Bias and Variance
기계학습의 오차를 구성하고 있는 bias와 variance 와 함께 기계학습의 목표인 일반화와 밀접한 관계를 가진 overfitting과 underfitting에 대해 알아보자. 선택 과정을 이해하기 위해서 bias, variance, overfitting, underfitting 사이의 trade-off 관계를 깊게 알아보자.
1. bias 와 variance
기계학습 알고리즘을 선택할 때 핵심이 되는 개념이다.
bias는 편향,
variance는 분산,
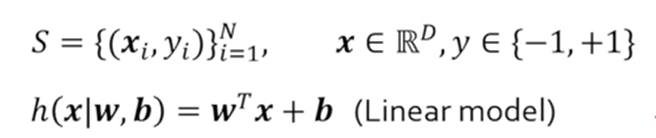
- 학습 데이터의 개수가 N개일 때, X는 input이고, Y는 기대하는 output으로 쌍을 N를 모은 것이 학습 데이터가 된다.
- input X는 multi dimension의 vector형태
- output Y는 예측해야 하는 값으로 -1와 1 (binary classification을 다루기 위해서)
- model class h를 정의한다.
- 학습 데이터를 가지고 parameter W, b를 결정하게 된다.
- 학습 데이터 S에 대해서 잘 동작하는 W와 b를 찾는 것이다.
여기서 과연 잘 동작하는 것은 무슨 의미인가? 이는 loss funcation으로 수치값으로 나타내게 된다.
- 손실함수 : 예측값과 정답값이 틀리면 틀릴수록 큰 값을 주는 함수
- 회귀의 경우, 예측값과 정답값의 차이가 클수록 2차의 함수로 패널티를 부여한다.
- 분류의 경우, 예측값과 정답값이 같으면 Loss가 0이고, 틀리면 Loss가 1이 된다.
- 최적화
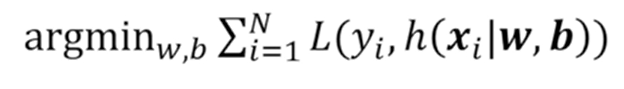
L이 정의한 손실함수가 되고, 하나의 학습 데이터에 대해서 모델의 함수값이 예측한 값이 h가 되고, 정답값이 y_i가 되며 사이의 Loss를 구하고
학습 데이터에 대한 전체 loss를 Minimize하는 W와 b를 찾는 과정이다.
2. Generalization
기계학습의 일반화는 기계학습 알고리즘이 학습한 데이터에 대해서 잘하는 것보다 학습과정에서 보지 못한 데이터에 대해서 잘하는 것의 성능이다.
학습과정동안 학습 데이터에 대해서는 최적화를 하는 와중에 new unseen data에 대해서 잘하는 것에 대해 같이 고려를 해야한다.
이로써 overfitting과 underfitting과 밀접하게 연관을 가진다.
3. Overfitting 과 Underfitting
알고리즘을 fitting할 때 사소한 up, down에 맞추게 된다면 기계학습 알고리즘의 함수적 표현이 복잡하게 fitting이 된다. 보지 못한 영역에 대해서 up, down이 심하게 반영을 하게 된다. 이는 정확도는 희생하면서 일반화 능력을 더 높이기 위함이다.
학습 에러가 큼에도 불구하고 이 함수를 사용하는 이유는 보지 못한 영역에 대해서 부드럽게 반영하는 과정을 고려하였기 때문이다.
학습 데이터와 테스트 데이터를 얻는 과정에 대해서 알아본다.
개와 고양이를 분류하는 task를 진행한다.
- universal set : 세상의 모든 개와 세상의 모든 고양이에 대한 이미지 (관측이 불가능하다. 현실적으로 불가능하고 가정한다.)
