TIL (Today I Learned)
1.🗂️ 2024.06.24 TIL

Subquery사용하는 이유조건에 따른 필터링: 메인 쿼리의 결과에 영향을 받는 조건을 지정할 때 사용. 예를 들어, 특정 조건을 만족하는 데이터만을 선택하고자 할 때 서브쿼리를 사용하여 해당 조건을 정의할 수 있다.중첩 집계 함수: 서브쿼리를 사용하여 메인 쿼리의 결
2.🗂️ 2024.06.25 TIL

coalesce특정열의 NULL 값을 적절한 값으로 치환할 때 사용하기 용이하다.coalesce 가 왜 NULL 값을 다룰 때 쓰는지 이해가 안 됐는데, 단어 뜻을 검색해보니 ‘합치다’ 라는 뜻… 예시)coalesce(value1, value2, …)customer
3.🗂️ 2024.06.26 TIL

뷰 (view)기본 테이블은 디스크에 공간이 할당되어 데이터를 저장But, 뷰는 데이터 딕셔너리 테이블에 뷰에 대한 정의만 저장피봇 테이블 (Pivot table)2개 이상의 기준으로 데이터를 집계할 때, 보기 쉽게 배열하여 보여주는 것 예시 음식점별 시간별 주문건
4.🗂️ 2024.06.27 TIL

hour(DATETIME) : DATETIME type 의 시간만 따로 조회 가능예시인덴트의 중요성을 느낌지금이야 쿼리문이 좀 짧고 간단하지만 나중에 서브쿼리 여러 개 사용하고 복잡해지면 가독성이 떨어질거 같아서 지금부터라도 쿼리문의 가독성을 높여 작성하는 버릇을 들여
5.🗂️2024.06.28 TIL

DATEDIFF두 날짜의 일(day)의 차이를 구해주는 함수예시 결과: 392 isdigit(): string 클래스에 있는 메서드로 문자열이 ‘숫자’로만 이루어져 있는지 확인할 수 있는 함수문자가 단 하나라도 있으면 False 반환,숫자로만 이루어져 있다면 Tru
6.🗂️2024.07.01 TIL

WHERE 절 집계함수 주의WHERE 절에서는 집계함수를 사용할 수 없다.따로 HAVING 절로 빼주거나,서브쿼리를 활용해야 한다.참고: https://velog.io/@ehdtkd98/프로그래머스조건에-맞는-사용자와-총-거래금액-조회하기-SQL수도코드로 설계
7.🗂️2024.07.02 TIL

TRUNCATE(number, decimals): 특정 자리수 이하를 버림하는 함수number: 버림할 숫자decimals: 숫자의 소숫점 이하 자릿수 (음수인 경우 소수점 이하의 자릿수를 왼쪽에서부터 제거)ex) PRICE = 12345의 경우, TRUNCATE(PR
8.2024.07.03 TIL

시저 암호: 어떤 문장의 각 알파벳을 일정한 거리만큼 밀어서 다른 알파벳으로 바꾸는 암호화 방식문자열을 아스키코드로 바꾸고, 그 아스키코드를 다시 문자열로 바꾸는 방식으로 구현 가능ord() : 문자열을 아스키코드로 변환chr() : 아스키코드를 문자열로 변환참고: h
9.2024.07.04 TIL

숫자 문자열과 영단어일부 자릿수를 영단어로 바꾼 카드를 건네주면 원래 숫자를 찾는 게임문제풀이딕셔너리 활용딕셔너리.items() 로 key, value 접근문자열에서 딕셔너리의 key 에 해당하는 부분을 value 로 replaces 를 정수형으로 변환해서 return
10.🗂️2024.07.05 TIL

직장인들이 사무실에 출근하여 매일 아침 루틴처럼 하는 일이 있을 것이다. 이런 부분에 있어서 똑같거나, 비슷하면서 반복되는 일이 분명 있을 것이다. 이런 업무들에서의 업무 자동화는 효율성을 높이고, 오류를 줄이며, 반복적인 작업을 줄이는 데 중요한 역할을 한다.1\.
11.🗂️2024.07.08 TIL

Python enumerate(): 순서가 있는 자료형을 입력받았을 때, 인덱스와 값을 동시에 접근하여 리턴! 예시 결과 참고: https://velog.io/@ehdtkd98/프로그래머스가장-가까운-글자-파이썬-h8cccj2b
12. 🗂️2024.07.09 TIL

SQL 일단 테이블의 생김새를 보고싶어 테이블을 JOIN 해봤는데, 한 쪽 테이블에는 데이터가 있는데, 나머지 테이블에는 JOIN 되면서 NULL 값들이 생겼다. 한 쪽 테이블에는 데이터가 있는데 다른 하나에는 없는 데이터를 조회하려면? OUTER JOIN 그러면
13.🗂️2024.07.10 TIL

코드로 구현:제곱은 \*\*2루트는 \*\*0.5참고: 문제 7 코드를 짜면서 항상 변수명을 뭘로 하면 좋을까?에 대한 고민을 했었다. 코드를 처음 보는 사람도 이해할 수 있도록 a, b 이런 것들 보다는 실제로 그 변수가 나타내는 내용이 반영되도록 하면 좋은데 적절한
14.🗂️2024.07.11 TIL

GRUOP BY 절에 두 개 이상의 컬럼을 사용하는 상황여러 컬럼의 조합을 기준으로 그룹화해야 할 때.일반적인 상황과 예시다차원 데이터 분석: 매출 데이터를 분석할 때 지역과 제품을 기준으로 그룹화 할 수 있음.카테고리와 서브 카테고리 집계: 쇼핑몰의 판매 데이터를 카
15.🗂️2024.07.12 TIL

오늘은 파이썬에서 웹 크롤링을 할 수 있는 라이브러리 Selenium 에 대해 알아봤다.Selenium은 웹 애플리케이션을 테스트하기 위한 프레임워크이다. 웹에 하는 명령을 코드화시켜서 작동시키며, 다양한 브라우저 작동을 지원하며 크롤링에도 활용된다.크롤링에서는 정적,
16.🗂️2024.07.15 TIL

시간 복잡도: 알고리즘이 문제를 해결하는 데 걸리는 시간을 나타내는 지표특정한 크기의 입력에 대하여 알고리즘이 얼마나 오래 걸리는지를 의미공간 복잡도: 특정한 크기의 입력에 대하여 알고리즘이 얼마나 많은 메모리를 차지하는지를 의미https://school.pr
17.🗂️ 2024.07.16 TIL

소수 판별하기 (자주 나오니 꼭 기억하자!)소수 확인하는 방법:어떤 수에 대해 2부터 자기 자신-1 까지의 모든 수들을 확인하며 만약 그 수로 나눠떨어지면 소수 X, 나눠 떨어지지 않으면 소수이다.파이썬으로 16이 소수인지 판별하는 코드를 구현하면 다음과 같다:결과:
18.2024.07.17 TIL

매일 아침 프로그래머스에서 파이썬과 SQL 문제를 풀기 시작한지 1 달 정도 된 거 같다. 그 동안 문제를 풀면 깃허브의 리포지토리에 하나하나 커밋했었는데, 우연히 크롬을 통해 깃허브에 자동으로 커밋하는 방법을 알게되서 공유하고자 한다. (저처럼 미련하게 하는 사람들이
19.🗂️2024.07.18 TIL

csv 파일 저장하기: .to_csv(’.file_name.csv’)인덱스를 설정하거나 해제할 수 있다.csv 파일 읽어오기: pd.read_csv(’file_name.csv’)컬럼 이름 변경df.head(): 데이터의 머리 부분을 확인 가능df.info(): 데이터의
20.🗂️2024.07.19

