운이 좋게도 최근 몇몇 기업에 서류및 코테등을 통과해서 면접을 진행중이다.
(덕분에 3주 정도 개발을 하지 못했다.)
VisitLog 진행상황
현재 VisitLog라고해서 간단한 사이드 프로젝트를 제작하고있다.
ㅋㅋ 공대 감성이라 디자인은 뭐 조촐하지만 감칠맛 돌게하는 그런디자인이라 생각한다ㅋㅋ
MSA 구조를 지향하고 있고, 다양한 시도를 많이 해보고 있다.
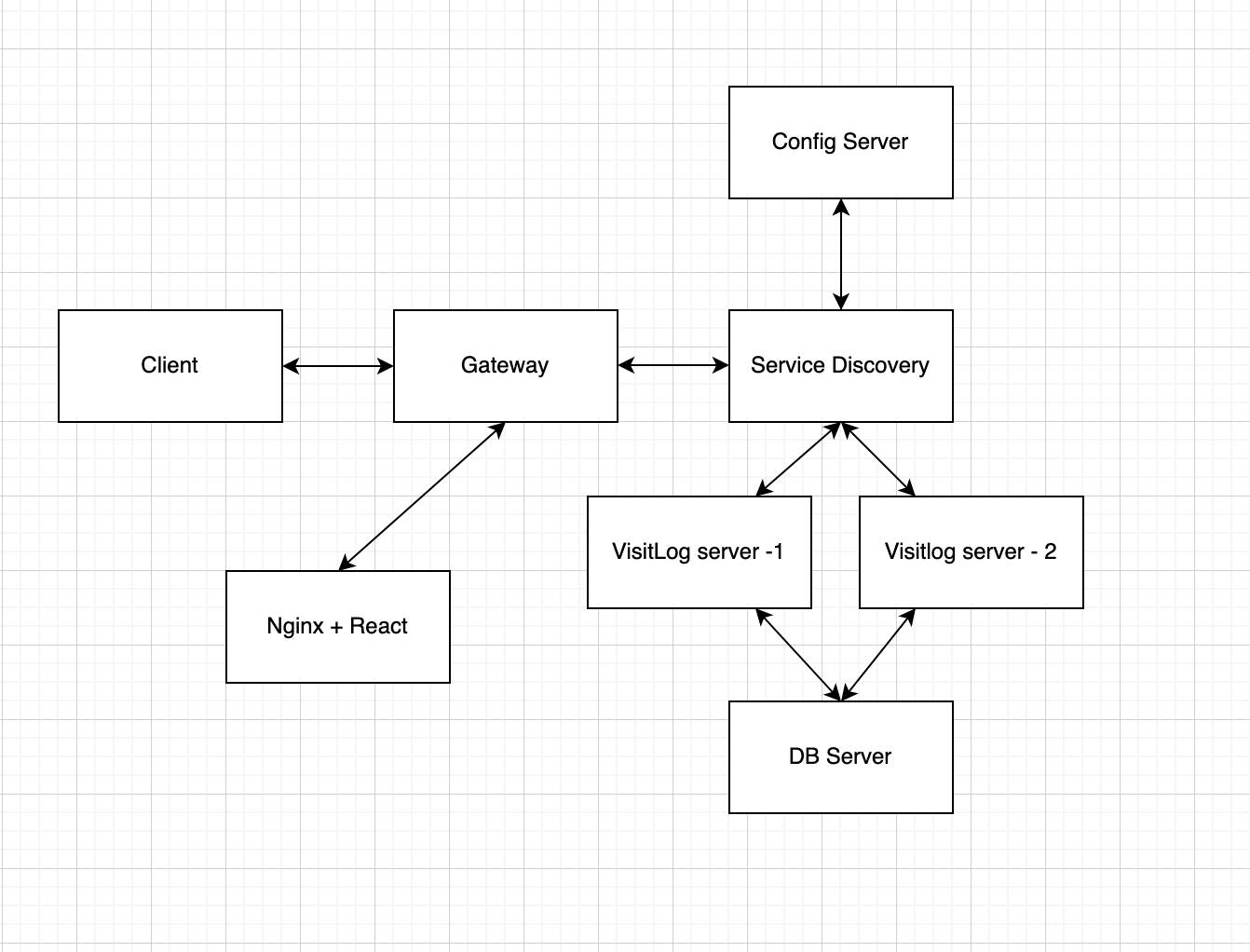
또한 현재 기초적인 틀은 전부 다 만들었다.
- 방문자수 조회 및 기록
- 서비스 디스커버리로 서버의 논리적 위치 -> 물리적 위치 매핑 가능
- Zuul + Ribon 을 통한 Client Side LoadBalancing
뭐 별거없어서 더 해야 하나 생각하고 있고 현재 생각중인 부분은
- 방문자수 그래프를 통한 조회기능( 데이터는 쌓아두고 있지만 그 것에 대해 활용하지 않음)
- Auth Server와 Zuul Gateway를 통한 회원 인증제도 도입
- MySql DB 구조 재설계 (수평 분할을 통해서 검색효율을 늘리고싶음. + Sharding까지)
- 방문자 중복 체크 기능(Cookie + Redis)
잠시 면접 준비는 하긴 싫고 해서,, 어떻게 만들지 생각해보는중..
