데이터 시각화01
01. Overview
데이터시각화 -> 분석 프로세스 -> 다변량 분석 -> 이변량 분석
데이터 전처리와 데이터 분석에서 많은 시간이 소요된다.
02. Matplotlib 라이브러리
데이터를 한 눈에 파악하는 두가지 방법
시각화(그래프)
- histogram
- scatter
- Density plot
- Bar plot
- mosaic plot
- box plot
- line plot
수치화(통계량)
- min, max, sum
- mean, std
- 사분위수
- 검정통계량
- p-value
테블로나 파워비아이?
02.1. 라이브럴리 불러오기
!pip install koreanize_matplotlib -q
import matplotlib.pyplot as plt
import koreanize_matplotlibwarnings.filterwarnings(action='ignore')
%config InlineBackend.figure_format='retina'02.2. 기본차트 그리기
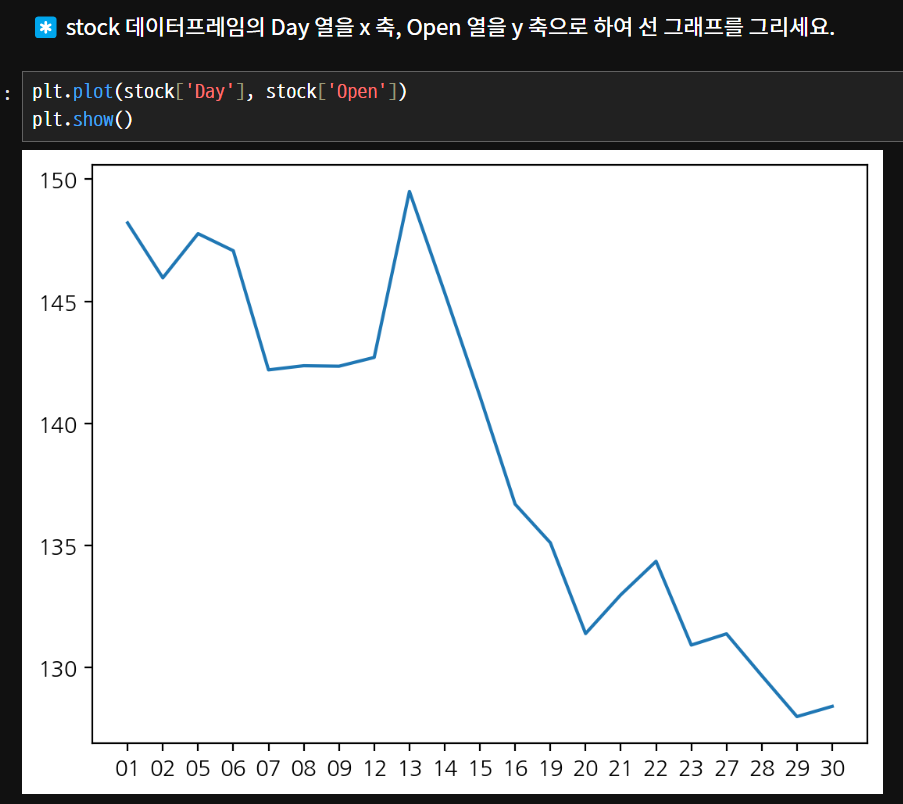
plot() 함수를 사용해서 그래프를 기본적으로 그릴 수 있다.
stock = stock.loc[stock['Date'].between('2022-12-01', '2022-12-31'), :]콤마 뒤에 오는 콜론은 삭제가 가능하다. 전체 데이터에서 일부 부분만 가져왔기 때문에 인덱스를 reset_index 해준다.
plt.plot() 는 꺾은선 그래프를 그린다.
plt.show() 깔끔하게 그래프만 나오게 보여준다.
plot() 안에 값을 하나만 넣으면 Y축값이 된다. x축을 지정하지 않으면 '인덱스'가 x축이 된다.
언제가 얼마였는지가 중요하지 않고 y축에 대한 전제척인 흐름를 보는 것이 중요하다.
숫자의 경우 눈금이 생략이 가능하다. 문자열의 경우는 생략되지 않는다.
02.3. 그래프 꾸미기
축의 이름과 그래프의 이름을 정해줄 수 있다.
- xlabel(), ylabel() 함수를 사용해 각 축의 이름을 지정한다.
- title() 함수를 사용해 그래프 제목을 지정한다.
size : 폰트의 크기
pad : 제목과 그래프의 간격
shift+tab 을 함수 내에 커서를 두고 누르면 함수 내 매개변수를 확인할 수 있다.
선의 스타일과 마커의 모양을 설정할 수 있다.
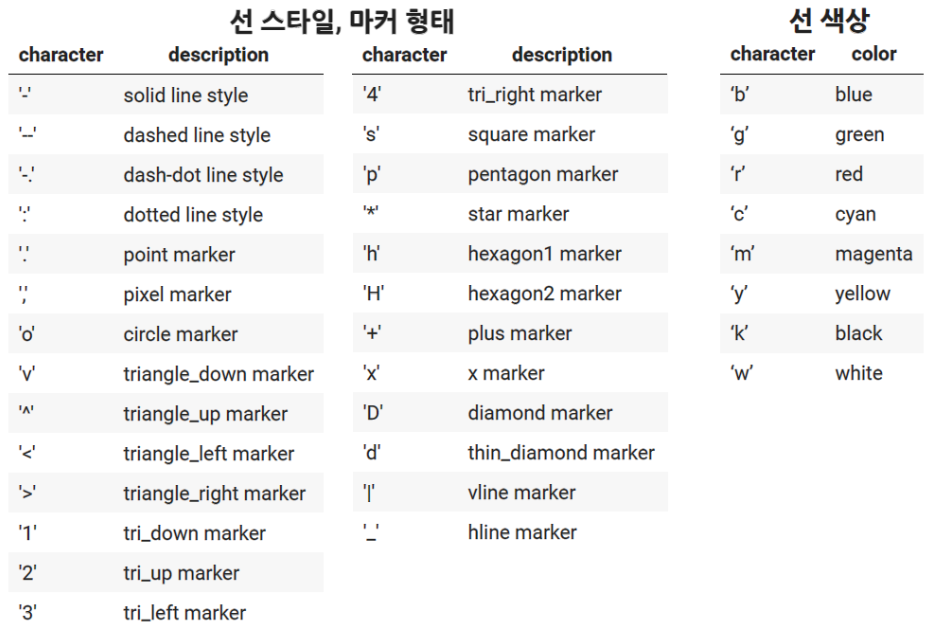
plt.plot() 안에 선의 색상 g, 선의 스타일 o-- 으로 지정해서 그래프의 linestyle를 설정할 수 있다. '.--'은 작은 동그라미의 마커를 의미한다.

여러 그래프를 겹쳐서 그릴 수 있다.
show()로 그래프를 마무리하기 전에 plot() 함수를 반복해서 사용하면 여러 그래프를 겹쳐서 그릴 수 있다.
plt.plot(stock['Day'], stock['Open'], color='tab:blue', marker='o', linestyle='--' , markersize=10)
plt.plot(stock['Day'], stock['Close'], color='r', marker='s', linestyle='--')
plt.title('Stock Price', size=15, pad=10)
plt.xlabel('Day')
plt.ylabel('Price')
plt.show()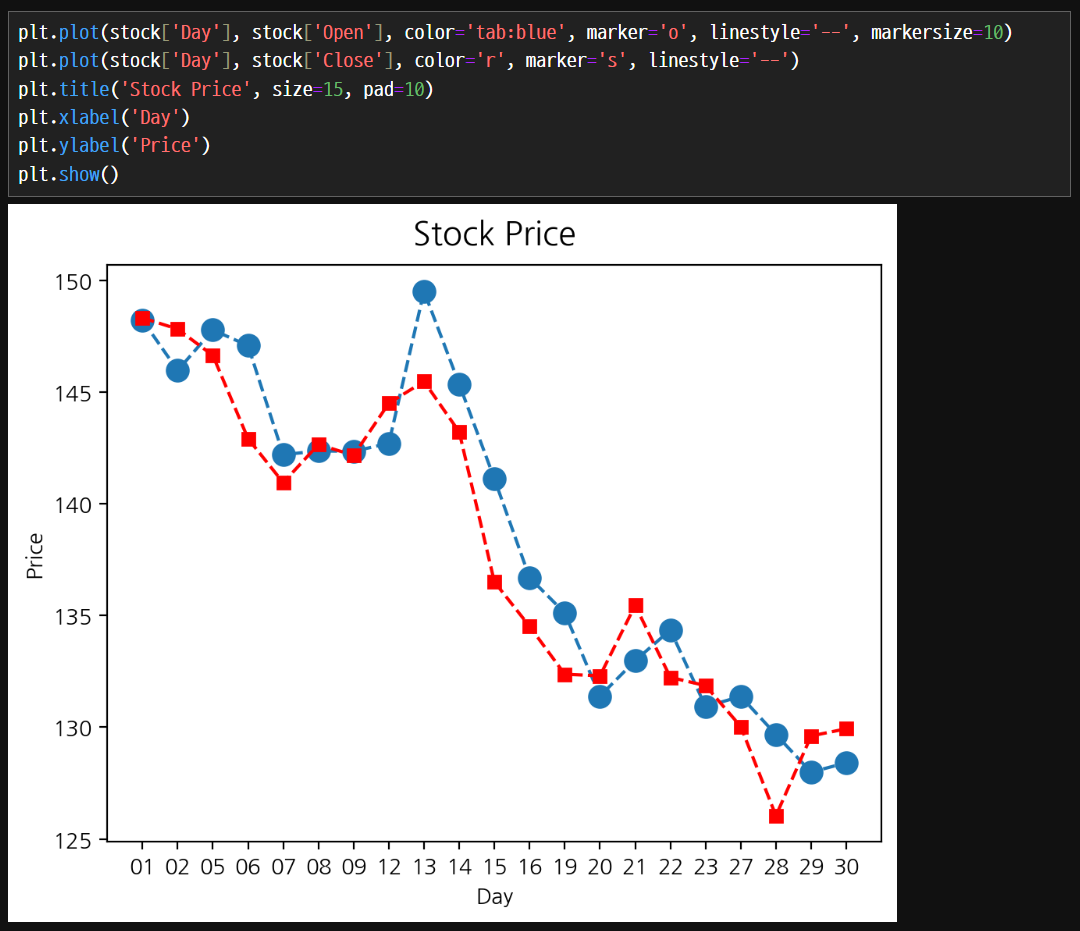
linewidth 으로 그래프 선의 굵기도 지정할 수 있다

plt.xticks()와 plt.yticks()로 눈금을 설정할 수 있다.