문제에서 주어진 내용을 딕셔너리 형태로 저장해서 그걸 사용하게 되는 경우가 종종 생기는 거 같다.예를 들어 다음과 같이 순위, 당첨 내용이 있는 경우처럼 세트로 묶이는 경우엔 딕셔너리를 떠올릴 수 있도록 노력해야겠다.문제 링크: https://school.pr
21.🗂️ 2024.07.22 TIL

프로그래머스에서 파이썬 알고리즘 문제를 풀 때 항상 제한사항이 있는데, 보통은 변수의 범위 등 문제를 푸는 데 크게 필요하진 않은 요소들 이어서 잘 안 읽었다. 하지만 오늘 코드카타를 하면서 문제의 요구사항을 제대로 안 읽어 문제 하나에 거의 2 시간 정도를 소비해버렸
22.🗂️ 2024.07.23 TIL

오늘은 프로그래머스 문제를 풀면서 처음으로 SELF JOIN 을 해봤다.SELF JOIN 의 개념:SELF JOIN 이란 말 그대로 동일 테이블 사이의 조인을 말한다. FROM 절에서 동일 테이블이 두 번 이상 나타나는데, 이 때의 주의사항은 동일 테이블 사이의 조인을
23.🗂️ 2024.07.24 TIL

오늘은 기초 프로젝트가 시작됐다. 우리 팀의 주제는 마케팅 성과 측정을 위한 데이터 분석데이터셋: https://www.kaggle.com/datasets/jessemostipak/hotel-booking-demand/data프로젝트 목표: 호텔 서비스의 현재
24.🗂️ 2024.07.31 TIL

프로그래머스 SQL 코드카타를 하면서 JOIN 을 할 수 없는 상황이 생겼는데, 그 상황에서 테이블을 어떻게 합쳐야 할지 고민 중 UNION 이라는 연산자를 알게 됐다.UNION은 두 개 이상의 SELECT 문을 결합하여 하나의 결과 집합으로 만드는 연산자이다.사용 목
25.🗂️ 2024.08.01 TIL

오늘은 파이썬 챌린지반에서 배운 Streamlit 에 대해 정리해보려고 한다.Streamlit 이란 Python 언어로 작성된 데이터 애플리케이션을 빠르고 쉽게 만들 수 있도록 도와주는 오픈 소스 라이브러리이다. 데이터 과학자, 머신 러닝 엔지니어, 애널리스트가 대화형
26.2024.08.02 TIL

SET 명령어와 사용자 정의 변수SET: SET 명령어는 변수의 값을 설정하는 데 사용.사용자 정의 변수: 사용자 정의 변수는 @ 기호로 시작하며, 사용 전에 반드시 초기화할 필요는 없지만, 초기화하지 않은 변수를 사용하면 NULL 값을 반환한다고 한다.예시코드: 참고
27.🗂️ 2024.08.05 TIL

SELECT 절에서의 서브쿼리:SELECT 절에서의 서브쿼리는 하나의 열처럼 사용됨.다른 테이블에서 계산된 값을 가져오기집계 함수 사용하기조건에 맞는 값을 가져오기아스키코드 변환 리마인드:ord() : 특정 문자를 아스키 코드값으로 변환chr() : 아스키 코드 값을
28.🗂️ 2024.08.06 TIL

map() : 예전에 백준 문제 풀 때 자주 사용했었는데, map 함수는 한 개 이상의 시퀀스의 요소들을 주어진 함수에 따라 변환하여 새로운 시퀀스를 생성하는 함수이다.다음과 같이 split 해서 각각의 변수에 할당할 수도 있고익명함수를 사용해 리스트의 각 요소를 제곱
29.🗂️ 2024.08.07 TIL

오늘은 리스트에서 각 요소들에대해 반복문을 돌면서 딕셔너리의 값을 리스트 형태로 저장하는 방법을 배웠다.먼저, {key: } 형태로 값이 비어있는 딕셔너리를 만들어놓고for 문을 돌면서 리스트에 append 하는것처럼 dictionarykey.append(value)
30.🗂️ 2024.08.08 TIL

오늘 머신러닝 관련 강의가 추가로 열려서 수강한 내용을 정리해보고자 한다.머신러닝 관련 용어AI: 인간의 지능을 요구하는 업무를 수행하기 위한 시스템Machine Learning: 관측된 패턴을 기반으로 의사 결정을 하기 위한 알고리즘데이터 수집과 처리 기술의 발전으로
31.🗂️ 2024.08.09 TIL

최소공배수를 구하는 문제알고리즘 문제들을 풀다보면 최소공배수, 최대공약수를 구하는 문제가 꽤 나오는거 같다. 그래서 한번 더 정리해서 다음번에 해당 문제가 나오면 반가운 느낌이 들었으면 한다.최대공약수: 두 수가 서로 공통으로 가지고 있는 약수 중 가장 큰 수예를들어
32.2024.08.12 TIL

동적 계획법:https://velog.io/@ehdtkd98/프로그래머스-멀리-뛰기-파이썬-1oqscus8동적 계획법의 대표적인 알고리즘인 피보나치 수열과 같은 위 유형의 문제는 n 이 커짐에 따라 어떤 규칙성을 갖게 되는지 파악하는 것이 중요. 동적 계획법:
33.🗂️ 2024.08.13 TIL

리스트의 요소를 끊기지 않고, 연결해서 더해야 하는 경우리스트를 두 개 붙이기로지스틱회귀: 범주형 종속변수(Y)가 0 또는 1인 이진 분류 문제를 다루기 위해 사용되는 통계적 방법오즈비는 특정 사건이 발생할 확률을 발생하지 않을 확률로 나눈 값. 예를 들어, 사건이 발
34.🗂️ 2024.08.14 TIL

리스트 내의 리스트의 각 요소에 접근할 때 단순히 for 문으로 접근하는게 아니라 divmod() 등 더 효율적인 방법 생각해보기https://velog.io/@ehdtkd98/프로그래머스-n2-배열-자르기-파이썬확실히 매일매일 알고리즘을 풀다보니 풀이 방식에
35.🗂️ 2024.08.16 TIL

슬라이딩 윈도우 기법슬라이딩 윈도우 기법(Sliding Window Technique)은 연속적인 부분 배열(subarray)이나 부분 문자열(substring)을 효율적으로 다루기 위한 알고리즘 기법입니다. 이 기법은 배열 또는 문자열에서 일정한 크기의 윈도우를 이동
36.🗂️ 2024.08.19 TIL

Polynomial Regression은 선형 회귀(Linear Regression)의 확장된 형태로, 데이터를 더 잘 설명하기 위해 다항식(polynomial) 항을 사용하여 회귀 모델을 만드는 방법. 이 모델은 독립 변수와 종속 변수 간의 비선형 관계를 학습하는 데
37.[TIL] [심화 프로젝트] 1일차: 주제 선정 및 ETA 작성

