Training Neural Networks
deep learning을 학습하기 위한 기법들에 대해서 알아보도록 하자. gradient descent의 기본 개념과 deep learning이 하나의 합성함수로 보았을 때 각각의 편미분 방법을 구할 수 있는 방법인 back propagation에 대해서 이해해보자. 다양한 활성함수를 사용하였을 때 나타나는 gradient vanishing 문제를 알아보고 이를 해결하기 위한 방법인 batch normalization을 알아보자.
심층신경망의 학습 과정
Neural Network의 기본적인 학습과정은 gradient descent 알고리즘을 사용한다.
Gradient Descent
최적화하고자 하는 파라미터들 W 과 학습 data를 해당 파라미터들 W 로 이루어진 neural networt에 입력으로 집어넣어서 ground truth 값과 비교함으로써 차이를 최소화하도록 하는 loss function L(W)를 만들었을 때 이를 최소화하는 파라미터들 W을 찾는 것이다.
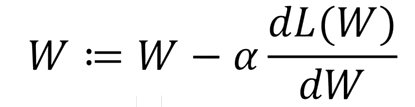
loss function L(W)에 대해서 각각의 파라미터들 W에 미분값을 구해서 현재 주어진 파라미터 값을 가지고 미분방향의 -방향으로 특정 step size 혹은 learning rate를 곱해서 해당 파라미터들을 업데이트하는 방식으로 학습을 진행한다.
random initialization에서 시작해서 함수의 높이가 점점 낮아지는 방향으로 해당 파라미터 값들이 점점 update가 일어난다.
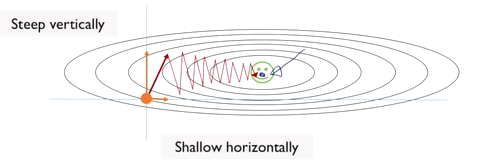
original gradient descent 를 사용하면 loss function이 복잡한 형태를 띄고 있을 때, 수렴하는 속도가 상대적으로 느리게 된다. 등고선에서의 접선의 기울기가 gradient가 되고 필요보다 더 많은 수의 반복 과정을 통해서 loss function의 극소수점에 도달한다.
MNIST handwritten digit classification 에서 MSE loss를 적용한 경우를 생각해보자.
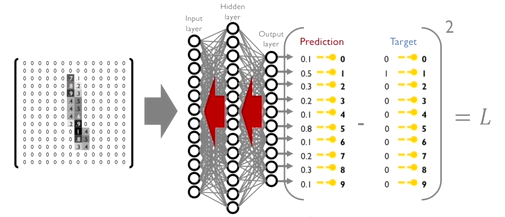
학습을 통해 최적화를 이루어내야 하는 대상 변수들은 각 layer들에 존재하는 파라미터들이다. 학습 data에 대해서 먼저 forward propagation을 진행하면서 각각의 파라미터들은 random initialization에서부터 시작한다. 나오는 예측값들을 입력 data의 ground truth값과 상이하고 차이를 계산해서 최소화하는 방향으로 loss를 정의한다.
neural network에 존재하는 각 parameter들에 대한 최종 loss function의 편미분 값을 사용하는 과정이다.

최적화를 해야 되는 W들에 있는 각각의 파리미터들로 손실함수들에 대한 편미분 값을 구하고 이를 통해 해당 파라미터들을 업데이트한다. 해당 과정은 forward propagation의 반대 방향으로 layer 별로 순차적인 계산을 수행하게 되는 back propagation 과정으로 와 의 각각의 gradient값인 loss function의 편미분 값을 계산할 수 있다.

각각의 파라미터들을 최종 output값에서 부터 입력 layer까지 쭉 진행하면서 얻어진 back propagation을 통해 편미분 값을 얻게 되면 gradient descent 알고리즘의 수식으로 파라미터들의 업데이트가 반복적으로 수행된다.
back propagation
neural network에 존재하는 각 parameter들에 대한 최종 loss function의 편미분 값을 어떻게 구하는 가에 대해서 알아보자.
