Introduction to Deep Neural Networks
기본적인 Perceptron의 동작 원리를 알아보고 AND, OR, XOR gate를 multi-layer Perceptron으로 풀 수 있다. 한 layer에서 할 수 있었던 선형 모델에서 벗어나서 복잡한 구조의 함수을 간단한 구조의 Perceptron에 여러 layer에 걸쳐서 쌓았을 때 해결할 수 있다.
neural network를 사용하는 대표적인 task인 classification에서 많이 활용되는 softmax layer와 logistic regression/ binary classification에서 사용되는 layer와 output의 형태와 loss function에 대해서 알아본다.
Deep learning 의 많은 활용 사례에서 해당 기법들이 사용되는 것은 확인해보자.
1. 심층신경망의 개념
deep neural networks 혹은 심층 신경망은 두뇌 속에 있는 뉴런 혹은 신경 세포들을 본 따서 만든 개념이다. 신경세포들이 서로 연결관계를 가지면서 정보를 고수준으로 처리하고 여러 지능적인 task를 수행할 있도록 한다. 신체 내의 두뇌의 동작 과정을 모방하여 수학적인 알고리즘으로 나타낸 것을 심층 신경망이라 한다.
인공지능 분야에서 혼동할 수 있는 기계학습 개념과 딥러닝 개념을 간단하게 집고 넘어가보도록 한다.
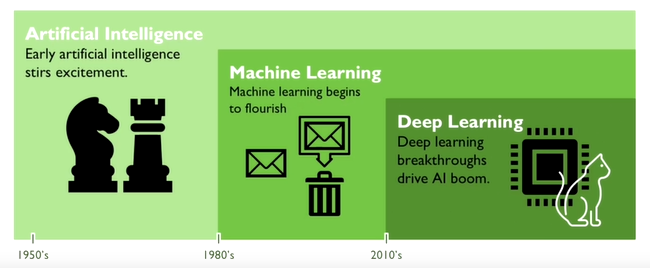
data를 중심으로 학습 data로 기계학습 알고리즘에 적용할 때, 주어진 입력과 출력의 관계를 잘 모방하고 본 따서 새로운 입력이 주어졌을 때 해당 task를 잘 수행할 수 있도록 하는 알고리즘이 기계학습/머신러닝 기법이다.
학습 data에 기반한 여러 기계학습 알고리즘 중 두뇌 속에 존재하는 신경세포들이 망을 이루면서 정보를 교환하고 처리하는 과정을 본 따서 만든 기계학습 방식의 일종이 딥러닝/ deep learning 알고리즘이 된다.
Artificial Neural Networks
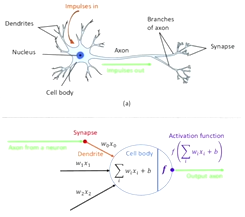
신경세포의 동작을 모방하여 만든 딥러닝을 알아보기 위해 먼저 신경 세포의 동작 과정을 알아보자.
하나의 신경세포는 다른 신경 세포들과 연결이 되어 있고, 다른 신경 세포들로부터 전기신호를 입력으로 받아 신경세포 하나에서는 특정한 값을 곱해서 나름의 변환된 전기 신호를 만들어낸다. 전기 신호를 해당 뉴런 혹은 신경세포가 연결되어 있는 다른 신경세포들에게 전달이 된다.
수학적으로 모델링을 하게 되면 입력 신호를 제공해주는 신경세포로부터 받은 입력값을 x1, x2등 여러 값으로 정의하여 해당 신경세포는 특정한 가중치를 곱해서 값과 특정한 상수값을 더해 다 다해서 1차 결합식으로 새로운 신호를 만들어 낸다. 활성화 함수 activation funcation를 최종적으로 통과해서 최종 output를 만들어낸다.
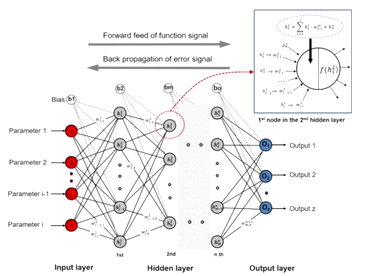
하나의 뉴런들이 모여서 하나의 신경망을 구성하게 된다. 하나하나의 특정 계층들이 존재하고 하나의 계층 내에 존재하는 다양한 뉴런들은 동일한 입력 정보를 받아서 각자 나름의 정보를 처리하게 된다. 처리된 정보를 한 세프의 입력으로 받아서 다음 계층에 있는 뉴런들에게 정보를 보내서 유의미한 정보를 얻어낸다.