기초 프로젝트가 끝나고 이것저것 바쁘게 하다 보니 벌써 심화 프로젝트 기간이 됐다. 프로젝트를 여러 번 해봤음에도 도무지 적응되지 않는 이 프로젝트 초기의 긴장감...! 그래도 그 긴장감 덕분에 매번 진심을 다하게 되는 것 같다.이번 프로젝트는 저번 기초 프로젝트에서
38.[TIL] Tableau 1 - 2주차 강의
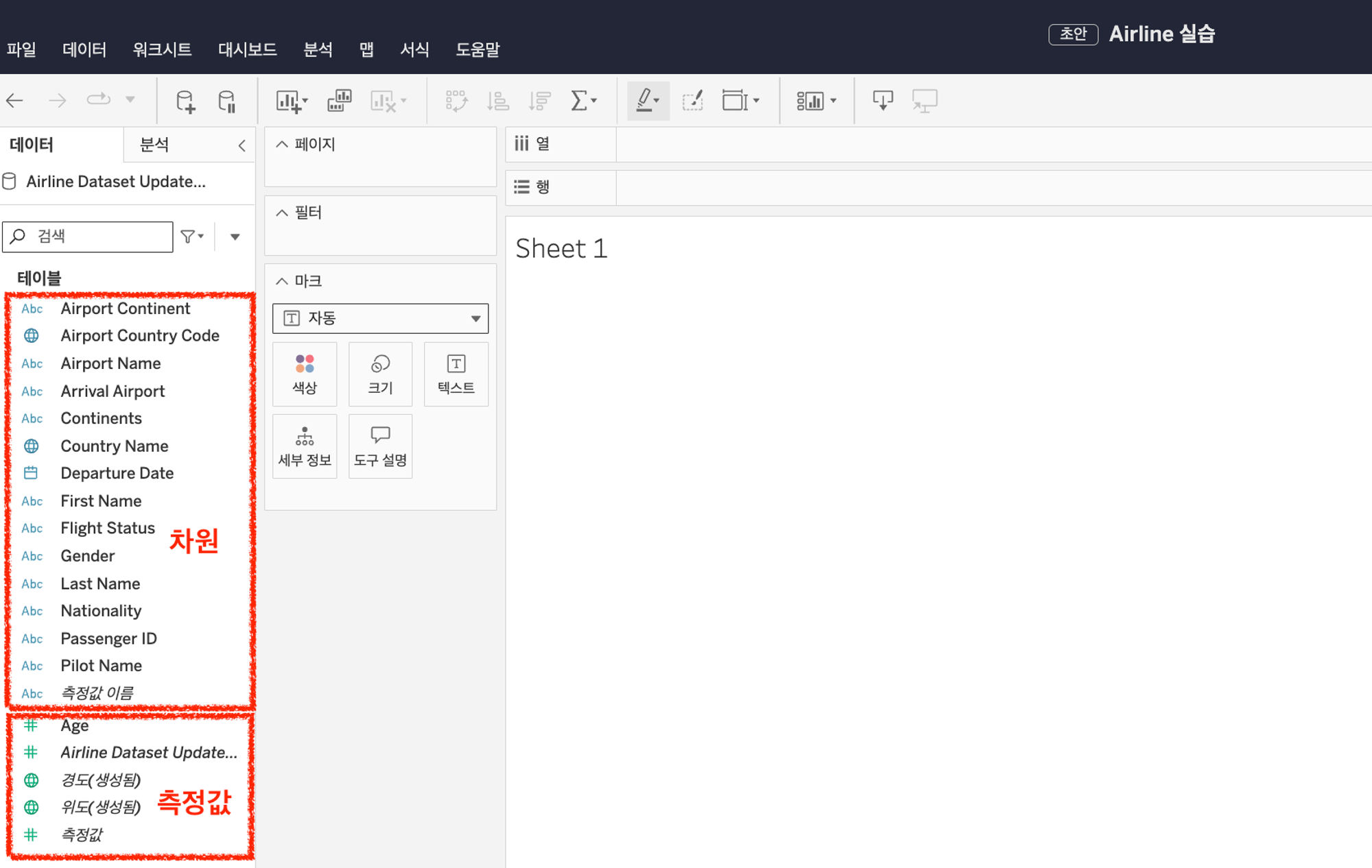
Google Looker Studio대표적으로 많이 사용.구글 스프레드 시트랑 연동 가능 & 무료 기능으로 대부분 커버 가능Microsoft PowerBI가격이 저렴한 편.마이크로소프트의 AZURE, MS 엑셀을 사용하는 조직에서는 Power BI 를 전사 BI 툴로
39.[TIL] [심화 프로젝트] 2일차: 데이터 통합 및 EDA
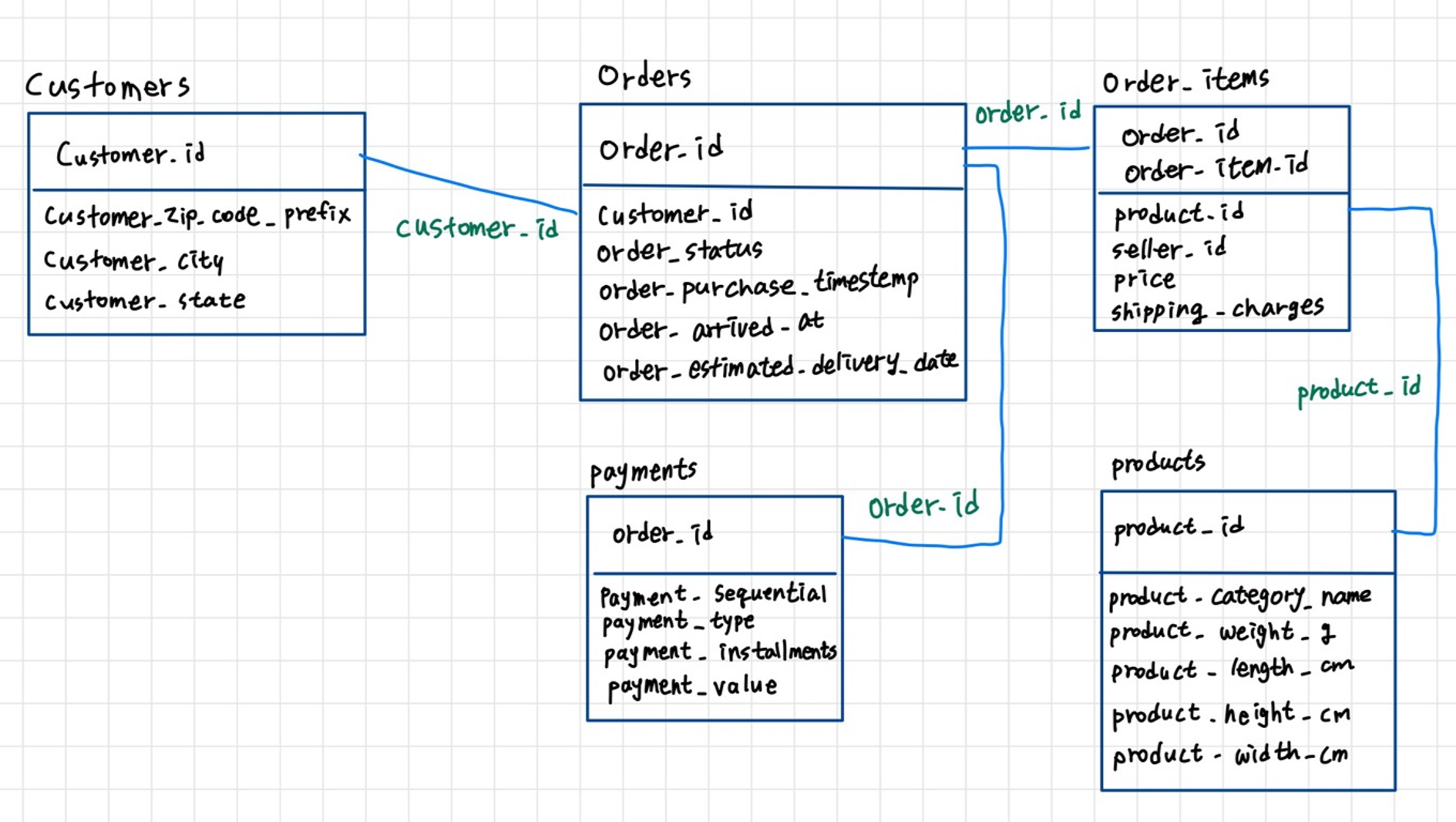
5개의 csv 파일을 분석용 통합 파일로 만들기우리의 군집 데이터는 총 5개의 csv 파일로 나뉘어 있다.ordersorder_itemscustomerspaymentsproductscsv 파일을 하나로 합쳐야 해서 먼저, ERD 를 통해 각각의 테이블 간의 관계를 파악
40.[TIL] Tableau 3 - 4 주차 강의