- training set : universal set에서 sampleing이 되어 개 이미지 1000장과 고양이 이미지 1000장
- test set : universal set에서 sampleing이 되었지만 training set과는 겹치지 않는다. (동일하게 관측이 불가능함 = 학습과정에서 관측이 불가능하다는 것)
4. Generalization Error

- true distribution 은 universal set의 분포를 표현한 것으로
모든 X와 모든 Y의 상관관계를 모든 경우에 대해서 표현한 것으로 관측이 불가능하다. - train data와 test data는 true distribution에서 샘플링된 데이터가 된다.
- iid는 training data와 test data를 얻는 과정이 서로 독립이 된다는 것을 가정한다. 샘플링하는 과정상에서 분포는 변하지 않는 가정한다.
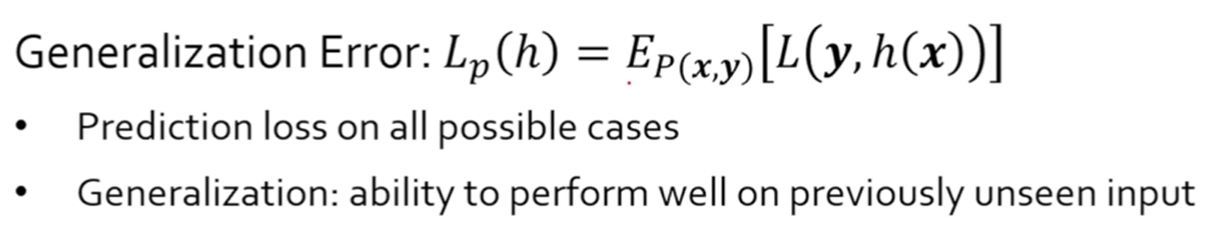
-
E는 expectation으로 하나의 분포를 가지는 값을 하나의 숫자로 요약한 것이다.
-
p(x, y)가 True distribution을 따른다고 하였을 때, 그때 구한 Loss의 평균값, 혹은 기대값이 된다.
-
과적합 : Generalization error < Training error
너무 과하게 학습 데이터에 적합이 된 경우이다. -
과소적합 : Generalization error > Training error
두 상황 중에서는 과소적합이 더 좋지 않은 경우이다. 학습 데이터는 input과 정답인 output이 모두 주어진 경우이기 때문에 과소적합이 발생하면 안된다. 모델의 선택의 문제가 있거나 학습이 잘 이루어지지 않은 것이다.
과적합이 발생한 경우는 학습 데이터에 대해서는 잘 학습을 한 경우이다.
- 일단 overfitting을 발생하게 만들어 training error를 최대한 줄일 수 있는 정도로 시도해본다.
- overfitting으로 training error와 validation error의 차이가 큰 경우에는 regularization을 통해서 training error을 조금은 손해를 보면서 validation error를 낮추어 두 차이를 줄이도록 한다.
5. overfitting과 model의 capacity와의 상관관계
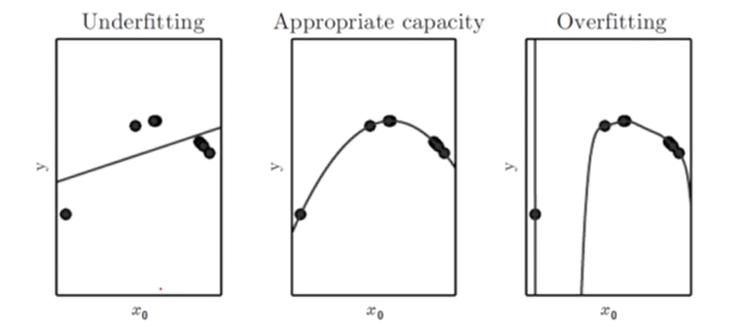
데이터를 fitting하기 위해서 함수를 선택한다.
- 첫번째의 경우 선형함수로 직선 밖에 표현이 불가능하여 굴곡을 반영하지 못해 underfitting이 발생하게 된다. 해당 모델이 다를 수 없는 용량
- 두번째의 경우 적절한 함수를 사용하여 잘 fitting된 모습이다.
- 세번째의 경우 복잡한 9차 함수를 사용하게 되면 training error를 줄일 수 있다.