범례와 괘선을 추가할 수 있다.
- legend() 함수를 사용해 범례를 표시해 그래프에 대한 이해를 도울 수 있습니다.
- label 속성을 사용해 각 그래프의 이름을 지정한 후 legend() 함수를 사용합니다.
- 표시할 범례 정보를 legend() 함수 안에 리스트 형태로 지정할 수 도 있습니다.
- grid() 함수를 사용해 괘선을 표시합니다.
plt.plot()를 작성할 때 적은 label이 범례의 이름이 된다.
plt.legend()의 위치는 loc=''를 통해서 정할 수 있다. label를 미리 지정하지 않을 때는 legend에서 리스트 형태로 label를 지정한다.
plt.grid()로 axis = '' 어느 축에 그리드를 그릴지 설정할 수 있다.
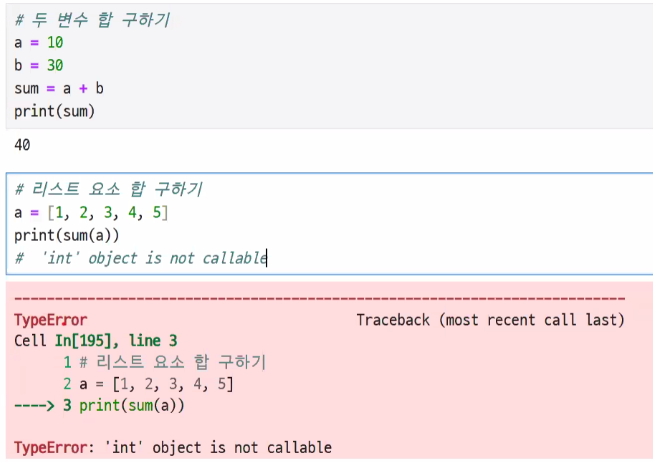
해당 변수의 메모리를 비워주거야 한다. del sum으로 변수로된 sum을 비워준다.
02.4. 섬세한 설정을 위한 기능
축의 범위를 조정할 수 있다.
- xlim(), ylim() 함수를 사용해 각 축에 표시할 범위를 지정합니다.
그래프의 크기를 조정할 수 있다.
- figure() 함수를 사용해 그래프 크기를 조절합니다.
- 기본 크기는 (6.4, 4.4) 이다.
수평선과 수직선을 추가할 수 있다.
- axhline(), axvline() 함수를 사용해 임의 위치에 가로선과 세로선을 그립니다.
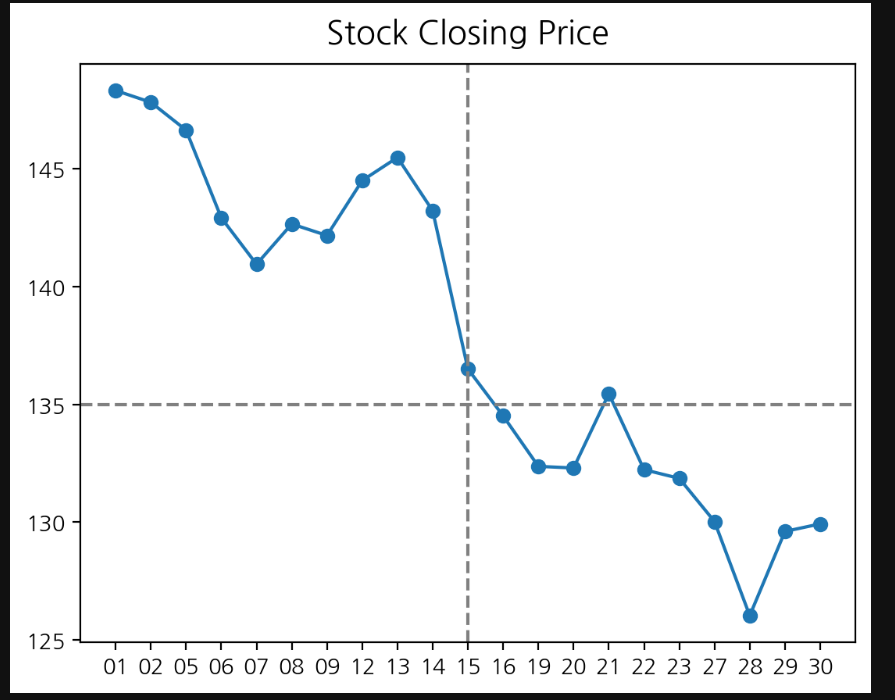
그래프를 그리고 평균이나 전체적인 선을 넣을 때 많이 사용한다.
그래프에 텍스트를 추가할 수 있다.
- text() 함수를 사용해 임의 위치에 텍스트를 출력합니다.
plt.plot(stock['Day'], stock['Close'], marker='o')
plt.title('Stock Closing Price', size=15, pad=10)
plt.axhline(135, color='grey', linestyle='--')
plt.axvline(10, color='grey', linestyle='--')
plt.text(-0.5, 135.2, '135', color='r')
plt.text(10.2, 125.5, '10', color='r')
plt.show()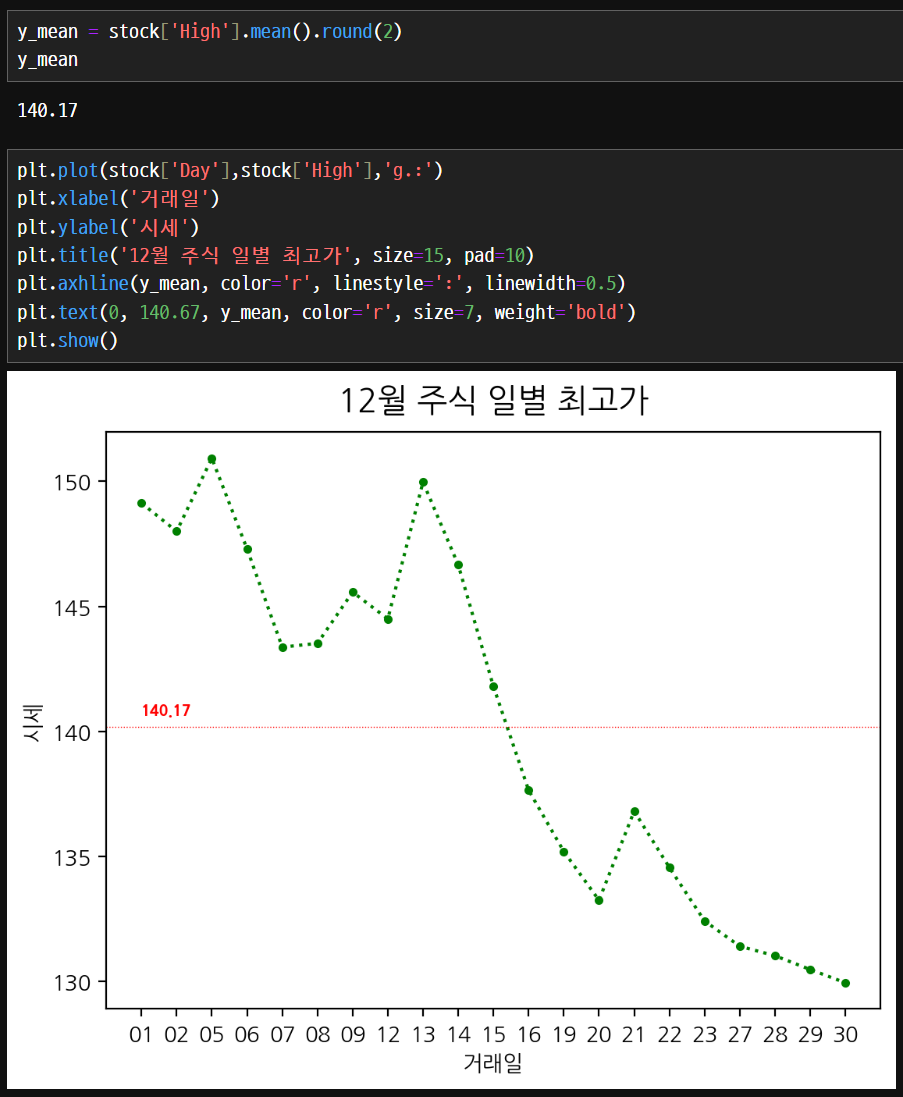
plt.axhline(y_mean, color='r', linestyle=':', linewidth=0.5)
plt.text(-0.5, y_mean+0.5, y_mean, color='r', size=7, weight='bold')선언한 변수를 이용해서 작성할 수 있다.
02.4. 위, 아래로 그래프 그리기
- subplot() 함수를 사용해 여러 행, 여러 열로 그래프를 한 번에 표시할 수 있다.
- subplot(행 수, 열 수, 위치) 형태로 지정한다.
- 만일 2행 1열로 표시할 것이면 subplot(2, 1, 1), subplot(2, 1, 2)를 사용한다.
- tight_layout() 함수를 사용해 그래프가 겹치지 않게 정리할 수 있다.
