카프카 스트림즈
- 카프카 스트림즈는 토픽에 적재된 데이터를 실시간으로 변환하여 다른 토픽에 적재하는 라이브러리
- 스트림즈는 카프카에서 공식적으로 지원하는 라이브러리
- 그래서 카프카 버전 Update -> 카프카 스트림즈 라이브러리 Update
- 따라서 자바 기반 스트림즈 어플리케이션은 카프카 클러스터와 완벽하게 호환되면서 편리한 기능들을 제공(신규 토픽생성, 상태 저장, 데이터 조인,장애 허용)
- 따라서 카프카 클러스터를 운영하면서 실시간 스트림 처리를 해야하는 필요성이 있다면 카프카 스트림즈 어플리케이션을 1순위로 고려하는 것이 좋음
- 빅데이터 처리에 필수적이라고 판단되었던 분산시스템이나 스케줄링 프로그램들은 스트림즈를 운영하는데 불필요.
- JVM 위에서 하나의 프로세스로 실행되기 대문.
카프카 스트림즈를 사용하는 이유
- 데이터 처리에 있어 다양한 기능을 스트림즈 DSL 을 통해 기본적으로 제공하고, 프로세서 API를 통하여 기능을 확장할 수 있음.
-
스트림즈 어플리케이션은 내부적으로
쓰레드를 1개 이상 생성할 수 있고, 쓰레드는 1개 이상의태스크를 가진다.-
스트림즈의 태스크(Task) 는 스트림즈 어플리케이션을 실행하면 생기는 데이터 처리 최소단위
-
3개의 파티션으로 이루어진 토픽을 처리하는 스트림즈 어플리케이션을 실행하면 내부에 3개의 태스크가 생김.
-
컨슈머의 병렬처리를 위해 컨슈머 그룹으로 이루어진 컨슈머 스레드를 여러개 실행하는 것과 비슷하다고 볼 수 있음.
-
카프카 스트림즈는 컨슈머 스레드를 늘리는 방법과 동일하게 파티션과 스트림즈 스레드 개수를 늘림으로써 처리량 을 늘릴 수 있음.
-
- 실제 운영환경에서는 장애가 발생하더라도 안정적으로 운영할 수 있도록 2개 이상의 서버로 구성하여 스트림즈 어플리케이션을 운영함.
- 카프카 스트림즈의 구조와 사용방법을 알기 위해서는 토폴로지와 관련된 개념을 익혀야 한다.
- 토폴로지란? 2개 이상의 노드들과 선으로 이루어진 집합을 뜻한다
링형,트리형,성형등이 존재하는데 스트림즈에서는 트리형 과 유사하다.
-
카프카 스트림즈에서는 토폴로지를 이루는 노드를 하나의 프로세서(Processor)라 부른다.
-
소스 프로세서,스트림 프로세서,싱크 프로세서존재프로세서 명 설명 소스 프로세서 데이터를 처리하기 위해 최초로 선언해야 하는 노드로, 하나 이상의 토픽에서 데이터를 가져오는 역할을 수행 스트림 프로세서 다른 프로세서가 반환한 데이터를 처리하는 역할. 변환, 분기처리와 같은 로직이 데이터 처리의 일종 싱크 프로세서 데이터를 특정 카프카 토픽으로저장하는 역할을 하며 스트림즈로 처리된 데이터의 최종 종착지.
-
- 노드와 노드를 이은 선을 스트림(Stream) 라고 부른다.
- 스트림즈DSL(Domain Specific Language)과 프로세서 API 2가지 방법으로 개발 가능
- 스트림즈 DSL은 스트림 프로세싱에 쓰일만한 다양한 기능들을 자체 API로 만들어 놓았기 때문에 대부분의 변환 로직을 어렵지 않게 개발 가능.
- 스트림즈 DSL로 구현하는 데이터 처리 예시
- 메시지 값을 기반으로 토픽 분기처리
- 지난 10분간 들어온 데이터의 개수 집계
- 토픽과 다른 토픽의 결합으로 새로운 데이터 생성
- 프로세서 API로 구현하는 데이터 처리 예시
- 메시지 값의 종류에 따라 토픽을 가변적으로 전송
- 일정한 시간 간격으로 데이터 처리
여기에 좀 더 자세한 내용을 알고 싶다면 필자는 윌리엄 배젝의
Kafka Streams In Actions시리즈 책을 추천하였다.
스트림즈 DSL
- 스트림즈 DSL은 레코드의 흐름을 추상화한 3가지 개념인
Kstream,Ktable,`GlobalKTable 등이 있다.- 이 3가지 개념은 컨슈머, 프로듀서, 프로세서 API에서 사용되지 않고스트림즈 DSL 에서만 사용되는 개념.