모델의 capacity와 training error는 반비례 관계로 capacity가 올라갈수록 training error는 무조건 작아진다.
복잡한 모델을 사용하연 학습데이터에 대해서는 error을 최소화하여 반영할 수 있지만, 데이터가 없는 구간에 데이터가 있는 경우에 대해서 smooth하게 반영한다. 두 경우를 비교하였을 때 후자의 경우가 더 확률이 높기 때문에 두번째가 더 좋은 모델이 된다. 이를 설명하는 법칙에 대해서 알아보자
Occam's Razor(오컴의 면도날 법칙)
인색하게 쓰는 것에 대한 원칙으로 "현상을 설명할 수 있는 모델이 2~3개 있다고 가정할 때, 가장 간단한 설명이 맞을 확률이 높다" 는 것이다. 경험에 대한 것이고 정답에 관한 것은 아니다.
정답은 직접 확인을 해야 알 수 있지만, 복잡한 경우가 맞기 위해서는 확률적으로 낮기에 가장 간단한 경우가 맞을 것이라는 것이다.
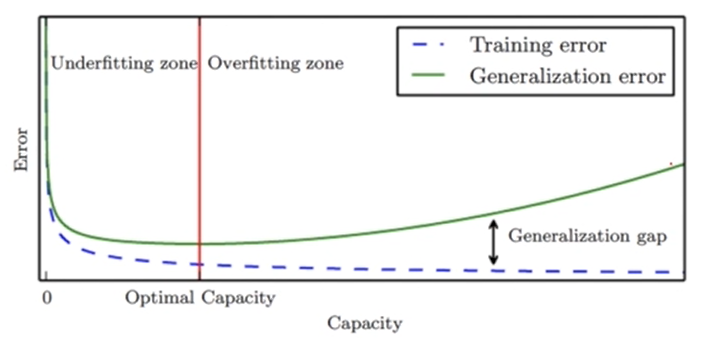
capacity와 training error의 관계를 표현한 그래프이다. 목표는 일반화 error를 최소화하는 것으로 녹색의 실선이 최적의 capacity를 지점을 찾아야 한다.
그래프의 빨간선을 기준으로 왼쪽은 underfitting의 영역이 되고, 오른쪽은 overfitting의 영역이 된다.
Generalization error은 training error와 달리 바로 구할 수 없고, 측정이 불가하며 validation을 통해서 예측할 수 밖에 없기 때문에 어렵다.
6. Regularization(정규화)
특정 solution에 대한 preference를 정규화라고 할 수 있다.
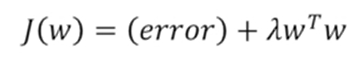
목적함수는 학습 데이터에 대해서 loss를 정의하고 loss가 minimized되도록 정의한다.
training loss가 최소화되는 방향의 W에 regularization term을 부여하여 과적합에 빠질 경우를 보완한다. 함수는 낮은 차수의 함수를 사용하는 것이 더 좋기 때문에 이를 더 선호한다.
모델의 capacity가 증가할수록 커지는 regularization term을 사용하여 모델의 loss를 최소화하는 것뿐만 아니라 모델의 capacity도 최소화하도록 정규화를 진행한다.
그냥 parameter는 학습을 통해서 배우는 변수들이 되고,
hyperparameter는 학습을 위해서 주어져야 하는 변수들이 된다.
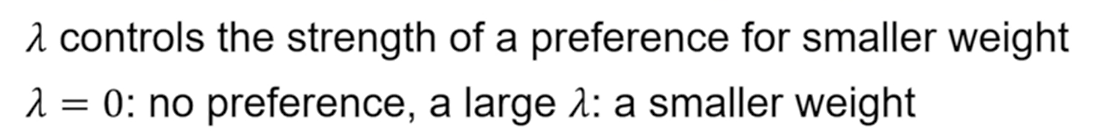
목적함수의 두가지 term에서 hyperparameter 람다를 적게주면, 첫번째 term만 고려하게 된다. 람다를 크게주게 되면 두번째 term를 고려하게 되는 것이다.