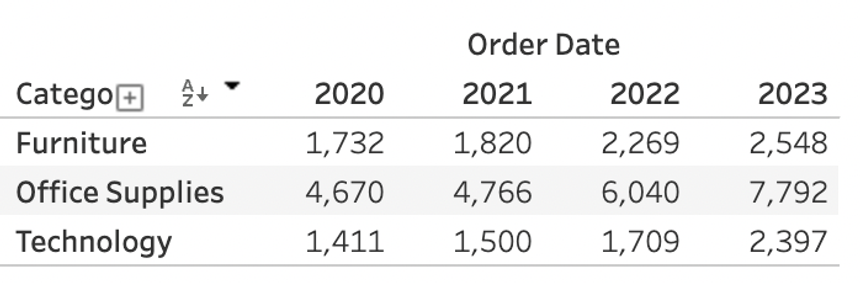
wide format tablewide format table은 옆으로 넓은 형태로 데이터가 쌓인다.데이터 분석을 할 경우 많이 사용되는 형태로 표를 비교하거나 그래프 시각화 하기 쉽다.상관 관계를 분석하거나 각 변수의 분포를 비교할 때 적합. long format
41.[TIL] [심화 프로젝트] 3일차: EDA
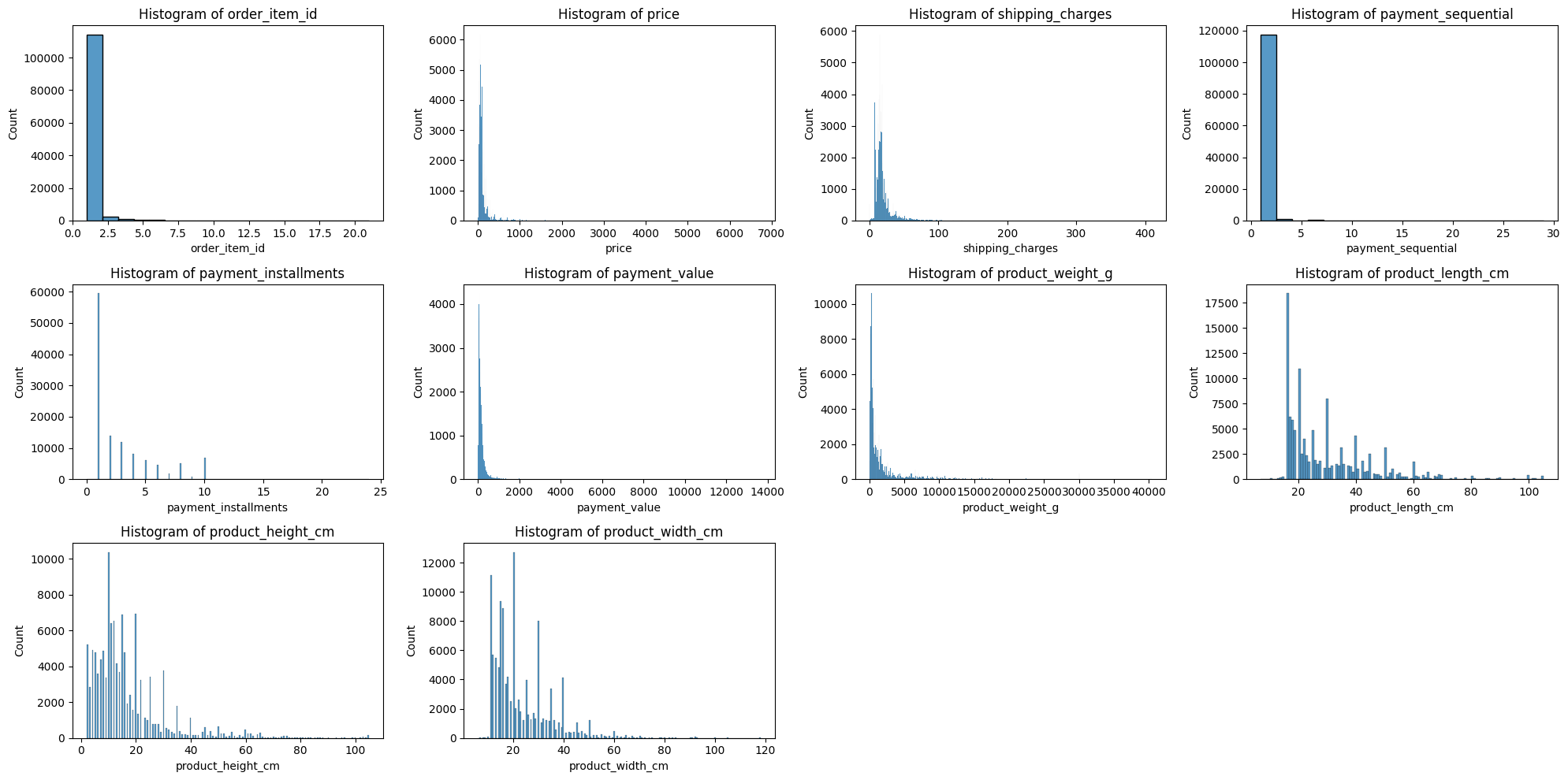
EDA오늘부터 시작해서 일요일까지 해야 할 일은 EDA를 통해 데이터를 간단히 살펴보고, 어떻게 전처리하면 좋을지 기준을 세워보는 것. 다른 사람들은 어떤지 모르겠는데, 나는 이 단계에서 가장 설레는 것 같다. 어차피 모델링 쪽은 코드 뚝딱뚝딱하면 금방 끝나지만, ED
42.[TIL] Tableau 지표 특강 - 2회차
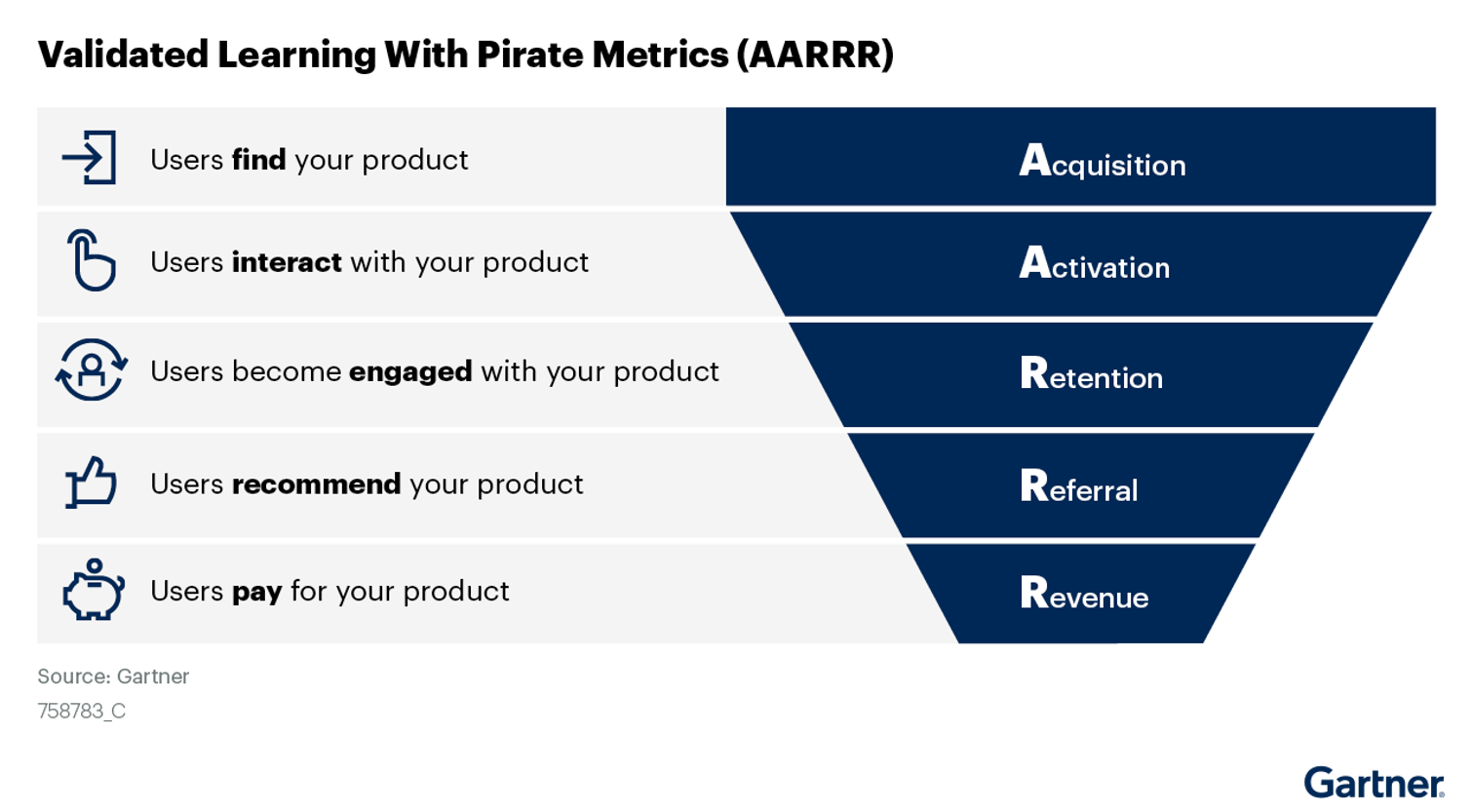
프레임워크 중심의 지표 관리: 지표 중심으로 현재 서비스의 상황을 판단할 수 있다.서비스 흐름에 따라 퍼널과 퍼널에 맞는 지표를 정의하고 해당 지표를 개선하기 Action을 수립.그로스에 가장 많이 사용되는 지표 프레임 워크는 AARRR. GAME, HEART 등 다양
