
Tree #1
개념
- 비선형 구조
- 원소들 간 1 : N 관계를 가지는 구조
- 계층형 자료구조
- 상위 원소에서 하위 원소로 내려가면서 확장되는 트리(나무) 모양의 구조
정의
- 노드 : 트리의 원소
- 한 개 이상의 노드로 이루어진 유한 집합이며 다음 조건을 만족한다.
- 노드 중 최상위 노드를 root라 한다.
- 나머지 노드들은 n(>=0)개의 분리 집합 T1,,,,Tn으로 분리될 수 있다.
- 이들 T1~Tn은 각각 하나의 트리가 되며(재귀적 정의) 루트의 부 트리(subtree)라 한다.
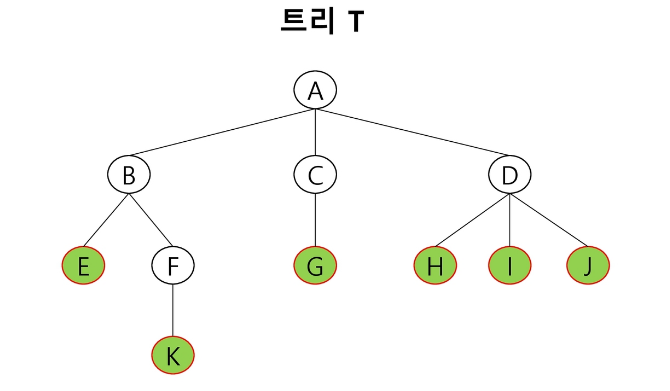
노드 : A, B, C ~ K
루트 노드 : A
간선 : 노드와 노드가 연결된 선
용어 정리
형제 노드 : 같은 부모(상위) 노드의 자식 노드 들
조상 노드 : 간선을 따라 루트 노드까지 이르는 경로에 있는 모드 노드들
서비 트리 : 부모 노드와 연결된 간선을 끊었을 때 생성되는 느리
자손 노드 : 서브 트리에 있ㄴ는 하위 레벨의 노드들
차수(degree)
- 노드의 차수 : 노드에 연결된 자식 노드의 수
- 트리의 차수 : 트리에 있는 차수 중 가장 큰 값
- 단말 노드(리프 노드) : 차수가 0(자식이 없는)인 노드
높이
- 노드의 높이 : 루트에서 노드에 이르는 간선의 수. 노드 레벨이라고도 함. (ex. B노드의 높이는 1, A는 0)
- 트리의 높이 : 노드 높이 중 가장 큰 값. (트리의 높이 = 3)
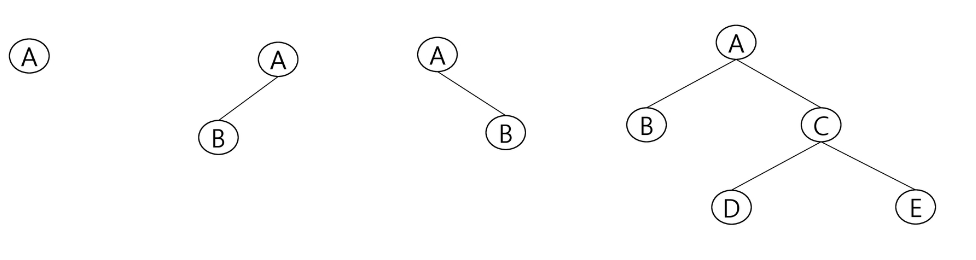
이진트리
개념
-
차수가 2인 트리
각 노드가 자식 노드를 최대 2개까지만 가질 수 있음 -
모든 노드들이 최대 2개의 서브트리를 갖는 특별한 형태의 트리
특성
- 높이 i에서의 노드의 최대 개수는 2개
- 높이가 h인 이진트리가 가질 수 있는 노드의 최소 개수는 (h+1)개가 되며, 최대 개수는
2^(h+1) - 1개가 됨.