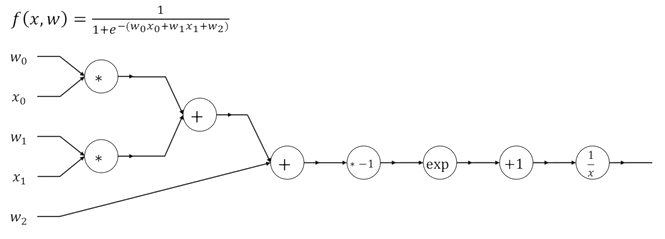
logistic regression의 경우 하나의 뉴런에 포함된 가중치는 이고, 입력 vector는 으로 구성되어 에 곱해지는 상수값 1로 선형 결합의 출력이 된다. 이를 sigmiod function을 통과하여 logistic regression의 연산과정을 알 수 있다.
해당 예측값과 grounf truth값과 비교하는 binary cross entropy loss를 통해 logistic regression를 학습한다.
3.1 예시1
예시로 예측한 값을 그대로 loss function이라고 생각하고 이를 minimize하도록 하는 그때의 가중치 를 찾는 gradient descent 과정을 수행한다고 가정한다.
파라미터들에 대한 loss function의 편미분 값을 구하는 과정이 back propagation을 통해 진행된다. back propagation은 기본적으로 합성함수의 미분 개념을 통해 이루어진다.
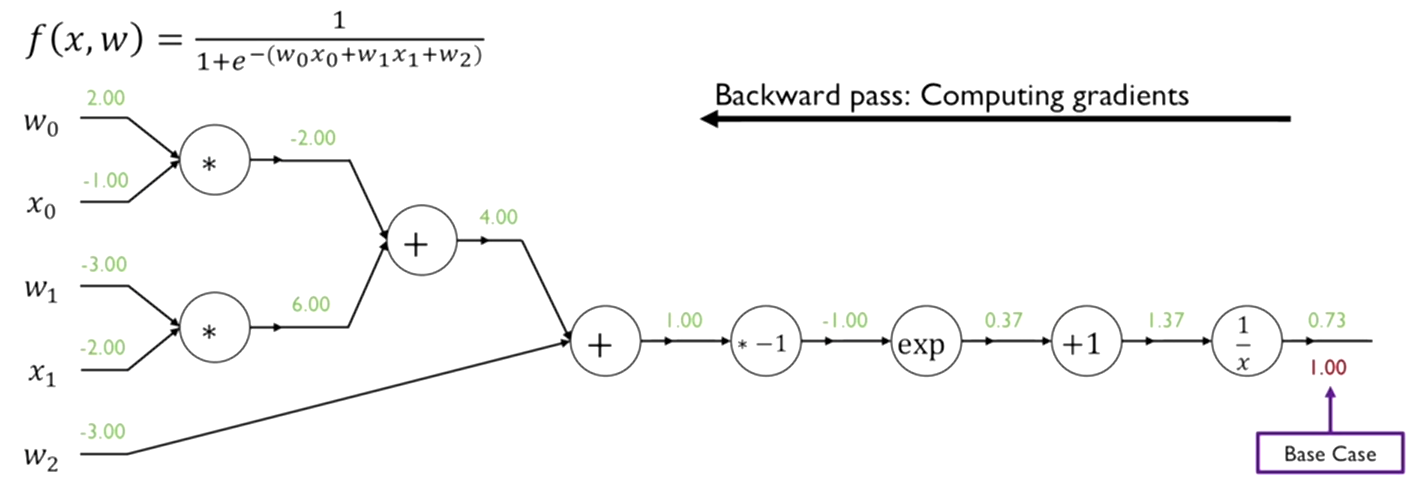
최소화하고자 하는 최종함수에 해당하는 하는 L이자 마지막 노드에 해당하는 편미분 값을 1로 정한다. 1은 함수값 자체를 미분했을 때의 결과로써 항상 1이 된다. 0.73이 L이 되고 이를 미분한다.
Step 1
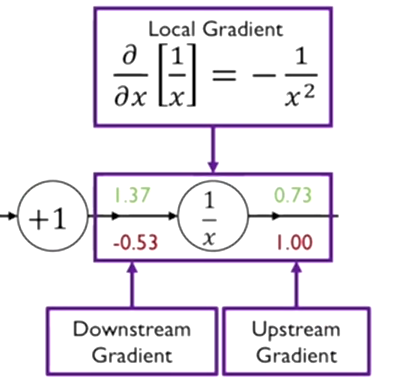
1. 함수에 대한 gradient값을 계산한다. 해당 함수 y를 x에 대해서 미분했을 때 가 된다. forward propagation에서의 입력값인 1.37을 입력으로 미분한 함수 x에 대입하면 얻어지는 값이 -0.53이 된다.