KStream
- KStream은 레코드의 흐름을 표현한 것
키와메시지값으로 구성- KStream으로 데이터를 조회하면 토픽에 존재하는 모든 레코드가 출력
- KStream은 컨슈머로 토픽을 구독하는 것과 동일한 선상에서 사용하는 것이라 간주할 수 있음

출처 : 링크
KTable
- KStream과 다르게
메시지 키를 기준으로 묶어서 사용. KStream은 토픽의 모든 레코드를 조회할 수 있지만 KTable은 유니크한 메시지 키를 기준으로가장 최신 레코드를 사용- 즉 새로운 들어온 데이터에 해당하는 키값이 Table에 존재하면 대체된다.
Global KTable
KTable과 동일하게 메시지 키를 기준으로 묶어서 사용.- 그러나 KTable로 선언된 토픽은 1개 파티션 -> 1개 태스크에 할당
- GlobalKTable로 선언된 토픽은 모든 파티션 데이터가 각 태스크에 할당되어 사용되는 차이점이 존재.
- GlobalKTable을 설명하기 가장 좋은 예는
KStream과KTable이 데이터 조인 을 수행할때 - KStream과 KTable이
조인을 수행하려면 코파티셔닝이 되어있어야 하는데 이를 GlobalKTable을 이용하면 해결 가능
- GlobalKTable을 설명하기 가장 좋은 예는
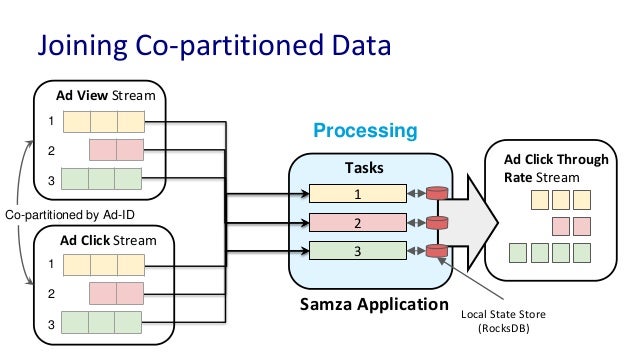
코파티셔닝 전략이란 : 조인을 하는 2개 데이터의 파티션 개수가 동일하고 파티셔닝 전략을 동일하게 맞추는 작업
파티션 개수가 동일하고 파티셔닝 전략이 같은 경우에는 동일한 메시지 키를 가진 데이터가 동일한 태스크에 들어가는 것을 보장 , 이를 통해 KStream의 레코드와 KTable의 메시지 키가 동일할 경우 조인을 수행할 수 있다.
- 여기서 문제는 조인을 수행하려는 토픽들이 Co-Partitioning이 있음을 보장할 수 없다는 것.
Kstream과KTable로 사용하는 2개의 토픽이 파티션 개수가 다를 수도 있고 파티션 전략이 다를수도있음 (이경우 X)- 위 경우
TopologyException이 발생.
- 따라서 문제를 해결하려면 리파티셔닝 과정을 거쳐야 하는데, 이 경우 복잡해짐
- 여기서
GlobalKTable을 사용하면 조인을 사용할 수 있다.- 데이터가 스트림즈 어플리케이션의 모든 태스크에 동일하게 공유되어있기 때문
그러나 GlobalKTable로 정의된 모든 데이터를 저장하고 사용하는 것은 브로커에 많은 부하를 유발하므로 작은 용량의 데이터일 경우에만 사용하는 것을 권장
많은 양의 데이터를 가진 토픽을 조인하는 경우 리파티셔닝을 통해 KTable을 사용하는 것을 권장.
스트림즈 DSL의 주요옵션
- 필수옵션
| 옵션명 | 설명 |
|---|---|
| bootstrap.servers | 프로듀서가 데이터를 전송할 대상 카프카 클러스터에 속한 브로커의 호스트이름: 포트를 1개이상 작성 |
| Application.id | 스트림즈 어플리케이션을 구분하기 위한 고유한 아이디를 설정. 다른 로직을 가진 스트림즈 어플리케이션은 서로 다른 application.id 값을 가져아한다. |
- 선택 옵션
| 옵션명 | 설명 |
|---|---|
| default.key.serde | 레코드의 메시지키를 직렬화, 역직렬화하는 클래스를 지정한다. 기본 값은 바이트 직렬화, 역직렬화 클래스인 Serdes.ByteArray().getClass().getName()이다. |
| default.value.serde | 레코드의 메시지 값을 직렬화, 역직렬화하는 클래스를 지정한다. 기본값은 바이트 직렬화, 역직렬화 클래스인Serdes.ByteArray().getClass().getName()이다. |
| num.stream.threads | 스트림 프로세싱 실행 시 실행될 스레드 개수를 지정한다. 기본값은 1 |
| state.dir | 상태기반 데이터 처리를 할 때 데이터를 저장할 디렉토리를 지정한다. 기본값은 tmp/kafka-streams이다. |
중요
- 요구사항에 맞게
KStream,KTable,GlobalKTable을 사용하는 것이 중요하다.