43.[TIL] [심화 프로젝트] 4일차: 데이터 전처리
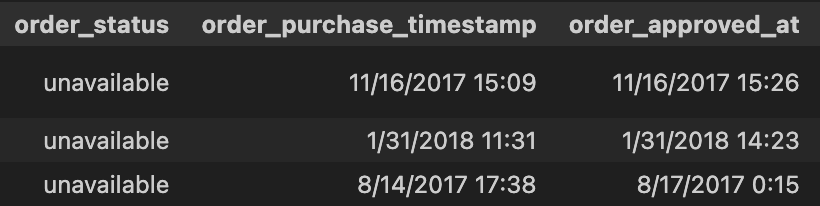
데이터 전처리오늘은 팀원들 각자 EDA 및 전처리 기준에 대해 고민했던 것들을 논의하며 최종 결론을 내는 날.결측치가 있었던 열은 다음과 같았다:결과:지금부터 각 열에 대한 기준을 세워보도록 하자!order_approved_at은 주문이 승인된 시간으로 order_st
44.[TIL] [심화 프로젝트] 5일차: 데이터 전처리
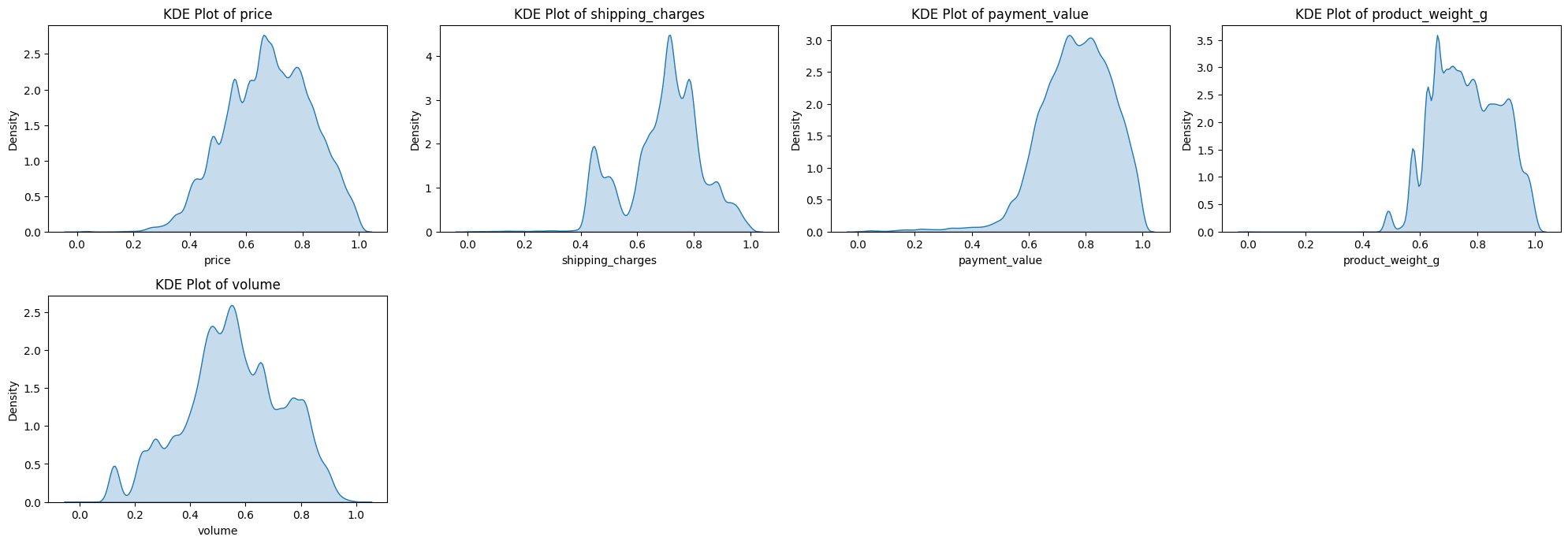
데이터 전처리(스케일링, 범주형 변수 인코딩)현재 수치형 변수가 오른쪽으로 꼬리가 긴 right-skewed 분포를 가지고 있다. 따라서, 로그변환 방법으로 변수들을 조금 더 정규분포에 더 가깝게 만들어 비대칭성을 줄인다.이후 정규화(Normalization)을 통해
45.[TIL] Tableau 지표 특강 - 3회차
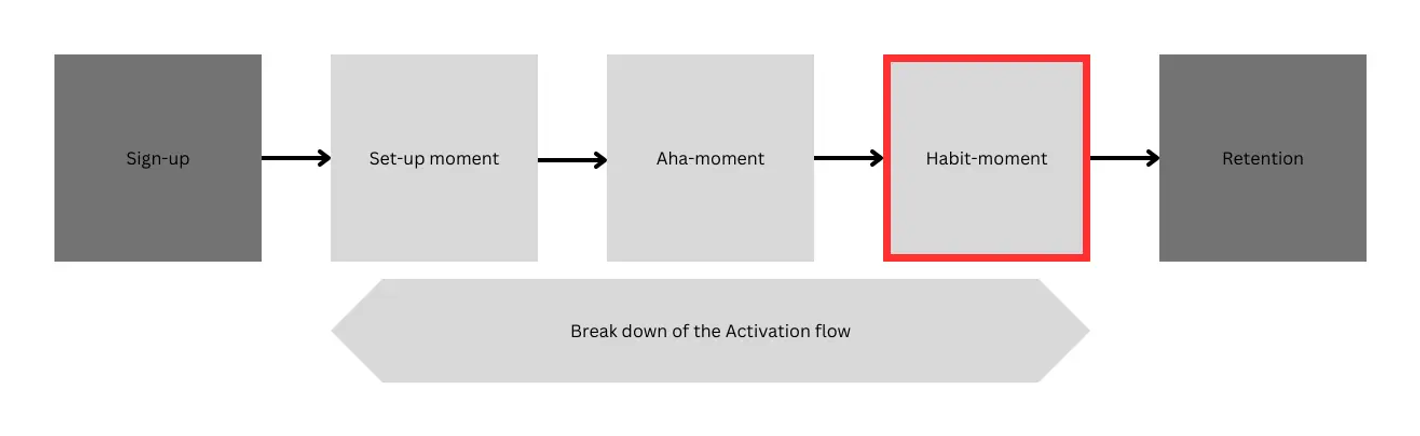
우리 서비스를 유저들이 처음으로 경험하고 활성화하는 단계.많은 고객을 획득하더라도 서비스의 가치를 제대로 경험하지 못하고 이탈하면 사업 가치를 만들어낼 수 없다.아래 이미지는 Activation 단계로 유저가 우리 서비스에 처음 유입된 시점부터 재방문으로 이어지는 순간
