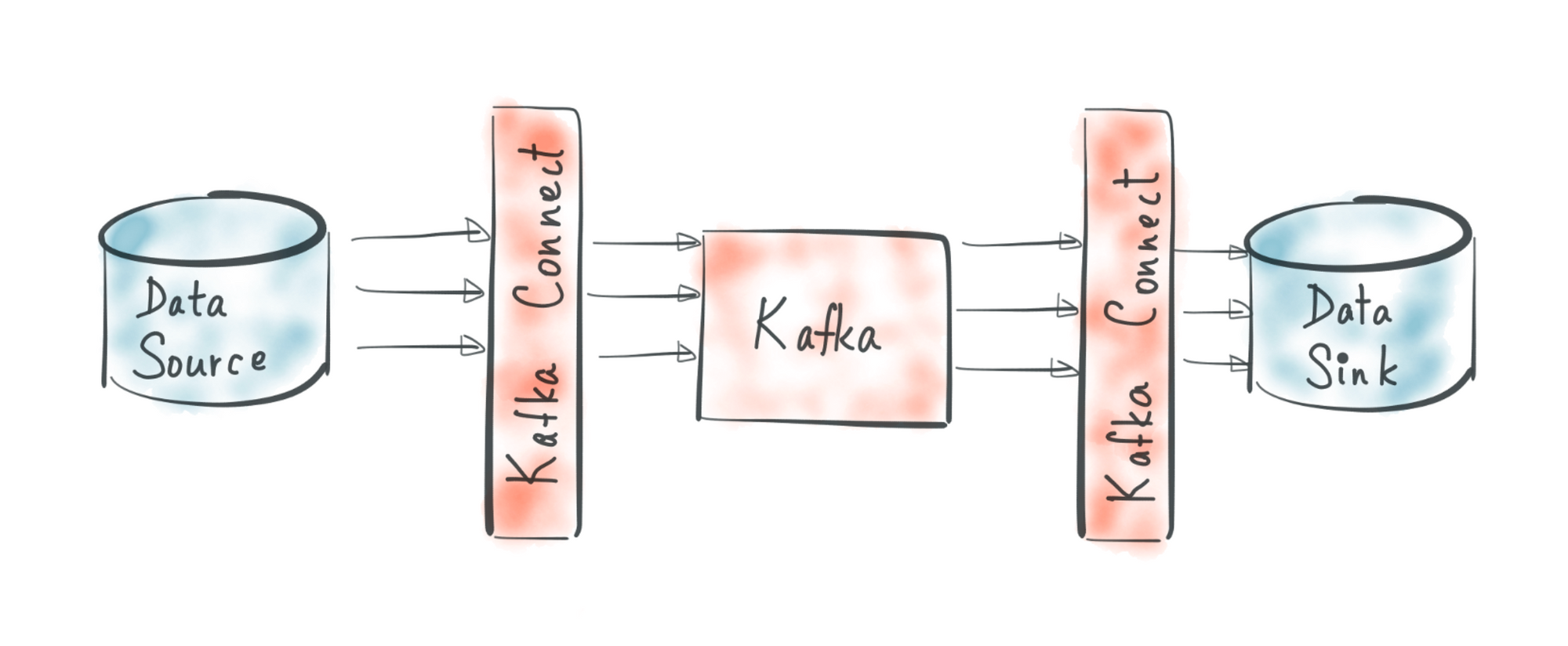
출처 : https://turkogluc.com/apache-kafka-connect-introduction/
- 1개 프로세스만 실행되는점이 특징
- 고 가용성 구성이 되지 않아 단일장애점(Single Point Of Failure)가 될 수 있다.
- 따라서 단일 모드 커넥트 파이프라인은 주로 개발환경이나 중요도가 낮은 파이프라인을 운영할 때 사용
분산모드 커넥트
- 2대 이상의 서버에서 클러스터 형태로 운영함으로써 단일 모드 커넥트 대비 안전하게 운영할 수 있다.
- 데이터 처리량의 변화에도 유연하게 대응할 수 있는 스케일 아웃을 지원한다.
- 따라서 상용환경에서 무중단 운영을 하길 원한다면 분산 모드 커넥트를 2대 이상 구성하고 설정하는 것이 좋다.
- REST API를 사용하면 현재 실행중인 커넥트의 플러그인 종류, 태스크 상태, 커넥터 상태등을 조회할 수 있다.
- 커넥트는 8083 포트로 호출할 수 있으며 HTTP 메소드 기반 API를 지원한다.,
| 요청 메소드 | 호출 경로 | 설명 |
|---|---|---|
| GET | / | 실행 중인 커넥트 정보확인 |
| GET | /connectors | 실행 중인 커넥터 이름 확인 |
| POST | /connectors | 새로운 커넥터 생성 요청 |
| GET | /connectors/{커넥터 이름} | 실행중인 커넥터 정보 확인 |
| GET | /connectors/{커넥터 이름}/config | 실행중인 커넥터의 설정값 확인 |
| PUT | /connectors/{커넥터 이름}/config | 실행중인 커넥터 설정값 변경 요청 |
| GET | /connectors/{커넥터 이름}/status | 실행중인 커넥터 상태 확인 |
| POST | /connectors/{커넥터 이름}/restart | 실행중인 커넥터 재시작 요청 |
| PUT | /connectors/{커넥터 이름}/pause | 커넥터 일시 중지 요청 |
| PUT | /connectors/{커넥터 이름}/resume | 일시 중지된 커넥터 실행 요청 |
| DELETE | /connectors/{커넥터 이름}/ | 실행 중인 커넥터 종료 |
| GET | /connectors/{커넥터 이름}/tasks/{태스크 아이디}/status | 실행 중인 커넥터의 태스크 상태 확인 |
| POST | /connectors/{커넥터 이름}/tasks/{태스크 아이디}/restart | 실행 중인 커넥터의 태스크 재시작 요청 |
| GET | /connectors/{커넥터 이름}/topics | 커넥트에 존재하는 커넥터 플러그인 확인 |
| PUT | /connector-plugins/ | 커넥트에 존재하는 커넥터 플러그인 확인 |
| PUT | /connector-plugins/{커넥터 플러그인 이름}/config/validate | 커넥터 생성 시 설정값 유효 여부 확인 |
단일 모드 커넥트
- 단일 모드 커넥트를 실행하기 위해서는 단일 모드 커넥트를 참조하는 설정파일인
connect-standalone.properties파일을 수정 - 해당 파일은 카프카 바이너리 config 디렉토리에 있다.