7. bias/variance decomposition
최적의 기계학습 모델을 찾는 과정에서 가장 중요한 개념이다.
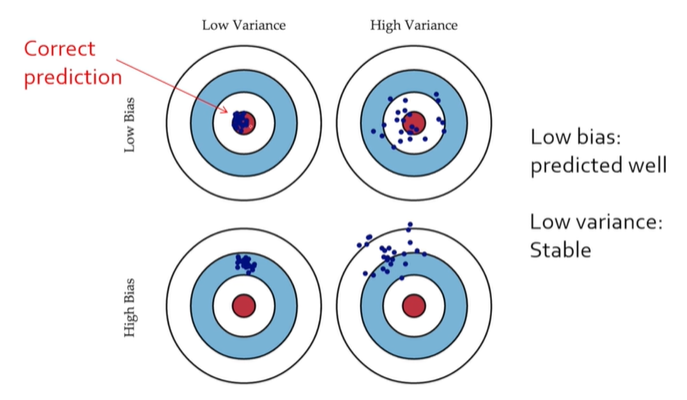
bias는 편향, variance는 분산이 된다.
영점도 잘 맞아서 10점에 쏠 수 있어야 하며, 널뛰지 않고 균일하게 쏴야한다.
- 1번째 과녁의 경우는 안정적이며, 영점도 잘 맞는 경우
- 2번째 과녁의 경우는 영점이 맞지만, 안정화가 덜되서 널뛰는 경우
- 3번째 과녁의 경우는 안정적으로 균일하지만, 영점이 맞지 않은 경우
- 4번째 과녁의 경우는 두 경우가 모두 맞지 않은 경우
bias와 variance가 모두 낮은 경우가 1번째 과녁으로 가장 잘 쏘는 경우가 된다.
구하는 방법
- bias는 예측한 것들에 대한 평균을 구하고, 예측의 평균값과 true값과의 차이로 구할 수 있다.
- variance는 true값을 알 필요없이, 예측한 것들에 대한 평균을 구하고, 예측의 평균값과의 거리의 제곱을 통해서 구할 수 있다. (X는 분포를 가지는 random variable)
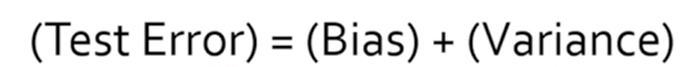
generalization error 혹은 test error를 낮추려면 bias와 variance가 모두 낮아야 한다.
기계학습에서는 bias와 variance가 trade-off가 존재하기 때문에 두 값을 모두 낮추기 위해서 많이 사용되는 방식은 Ensemble Learning이다.
정리)

다음 이미지를 통해서 bias와 variance, overfitting과 underfitting의 관계에 대해서 정리해보자.
-
overfitting은 과하게 적합이 되어, training data의 노이즈까지도 적합이 된다.
-
그럼으로 모델은 널뛰게 되며 unstable하여 variance값이 올라가게 된다. 모델의 capacity가 증가하면 증가할 수록 variance가 올라가게 된다.
-
variance를 잡기 위한 가장 좋은 방법은 training data의 수를 늘리는 것이다.
-
regularization을 사용하는 이유는 data가 충분하지 않아서 어떤 preference를 주기 위함이다.
-
bias가 높은 것은 영점이 맞지 않은 것으로 별로 정확하지 않는 모델로 underfitting과 관련이 있는 것을 의미한다.
-
모델의 복잡도가 낮다는 것이고 데이터가 필요로 하는 복잡도보다 부족한 것이다.
-
bias를 잡기 위해서는 모델의 complexicity를 올리는 것으로 해결할 수 있다.
-
모델의 complexicity를 올릴수록 bias는 낮아지지만,trade-off 관계로 인해 variance가 올라갈 확률이 높다.
-
bias는 데이터를 더 모은다고 해결되지 않는다. 이미 선형모델을 사용하고 있는 경우 데이터를 표현할 수 있는 능력이 부족한 것임으로 데이터로 해결할 수 없다.