46.[TIL] [심화 프로젝트] 6일차: 모델 적용 및 성능 비교
개인의 가설검정에 필요한 컬럼과 초기 군집 갯수를 넣어 클러스터링 진행 후 성능 보기실루엣 계수, WCSS, scatterplot엘보우 방법, 실루엣 분석으로 최적의 군집 갯수 찾기1번에서 했던 기본 모델과 최적의 클러스터 모델에 대해서 성능 비교실루엣 계수, WCSS
47.[TIL] 실전프로젝트 1일차: 주제 선정 & ETA 작성
주제 선정ETA 작성심화 프로젝트 종료 후 일주일 간 Tableau를 활용한 대시보드 제작 방법에 대해 공부한 뒤 오늘 드디어 실전 프로젝트가 시작됐다. 시간이 왜 이렇게 빨리 가는지… 시간이 야속하지만, 이번 프로젝트는 시각적인 요소가 주된 목표이다 보니 재밌는 프로
48.[TIL] 실전프로젝트 2일차: EDA 및 데이터 전처리
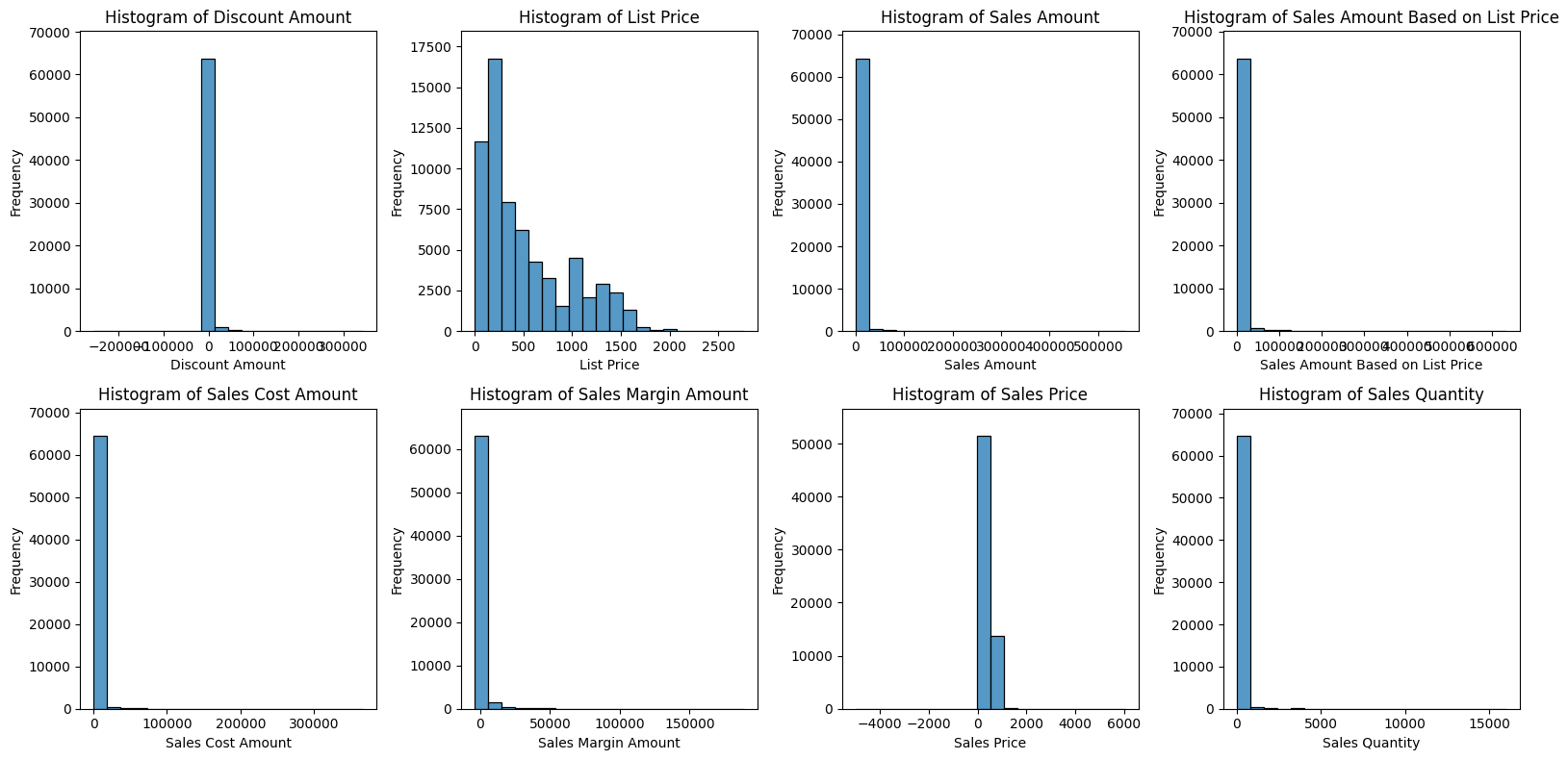
EDA데이터 전처리결과:결과:결과:수치형 변수 (8):Discount AmountList PriceSales AmountSales Amount Based on List PriceSales Cost AmountSales Margin AmountSales PriceeSal