- 함수의 output에 해당 편미분 값에 같이 곱해준다. 최초의 값은 1에서 시작함으로 1에 -0.53를 곱해서 gradient를 구한다.
해당하는 값 1.37을 x라고 하면, -0.53은 dL을 dx로 편미분한 값이 된다.
Step 2
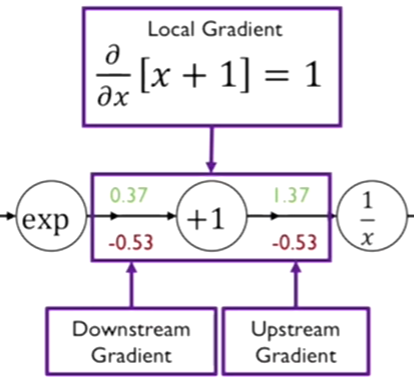
두번째 노드는 주어진 입력값을 x라고 할 때 x+1에 해당하는 함수이다.
-
함수를 x에 대해서 편미분 한다. x에 대한 편미분 값은 1이 된다.
-
해당 노드의 output에 해당하는 gradient 값에 미분한 값을 곱해준다. 이전 step에서의 값인 -0.53에 1을 곱해준다.
Step 3
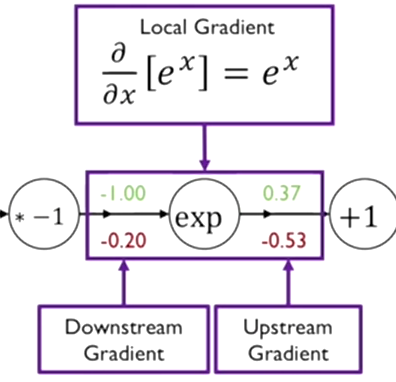
-
함수를 x에 대해서 편미분 한다. exponential 함수는 미분한 값이 그대로 나온다. 함수의 입력값 x는 -1이고 미분한 값에 넣어 해당 함수의 편미분값 를 구한다.
-
해당 함수의 output 값 -0.53에 함수의 편미분값을 곱해서 입력값에 대한 gradient -0.2를 구한다.
Step 4
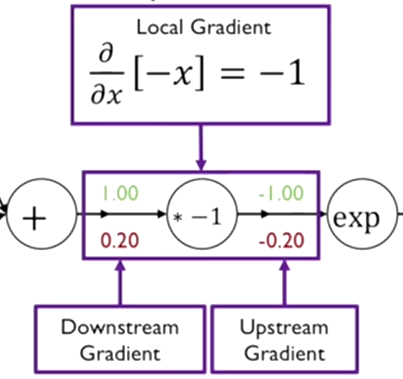
1. 함수를 x에 대해서 편미분 한다. 함수는 미분한 값은 -1이 된다.
- 해당 함수의 output 값 -0.2에 함수의 편미분값 -1을 곱해서 입력값에 대한 gradient 0.2를 구한다.
Step 5
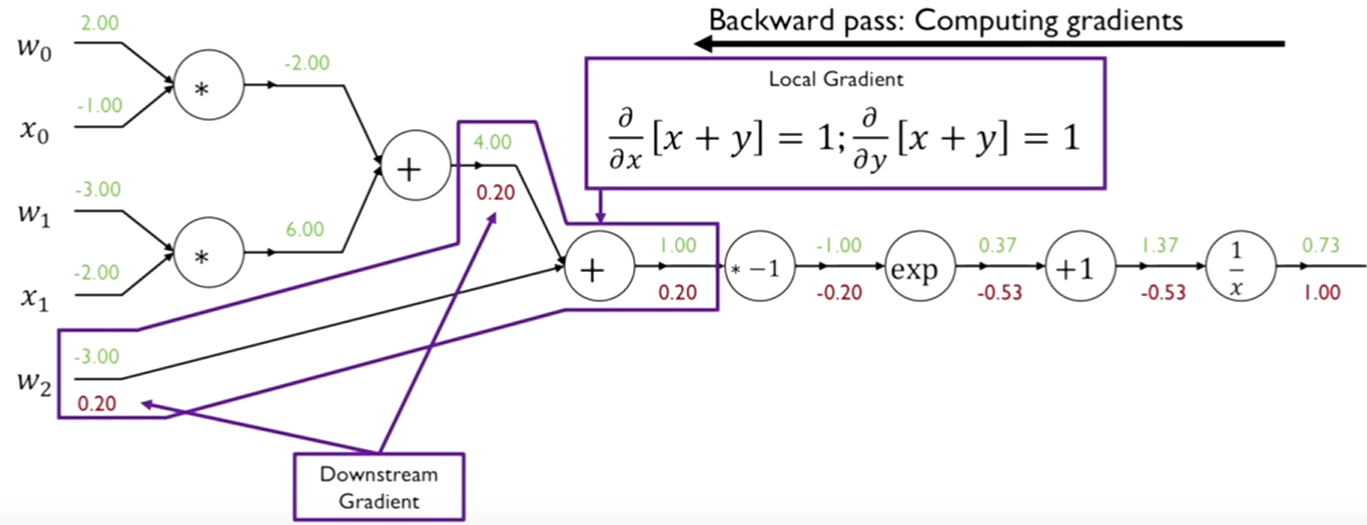
1. 함수를 편미분한다.