생각나는대로 글을 쓸 예정이다.
방문자 중복체크 기능
일단 VisitLog의 방문자 수의 체크하는 기능에 방문자 중복 체크 기능을 넣으면 사용자 입맛을 더 다양하게 자극해볼 수 있지 않을까 한다.
중복체크에 대한 DB조회의 비효율성
하지만 사용자가 여길 방문했다 저길 방문했다 하는 정보에 대해 DB전체를 조회하는 것은 너무 비효율적이라 생각.
1차적으로 떠오른 방식이, Cookie와 Redis를 통한 Cache였다.
사용자 IP address(혹은 Mac Address)와 게시글 ID에 대한 정보를 통해서 같은 게시글을 판별유무를 확보할 수 있게하자.
Cookie를 사용할까?
아무래도 클라이언트에 자원을 저장하기 때문에 공간적인 측면에서 효율적일 것이라 생각했다.
먼저 Cookie는 지워버리면 그만이라고 생각했다.
Cookie는 결국 클라이언트 단에서 저장하는 자원, 지원버리거나 저장하지 못하도록 하면 서버단에는 계속 새로운 사용자가 포스팅을 읽을것이라 생각했다.
Redis를 사용할까?
Redis는 In-memory db로 Cache로 사용하기에 알맞다.
또한 서버에서 사용자의 접속로그를 기록하기에, 보다 정확하게 사용자의 중복접속을 제외한 방문자 수를 체크해줄 수 있을것 같다.
서버의 규모가 커지면 Redis또한 당연히 많은 메모리를 차지하게 될 것이고, 서버 부하를 줄이기에는 이것으로는 부족할 것이라 생각했다.
사실 Redis도 충분할 것이라 생각하지만 더 효율적인 방식은 없을까라고 보는게 맞을듯.
그냥 둘다 사용하자!!
즉 내가 내린 방식은 다음과 같다.
1. 1차적으로 Cookie에 그 정보가 있을 경우, 레디스까지 접근 없이 사용자의 방문자수를 그대로 유지한다.
2. 쿠키에 정보가 없을경우 레디스를 조회하여 사용자가 그 페이지를 방문했다면 방문자수를 그대로 유지한다.
3. 쿠키와 레디스 모두 방문기록이 존재하지 않는다면, DB에 방문기록을 올린다.
4. 쿠키는 날짜를 비교, 레디스는 다음날 00:00시가 지나면 데이터가 휘발되도록 expire를 설정한다.
오 뭔가 효율적일 것 같다.
Auth Server + Zuul Server
음.. 사실 1차 마일스톤에 도입할 생각은 없다.
다만 그냥 내머릿속에 생각이니 끄집어본다.
Auth Server와 Zuul 을 이용한다.
Auth Server에 ZuulFilter를 상속한 PreFilter를 만들어서, Authentication Header에 올바른 Token 값이 들어온다면 해당 요청을 승인해서 다음 MSA로 요청을 전달하고 그렇지 않을 경우는 requestContext.getCurrentContext() 를 통해서 현재 요청을 가져오고, requestContext.unset 혹은 request.setSendZuulResponse(false) 등을 통해서 요청을 거절 하거나 다른 Zuul Response로 응답하게 만들어 두도록 한다.
MYSQL DB 재설계
음.. 사실 이부분에 대한 고민이 제일많다.
아무래도 Mysql 에 Replication이나 Sharding에 대한 경험이 없다보니까, 약간 망설여지는 부분이다.
책이나 친구의 조언을 통해서 아마 조금씩 지식을 개선해나가지 않을까 싶다.
그래서 일단 요 부분은 시간나면서 계속 개선할 예정이긴 하다만..
일단 내생각은 이렇다.
UnixTime의 TimeStamp를 데이터로 받고 년별로 Partioning을 하면 되지 않을까?
너무 가볍게 생각하는 것일 수 있다.
왜 UnixTime의 TimeStamp(1970.01.01이후 초를 변환한것)을 Integer로 받으면 좋다고 생각하는 이유는 다음과 같다.
- Index를 하나로 설정할 수 있거니와 (아 물론 id값도 박긴 해야 하겠지만서도, 내말은 년,월,일 이렇게 분리 안해도 된다 이말이다.)
- 두번째로는 이렇게 함으로써 DB 저장공간도 효율적으로 사용할 수 있다는 것.
- 세번째로는 Date를 비교하는 속도보다 당연히 Number값을 조회/비교 하는것이 훨씬 Performance가 좋을 것이며
- 아스날로 마무리
사실 이글은 면접 및 CS 준비를 하다 쓴 뻘글이기도 하며 얼른 다시 개발하고싶다 ㅋ.ㅋ 😁

가즈아아아아아