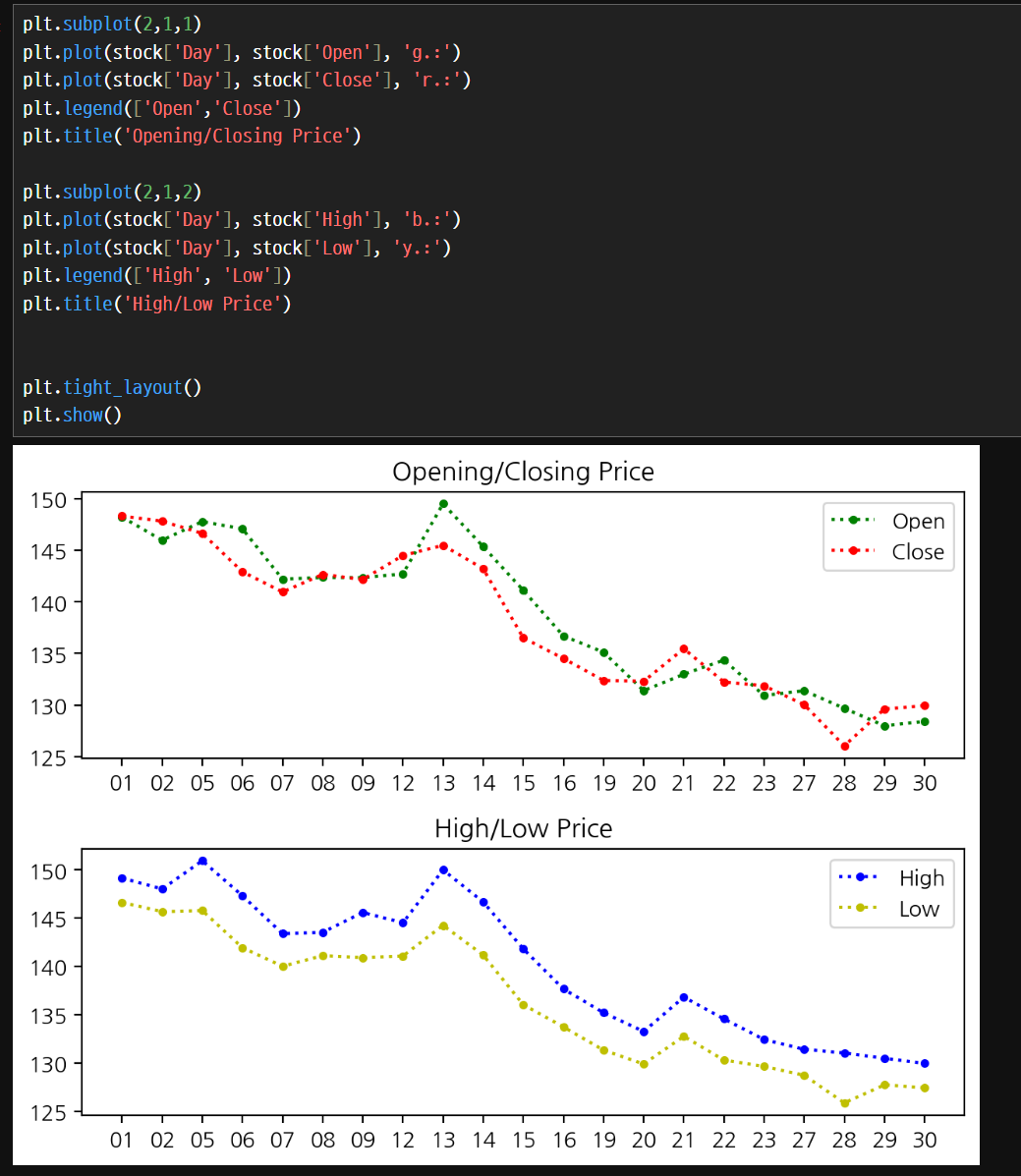
그린 그래프를 드레그 앤 드랍으로 바탕화면에 옮기면 그래프가 이미지로 저장된다.
03. Seaborn 라이브러리
seaborn은 데이터 시각화의 라이브러리 중 하나이다.
matplotlib을 기반으로 작성되었으며 고수준 인터페이스를 제공한다.
03.1. 환경준비
사용할 기본 라이브러리와 분석 대상이 되는 데이터를 읽어온다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import koreanize_matplotlib
import seaborn as sns
import warnings03.2. 기본 그래프
histogram
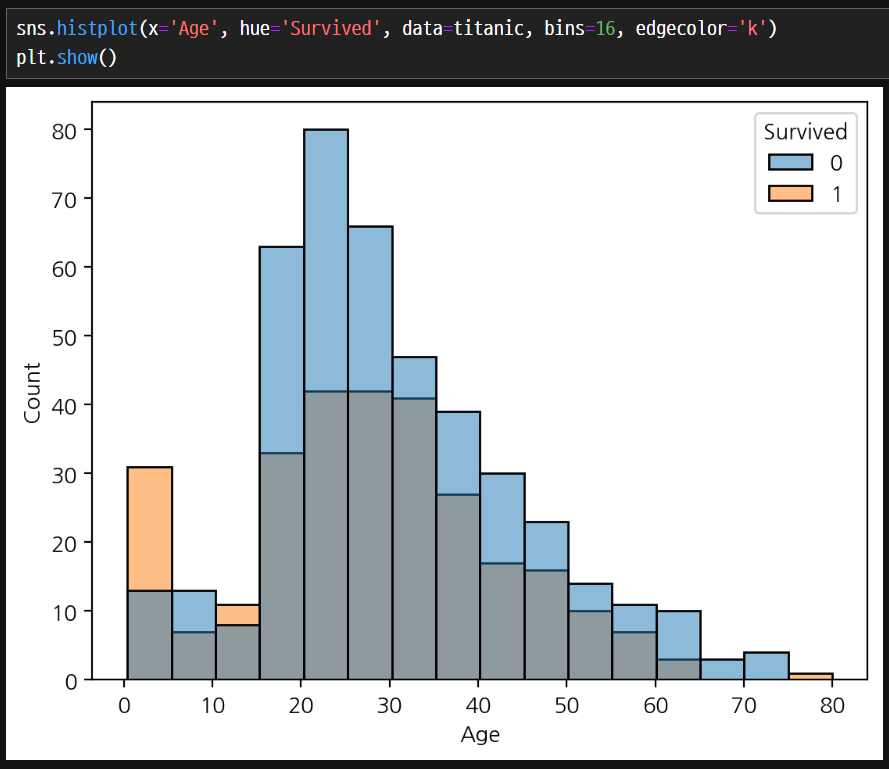
- sns.histplot() 함수는 단일 변수의 데이터 분포를 Histogram으로 표시합니다.
- hue 매개변수를 사용하여 구분 기준이 되는 범주형 변수를 지정할 수도 있습니다.
histogram의 단점은 bin를 설정해주지 않으면 데이터에 따라 변경되어서 일관성이 없다.
데이터의 분포를 막대로 표현하여 구간별로 확인한다.
seaborn의 hue는 특별한 기능이다. age에 대해서 survived에 따라서 0과 1로 나눌 수 있다. 누적이 아닌 값임을 확인하자. 이는 matplotlib에는 존재하지 않는 기능이다.
hue 매개변수를 사용하면 지정한 변수의 데이터 분포를 다른 열을 기준으로 구분해 확인할 수 있다.
Density plot
- sns.kdeplot() 함수는 단일 변수 또는 두 변수의 데이터 분포를 Density Plot으로 표시합니다.
- 숫자형 변수의 값 분포를 확인할 수 있는 커널밀도추정(KDE, kernal Density E) 그래프를 표시합니다.
- 그래프 아래의 면적이 1이 됩니다.
- x와 y 매개변수 중 하나를 사용하여 변수를 지정해 표시되는 방향을 조정합니다.
- hue 매개변수를 사용하여 구분 기준이 되는 범주형 변수를 지정할 수 있습니다.
빈도에 따라서 모양이 변하지 않는다. 히스토그램은 빈도에 따라서 모양이 변한다.
연속된 숫자의 데이터를 확률값을 그래프로 나타낸다. 그럼으로 그래프 내 면적은 100% 1이 된다.
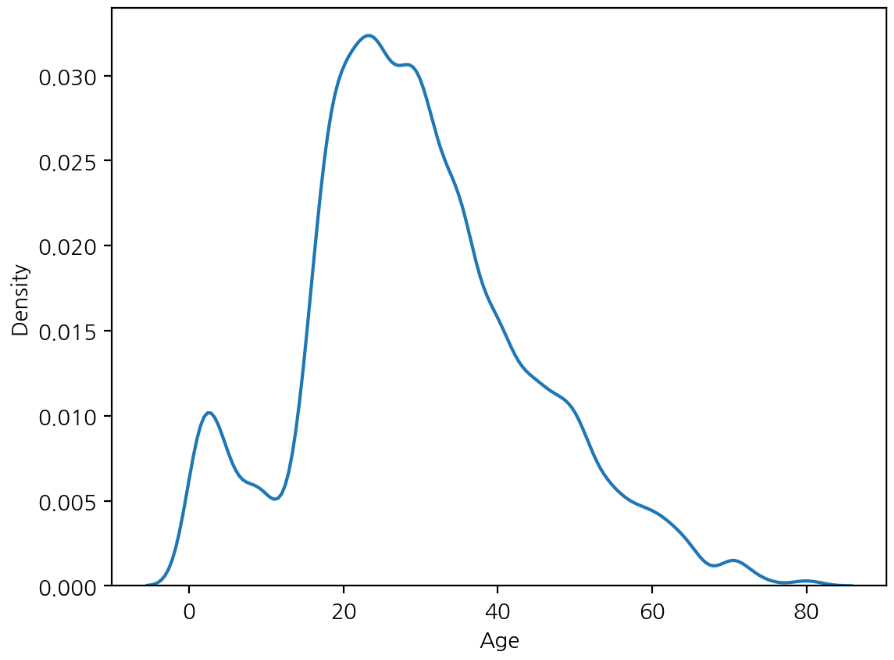
sns.kdeplot(x='Age', data=titanic, bw_adjust=0.5)
plt.show()bw_adjust는 디폴트가 1로 부드러운 곡선을 보여주며 해당 값을 조정하여 히스토그램과 유사하게 나타낼 수 있다.