x와 y라는 2개의 입력변수를 받아서 둘을 더하는 함수이다. 입력이 두개의 branch를 가지며 x와 y에 대한 각각의 편미분을 구해야 한다.
x에 대한 편미분값은 1이 되고, 마찬가지로 y에 대한 편미분값도 1이 된다.
- x의 경우에는 해당 함수의 output 값 0.2에 함수의 편미분값 1을 곱해서 입력값에 대한 gradient 0.2를 구한다. y의 경우도 해당 함수의 output 값 0.2에 함수의 편미분값 1을 곱해서 입력값에 대한 gradient 0.2를 구한다.
Step 6
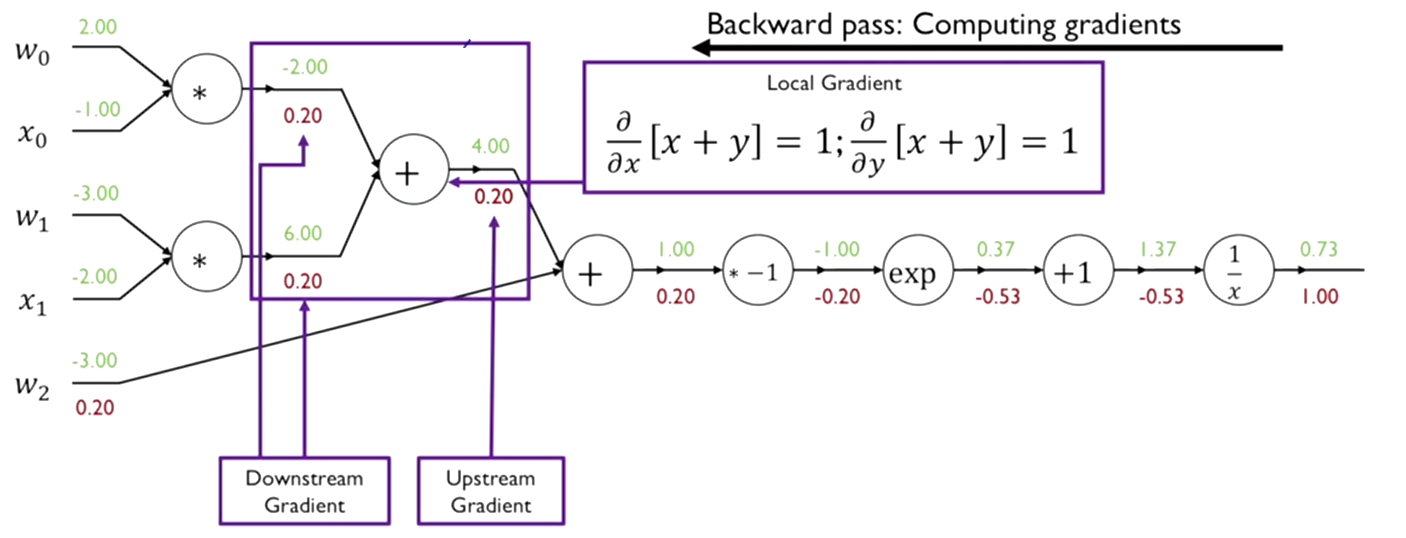
1. 함수를 편미분한다.