붉은색 뉴런들이 최조의 신경으로 시신경 세포들이라고 하면 순차적으로 처리하는 과정을 통해 눈에서 강아지인지 고양이인지 인지할 수 있다.
DNN(deep neural network)
신경망에서 정보를 처리하는 단계를 단 몇 단계로 그치지 않고 수백 단계에 걸쳐서 정보를 처리하면서 고수준의 인공지능 task를 처리하는 것이 DNN이 된다.
DNN으로 효과적인 결과를 얻기 위해서는 필요한 3가지
- 학습을 위한 빅데이터
- 높은 사양의 GPU 하드웨어
- 최대한의 성능을 위한 deep learning algorithm
딥러닝 예시
- 영상 인식의 분야
- 이미지 합성
- 기계 번역 등의 자연어 분야
- 자연어 생성
- 주식 가격 예측
2. Perceptron
뉴런의 동작과정을 수학적으로 본 따서 만든 알고리즘이 Perceptron이다.
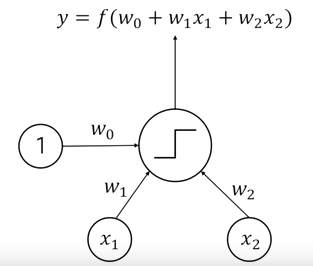
기본적인 입출력 세팅은 하나의 Perceptron이 다른 두 개의 뉴런으로부터 입력 신호를 받을 때,
해당 입력 신호를 x1, x2라고 한다.
뉴런은 정보를 잘 처리해서 출력 신호 y를 제공한다.
내부적으로 가중치에 해당하는 라는 가중치를 가진다.
뉴런/Perceptron 은 입력 정보를 가중치를 곱해서 가중합을 만들어 내는 과정을 거친다.
활성함수를 거쳐서 최종 출력 신호를 만들어 낸다.
출력 신호는 뉴런이 실제 입력 신호를 제공하게 되는 다음 계측에 있는 뉴런들에게 해당 출력을 전달해 준다.
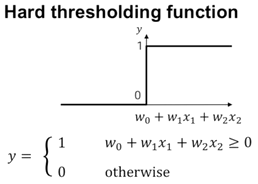
합산된 값이 최종적으로 0보다 큰 경우에는 최종 output이 1이 되고, 가중합의 값이 0보다 작은 경우에는 output이 0이 된다.
라는 특정한 상수값을 더해서 가상의 추가적인 입력 뉴런과 연결되어 있다고 가정하고, 이 입력 뉴런이 항상 1을 주는 상황이라고 한다. 여기에 뉴런의 입력값에 특정한 가중치를 곱하는 방식 으로 설명할 수 있다.
AND, OR, XOR gate
Perceptron을 통해 논리연산에서 활용되는 AND, OR gate를 쉽게 구현할 수 있다.
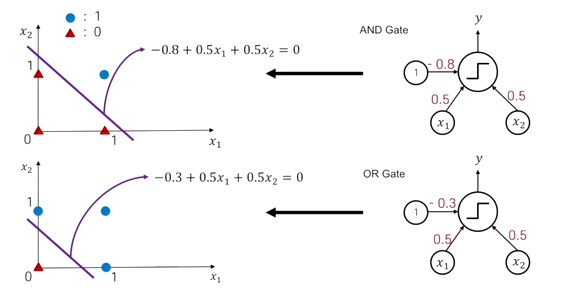
가중치의 값에 변화를 주면서 특정한 선형 결합의 가중치 값이 0보다 크냐 작냐에 따라서 최종 output이 달라진다. 0과 1이 달라지는 경계를 decistion boundary라고 한다. 입력으로 주어지는 x1, x2 (feature)를 나타내는 좌표공간을 input feature space라고 한다. 수식은 각각 2차원 상에서 직선을 나타내고 직선의 위 부분은 output이 1이 되고 아래는 0이 되면서 decistion boundary에 따라서 input feature space가 양분된다.
또다른 논리연산인 exclusive or gate (XOR gate)를 구현할 수 있다.