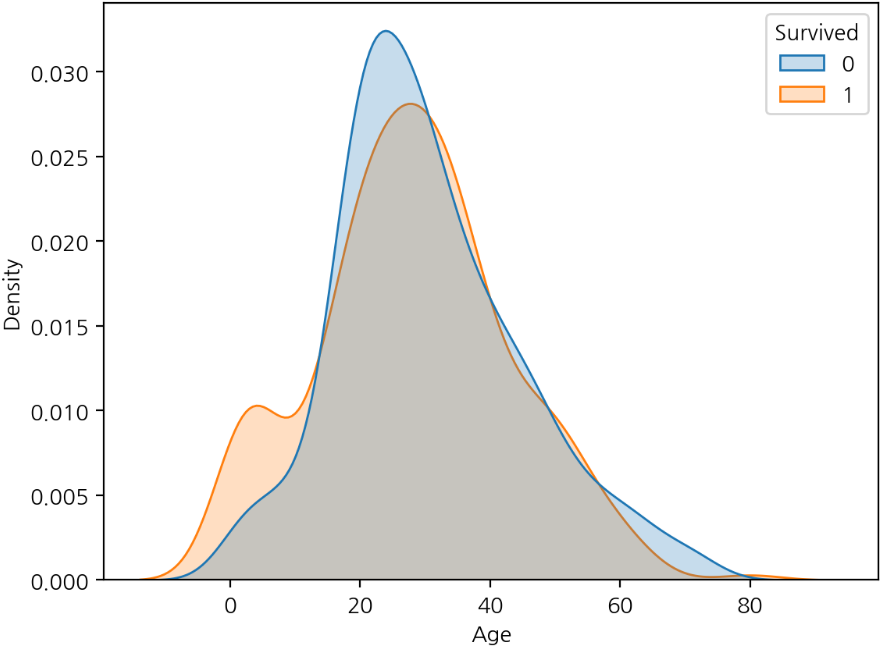
hue 매개변수를 사용하면 구분하는 열에 따라서 각각의 그래프의 면적이 1이 되게 한다.
- common_norm=False를 지정하면 그래프 각각의 면적이 1이 됩니다. True로 지정하게 되면 두 그래프의 면접의 합이 1이 된다.
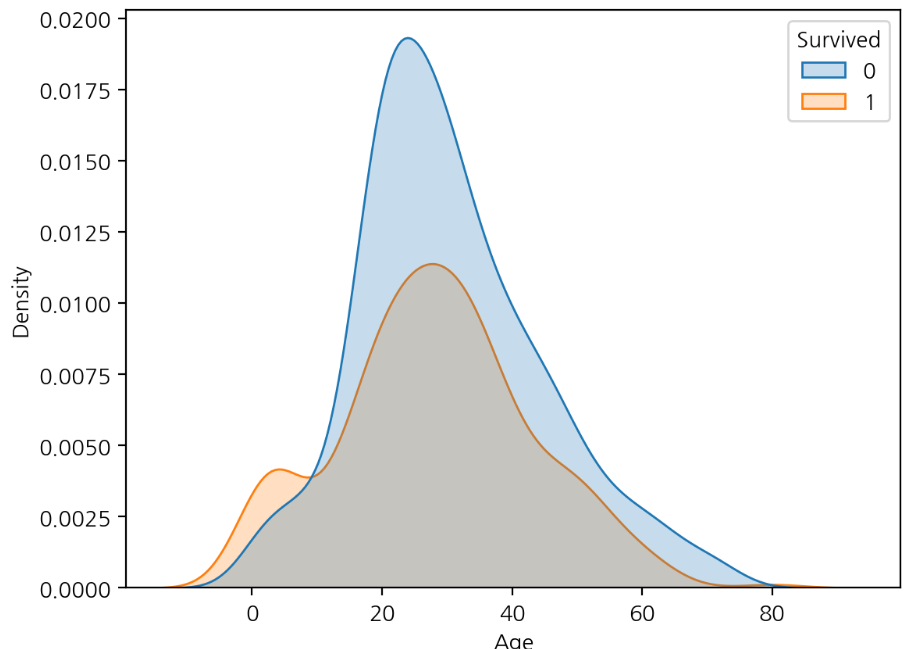
Box plot
- boxplot() 함수는 단일 변수나 여러 변수의 분포를 Box Plot으로 표시합니다.
- 변수의 분포와 이상치(Outlier)를 시각적으로 탐색할 수 있습니다.
- boxplot() 함수는 x와 y 매개변수 중 하나를 사용하여 변수를 지정합니다.
- hue 매개변수를 사용하여 구분 기준이 되는 범주형 변수를 지정할 수 있습니다.
sns.boxplot(y='Age', data=titanic)
plt.show()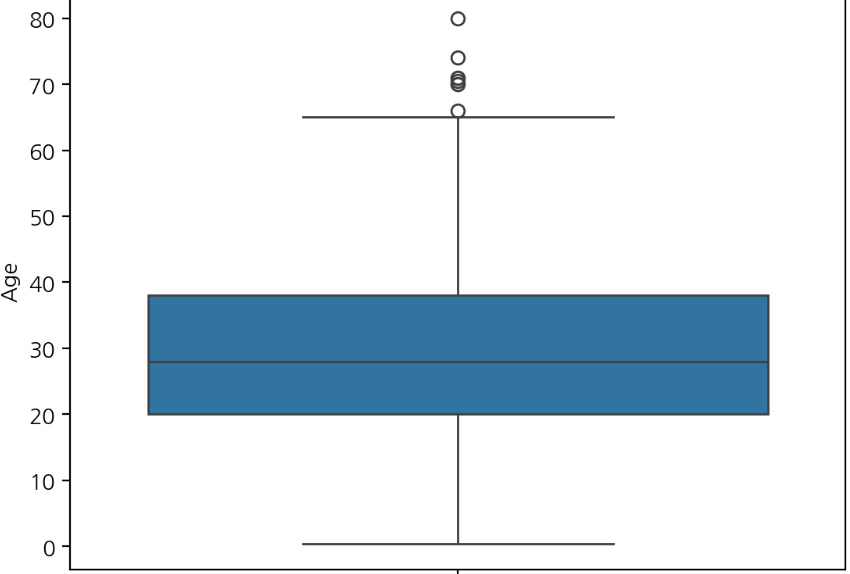
IQRx1.5의 값은 그래프에서 나타나지 않고 해당 값 안에서 가장 작은 값은 가로줄로 나타나고, 선을 넘어가는 큰값은 이상치로 나타난다. boxplot에서는 중앙값임을 알 수 있고 평균은 그래프 내에서 알 수 없다.
sns.boxplot(y='Age', x='Survived', data=titanic)
plt.show()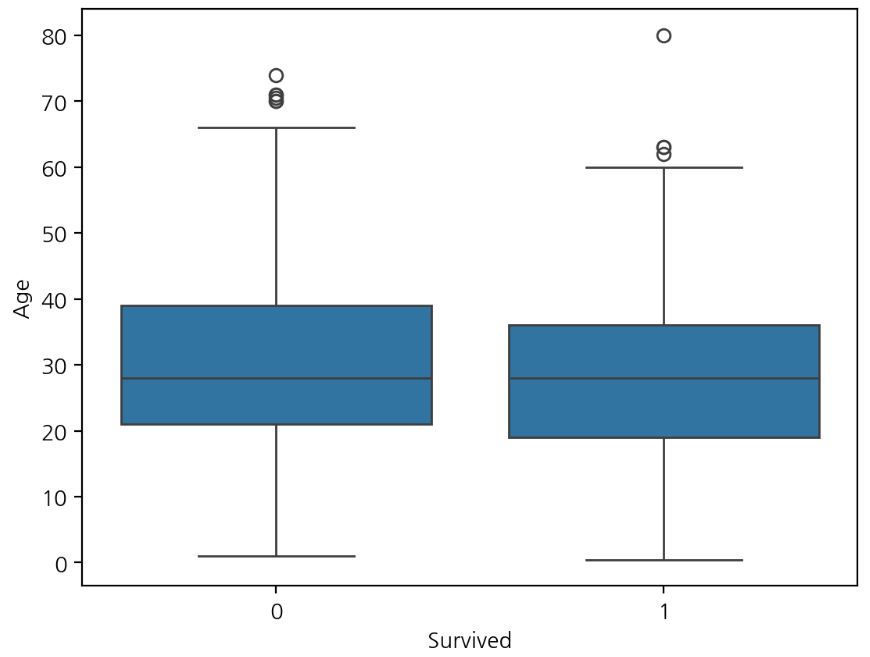
x에 설정한 컬럼을 기준으로 y축에 설정된 컬럼의 분포를 확인한다.
sns.boxplot(x='Age', y='Survived', data=titanic, orient='h')
plt.show()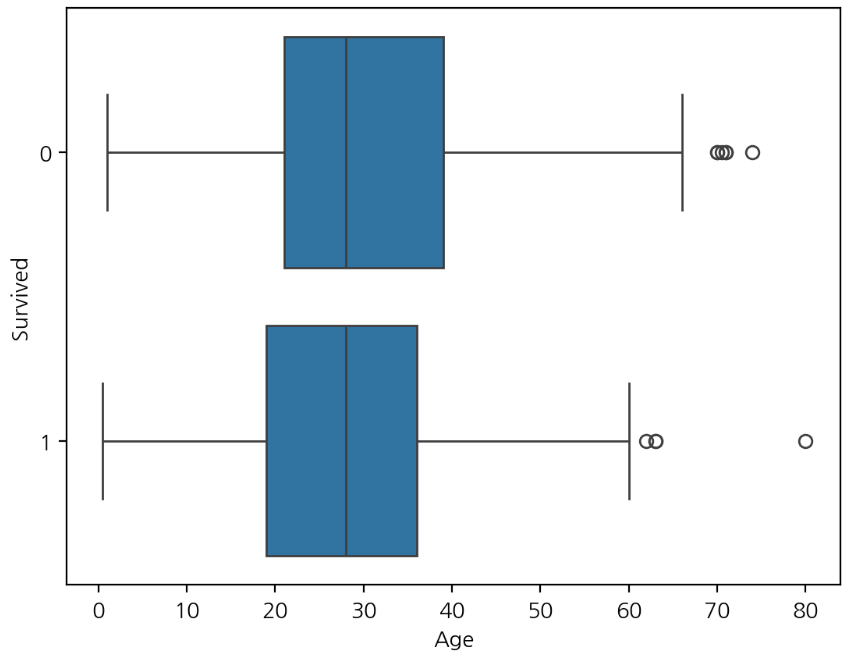
가로로 그래프를 그리고 싶을 때는 orient='h'로 지정해서 그릴 수 있다.
하한(lower bound) : Q1-1.5IQR
상한(upper bound) : Q3+1.5IQR
03.3. 고급 그래프
Distribution plot
- distplot() 함수는 단일 변수의 분포를 시각화하기 위한 함수입니다.
- Histogram과 Density Plot을 같이 표시할 수 있습니다.
- kde 매개변수를 사용하여 커널밀도함수 그래프를 추가로 그릴지 여부를 지정합니다.
- rug 매개변수를 사용하여 각 데이터 포인트의 위치를 보여주는 선을 그릴지 지정할 수 있습니다.