스트림즈DSL - stream(), to()
- 스트림즈 DSL로 구현할 수 있는 가장 간단한 스트림 프로세싱은 특정 토픽의 데이터를 다른 토픽으로 전달하는 것
- 다음예는 stream_log 토픽에서 stream_log_copy 토픽으로 동일한 데이터를 옮기는 요구사항을 구현해보자.
-
특정 토픽을 KStream 형태로 가져오려면 스트림즈 DSL의
stream()메소드를 사용하면 된다. -
또한 KStream의 데이터를 특정 토픽으로 저장하려면 스트림즈DSL의
to()메소드를 사용하면된다. -
build.gradle
dependencies {
implementation 'org.apache.kafka:kafka-streams:2.7.0'
}- SimpleStreamsApplication.java
public class SimpleStreamsApplication {
//스트림즈 어플리케이션은 어플리케이션 아이디를 지정
//어플리케이션 값을 기준으로 병렬처리
private static String APPLICATION_NAME = "streams-application";
//스트림즈 어플리케이션과 연동할 카프카 클러스터 정보 입력
private static String BOOTSTRAP_SERVER= "localhost:9092";
private static String STREAM_LOG = "stream_log";
private static String STREAM_LOG_COPY = "stream_log_copy";
public static void main(String ...args){
Properties config = new Properties();
config.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_NAME);
config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVER);
//스트림 처리를 위해 직렬화 ,역직렬화 방식을 지정
config.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
config.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
//스트림 토폴로지를 정의하기 위한 용도
StreamsBuilder builder = new StreamsBuilder();
//stream_log 토픽을 담을 KStream 객체를 만들기 위해 stream() 메소드 사용
// StreamBuilder는 stream() 외에 KTable을 만드는 table, globalKTable()등을 지원한다.
KStream<String, String> streamLog = builder.stream(STREAM_LOG);
//다른 토픽으로 전송하기 위해 사용
streamLog.to(STREAM_LOG_COPY);
//SteamBuilder로 정의한 토폴로지에 대한 정보와 스트림즈 실행을 위한 기본 옵션을 파라미터로 KafkaStreams 인스턴스 생성
KafkaStreams streams = new KafkaStreams(builder.build(),config);
//KafkaStreams 인스턴스를 실행하려면 start() 메소드 사용.
streams.start();
}
}스트림즈 어플리케이션은 작성
소스코드를 실행하고 이제, 스트림즈 소스 프로세서에서 사용하는 토픽을 생성해보자
- 토픽생성 로직
bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--partitions 3 \
--topic stream_log
- 데이터 생성

- 이제 실행을 하고 stream_log_copy 토픽을 확인하자
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic stream_log_copy --from-beginning
stream_log가 stream_log_copy로 데이터가 이전된것을 확인할 수 있다.
스트림즈DSL - filter
- 토픽으로 들어온 문자열 데이터중 특정 조건을 만족시키는 경우만 데이터를 처리하도록 하는 메소드 filter() 가 있다.
KStream<String, String> streamLog = builder.stream(STREAM_LOG);
streamLog.filter(((key, value) -> value.length() > 5));스트림즈 DSL - KTable과 KStream을 join
- KTable과 KStreams를 함께 사용하는 경우, 메시지 키를 기준으로 조인을 할 수 있다.
- 대부분의 데이터베이스는 정적으로 저장된 데이터를 조인하여 사용, 카프카에서는 실시간으로 들어오는 데이터들을 조인할 수 있다.
- 예를들어, 메시지 키, 주소를 메시지 값으로 가지고 있는 KTable이 있고, 메시지키 주문한 물픔을 메시지 값으로 가지고 있는 KStream이 존재한다고 가정하면 토픽에 저장된 이름: 주소로 구성된 KTable과 조인하여 새로운 데이터를 생성할 수 있음
- KTable과 Kstream을 소스 프로세서로 가져와서 특정 토픽에 싱크 프로세서로 저장하는 로직을 구현해보자.
- 조인할 때 중요한점은 코파티셔니잉 되어있는지의 여부를 확인하는것
- KTable과 Kstream이 코파티셔닝이 되어있지 않은 경우
Topology Exception을 발생시키기 때문이다. - 그러므로 KTable, KStrem으로 사용할 토픽을 생성할 때 동일한 파티션 개수, 동일한 파티셔닝을 사용하는 것이 중요.