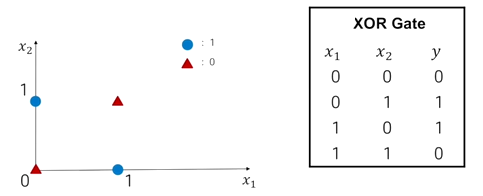
입력으로 주어지는 x1, x2가 각각 0이거나 1일 때 함수값이 0이 나오고 반대이 경우 1이 나온다. 1차 결합식을 일반화해서 나타내면 으로 특정한 형태의 기울기와 y절편을 가지는 직선이 되고 exclusive or gate의 경우 직선을 통해서 양분해서 두 부분으로 나눌 수 없게 된다.
간단한 형태의 Perceptron을 여러 단계를 걸쳐서 표현하면 XOR gate를 표현할 수 있다.
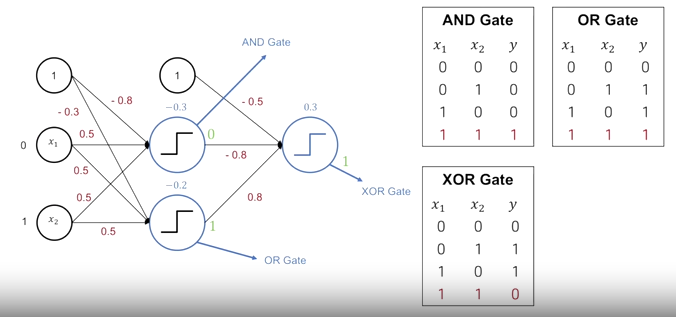
입력 신호 x1과 x2, y절편인 1에 부여되는 특정 가중치 -0.8까지 곱하여 입력 layer를 구성한다. 첫번째 layer에서는 입력 layer의 신호를 받아서 하나의 뉴런은 AND gate를 구성하고, 두 번째 layer는 OR gate를 구성하도록 설정한다. AND gate와 OR gate의 출력 값을 다시 입력으로 받아서 뉴런의 특정 가중치를 1과는 -0.5, AND gate와는 -0.8, OR gate와는 0.8 를 곱해서 최종적으로 XOR gate를 구현할 수 있다.
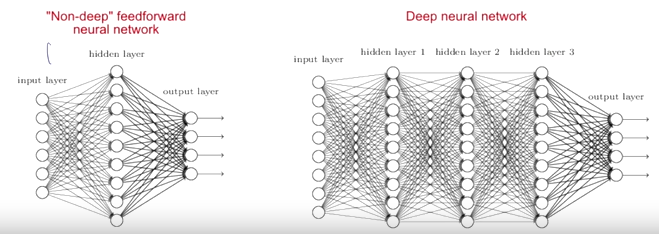
1차 결합식만으로 정보를 처리하는 간단한 단위 구조체인 Perceptron을 가지고 각각의 계층에서 서로 다른 역할들을 하는 여러 뉴런들을 순차적으로 연결함으로써 여러 계층에 걸쳐서 정보를 처리하는 nerual network으로 복잡한 문제도 처리할 수 있게 된다.
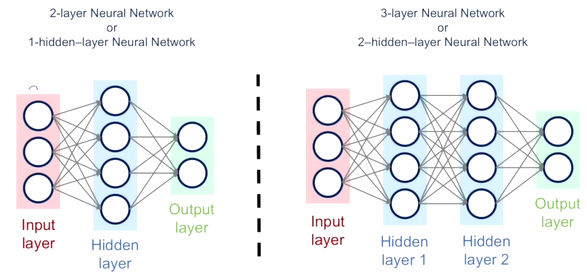
최종 output layer와 입력 input layer를 제외하고, 중간 단계의 layer를 hidden layer라고 부른다.
hidden layer가 하나일 때는 1-hidden-layer neural network이고, 입력 layer는 디폴트로 주어지기 때문에 hidden layer와 output layer 를 카운트해서 2-layer neural network 라고도 부른다.
이를 tensorflow playground 웹사이트를 통해서 다양한 계층들과 각 계층별로 뉴런의 개수들을 설정해서 task를 테스트할 수 있다.
3. multi-layer에서 Forward Propagation
한 계층 내에서 여러 개의 Perceptron를 두고 순차적인 계산과정을 나타내는 Forward Propagation에 대해서 알아보자.