위 이미지는 docker http://wurstmeister.github.io/kafka-docker/ 에서 설정된 binary 파일내부의 config이다.
#### connect-standalone.properties
# 커넥트와 연동할 카프카 클러스터의 호스트와 포트 작성
bootstrap.servers=localhost:9092
# 데이터를 카프카에 저장할 때 혹은 카프카에서 데이터를 가져올 때 변환하는 데에 사용한다.
# 카프카 커넥트는 JsonConverter, StringConverter, ByteArrayConverter를 기본으로 제공
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
# 만약 스키마 형태로 제공 X -> enable option을 false로 설정
key.converter.schemas.enable=true
value.converter.schemas.enable=true
#단일모드 커넥트는 로컬파일에 오프셋 정보를 저장.
# 오프셋 정보는 소스커넥터 또는 싱크 커넥터가 데이터 처리 시점을 저장하기 위해 사용됨.
offset.storage.file.filename=/tmp/connect.offsets
# 태스크가 처리 완료한 오프셋을 커밋하는 주기를 설정
offset.flush.interval.ms=10000
#플러그인 형태로 추가할 커넥터의 디렉토리 주소를 입력
plugin.path=
- 단일 모드 커넥트는 커넥트 설정파일과 함께 커넥터 설정파일도 정의하여 실행하여야 함
- 카프카에서 기본으로 제공하는 파일소스 커넥터는 바이너리가 설치된 config 디렉토리에
connect-file-source.properties로 저장되어있다.
#### connect-file-source.properties
# 커넥터의 이름
name=local-file-source
#사용할 커넥터의 클래스 이름을 지정
connector.class=FileStreamSource
#커넥터로 실행할 태스크 개수를 지정
tasks.max=1
#읽을 파일의 위치
file=test.txt
# 읽은 파일의 데이터를 저장할 토픽의 이름을 지정
topic=connect-test- 실행하기
connect-standalone.sh config/connect-standalone.properties \
config/connect-file-source.properties분산 모드 커넥트
- 단일 모드 커넥트와 다르게 2개 이상의 프로세스가 1개의 그룹으로 묶여서 운영.
- 덕분에, 1개의 커넥트 프로세스에 이슈가 발생하더라도 나머지 1개의 커넥트 프로세스가 커넥터를 이어받아서 파이프라인을 지속적으로 실행할 수 있는 특징이 있음.
- 분산 모드 커넥트를 묶어서 운영하기 위해 어떤 설정을 해야하는지 분산 모드 설정 파일인
connect-distributed.properties를 보면 알 수 있다.
##### connect-distributed.properties
# 카프카 브로커 서버
bootstrap.servers=localhost:9092
# 다수의 카프카 프로세스들을 묶을 그룹 이름
group.id=connect-cluster
# 데이터를 카프카에 저장할 때 혹은 카프카에서 데이터를 가져올 때 변환하는데 사용
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
# 스키마 형태를 사용하고 싶지 않다면 enable 옵션을 false로 변경한다.
key.converter.schemas.enable=true
value.converter.schemas.enable=true
# 분산 모드 커넥트는 카프카 내부 토픽에 오프셋 정보를 저장.
# 이 오프셋 정보는 소스 커넥터 또는 싱크 커넥터가 데이터 처리 시점을 저장하기 위해 사용함.
offset.storage.topic=connect-offsets
offset.storage.replication.factor=1
#offset.storage.partitions=25
config.storage.topic=connect-configs
config.storage.replication.factor=1
status.storage.topic=connect-status
status.storage.replication.factor=1
#status.storage.partitions=5
# 오프셋을 커밋하는 주기
offset.flush.interval.ms=10000
# These are provided to inform the user about the presence of the REST host and port configs
# Hostname & Port for the REST API to listen on. If this is set, it will bind to the interface used to listen to requests.
#rest.host.name=
#rest.port=8083
# The Hostname & Port that will be given out to other workers to connect to i.e. URLs that are routable from other servers.
#rest.advertised.host.name=
#rest.advertised.port=
# 추가 플러그인 경로!
# plugin.path=/usr/local/share/java,/usr/local/share/kafka/plugins,/opt/connectors,
#plugin.path=- 분산 모드 커넥트를 실행할 때는 커넥트 설정파일만 있으면 됨.
- 커넥터는 커넥트가 실행된 이후에
REST API를 통해 실행/중단/변경할 수 있음.
connect-distributed.sh ../config/connect-distributed.properties- 서버가 켜짐.
- 상용환경에서는 2대이상의 분리된 서버에서 분산 모드 커넥트를 실행하는 것이 좋다.
소스 커넥터
- 만약 사용한다면 작성
싱크 커넥터
- 만약 사용할 때가 된다면 그때 공부한다는 마인드

수동적인 과신과 행운이 아닌, 능동적인 노력과 치열함