이전 노드와 돌일하게 x와 y라는 2개의 입력변수를 받아서 둘을 더하는 함수이다. 입력이 두개의 branch를 가지며 x와 y에 대한 각각의 편미분을 구해야 한다.
x에 대한 편미분값은 1이 되고, 마찬가지로 y에 대한 편미분값도 1이 된다.
- x와 y의 경우 모두 해당 함수의 output 값 0.2에 함수의 편미분값 1을 곱해서 입력값에 대한 gradient 0.2를 구한다.
Step 7
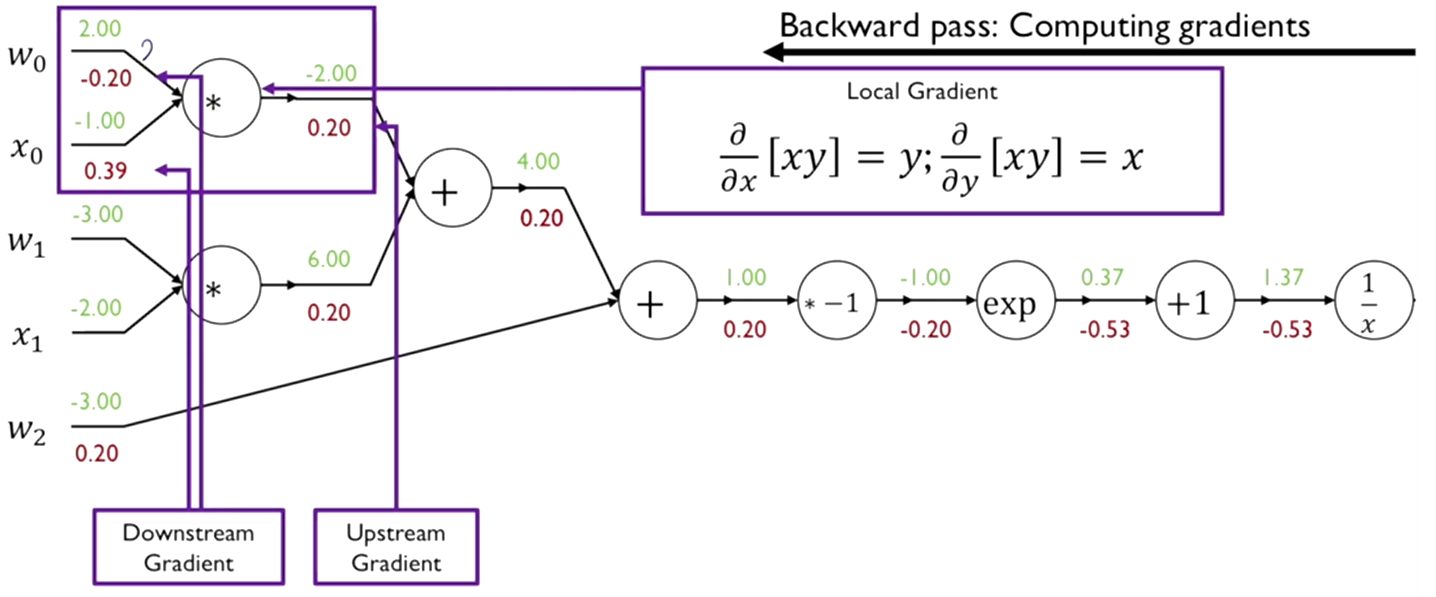
-
함수를 편미분한다.
x와 y라는 2개의 입력변수를 받아서 둘을 곱하는 함수이다. 입력이 두개의 branch를 가지며 x와 y에 대한 각각의 편미분을 구해야 한다.
x에 대한 편미분값은 y으로 -1이 되고, 마찬가지로 y에 대한 편미분값으로 x가 되어 2가 된다. -
해당 함수의 output 값 0.2에 x에 대한 편미분값 -1을 곱해서 -0.2를 얻게 되고, y에 대한 편미분값 2를 곱해서 0.39를 얻을 수 있다.
최초의 입력 노드들과 중간 노드들 모두의 편미분 값을 계산할 수 있다. gradient descent로 업데이트 해야하는 파라미터 값들은 이 된다.
초기의 2에서 특정한 learning rate 0.1을 곱하고 gradient 편미분 값 -0.2 을 곱한값을 빼서 를 업데이트하게 된다.
중간의 값들을 모두 구하긴 했지만 gradient descent로 업데이트 해야하는 파라미터 값들에 해당하지 않기에 넘어간다.
