✅ 오늘의 목표
- 5개의 csv 파일을 분석용 통합 파일로 만들기
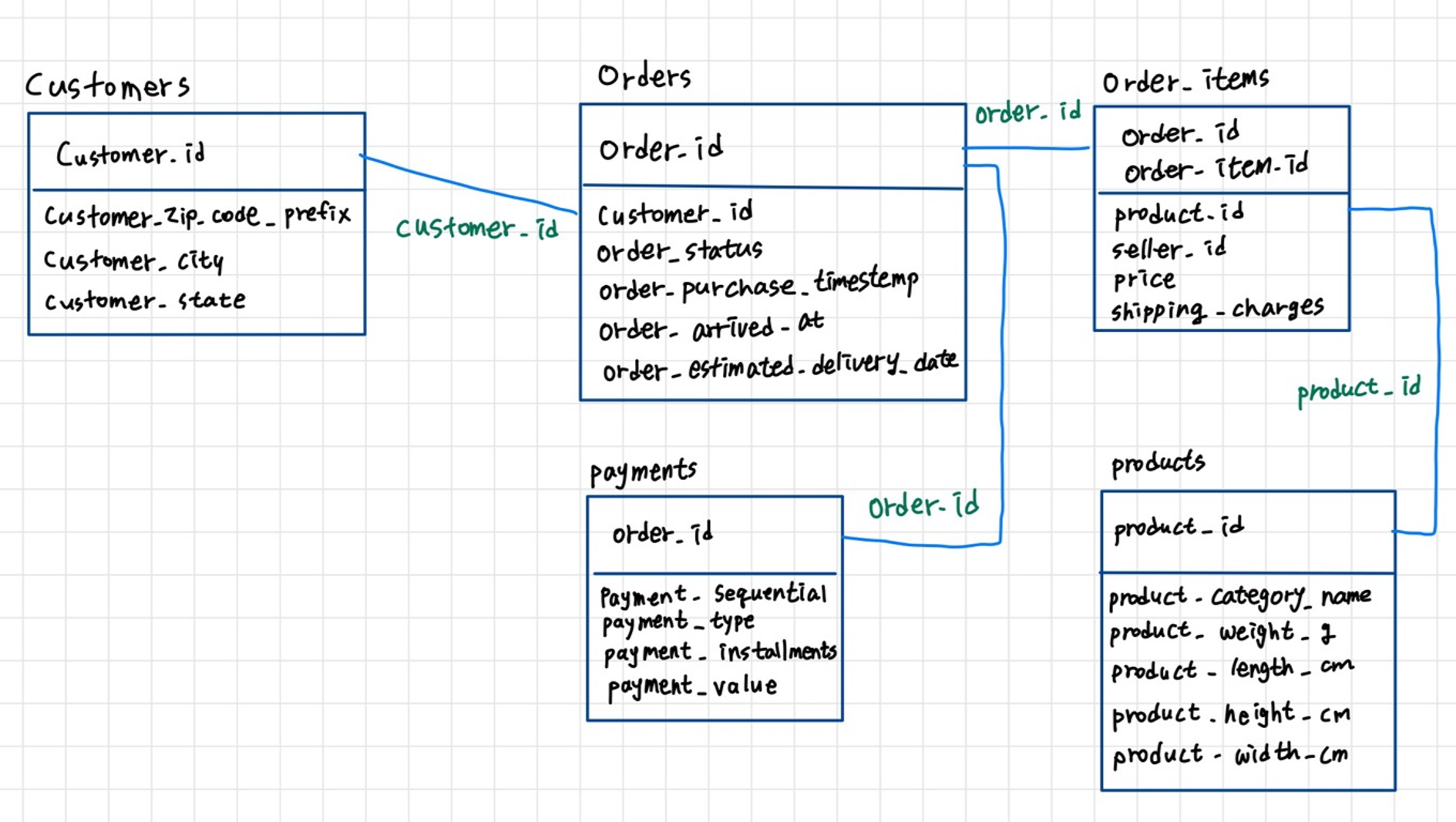
하나의 통합 파일로 만들기
합쳐야 할 데이터는?
우리의 군집 데이터는 총 5개의 csv 파일로 나뉘어 있다.
- orders
- order_items
- customers
- payments
- products
csv 파일을 하나로 합쳐야 해서 먼저, ERD 를 통해 각각의 테이블 간의 관계를 파악했다. 그리고, 팀원 중 데이터를 하나로 합치는 작업을 해본 사람이 없어서 각자 방법을 알아보기로 했다. 알아보던 중 merge로 데이터프레임을 합치는 방법을 알아냈고, 팀원 중 한 분께서 맡아서 해주셨다.
문제발생
그런데, 여기서 문제가 발생했다. 통합 파일의 정합성을 검증하던 중 중복 데이터가 9,425 개나 있었다.
