Machine learning
기계학습의 정의와 종류에 대해서 알아보자.
1. 기계학습
인공지능의 한 분야로써, 알고리즘을 설계하는데 실험적으로 얻은 데이터로부터 점점 개선되도록 할 수 있는 알고리즘을 설계하고 개발하는 분야를 기계학습이라고 정의한다.
흔하게 혼용할 수 있는 단어들에 대해서 정리해보자.
- 인공지능 : 사람과 같은 지능을 만드는 분야
- 기계학습
- 컴퓨터 비전
- 자연어처리 : 언어 지능을 담당
- 딥러닝 : 기계학습 중에 신경망 중에 많은 계층 모델을 가지는 신경망을 쓰는 분야
2. 기계학습의 역사적 정의
하버트
경험을 통해서 성능을 높이는 시스템에 의한 모든 프로세스
아서 사무엘
직접적으로 프로그래밍하지 않고 컴퓨터가 스스로 배울 수 있는 능력을 다루는 학문
컴퓨터 프로그램 중에 E와 P와 T
T : task (어떤 작업을 수행할 것인가)
P : performance (어떤 성능지표를 정의하고 이를 통해 모델을 비교할 것인가)
E : Experience (어떤 학습 데이터를 사용할 것인가)
경험 Data E를 기반으로 해서 어떤 특정 Performance Measure , 혹은 Performance P를 개선하는 것이다. 그것이 어떤 작업T에 대한 것이다.
예를 들어 체스의 경우, T는 체스를 두는 것이라 할 수 있고 P는 여러가지 옵션 중에 승률과 같은 것으로 정의할 수 있고 한판 한판 둔 경험이 학습 E 데이터로써 활용이 될 것이다.
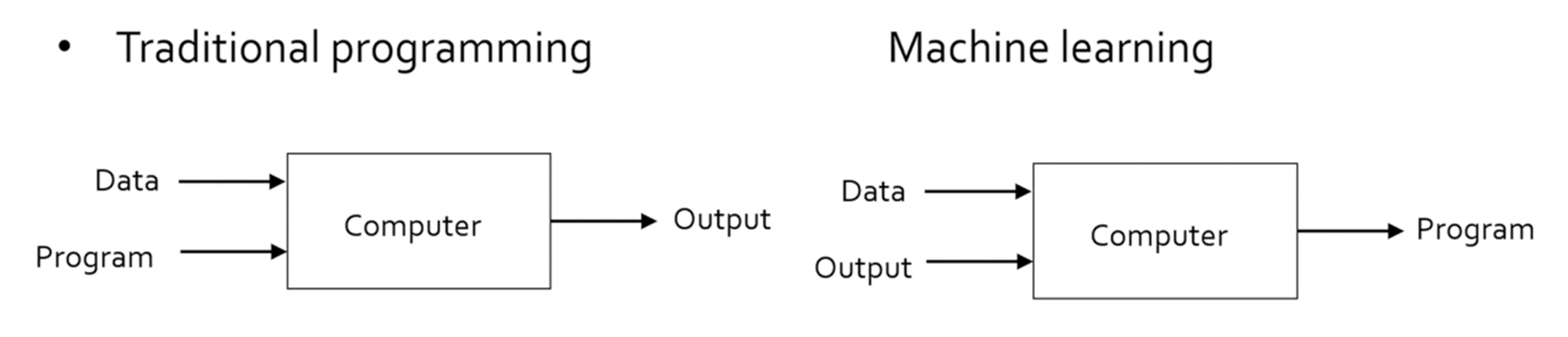
과거의 전통적인 방식으로 구현하게 되면 모든 경우와 룰, 예외 사항에 대해서 모두 하드 코드로 작성하게 되어 시간이 오래걸린다.
2. Generalization (일반화)
-
일반화는 기계학습의 최종적인 목표이다.
예제로 학습 데이터를 100개만 주어도 이 100개만 보고 어떤 특정 패턴을 배워서 이 100개에 없는 예제에 대해서도 작업을 잘 수행해야 한다.