3.2 예시2
사진)
풀어서 계산한 Sigmiod 함수 과정을 하나의 노드로 보고 gradient를 계산해서 한번에 back propagation을 수행한다.
사진)
Sigmiod함수를 x에 대한 미분으로 x에 대한 수식뿐만 아니라 sigmiod 함수의 출력값인 y에대한 수식으로도 나타낼 수 있다. 노드의 입력값은 1이고 sigmoid 함수를 통과한 값은 0.73이고 해당 output 노드의 gradient는 1이라면, sigmiod 함수의 출력값인 0.73을 에 넣어서 으로 계산할수 있다.
간단한 logistic regression에서 나아가서 multi-layer precptron과 convolution neural network, recurrent neural network, transformer 등에 대해서 이해할 수 있다.
딥러닝의 학습과정을 정리해보자.
주어지는 데이터 입력으로 forward propagation이 계산과정을 수행하고 최종적으로 loss를 계산하고 이를 최소화하는 과정을 back propagation과정을 통해서 직접적으로 업데이트할 파라미터들에 대한 loss function의 gradient값을 구하고 파라미터들을 gradient descent 알고리즘을 통해 업데이트한다.
sigmoid activation function
사진)
하나의 뉴런이 입력 신호를 선형 결합에서 만들어진 값에 hard threshold를 적용해서 최종 출력값을 내어줬던 것을 부드러운 형태의 함수로 근사화한 것이다.
Sigmoid의 특성은 주어진 선형 결합의 결과가 -무한대에서 +무한대까지 가지는 값들을 0-1 사이의 값으로 매핑한다. Logistic regression의 경우 positive class에 대응하는 예측된 확률값으로 해석한다.
사진)
Sigmoid 함수에서 gradient값을 유도했을 때 가 되고, 값이 0에서 1사이 값이 되면 해당 이차식은 최대값이 이고 0을 최소값으로 가지는 범위를 가지게 된다.
사진)
Sigmoid 함수를back propagation 할 때마다 output 값에서 계산되었던 gradient 값인 에 최소 0에서부터 최대 1/4까지의 값을 곱해줌으로써 입력값의 gradient가 결정된다.
곱해진 값은 1보다 많이 작은 값이기 때문에 sigmoid 노드를 back propagation 할 때마다 gradient 값이 점차 작아지게 된다.
Gradient vanishing
여러 layer에 걸치면서 sigmoid function의 back propagation을 수행할 때마다 gradient 값이 계속 깍여나가 점차 0이 되는 문제이다. 앞쪽에 있는 파라미터들에 도달하는 gradient값이 작아져서 파라미터들이 업데이트가 거의 일어나지 않아서 전체적으로 학습이 느려지게 된다.
활성화 함수
해결하기 위해서는 sigmoid activation function이 아닌 다른 활성화 함수를 사용하는 방법이다.
Tanh activation function
사진)
Tanh 함수는 sigmoid 함수에 2를 곱하고 -1를 한 함수로, 선형결합을 입력으로 넣었을 때 -무한대에서 +무한대의 값이 아닌 -1부터 1 사이의 범위로 매핑한다.
평균값이 0을 중심으로 나오는 값이 되고 이는 학습을 좀 더 빠르게 해주는 효과가 있다.
Tanh함수도 미분한 gradient값이 최소 0에서 최대 1/2 까지 범위가 된다. Tanh함수 노드를 back propagation 할 때마다 gradient 값이 1/2 혹은 그 이하로 깍여나가게 되는 문제점이 있다.
ReLU activation function
layer를 층층이 많이 쌓았을 때에 gradient vanishing 문제를 해결하기 위해 많이 사용되는 함수는Rectified Linear Unit 함수이다.
사진)
한 뉴런에서 선형결합을 통해 나온 값이 -무한대에서 +무한대까지의 다양한 값을 가질 때, 0보다 작은 경우는 0으로 두고 0보다 큰 값은 그 값 그대로 내어준다.
기존의 sigmoid 와 tanh 는 입력값이 커지면 커질수록 함수가 거의 상수값 1에 가까워져 gradient값이 0에 되는 문제를 ReLU함수에서는 해결하게 된다. ReLU 함수는 sigmoid에 비해 복잡한 연산에 대해서 빠르게 계산할 수 있다.