- hist_kws 매개변수에 꾸미기 위한 다양한 설정 값을 딕셔너리 형태로 전달합니다.
sns.distplot(x=titanic['Age'], bins=16, hist_kws={'edgecolor': 'k'},
kde=True,
hist=True,
rug=True)
plt.show()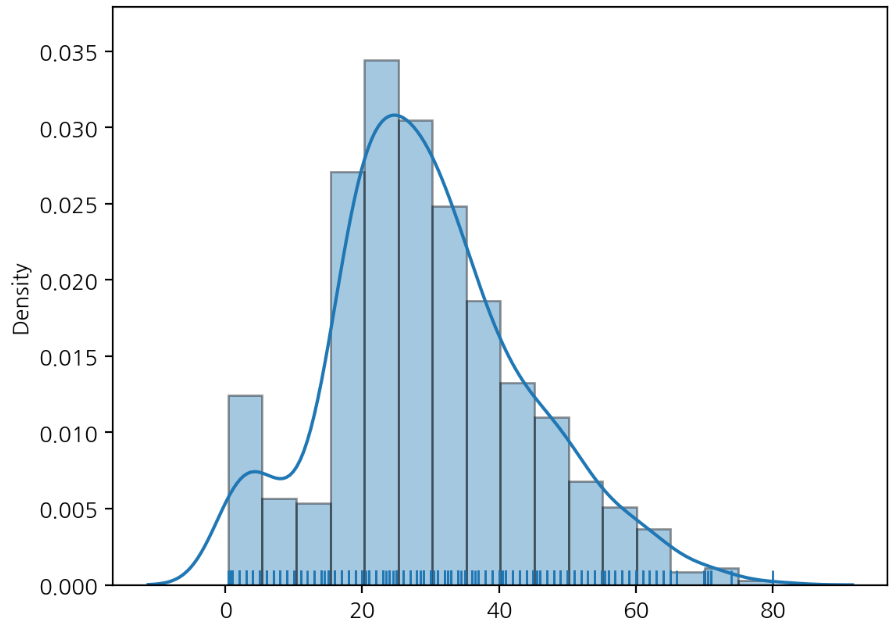
단일 변수의 시각화를 나타낸다. histogram과 density plot을 같이 그릴 수 있다. hue 매개변수 사용이 불가하다.
joint plot
- jointplot() 함수는 두 변수 간의 관계를 시각화하기 위해 산점도와 히스토그램을 함께 그려줍니다.
- kind 매개변수를 사용하여 그래프의 종류를 지정할 수 있습니다.
- hue 매개변수를 사용하여 구분 기준이 되는 범주형 변수를 지정할 수 있습니다.
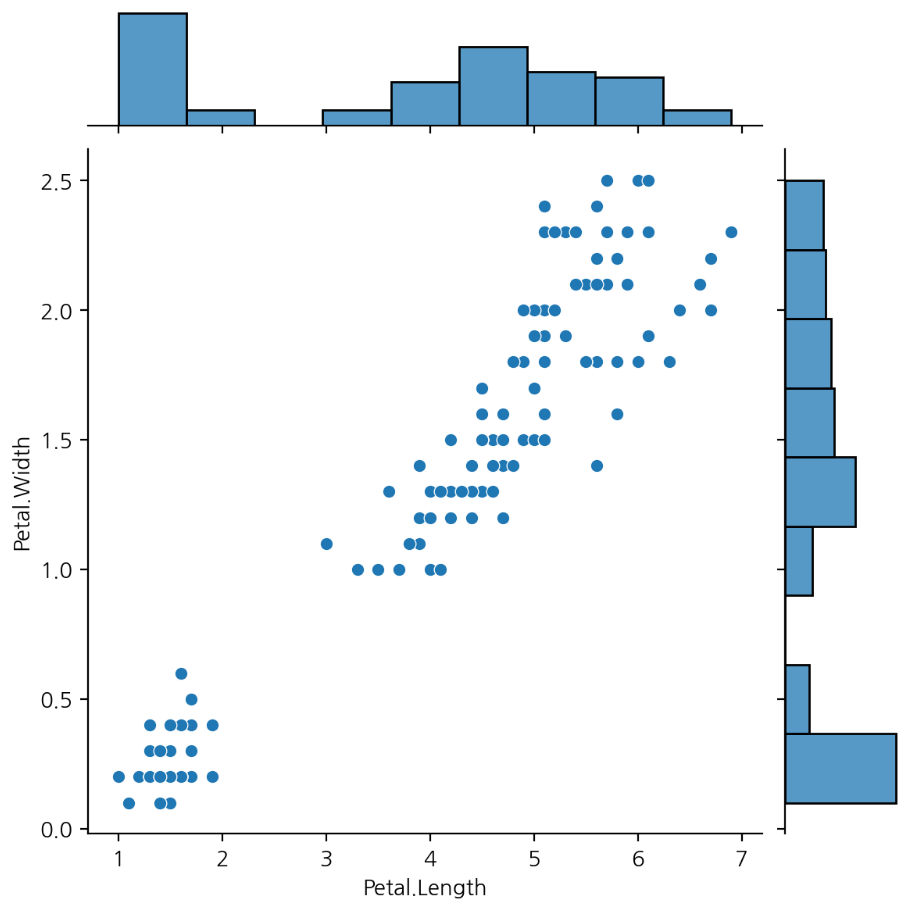
두 변수 간의 관계를 시각화한다. 산점도와 histogram을 같이 그릴 수 있다.
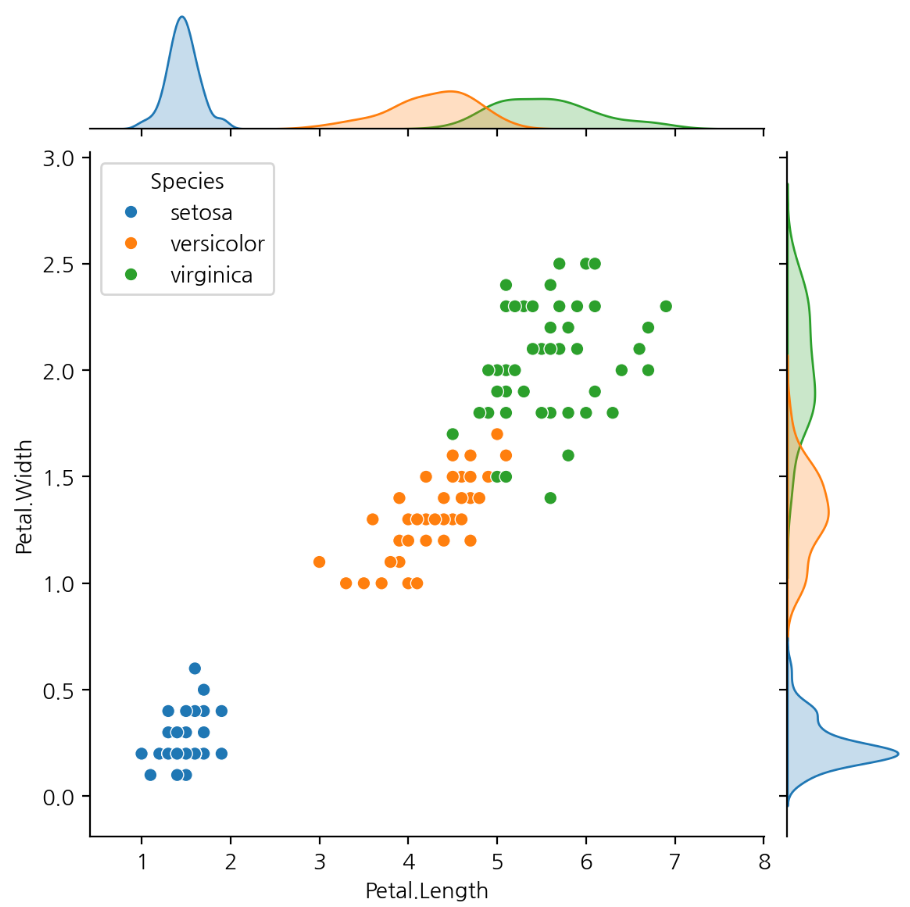
hue 매개변수를 사용할 수 있다.
Pair plot
- pairplot() 함수는 변수 간의 산점도 및 변수 분포를 한 번에 시각화하는 기능을 제공합니다.
- hue 매개변수를 사용하여 추가적인 범주형 변수를 지정할 수 있습니다.
- 하지만 그려지는 데 시간이 많이 걸리는 단점이 있습니다.
여러 변수 간의 관계를 산점도와 변수 분포를 시각화한다. 변수 간의 관계는 산점도로 나타나고, 변수 자기자신은 히스토그램 분포로 나타난다.
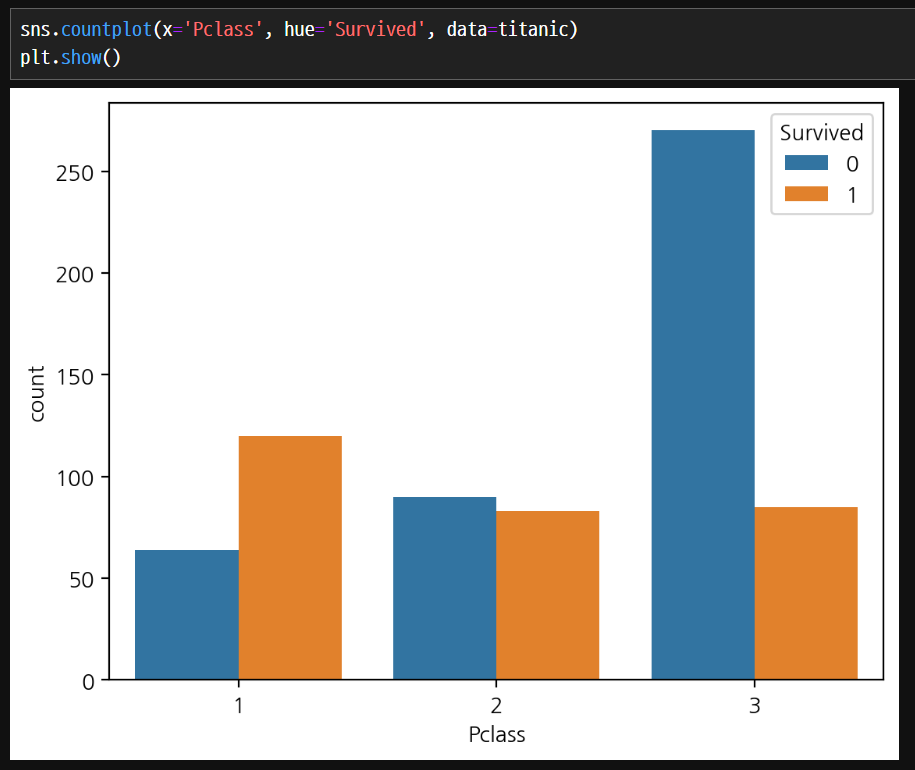
Count plot
- countplot() 함수는 범주형 변수의 빈도를 막대 그래프로 시각화하는 함수입니다.