# orders_df와 customers_df를 customer_id를 기준으로 병합
merged_df = pd.merge(orders, customers, on='customer_id', how='left')
# merged_df와 order_items_df를 order_id를 기준으로 병합
merged_df = pd.merge(merged_df, order_items, on='order_id', how='left')
# merged_df와 payments_df를 order_id를 기준으로 병합
merged_df = pd.merge(merged_df, payments, on='order_id', how='left')
# merged_df와 products_df를 product_id를 기준으로 병합
merged_df = pd.merge(merged_df, products, on='product_id', how='left')
print(merged_df.duplicated().sum())
결과: 9425문제 해결 과정
팀원들과 이 문제에 대해 열띤 토론을 하기 시작했다. kaggle에서 데이터를 다운로드 받을 때 위의 5개의 csv 파일 외에도 capstone_data_cleaned.csv 파일이 있었다. 이 데이터셋은 결측치 처리, 이상치 처리가 되어있는 듯했고, 잘 정돈되어 있어 일종의 정답이라고 생각했다. (그랬으면 안 됐는데…)
이 파일과 최대한 비슷하게 가야 한다, 참고 정도로 생각해야 한다, 이 데이터셋은 만든 사람의 의도를 우리가 알 수 없기 때문에 그냥 아예 무시하고 우리만의 기준을 세워서 진행하면 된다 등 여러 의견이 나왔다. 그렇게 몇 시간을 회의하다가 더는 지체되면 안 될 것 같아 튜터님께 도움을 요청하러 갔다.
튜터님께 지금까지 우리가 했던 것과 데이터 병합 과정에서 중복 문제가 발생했다는 말씀을 드리며 같이 고민했다. 그러던 중 튜터님께서 “혹시, 병합 전에 각각의 테이블에 대해서 중복 검사를 해보셨나요?” 어라…? 뭔가 기분이 쎄한데? 빠르게 해봤는데 결과가..!
print(order_items.duplicated().sum())
print(orders.duplicated().sum())
print(customers.duplicated().sum())
print(payments.duplicated().sum())
print(products.duplicated().sum())
결과:
0
0
3089
0
0병합 전 customers 테이블에 이미 3089 개의 중복 데이터가 존재했다. 게다가, 우리가 병합했던 방식을 보면 customers 테이블과 orders 테이블 가장 먼저 병합하고, 그 뒤로 3번의 과정이 더 있다. 그리고 3089에 3을 곱하면 9,267개로 9,425와 매우 비슷한 값을 보인다. 하하하… 이런 어처구니없는 실수를 하다니… 이 간단한 걸 해결해 보겠다고 금요일 하루를 날리다니!
병합 전 customers 테이블에서 중복 값을 제거하고 병합을 실시 했을 때 다행히 중복 문제가 잘 해결됐다.
customers = customers.drop_duplicates()
# orders_df와 customers_df를 customer_id를 기준으로 병합
merged_df = pd.merge(orders, customers, on='customer_id', how='left')
# merged_df와 order_items_df를 order_id를 기준으로 병합
merged_df = pd.merge(merged_df, order_items, on='order_id', how='left')
# merged_df와 payments_df를 order_id를 기준으로 병합
merged_df = pd.merge(merged_df, payments, on='order_id', how='left')
# merged_df와 products_df를 product_id를 기준으로 병합
merged_df = pd.merge(merged_df, products, on='product_id', how='left')
print(merged_df.duplicated().sum())
결과: 0통합 파일 완성
합쳐진 데이터의 요약 정보는 다음과 같다:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 119160 entries, 0 to 119159
Data columns (total 24 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 order_id 119160 non-null object
1 customer_id 119160 non-null object
2 order_status 119160 non-null object
3 order_purchase_timestamp 119160 non-null object
4 order_approved_at 118982 non-null object
5 order_delivered_timestamp 115738 non-null object
6 order_estimated_delivery_date 119160 non-null object
7 customer_zip_code_prefix 119160 non-null int64
8 customer_city 119160 non-null object
9 customer_state 119160 non-null object
10 order_item_id 118325 non-null float64
11 product_id 118325 non-null object
12 seller_id 118325 non-null object
13 price 118325 non-null float64
14 shipping_charges 118325 non-null float64
15 payment_sequential 119157 non-null float64
16 payment_type 119157 non-null object
17 payment_installments 119157 non-null float64
18 payment_value 119157 non-null float64
19 product_category_name 117893 non-null object
20 product_weight_g 118305 non-null float64
21 product_length_cm 118305 non-null float64
22 product_height_cm 118305 non-null float64
23 product_width_cm 118305 non-null float64
dtypes: float64(10), int64(1), object(13)
memory usage: 21.8+ MB원래는 오늘 EDA도 해보는 게 목표였는데, 통합파일 만드는 데 생각보다 시간을 많이 써서 주말부터 해보려고 한다. 그래도 다음에 또 데이터를 병합해야 할 일이 생겼을 때는 수월하게 할 수 있을 것 같아 값진 시간이었다.
내일 할 일
- SQLD 자격증 시험
- 프로젝트 기간이라 계획했던 것 만큼 공부를 많이 하진 못했지만, 그래도 최선을 다 해 보자…!!
- EDA