- 파티셔닝 전략은 기본 파티셔너를 사용.
- KTable과 Kstream이 코파티셔닝이 되어있지 않은 경우
#address 토픽
kafka-topics.sh --create \
> --bootstrap-server localhost:9092 \
> --partitions 3 \
> --topic address
#이하 한줄로 묶어서
#order 토픽
kafka-topics.sh --create --bootstrap-server localhost:9092 --partitions 3 --topic order
#order_join 토픽
kafka-topics.sh --create --bootstrap-server localhost:9092 --partitions 3 --topic order_join- build.gradle
implementation 'org.apache.kafka:kafka-streams:2.7.0'- KStreamJoinTable
public class KStreamJoinKTable {
private static String APPLICATION_NAME = "order-join-application";
private static String BOOTSTRAP_SERVERS = "localhost:9092";
private static String ADDRESS_TABLE = "address";
private static String ORDER_STREAM = "order";
private static String ORDER_JOIN_STREAM = "order_join";
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_NAME);
properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
properties.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
properties.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder streamsBuilder = new StreamsBuilder();
KTable<String, String> addressTable = streamsBuilder.table(ADDRESS_TABLE);
KStream<String, String> orderStream = streamsBuilder.stream(ORDER_STREAM);
orderStream.join(addressTable, (order, address) -> order + "send to " + address)
.to(ORDER_JOIN_STREAM);
KafkaStreams streams = new KafkaStreams(streamsBuilder.build(), properties);
streams.start();
}
}# address topic에 데이터 입력
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic address --property "parse.key=true" --property "key.separator=:"
> donggeun:seoul
> kim:busan
# order topic에 데이터 입력
kafka-console-producer.sh --bootstrap-server localhost:9092 --topic order --property "parse.key=true" --property "key.separator=:"
> donggeun:Porsche
> kim:audi
# 둘이 join 한 거 데이터 확인
kafka-conole-consumer.sh --bootstrap-server localhost:9092 --topic order_join --property parse.key=true --property key.separator=":" --from-beginning

- 언뜻 결과물을 보면 KTable과 크게 다르지 않지만
- GlobalKTable로 선언한 토픽은 토픽에 존재하는 모든 데이터를 태스크마다 저장하고 조인 처리를 수행하는 점이 다름.
프로세서 API
-
프로세서 API는 스트림즈 DSL 보다 투팍한 코드를 가지지만 토폴로지를 기준으로 데이터를 처리한다는 관점에서 동일한 역할을 함.
-
스트림즈 DSL은
데이터처리,분기,조인을 위한 다양한 메소드들을 제공하지만 추가적인상세 로직의 구현이 필요하다면 프로세서 API를 구현할 수 있음 (아마 Low단의 Logic을 그대로 제공하는듯) -
프로세서 API에서는 다만 스트림즈 DSL에서 사용했던
KStream,KTable,GlobalKTable의 개념이 없다. -
FilterProcessor.java
public class FilterProcessor implements Processor<String,String> {
private ProcessorContext context;
@Override
public void init(ProcessorContext context) {
this.context = context;
}
@Override
public void process(String key, String value) {
if(value.length()>5){
context.forward(key,value);
}
context.commit();
}
@Override
public void close() {
}
}- SimpleKafkaProcessor
public class SimpleKafkaProcessor {
private static String APPLICATION_NAME = "processor-application";
private static String BOOTSTRAP_SERVERS = "localhost:9092";
private static String STREAM_LOG = "stream_log";
private static String STREAM_LOG_FILTER = "stream_log_filter";
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(StreamsConfig.APPLICATION_ID_CONFIG, APPLICATION_NAME);
properties.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
properties.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
properties.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
//Topology 클래스는 Processor API를 사용한 토폴로지를 구성하기 위해 사용한다.
Topology topology = new Topology();
//Stream_log 토픽을 소스 프로세서로 가져오기 위해 addSource 메소드를 사용했다.
//스트림 프로세서를 사용하기위해 addProcessor method를 사용했고, FilterProcessor를 구현하여 넣었다.
// 데이터를 저장하기 위해 addSink 메소드를 사용했다. 이때 세번째는 부모노드를 사용하는데, 필터링 처리가 완료된 데이터를 저장해야 하므로 부모노드는 Processor이다.
topology.addSource("Source",STREAM_LOG)
.addProcessor("Processor", FilterProcessor::new
,"Source")
.addSink("Sink",STREAM_LOG_FILTER,"Processor");
KafkaStreams streaming = new KafkaStreams(topology, properties);
streaming.start();
}
}