- 주어진 데이터셋에서 각 범주의 개수를 계산하고 막대 그래프를 그려줍니다.
- hue 매개변수를 사용하여 특정 범주형 변수를 기준으로 구분해 표시할 수 있습니다.
- order와 hue_order 매개변수를 사용하여 막대 그래프에 그려질 범주의 순서를 지정할 수 있습니다.
count plot을 사용하면 집계하지 않아도 알아서 count하여 집계할 수 있다.
머신러닝에서 분류 데이터가 어떻게 분포하고 있는지 확인할 때 count plot을 많이 사용한다.
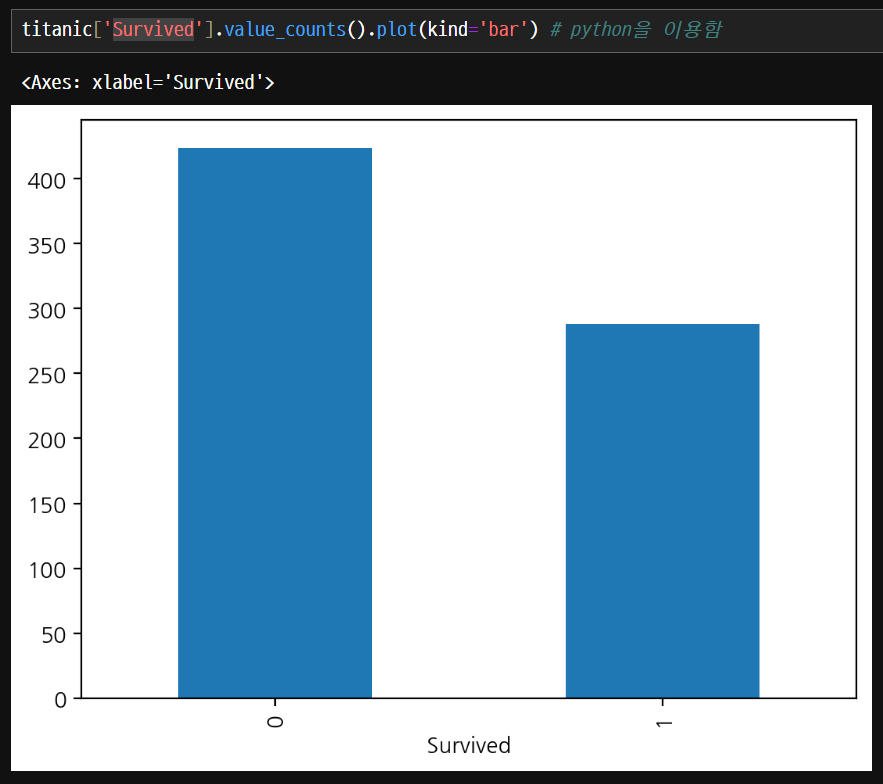
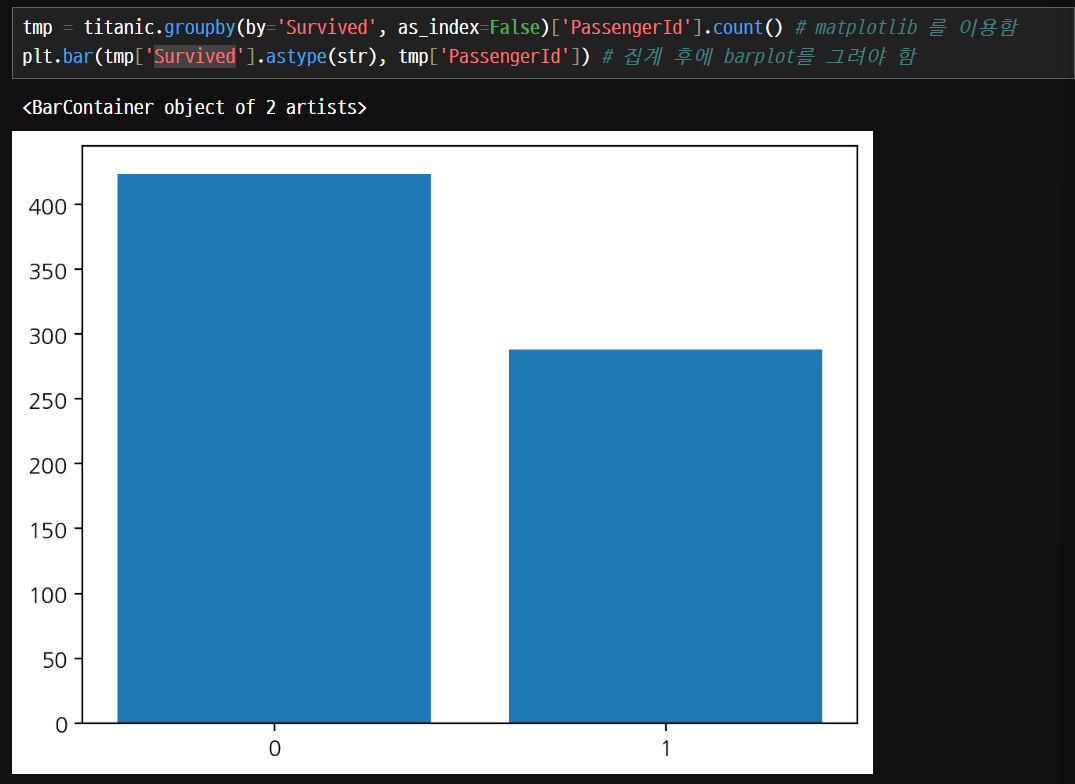
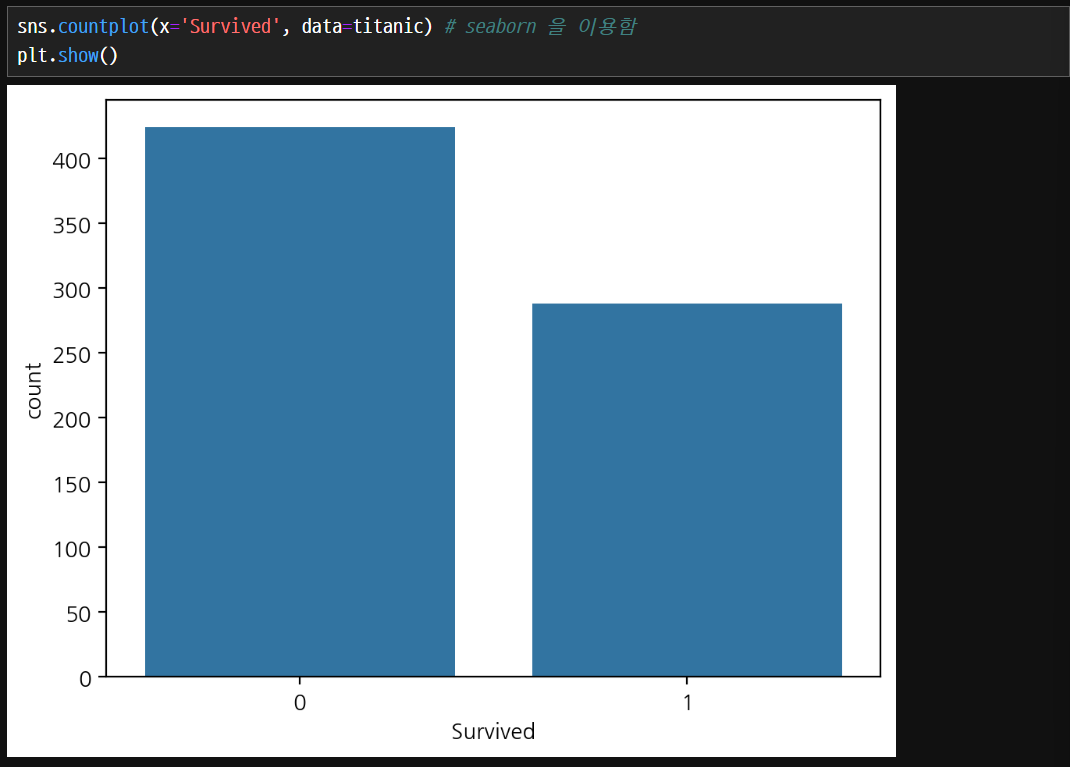
hue 매개변수가 사용이 가능하다.