49.[TIL] 실전프로젝트 3일차: 데이터 전처리 마무리 및 지표 설정
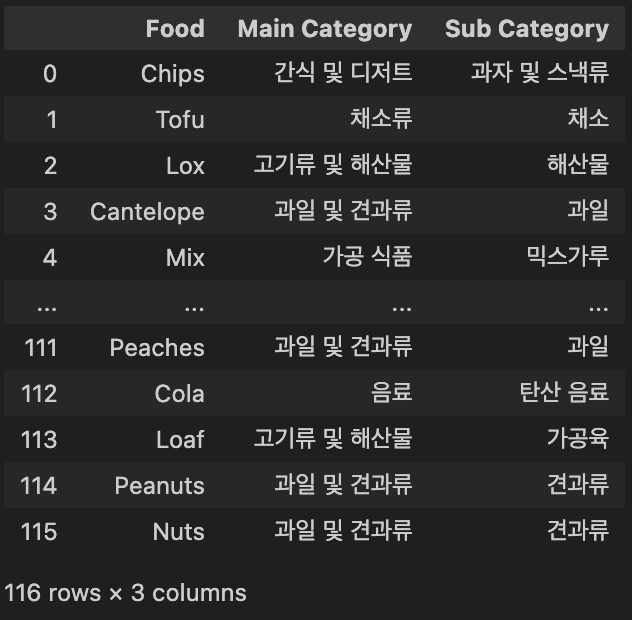
데이터 전처리 마무리지표 설정오늘은 어제 못 한 대분류, 소분류 컬럼 추가하기, 도매/소매 분류하기, 비싼 금액을 어떻게 처리할지에 대한 기준 세우기를 하고자 한다.어제 Item Class에서 P01이 99.9%를 차지해서 이렇게 하나로 분류되는 Item Class는
50.[TIL] 실전프로젝트 4-5일차: 대시보드 구성 및 고객 세그먼트 나누기
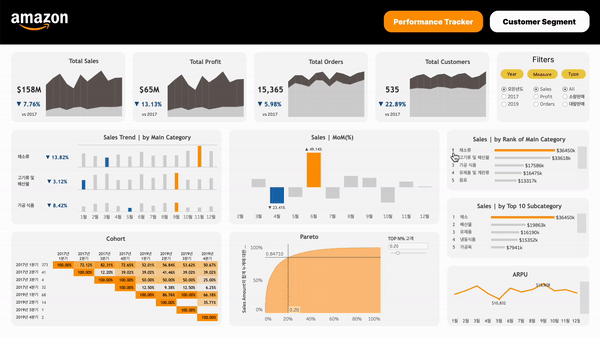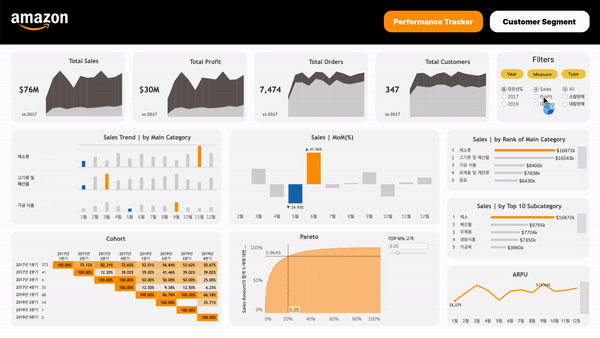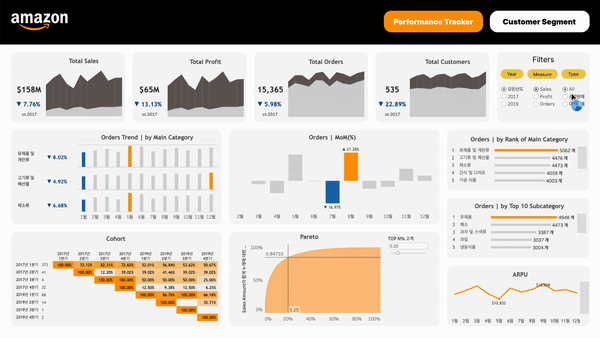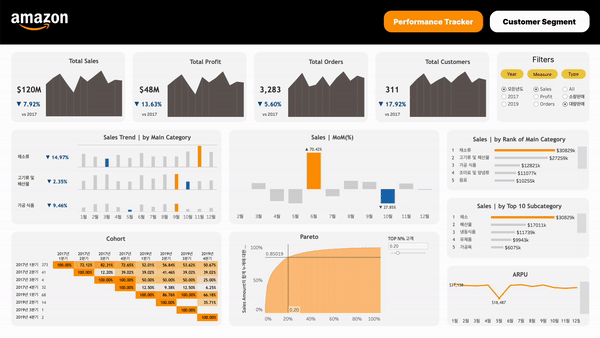
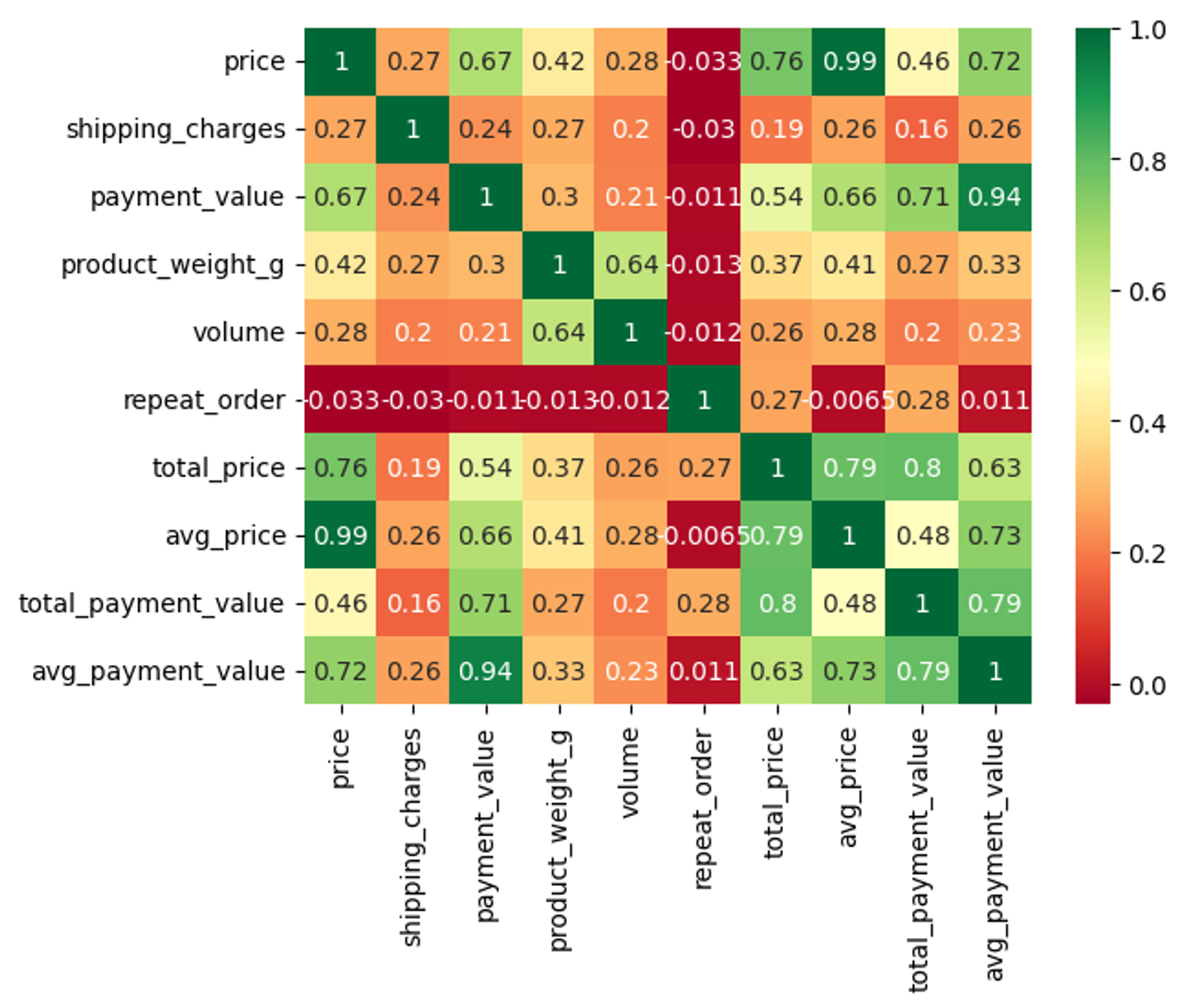
유관부서를 고려한 대시보드 구성하기고객 세그먼트 나누기여러 유관부서가 사용할 대시보드이기에 크게 다음과 같이 두 유형의 대시보드로 구분했고, 대시보드별로 궁금해할 만한 것들을 정리해 봤다:아마존 성과 지표여러 Metric어느 정도의 매출을 달성하고 있는가?어느 정도의