유사성을 판단하여 하나의 전형이라는 것을 만들어내는 과정을 스스로 하는 것이다. 이러한 행동은 일종의 추상화 과정으로 공통적인 특징을 파악해서 일종의 일반화된 개념으로 추상화한다. -
학습 데이터에 대해서 잘 되는 것이 목표가 아니라, 학습 데이터로부터 어떤 패턴을 배워서 학습 데이터에서 보지 못한 새로운 데이터가 오더라도 잘하길 기대한다.
-
학습용으로 모아둔 학습 데이터를 완벽하게 이해한다면 학습 데이터가 어떻게 생겼는지 생성까지 가능해진다. 해당 알고리즘이 생성형 Generative 인공지능이다.
3. No Free Lunch Theorem for ML
매번 새로운 task 혹은 데이터를 모을 때마다 최적의 알고리즘을 찾는 과정을 수행해야 한다.
어떤 기계학습 알고리즘도 다른 기계학습 알고리즘보다 항상 좋다.
4. 기계학습의 종류
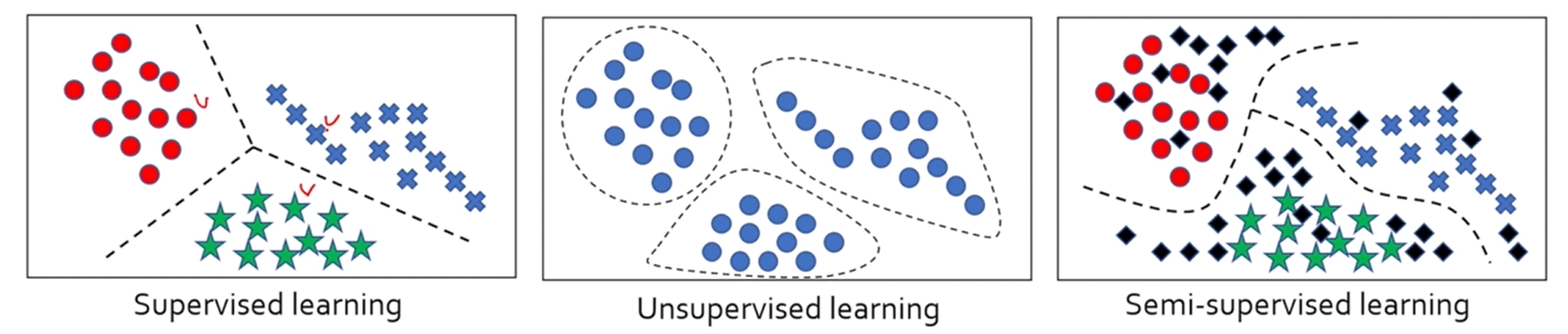
- 지도학습 : 기계학습 알고리즘에게 input, output를 쌍으로 만들어서 그런 학습 데이터로 함수를 학습한다. ex) 분류(범주형 분류), 회귀(실수로 예측)
- 비지도학습 : 학습 데이터가 x로만 구성되어 input만 알려준다. 큰 기대를 바라면 안됨, 일부 ex) 클러스터링(군집화)
- 세미 지도학습 : 지도학습과 비지도학습의 중간이다. 몇몇 데이터에는 y값을 사람이 부여하고, 없는 것은 그대로 둔다.
ex) LU learning(몇몇 데이터는 y부여하고 몇몇은 부여 안함), PU learning(정상과 비정상으로 나눌 때 정상의 경우 데이터만 부여함, 레이블이 없는 것은 확률로 주게 됨) - 강화학습 : 데이터셋이 아닌 환경이 주어지며, 환경의 상태인 State와 reward 보상을 통해서 agent가 action 행동을 수행 ex) 바둑 agent
(reward가 바로 주어지는 경우와 나중에 주어지는 경우로 후자의 경우 매우 어려움)
정리)
- 기계학습은 인공지능의 한 분야로 데이터로부터 점점 개선되도록 할 수 있는 알고리즘을 설계하는 것
- 일반화는 학습 데이터가 아닌 다른 데이터에 대해서도 분석한 패턴에 대해 잘 수행하도록 하는 것이며 기계학습의 궁극적인 목표
- 어떤 기계학습 알고리즘도 다른 어떤 알고리즘보다 항상 더 나은 것은 없다.
