Supervised Learning overview
Supervised Learning의 공통적인 특징들에 대해서 알아보자.
1. 지도학습
지도학습은 컴퓨터에게 어떠한 문제를 풀도록 학습을 시킨다.
지도학습의 예제들에 대해서 알아본다.
- 이미지 분류 : 개인지 고양이인지
(x: 이미지, y: 1-10의 정수 집합) - 텍스트 분류 : 긍정인지 부정인지
(x: 영화 리뷰, y: 1(P)과 -1(N)) - 문장 생성 : 다음 단어 예측
(x: 문장 앞부분, y: 단어(정답 벡터)) - 문장 번역 : 한국어 문장 전체를 영어 문장으로 번역
(x: 문장(벡터 변환), y: 벡터 또는 벡터들의 수열) - 주식 가격 예측 : 열흘간의 가격 정보를 통해 다음날의 가격 예측
(x: 열흘간의 가격 정보 (10차원의 벡터), y: 정답 정보)

문제는 다차원의 벡터로 x가 되며, 정답의 경우 레이블 y가 된다.
지도학습의 중요한 가정은 다음과 같다.
입력과 정답의 쌍들이 데이터로 여러개 존재하는 상황을 가정하고 이 데이터를 사용하여 학습을 하게 된다.
2. 머신러닝과 지도학습
과거에는 전문가의 전문 지식에 의존하거나 수학적인 틀들로 설명하려고 하는 시도를 일련의 규칙을 설명하는 방식을 알고리즘으로 구현하려고 하였다. 예외적인 조항과 복잡하기 때문에 한계를 가지게 되어서 Supervised Learning은 머신러닝이라는 방식으로 접근한다.
머신러닝은 데이터를 다양하게 입력과 정답 쌍을 주고 스스로 알고리즘이 규칙을 파악해서 사람이 직접 규칙을 입력하는 것이 아니라 본인이 스스로 규칙을 판단하도록 도와주는 형태의 학습을 Supervised Learning이라 한다.
supervised learning은 두가지의 task로 나눌 수 있다.
- Classification 은 고를 수 있는 정답이 정해져있고 다음 정답이 무엇언지 보기에서 골라서 분류하는 것이다.
- Regression 는 정답이 숫자로 혹은 연속적인 실수 변수로 표현되는 경우 회귀라고 한다.
문장을 번역하고 다음 단어를 예측하는 경우는 일반적으로 분류로 한다. 정답이라고 부를 수 있는 것들이 한글 조합이 정해져 있기 때문이다.
3. Unsupervised Learning
문제만 있고 정답 쌍 없이 데이터만 주어진 경우를 말하며 학습에 대한 지도나 지시를 주지 않고 스스로 학습하도록 하는 것이다.
4. 지도학습의 수학적 정의
지도학습의 수학적 정의를 위해서 풀고자 하는 문제 task에 대해서 수학적으로 풀어보도록 한다.
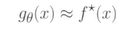
f* : 정답함수로 모든 이미지를 보고 정답을 분류할 수 있는 함수
g(x) : 구하는 모델을 f*에 가깝도록 만드는 것이 목표
g라는 클래스 안에 속하는 함수들 중에서 정답함수 f*에 가장 근사하는 함수를 찾는 문제로 치환된다.
가정을 통해서 지도학습의 과정을 이해해보독 한다. 해당 과정이 중요한 개념임으로 잘 이해하고 넘어가야 한다!
1. 세상에 존재하는 모든 함수가 아닌 어떤 함수 클래스를 정의해서 함수 클래스 중에서만 뽑는다.
2. 세상에 존재하는 모든 입력 중에서 함수값 두 개가 비슷하지 비교하는 것이 아닌 주어진 데이터(n개)만 가지고 값을 비교하겠다.
3. pointwise Loss 는 (x_i, y_i)라고 하는 하나의 데이터 포인트에 대해서 어떠한 손실이 발생하는지를 계산한 것이다. n개의 데이터에서 발생하는 pointwise Loss들의 평균을 낸 결과가 목표로 삼는 L이 된다.
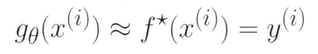
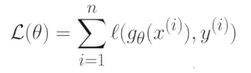
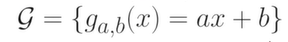
결론적으로 supervised learning은 L(세타)를 가장 minimized하는 g(세타)를 찾는 것이 된다.
5. Linear regression
선형 회귀는 수많은 데이터쌍이 선형적인 특징을 가지는 데이터셋이 된다. 키와 몸무게에 대해서 task를 가질 때, x는 키에 해당하며 어떠한 실수값이 되고 1차원 벡터가 아닌 스칼라가 된다. y는 맞추고자 하는 몸무게가 되고 실수가 된다.
- 키와 몸무게의 관계를 설명하는 함수를 세상에서 존재한느 모든 함수가 아니라 선형 함수 내에서 이 데이터를 가장 잘 표현하는 함수를 찾는 것이다.
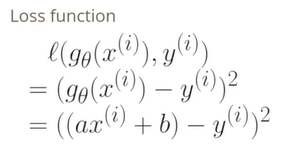
- 선형 함수의 계수인 (a, b)를 찾는 문제로 치환할 수 있다.
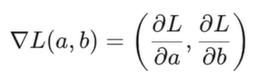
- Loss 함수는 g세타와 f*가 얼마나 비슷하지를 평가하는 방식을 정의한다. mean-squared error로 오차의 제곱을 계산하는 것이 pointwise Loss가 된다.
어떤 함수의 최솟값을 구할 때는 미분해서 0이 되는 지점을 찾듯이 변수가 2개인 경우도 a에 대해서 미분해서 0이 되는 지점과 b에 대해서 미분해서 0이 되는 지점을 찾아 각각 최소가 되는 지점을 찾으면 문제를 해결할 수 있다.
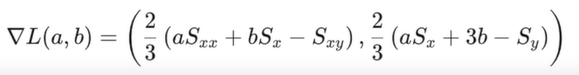
L의 gradient는 각각 a와 b를 비문한 것들을 모아놓은 벡터라고 생각하면 된다.
정리)
- 지도학습은 문제와 정답 쌍으로 구성된 데이터 셋이 주어져 있다.
- 모든 함수 중에서 정답 함수를 근사하는 가장 올바른 함수를 찾는 것이 아닌 g세타라고 하는 어떤 세타라는 파라미터들로 이루어진 함수 클래스를 정의해서 함수 클래스 중에서 반영한다.
- 어떤 g세타가 정답 함수를 잘 근사화하는지 평가하는 지표로 손실함수 L을 사용한다.
- 주어진 데이터셋에 대해서 loss를 계산한 손실의 총합 또는 평균을 L로 표현한다.
- L(세타)가 가장 작아지도록 하는 세타가 무엇인지 찾는 것이 최종적인 목표가 된다.