51.[TIL] 실전프로젝트 6일차: 마케팅 방향성 구상
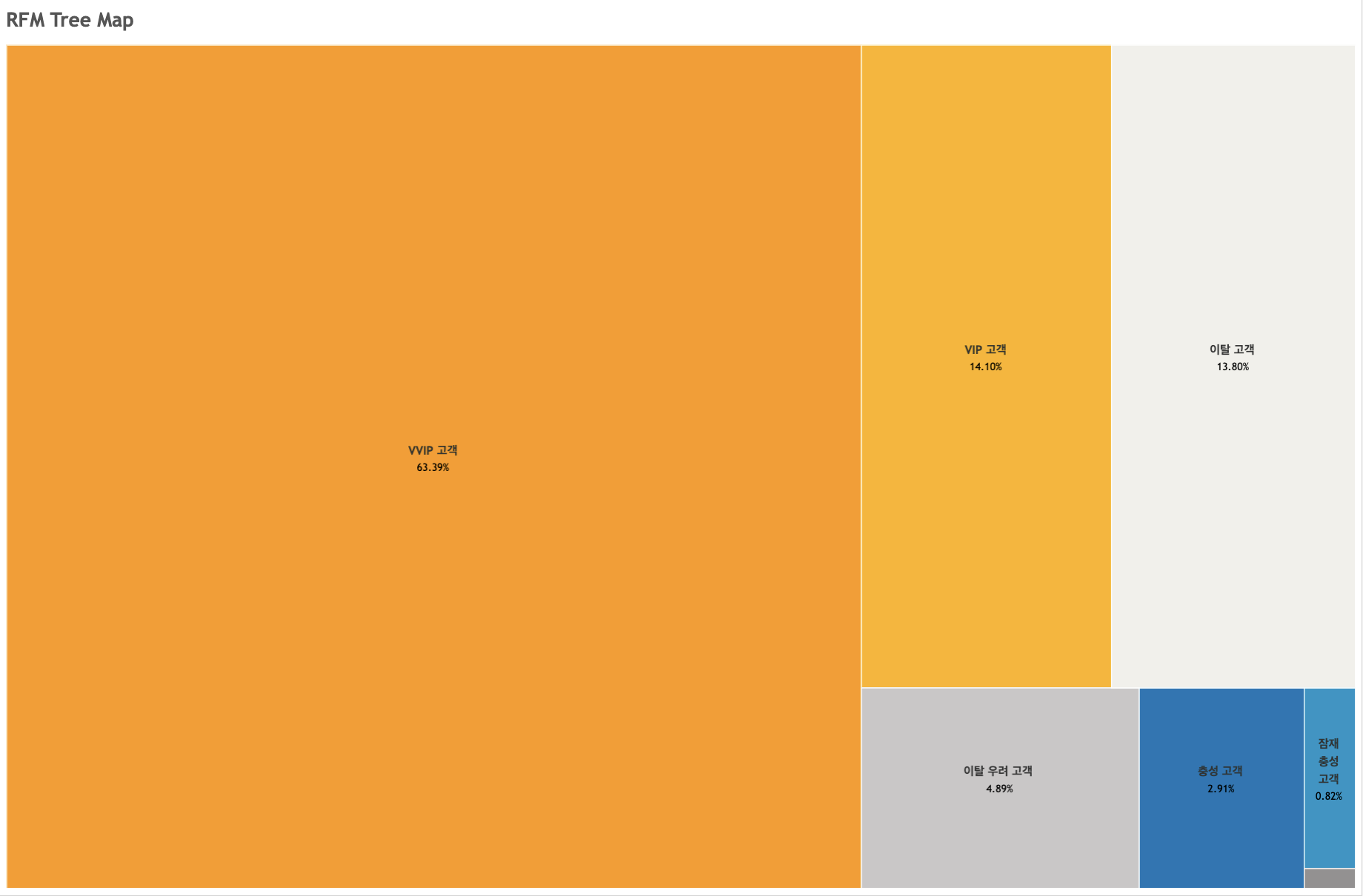
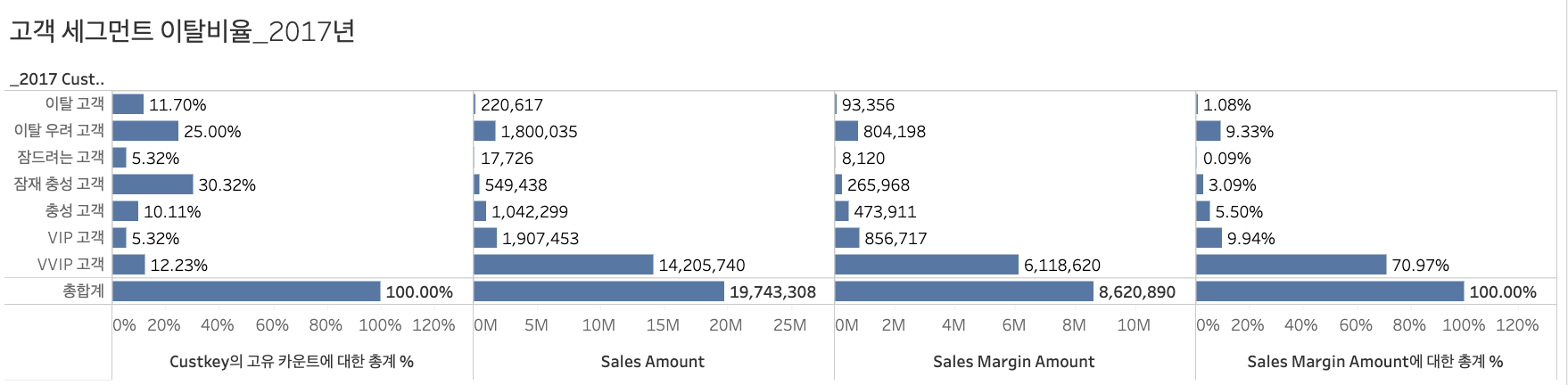
핵심 고개 유지를 위한 마케팅 구상이탈 고객 재유치를 위한 마케팅 구상현재 아마존의 핵심 고객(VVIP, VIP)의 수는 전체 대비 약 26%를 구성하지만, 전체 대비 약 77%의 이익을 차지한다.따라서, 이 핵심 고객들이 우리 서비스에 완전히 정착할 수 있도록 유지할
52.[TIL] 실전프로젝트 7일차: 최종 액션 플랜 도출
튜터님께 멘토링 받고 최종 액션 플랜 도출하기어제까지의 결과로 다음과 같이 세 가지 액션 플랜이 도출됐다:핵심 고객에 집중하여 더 큰 효과를 창출하는 액션 플랜(할인 쿠폰 전략)이탈 고객 재유치를 위한 웰컴백 프로모션(할인 쿠폰 전략)크로스셀링(연관분석) 전략이 전략들
53.[TIL] 실전프로젝트 실전프로젝트 마지막: 피피티 제작 및 대본 구성

아마존 소개프로젝트 목표데이터 소개데이터 시각화(수치형, 범주형, 날짜변수 나눠서)EDA 결과이상치 처리(파생변수 같이 소개 Main, Sub Category, Sales Type)수치형 변수(음수값 확인, 0원인 것들 확인, 이상치 처리 X → 파생변수)범주형 변수(