ReLU함수는 주어진 값이 음수가 될 경우에 해당 gradient는 0이 되어버리게 된다. Output 노드에어떤 gradient값이 주어져도 0을 곱해버리면서 결국 0이 된다. 하지만 양수의 경우는 gradient vanishing 문제없이 gradient가 유지된다는 장점으로 layer가 많을 때 좋다.
학습 데이터 : ring type
입력 노드 : 2차원으로 이루어진 vector
히든 레이어 : 2개
배경색과 학습 데이터의 위치가 일치할 때 학습이 잘 된 경우이다.
batch normalizaition
특정 활성화 함수를 사용하였을 때 학습을 용이하게 하는 특별한 형태의 뉴런 혹은 layer가 batch normalization이 된다.
Step 1
사진)
Sigmoid를 예를 들었을 떄 gradient 값이 0에 가깝지 않고 어느 정도 양수로 큰 gradient를 가지는 범위를 벗어나게 되면 gradient값이 거의 0이 되면서 vanishing 문제가 발생하게 된다.
Tanh도 음수값인 경우는 gradient가 완전히 0이 되어서 back propagation 과정에서 학습이 이루어지지 않는다.
Batch noramlization은 foward propagation 할 때 활성함수들의 입력으로 주어지는 값들의 대략적인 범위를 0 근처의 범위로 제한하게 되면 gradient vanishing이 발생하지 않을 수 있다.
사진)
하나의 Mini batch가 주어지고 하나 당 데이터가 100일 때, tanh 활성화 함수를 통과하기 직전에 입력으로 발생되는 값 10개를 평균과 분산을 계산해서 평균이 0, 분산이 1이 되도록 하는 정규화 과정을 거치면 0을 중심으로 하는 제한할 수 있다.
분산을 제한을 두는 이유는 값들의 변화 폭이 너무 작으면 tanh 의 output값들의 변화도 작아지기 때문에 데이터들 간의 차이를 구분하기 어렵다.
특정한 layer와 특정한 노드에서 발견되는 하나의 mini batch 내의 10개의 data item들의 값들을 평균이 0이고 분산이 1이 되는 분포를 만들어주게 된다.
결론적으로 baatch normalization 은 fully connected layer 혹은 선형 결합을 수행한 이후에 활성화 함수를 통과하기 직전에 추가하는 것이 일반적이다.
Step 2
하지만 출력값들이 고유한 평균과 분산을 가지고 이에 학습해야하는 중요한 정보를 담고 있게 되면 batch normalization을 하는 것이 잘 추출한 정보를 잃어버리게 하는 과정이 되어버린다.
평균을 무조건 0 분산을 1로 만드는 과정에서 잃어버린 정보를 스스로 원하는 정보로 복원하는 방법이 있다.
사진)
평균0 분산1을 만든 값에 gradient descent로 최적화하게 되는 파라미터들을 도입해서 라는 변환을 수행해서 추가적인 작업을 batch normalization에 추가하게 된다.
가 평균이 0 분산이 1이 되고, 확률 변수를 곱하기로 a값인 곱하고 b값인 를 더하게 되면 10개의 값의 평균 값은 b가 되고 분산은 이 된다. 이를 통해 딥러닝이 원하는 최적의 평균 분산 값을 스스로 결정할 수 있게 되며, 스스로 결정하는 부분은 설정한 loss function을 최적화 하는 방향의 파라미터 값으로 부터 도출된다.
Batch normalization의 첫번째 스텝을 통해서 평균을 0 분산을 1로 만든 이후 두번째 스텝을 통해 해당 데이터가 가지는 고유의 평균과 분산을 복원해낼 수 있다.
수도코드 사진)
감마와 베타는 1과 0이 되도록 해서 tanh 의 gradient 를 살려준다.
정리)
- gradient descent에 기반해서 back propagation 과정으로 loss function의 gradient값을 구해서 파라미터들을 업데이트해 학습을 진행한다.
- 곱해진 값은 1보다 많이 작은 값이기 때문에 sigmoid 노드를 back propagation 할 때마다 gradient 값이 점차 작아지게는 gradient vanishing문제가 발생한다.
- sigmoid 이외의 tanh, ReLU 활성화 함수를 사용해서 gradient vanishing없이 gradient를 유지한다.
- batch normalization으로 권한을 부여해 평균은 0 분산을 1로 만들어주면서 학습을 용이하게 하면서 데이터의 고유 특성을 복원할 수 있다.
