Linear Regression
Supervised Learning에서 가장 기초적이면서도 중요한 Linear regression에 대해서 자세히 알아보고, 특히 입력이 여러 차원인 경우에 대해서 어떻게 다루고 과적합과 과소적합이 발생하였을 경우에 대해서 알아보자.
선형 회귀에서 Loss는 mean-squared error를 일반적으로 사용한다.
실제로 Supervised Learning 문제는 다차원 벡터의 경우가 많다. 다차원 입력일 때의 Linear regression을 다루어 본다. 먼저 1차원일 경우와 2차원일 경우의 차이점을 알아보고 넘어가자.
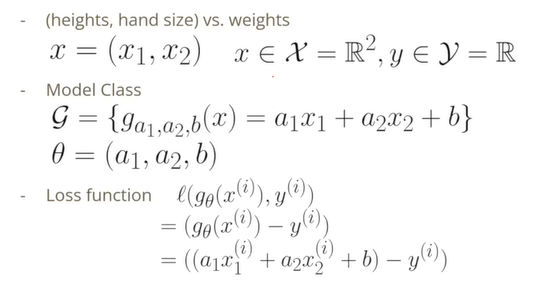
키의 x_1과 손의 크기 x_2 두 개의 입력을 가지고 몸무게를 맞추는 함수 클래스를 정의하여 정의한 함수와 정답 y_i와 얼마나 비슷한가를 판단하는 척도로 오차의 제곱을 사용한다.

모델에 대한 추정값과 정답 y_i에 대한 차이의 제곱을 n개에 대해서 총합 또는 평균을 구한다.
1차원 입력에 대응되는 선형 회귀보다 복잡한 식이 되었지만, 아무리 많은 데이터 포인터가 있더라도 a_1, a_2, b에 대한 이차식을 구할 수 있으며 L(a_1, a_2, b)에 대해서 Gradient를 구한다.
Gradient는 어느 방향으로 가장 빠르게 증가하는 가를 나타내는 지표이다.
결론적으로는 문제의 난이도는 올라간 것이 아니다. 각각 a_1, a_2, b에 대해서 미분하였을 경우 모두 일차식만 남게 되어 변수가 3개인 일차식이 3개가 되어 연립 방정식으로 간단하게 해결할 수 있다.
1. Linear Regression Multidimension
다음은 D차원에서의 선형 회귀를 보도록 한다.
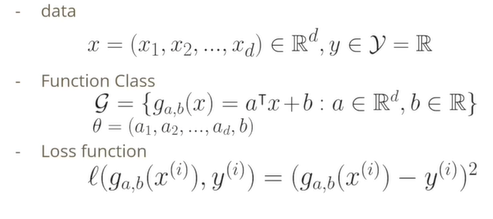
- 32x32x3형태의 이미지로 입력이 D차원인 벡터가 되고, 대응되는 y는 실수값으로 예측하는 문제가 된다.
- Linear Regression는 입력을 어떤 선형 함수로 표현하였을 때 가장 y에 근접한가를 본다.
- mean-squared error를 일반적으로 사용하는 이유는 분석이 용이하고 미분이 가능하여 통계적으로 의미를 가지기 때문이다.
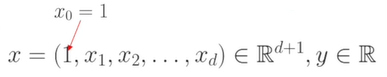
찾고자 하는 파라미터셋은 세타 = (a_1, ... a_d, b)가 된다. a벡터와 상수 b를 하나로 융합하여 하나의 변수 벡터를 만들어낸다. 가상의 x_0를 두고 이를 1로 값을 주어 b역할을 한다.
a가 d차원, b가 단순한 스칼라였지만, a가 d+1차원으로 하나의 벡터로 수식을 표현할 수 있다. 지금까지는 (a,b)를 모든 파라미터로 묶어서 세타라는 이름으로 불렀지만, 이제는 a자체가 파라미터 세타러 구분없이 사용할 수 있다.
Normal Equation
변수가 d+1개이고, d+1개에 대해서 모두 미분하면 d+1개의 변수와 d+1개의 식으로 이루어진 문제를 해결하면 된다. Gradient를 한번에 고려해서 간단하게 구해볼 수 있다.
x로 이루어진 행렬과 y로 이루어진 벡터로 x와 a, y를 잘 정의하면, 가 부터 까지 존재하는 것이 되고, 가 부터 까지 존재하기 때문에 두 개를 뺀 벡터의 크기를 손실값으로 할 수 있다.