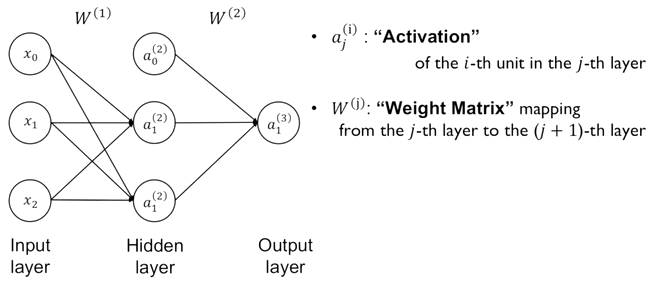
특정 layer에서 한 layer에 있는 몇 번째의 뉴런 해당 layer의 특정 뉴런의 출력 값을 activation 으로 아래첨자 j는 layer이고, 위첨자는 layer내에 몇번째 노드인지 index i가 된다. 여러 노드 혹은 뉴런들의 가중치들을 다 모아서 하나의 행렬로 나타내고 이를 계층별 가중치들을 모음체인 로 j는 layer를 나타낸다.
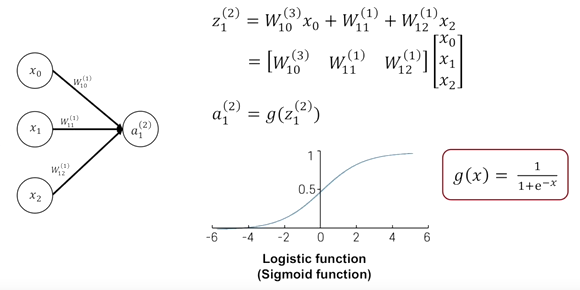
vector나 행렬 곱을 사용하여 특정 뉴런에 있는 output값을 계산하는 과정에서 뉴런의 입력 x0, x1, x2 으로 주어지는 vector를 column vector로 만들고, 뉴런이 가지는 가중치를 row vector로 만들어서 행렬의 내적 형태로 가중합을 구할 수 있다. 가중합으로 나타내지는 scalar값에 부드럽게 처리하는 sigmoid function/logistic function과 같은 활성화 함수를 사용해 0에서 1사이의 실수값을 최종적인 output 값으로 만들어 낸다.
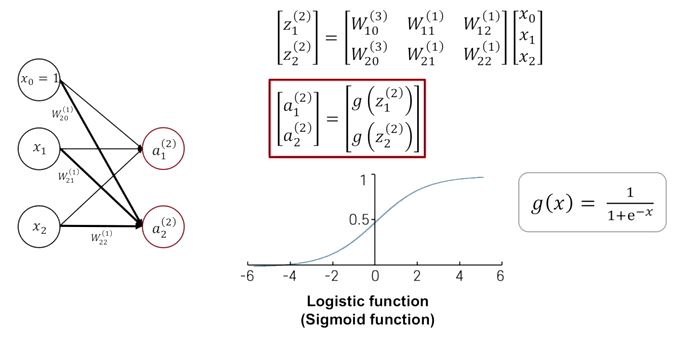
이전의 output 노드가 하나인 것에서 output노드가 2개일 때는 두 번째 뉴런이 가지는 가중치를 동일하게 row vector로 만들어서 위에 있었던 뉴런의 가중치와 함께 행렬을 구성한다. 내적 형태로 가중합을 구할 수 있다. output 노드 혹은 노드의 개수에 해당하는 dimension을 가지는 열벡터가 나오게 되고 열벡터로 주어진 각각의 원소에 활성화 함수가 적용된다.
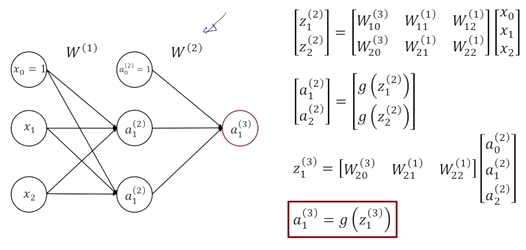
두번째 layer의 경우에도 해당 뉴런이 가지는 가중치를 row vector로 쓰고 전 layer의 출력 값이였던 column vector를 곱해서 활성화 함수를 적용하여 최종 output를 구한다.