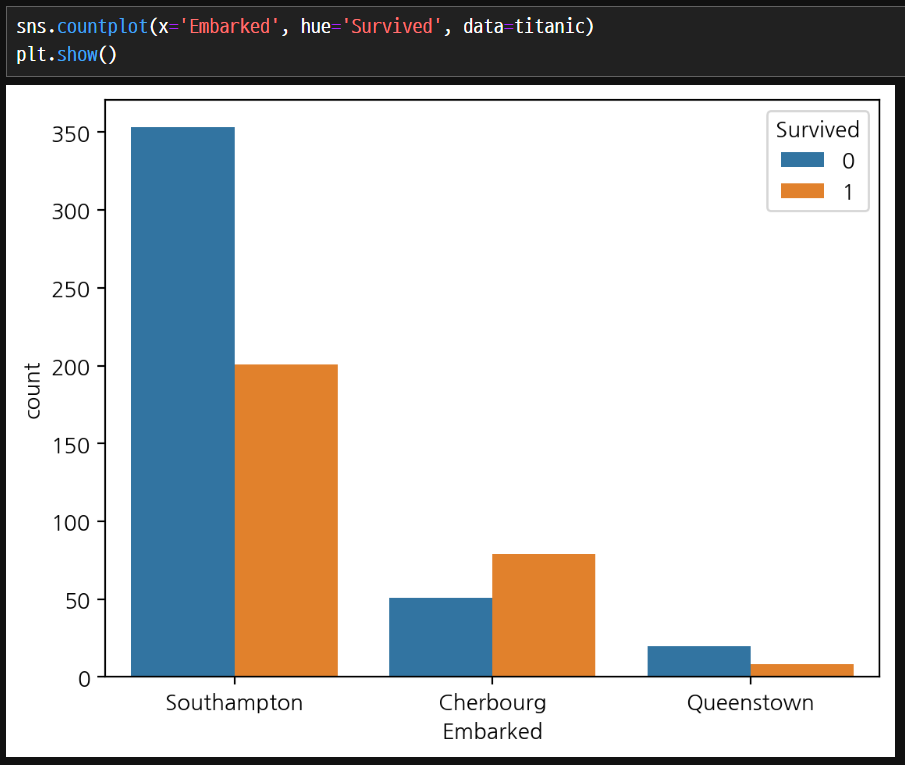
생존자수1만 보았을 경우에는 큰 차이가 없지만 전체적인 생존 비율을 hue 매개변수를 통해서 비교하면 의미있는 값을 구할 수 있다.
Bar plot
- barplot() 함수는 범주형 변수에 대한 막대 그래프를 그리는 함수입니다.
- barplot() 함수는 데이터를 추정하고 오차 막대를 표시할 수 있습니다.
- 이 오차 막대는 각 범주의 평균과 신뢰 구간을 시각화하는 데 사용됩니다.
- hue 매개변수를 사용하여 특정 범주형 변수를 기준으로 구분해 표시할 수 있습니다.
- 예를 들어, hue 매개변수를 사용하여 다른 집단에 대한 데이터를 시각적으로 구분할 수 있습니다.
- barplot() 함수는 기본적으로 평균값을 계산하고 오차 막대를 그립니다.
- 필요하다면 estimator 매개변수를 사용하여 다른 추정값을 지정할 수 있습니다.
- 예를 들어, estimator=np.median를 사용하여 중앙값을 계산할 수 있습니다.
bar plot은 데이터의 평균과 신뢰 구간을 시각화해준다. csv로 가져오는 데이터는 세상의 모든 데이터가 아니다. 전체 데이터인 모집단에 대해서 표본만을 가지고 있는 것이다.
신뢰구간은 표본에서 일부만 무작위 샘플링을 하여 평균을 구한다. 복원추출을 하여 샘플링을 반복(5000번)해서 구한 평균들의 평균을 구한다. 분포를 그려서 가장 작은 2.5%와 가장 큰 2.5% 평균을 제거하여 세로선의 95% 신뢰구간을 의미한다.
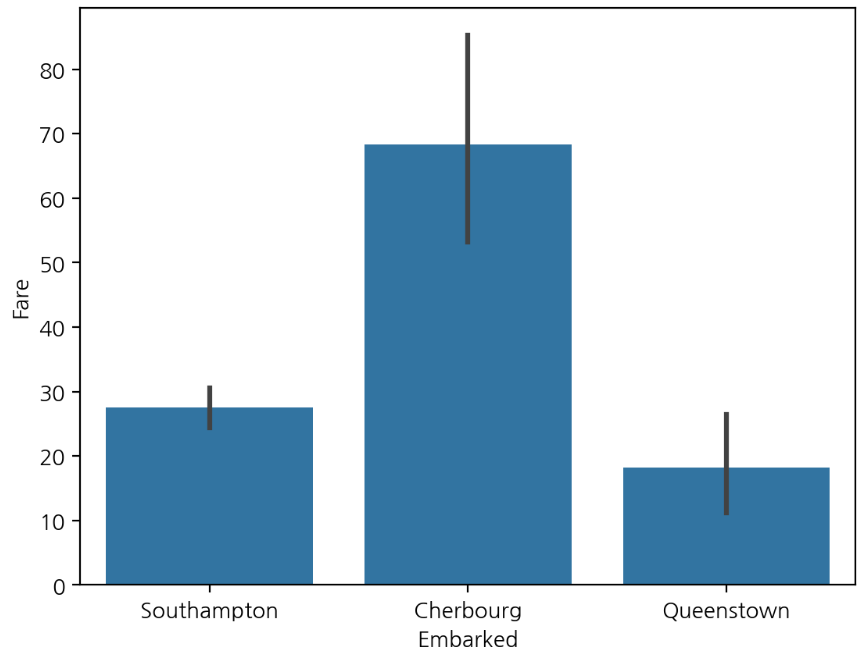
sns.barplot(x='Embarked', y='Fare', data=titanic, errorbar=('ci', 95), n_boot=5000)
plt.show()errorbar 매개변수로 디폴트 신뢰구간 외에 지정이 가능하고, n_boot 매개변수를 통해서 무작위 샘플링 복원 추출의 반복횟수를 지정할 수 있다.
heatmap
- heatmap() 함수는 두 범주형 변수를 집계한 결과를 색의 농도 차이로 표시합니다.
- 이를 위해서 집계(groupby)와 피봇(pivot)을 먼저 만들어 줘야 합니다.
- 여러 범줏값을 갖는 변수를 비교할 때 유용합니다.
- Embarked 별 Pclass 별 탑승자 수를 표시해 봅니다.
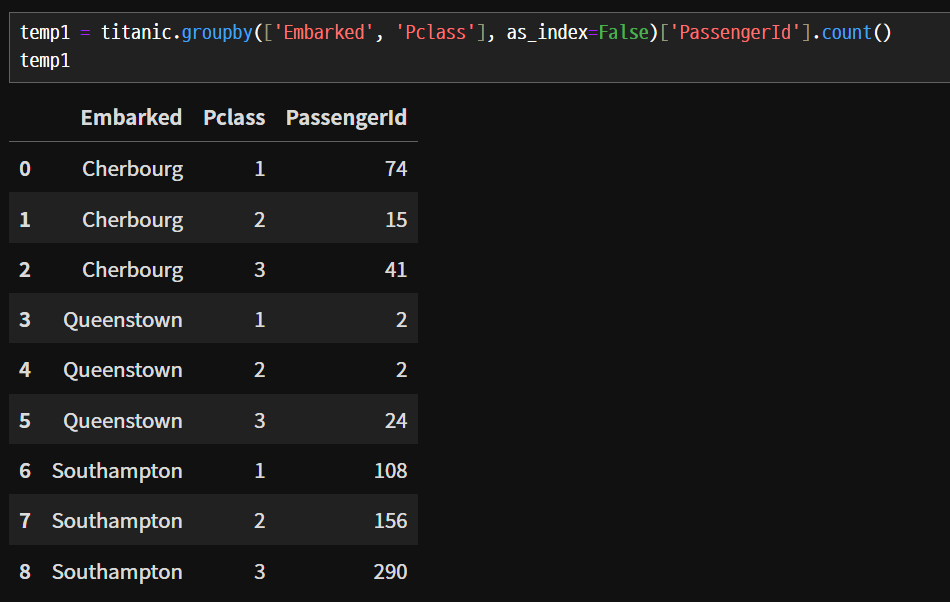
pivot()함수를 통해서 2개의 축으로 데이터를 집계하여 정리할 수 있다.
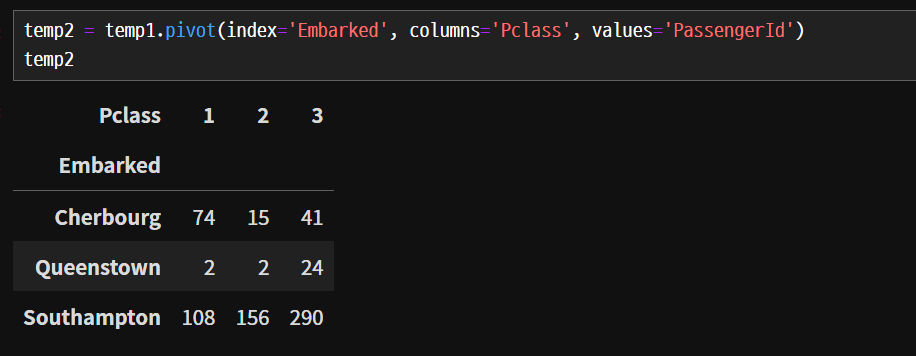
temp1 = titanic.groupby(['Embarked', 'Pclass'], as_index=False)['PassengerId'].count()
temp2 = temp1.pivot(index='Embarked', columns='Pclass', values='PassengerId')
display(temp2)
sns.heatmap(temp2, annot=True)
plt.show()heatmap의 색이 연할수록 큰값, 진한색일수록 작은값을 의미한다.
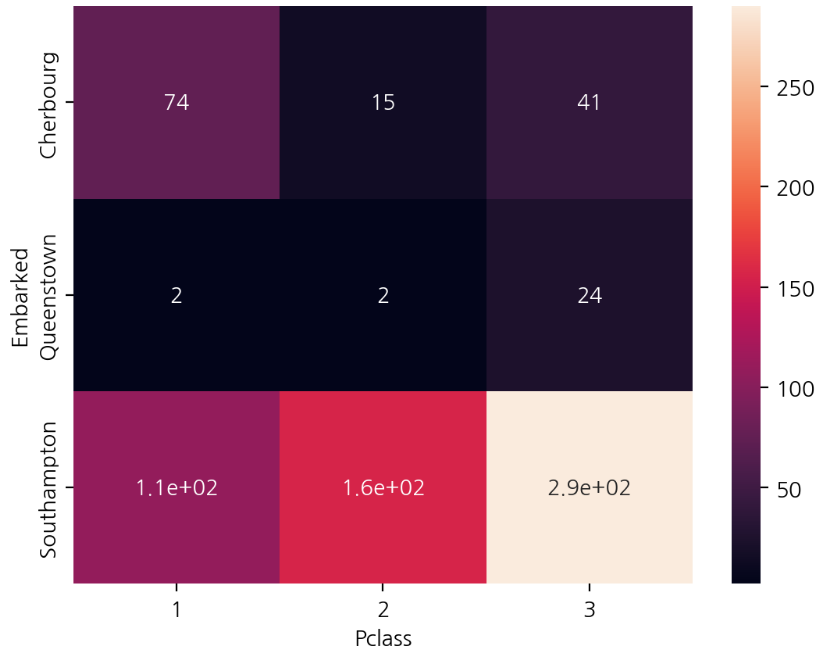
- annot 매개변수는 heatmap 내에 숫자값을 표시한다.