시그마로 모두 더했던 과정을 의 벡터의 크기라고 하는 식으로 표현할 수 있다. 이를 최소화하는 과정은 벡터 a에 대한 미분으로 통해 해결할 수 있다. a에 대한 미분=a에 대한 gradient값이 0인 지점이 되는 곳이 Loss가 최소화되는 지점이 된다.
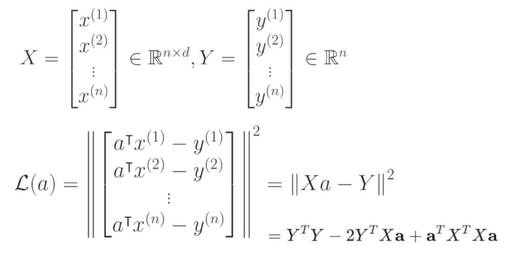
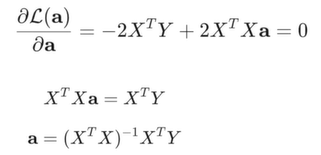
2. 고차식 함수를 사용한다면?
데이터를 선형적으로 맞추는 것에 초점을 맞추었지만 실제 현실은 그렇지 않은 경우가 더 많기 때문에 이상치 같은 데이터가 많을 수 밖에 없다. 데이터를 이차함수로 표현하는 경우에 대해서 알아본다.
이차함수를 사용하는 선형회귀가 되는 이유는 무엇일까?
x와 y를 푸는 것이 아니라 이는 주어진 것으로 z를 가지고 y를 표현할 때 x에 붙는 계수를 맞추는 것이 됨으로 계수에 대한 일차식 선형함수는 여전하기 때문에 동일하게 선형회귀를 사용하여 해결한다.
더 좋은 적합도를 찾게 되면서 이차함수가 아니라 삼차함수와 같이 feature나 kernel를 추가하여 더 복잡한 함수로 데이터를 완벽하게 할 수 있지만 필연적으로 overfitting이 발생하게 된다.
3. Overfitting
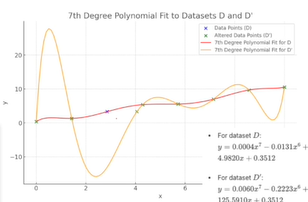
하나의 데이터가 변동에도 모델의 형태가 드라마틱하게 변할 수 있다. 노란색 모델의 형태에서 빨간색 모델의 형태로 변하게 된다. 주어진 데이터를 설명하기엔 지나치게 피팅되어 고차식이 등장하게 된다.
overfitting을 해결하기 위해서는 데이터의 양을 늘리는 방법으로 해결할 수 있다.
적절한 개수의 데이터에 대해서 얼마나 복잡한 모델을 사용하는 게 좋을지 확인하는 3카테고리로 분류해 알아보자.
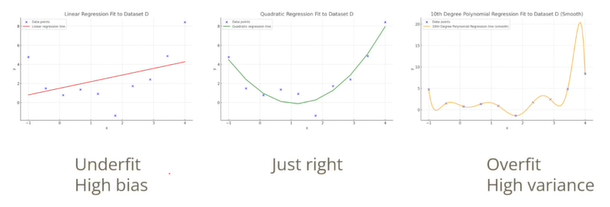
- 왼쪽의 경우 loss가 크게 발생한다. 모델의 한계가 존재해서 발생하는 경우를 underfit으로 bias가 존재한다.
- 중앙의 경우 추세를 적절하게 반영하는 것을 알 수 있다.
- 오른쪽의 경우 오버해서 데이터에 피팅되는 경우로 overfit으로 데이터 하나가 조금만 바뀌어도 모델이 드라마틱하게 변하는 변동성을 가지고 있으며 고분산(high variance)이라 한다.
적절한 점을 찾기 위해선 어떻게 해야하는가?
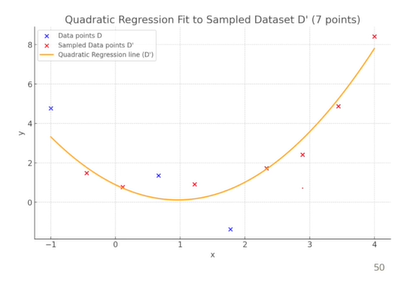
학습 데이터를 학습데이터와 검증데이터로 나누어서 해결할 수 있다. 실제 데이터는 고차원의 데이터이기 때문에 데이터를 그래프로 시각화하기 어렵다. 학습 데이터 10개의 경우, 데이터를 선형 회귀에 적용할 때는 7개의 데이터만을 사용하여 계산하는 손실(train loss)과 학습에 사용하지 않았던 데이터들의 손실(validation loss)이 비슷하다면 적어도 overfitting이 발생하지 않았다고 할 수 있다.