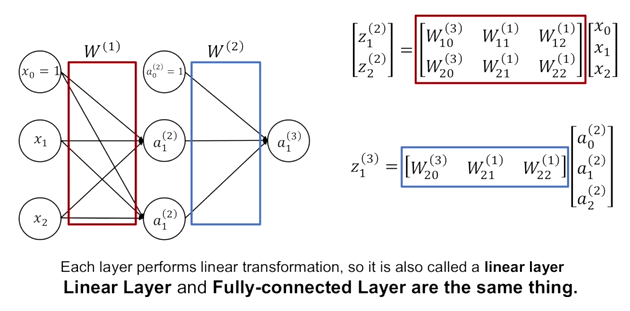
각 layer별로 가지는 모든 뉴런들의 가중치이나 output 뉴런에 대한 가중치들을 하나의 행렬로써 묶어서 나타낼 수 있다.
4. MNIST dataset
0-9까지의 digit data를 가지면 하나의 이미지는 28x28이고, 학습 데이터는 5만 5000장 테스트 데이터는 1만장이다.
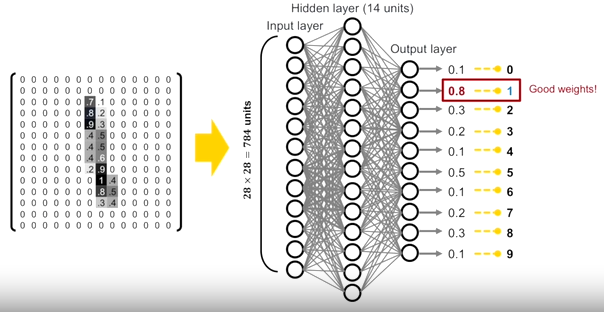
하나의 이미지에 대해서 pixel이 28x28개이고, 각각의 pixel값은 하얀 픽셀이면 0이고 검은 픽셀이면 1이 된다. 픽셀을 세로로 잘라서 28의 제곱 개수만큼의 입력 노드를 가지는 input feature vector를 만들어 nn의 입력으로 넣는다.
0-9까지의 digit에 해당하는지를 알아보는 task로 최종 output layer에 첫번 째 노드가 digit0, 마지막 노드가 digit9에 해당하는 확률값을 내어주는 multi-layer perceptron이 된다.
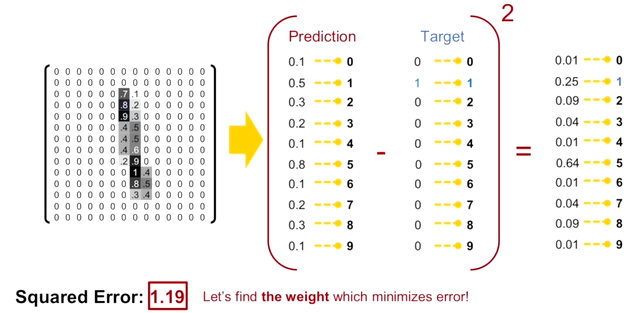
최종 출력값에 대해서 이상적인 출력 vector를 ground true function결과를 바탕으로 loss function을 만든다. 정답이 아닌 클래스의 값을 모두 0으로 한다. 해당 loss를 MSE가 된다. 분류 문제에서 MSE를 사용하였을 때 발생하는 문제점은
- 예측값과 참 값의 차이가 최대 1일 될 수 있고 이에 학습에 사용되는 gradient값이 크지 않아 학습이 느려지는 문제점
- MSE는 출력값이 확률 분포(즉, 합이 1인 값들)가 되도록 강제하지 않아서 원하는 형태는 예측값, 출력 값의 형태는 0일 확률이 10%인지, 1일 확률이 70%인지, 5일 확률이 20%로 따라서 확률의 합이 1이 되도록 하는 확률분포에 해당하는 vector를 얻는 것이 어려움.