- fmt 매개변수는 표시 형식 지정한다.
- linewidth 매개변수는 간격을 지정한다.
- cmap 매개변수는 색상을 지정한다.
- cbar 매개변수를 False로 지정하면 colorbar를 제거할 수 있다.
- square = True 을 통해서 heatmap내에 바를 정사각형으로 고정할 수 있다.
문자 데이터는 heatmap으로 구현할 수 없음으로 오류가 발생한다. 숫자들로 이루어진 컬럼들만 분석이 가능하다.
box plot, heat plot은 신경을 써주어야 한다.
04. 데이터 분석 프로세스
04.1. CRISP-DM
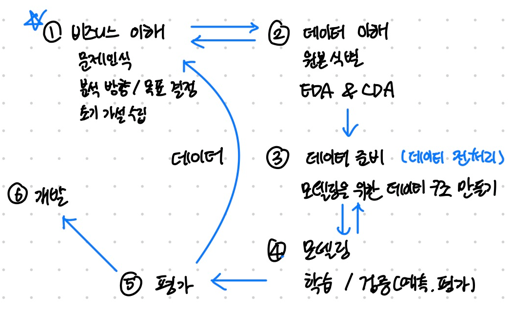
Business understanding
비즈니스에서 어떤 문제가 발생하였는지 탐색하고 데이터 분석의 방향과 목표를 설정하여 초기 가설을 수립힌다.
- 비즈니스 관점 : 고객 서비스 부서 고객 수 유지 목표
- 데이터 분석 관점 : 고객 이탈 전에 정확도로 예측 -> 분류 문제
초기 가설 수립에서는 다양한 직무의 사람들과의 의견을 수렴할 필요가 있다. 데이터 의 존재 여부를 고려하지 않고 가설을 도출한다.
Data understanding
문제의 해결책을 만드는 데이터가 문제에 정확히 부합하는 데이터가 있는 경우는 많이 없다. 데이터에 따라서 데이터 취득 및 유지 비용이 다르다.
가용 데이터를 하나의 데이터프레임으로 가공해야 한다. 새로운 원시 데이터를 넣었을 때 원활하게 작동하는 데이터파이프라인을 구현해야 한다.
데이터 탐색 : EDA, CDA
- EDA : 개별 데이터의 분석, NA와 이상치 파악
- CDA : 탐색으로 파악이 애매한 정보는 통계적 분석 도구 사용
Data preparation
데이터 분석을 위해 특정 조거에 맞는 데이터 유형과 구조가 있기에 해당 데이터의 형태를 조작하고 변환하는 과정이 필요하다.
- 추가변수 도출
- 결측치 조치
- 가변수화
- 스케일링
- 데이터 분할
하나의 잘 정리되고 정제된 데이터프레임이 필요하다.
데이터가 범주형 데이터인지, 수치형 데이터인지에 따라서 나누고 탐색의 방법이 다르다.
- 범주형 데이터 : 질적 데이터(정성적)
- 수치형 데이터 : 양적 데이터(정량적)
Modeling
중요 변수들을 선택하고, 적절한 알고리즘을 적용하여 예측 모델을 생성한다.
- 중요 변수 선정
- 모델 생성
- 모델 성능 검증
모델링은 데이터로부터 패턴을 찾는 과정으로 오차를 최소화하는 패턴이다.
Evaluation
모델에 대한 데이터 분석 목표와 비즈니스 목표달성에 대한 평가한다.
모델에 대한 최종 평가는 test set를 이용한다.
Developing
프로덕션 환경의 파이프라인, 모델 및 배포가 고객 목표를 충족하는지 확인한다.
데이터 수집부터 모델 배포 관리까지 파이프라인으로 구성해야 한다.
05. 단변량 분석, 이변량 분석
분석할 수 있는 자료의 종류를 수치형과 범주형을 나눌 수 있다.
- 숫자로 저장된 자료이지만 범주형일 수 있다.
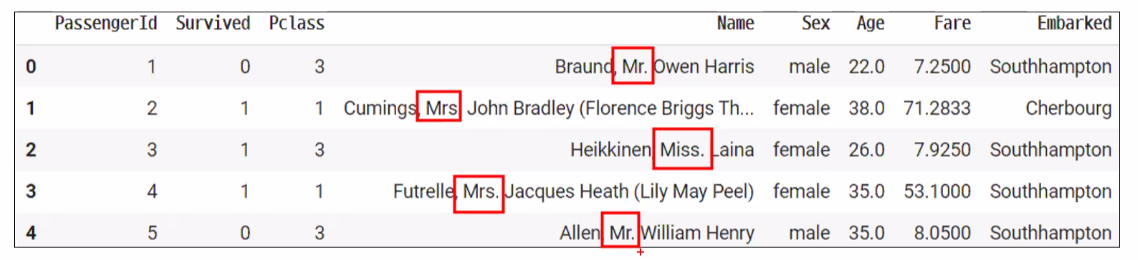
name컬럼을 보통 지웠지만 mr와 miss, mrs등을 통해서 결혼의 여부도 알 수 있다...!
Pclass에서 3등실이 모여서 1등실로 갈 수 없음..! 이는 숫자값에 의미를 가지지 않음을 나타내며 범주형으로 생각한다.
숫자의 크기에 의미가 있다면 수치형으로 분리할 수 있고, 의미가 없다면 범주형 데이터로 분리해야한다.
수치형 데이터
1. 수치화해서 분석한다. -> 최소값, 최대값, 평균값, 표준편차, 사분위수
2. 시각화해서 분석한다. -> histogram과 density plot, box plot으로 분포를 확인한다.
범주형 데이터
1. 수치화해서 분석한다. -> 최빈값 등 범주별로 비율value_counts을 확인한다.
2. 시각화해서 분석한다. -> bar plot이나 count plot으로 범주값별로 확인한다.
05.1. 단별량 분석① - 수치형
수치형 변수는 크기를 비교할 수 있는 연속적인 숫자를 갖는 변수이다.
plt.rcParams['figure.figsize'] = (6, 4)모든 차트의 크기를 고정할 수 있다.
수치화
mean() : 평균
median() : 데이터를 크기 순으로 나열한 상태에서 가운데 위치한 중앙값
mode() : 빈도가 가장 높은 값인 최빈값
describe() : 4분위수(25%, 50%, 75%, 경계에 있는 값은 양쪽값의 평균으로)와 함께 시리즈로 결과가 나타난다. 시리즈는 컬럼명으로 접근한다.
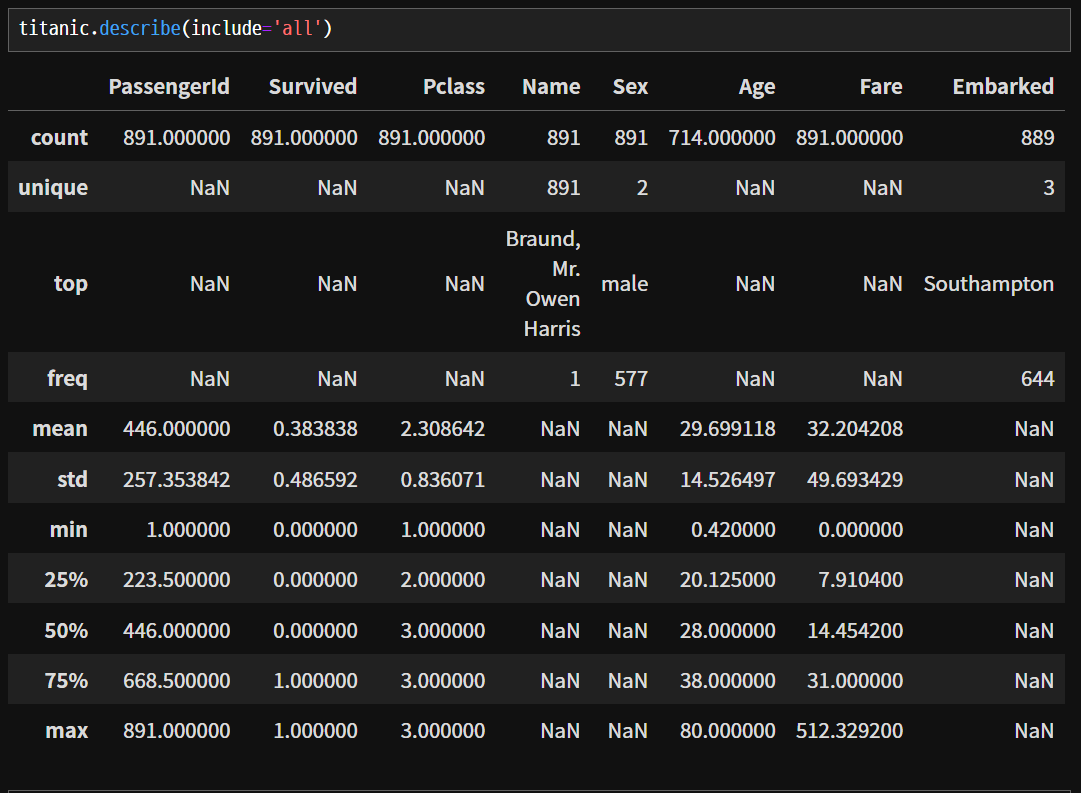
descirbe()는 기본적으로 수치 데이터에 대해서만 나온다. 모두 보고자 하면 include='all' 매개변수를 추가하여 볼 수는 있다.
titanic[['Age']].describe()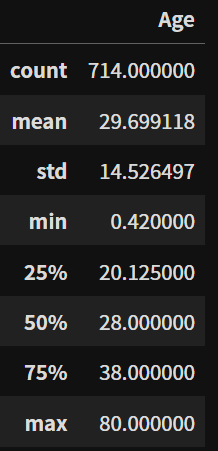
시리즈로 나오는 결과에 의지를 보여준다! []를 한번 더 씌움으로써 데이터프레임 형태로 결과를 표시할 수 있다.
titanic[['Age']].describe().T
결과를 가로 방향으로 바꾸어 표시할 수 있다.
06. 참고: 가설과 가설검정
07. 과정Summary