학습 순서를 정리해보자
1. 데이터를 학습 데이터와 검증 데이터로 나눈다.
2. 학습하면서 학습 데이터가 적어도 유의미하게 작아지는지 확인한다. 유의미하지 않으면 모델이 충분히 표현하지 않아서 발생한 underfitting
3. 학습 손실이 꽤 작아지는 지점을 찾았을 때, overfitting이 발생하는지 확인한다.
4. train loss와 validation loss의 차이가 크지 않은지 확인한다. 크지 않은 경우 overfitting없이 적절하게 학습이 된 경우이다.
4. Train-Validation-Test
학습 셋은 푸는 연습 문제, 검증 셋은 일종의 모의고사가 된다. 연습 문제를 모의고사 점수가 높아질 때까지 학습한다. 테스트 셋은 최종적인 수능으로 쉽게 이해할 수 있다.
Occam's Razer
확실히 일차식은 underfitting이고, 사차식은 overfitting일 때, 이차식과 삼차식 중에 어떤 것을 선택하는 게 옳은 것인가? 에 대한 질문에 대해서 Occam's Razer를 통해 알아보자.
Occam's Razer는 어떠한 현상을 설명하는 가능한 가장 간단한 룰을 따르자 는 원리이다.
- 이차식과 삼차식이 모두 유의미한다고 하면 간단한 모델을 사용하는 것이 안전하다.
- 낮은 학습 오차를 유지하면서 학습 오차와 검증 오차가 비슷해지는 모델을 찾는다.
- 학습 오차가 낮은 데 검증 오차가 크다면 overfitting이 발생한 경우이다.
- overfitting이 발생한 경우 모델의 복잡도를 낮춘다.
- overfitting이 발생한 경우 데이터를 추가한다.

5. 주요 테크닉
Cross Validation
데이터가 부족한 경우에 이를 해결하기 위한 테크닉은 Cross Validation이 있다.
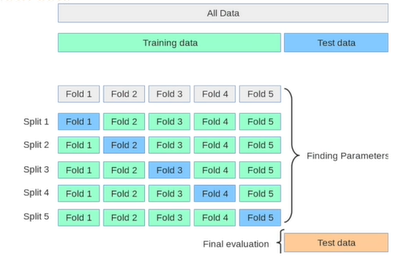
학습과 검증을 번갈아가면서 사용하게 되면 결론적으로 데이터를 100% 전부 사용하게 된다.
Regularization
overfitting을 방지하기 위한 테크닉 중 하나는 정규화이다.

줄이고자 하는 mean-squrad error loss, 실제로 기존의 풀고 싶었던 문제는 손실값을 최소화하는 것이다. overfitting은 이 loss를 줄이는 것에 매몰되어 있는 문제로 인해 발생하는 현상으로 이를 해곃하기 위해 무게추를 달아주는 역할이 정규화가 된다.
독특한 값을 가져 모델이 복잡해지지 못하도록 하는 손실을 줄이면서도 ||a||의 크기느 적당하게 유지해야 한다는 제약이 정규화가 된다. 람다라는 파라미터가 크게 된다면 손실을 줄이는 것보다 a가 커지는 것을 더 경계하는 형태가 된다. 정규화를 크게 한다는 의미가 된다.
Augmentation 증강
복잡한 모델을 사용하지 않고도 데이터를 추가적으로 늘릴 수 있다.

증강을 통해서 데이터 증강을 할 수 있는 이유는 일반적으로 다루는 이미지들이 어떤 특정한 변화에 대해 불변성을 가진다는 성질 때문이다. 이미지를 줄이거나 돌려서 봐도 이미지의 본질적인 특성이 변화하지 않는다는 것이다. 확대, 이동, 뒤집기, 회전, 노이즈추가, 색상 변화, 밝기 변화 등과 같은 다양한 방법을 사용할 수 있다.
데이터마다 특성을 각각 가지기 때문에 증강을 막무가내로 사용하면 안된다.
정리)
- Normal Equation은 d+1번 여러번 계산해야 될 문제를 의 벡터의 크기라고 하는 식으로 표현하여 깔끔하게 표현할 수 있다.
- 모델이 고차식이 되더라도 선형 회귀로 해결할 수 있다.
- overfitting과 underfitting의 trade-off관계를 이해하면서 모델의 복잡한 정도를 고려해야 한다.
- 학습과 검증 데이터로 overfitting을 확인할 수 있다.