4. Softmax Layer
MSE의 문제점을 해결하기 위해 Softmax Layer로 활성화 함수를 적용해보자.
classification에서의 softmax layer
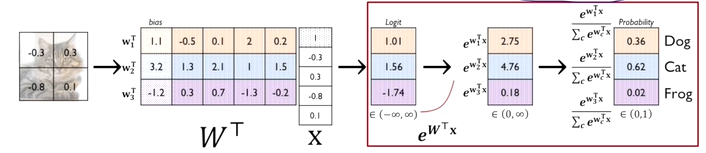
multi-layer perceptron과 마찬가지로 해당 layer의 입력 vector에 y절편에 해당하는 상수를 붙여서 입력 노드 와 layer의 가중치 값들을 모두 모아놓은 로 출력 노드는 3개이고, 입력 노드는 총 5개로 이루어져 있다. vector 간의 내적을 통해 각각의 출력 노드 값을 계산해 softmax layer에 통과시킨다. softmax layers의 입력값은 -무한대에서 +무한대까지의 다양한 값을 가질 수 있다. 이를 합이 1인 형태의 확률분포를 가지는 vector로 변환한다.
-
지수함수를 통과시킨다.
0일 때는 1이고, -무한대에서 +무한대로 갈수록 기하급수적으로 증가하는 형태이다. 모두 양수인 형태의 출력값을 가진다. -
상대적인 비율을 계산한다.
지수함수 값들의 합 분의 해당 경우의 값을 분자에 두어 상대적인 확률값으로 변환다. 총 합이 1인 형태로 모두 다 양수인 확률 vector를 구한다. -
출력된 결과가 softmax layer에 cross entropy loss function을 적용한다.
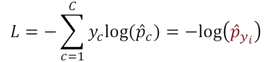
정답 class를 기준으로 확률값이 최대한 1이 되는 loss를 cross entropy function으로 변환한다.
- 가 예측된 확률 vector로 cat이 될 확률 0.62가 된다.
- 는 ground truth vector로 해당하는 class일 때는 1이고, 아닌경우 0으로 one-hot vector로 구한다.
- 예측값에 log를 취해서 one-hot vector를 곱해 최종적으로 -을 붙여서, -log는 1일 때 0이고 값이 작아질수록 무한대로 커지는 loss를 발생시킨다.
- softmax loss는 다른 class에 부여된 확률값은 부여하지 않는다. 1번에서 지수 함수를 통과하면서 상대적인 비율을 타지키 때문에 정답 class의 확률이 커질수록 아닌경우는 자연스럽게 작아지게 된다.
logistic regression에서의 softmax layer

logistic regression에서는 output 노드가 하나의 노드로만 구성되고, 동일하게 해당 layer의 입력 vector에 y절편에 해당하는 상수 1를 붙여서 입력 노드 와 layer의 가중치 값들을 모두 모아놓은 와 곱해준다.
- 가상의 다른 class에 해당하는 logit값을 0으로 default로 설정해주고 이진 분류에서 output 노드는 선형결합의 결과를 positive class로 두고, 0은 negative class로 둔다.
-
주어진 선형 결합의 output에 지수함수를 통과시킨다.
negative class인 0은 으로 output값은 1이 된다. -
두 값의 상대적인 비율을 계산한다.
negative class에 예측된 확률값은 1에서 positive class의 상대적인 확률값을 빼서 구할 수 있다.
가상의 negative class에 대한 확률 값을 계산하는 부분은 고정해놓고 positive class만 확률에 대해 최적화된 값을 도출해내는 형태이다.
- cross entropy loss에서 두가지의 경우만 binary cross entropy loss
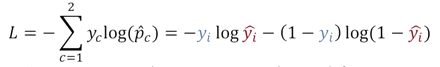
original softmax loss의 수식을 최종 output으로서 얻은 positive class를 ground truth class가 positive class라고 한다면 y vector는 1,0이 된다.
- 는 positive class일 때 1이 되고, negative class일 때는 0으로 정의된다.
정리)
- deep learning은 신체 내의 두뇌의 동작 과정을 모방하여 수학적인 알고리즘으로 나타낸 것을 심층 신경망이라 한다.
- Perceptron은 입력 vector와 각 layer별로 가지는 모든 뉴런들의 가중치이나 output 뉴런에 대한 가중치들을 하나의 행렬로 구한다.
- 선형 결합의 결과를 활성화 함수에 통과시켜서 최종적인 output 값을 구한다.
- forward propagation은 입력 데이터 층을 가쳐서 perceptron의 순차적인 계산과정으로 출력 output을 구한다.
- MSE의 값을 합이 1이 되는 0과 1 사이의 값들로 변화하기 위해서 softmax layer를 적용한 후에 cross entropy loss를 적용한다.