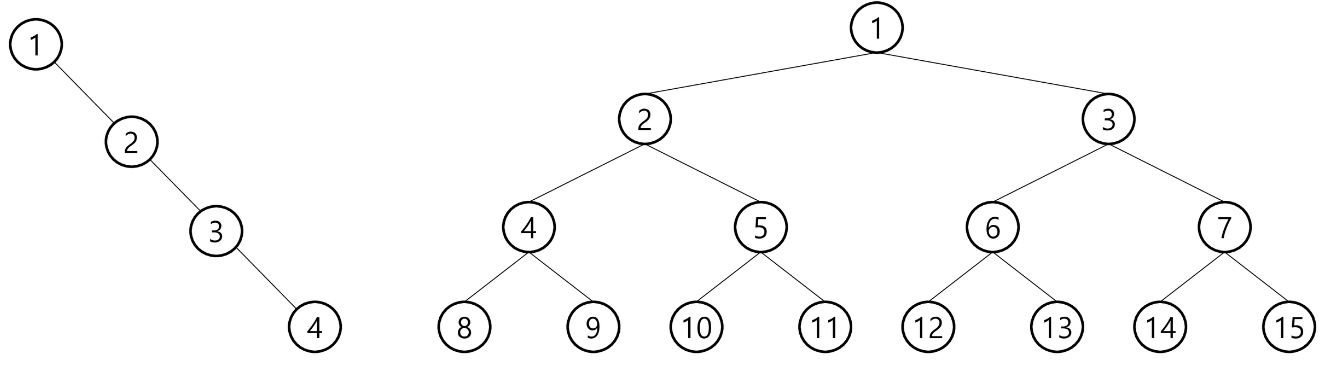
배열로 표현
- 루트 번호를 1
- 왼쪽 자식 노드는 부모(루트 포함) 노드 * 2
- 오른쪽 자식 노드는 * 2 + 1
비선형 자료구조 완전탐색
비선형 구조인 트리, 트래프의 각 노드를 중복되지 않게 전부 탐색하는 것.
하지만 비선형 구조는 선형 관계와 달리 선후 관계를 모름.
→ 그래서 DFS와 BFS로 탐색해야 함.
BFS
루트 노드의 자식 노드들을 먼저 차례대로 방문한 후에, 방문했던 자식들을 기준으로 하여 다시 해당 노드의 자식 노드들을 차례로 방문
그럼 다음 레벨의 자식 노드를 방문하기 위해서는 현재 레벨의 자식들을 다 방문 한 뒤에야 탐색 가능
→ 즉, 선입선출 형태라 Queue를 활용함.
Queue에는 다음 방문할 노드를 저장.
예시
-
큐에 루트 노드(A)를 넣는다.
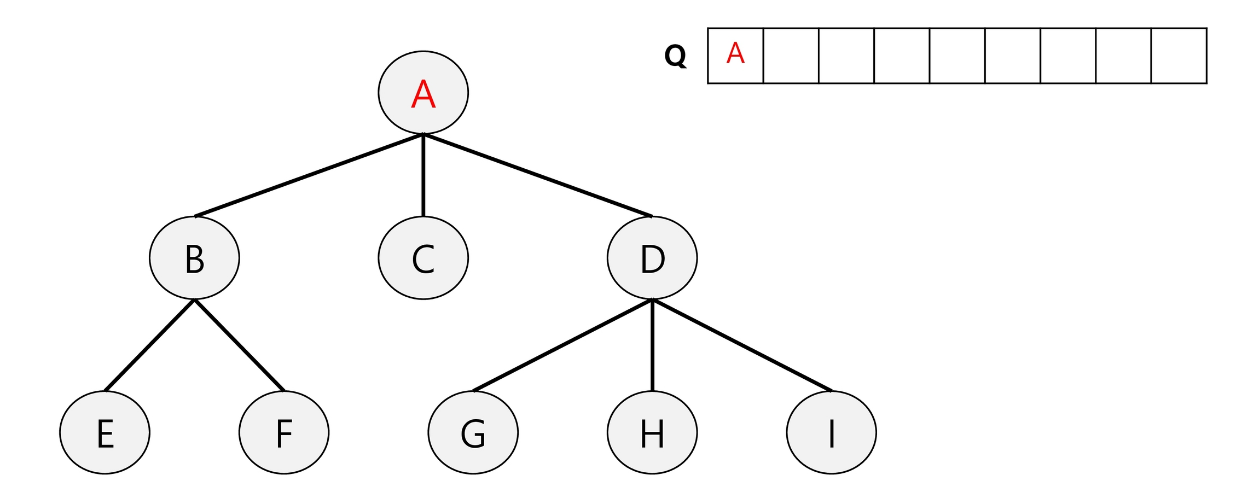
-
A가 큐에서 나오면서 A의 자식들을 방문 예정인 큐에 넣는다.
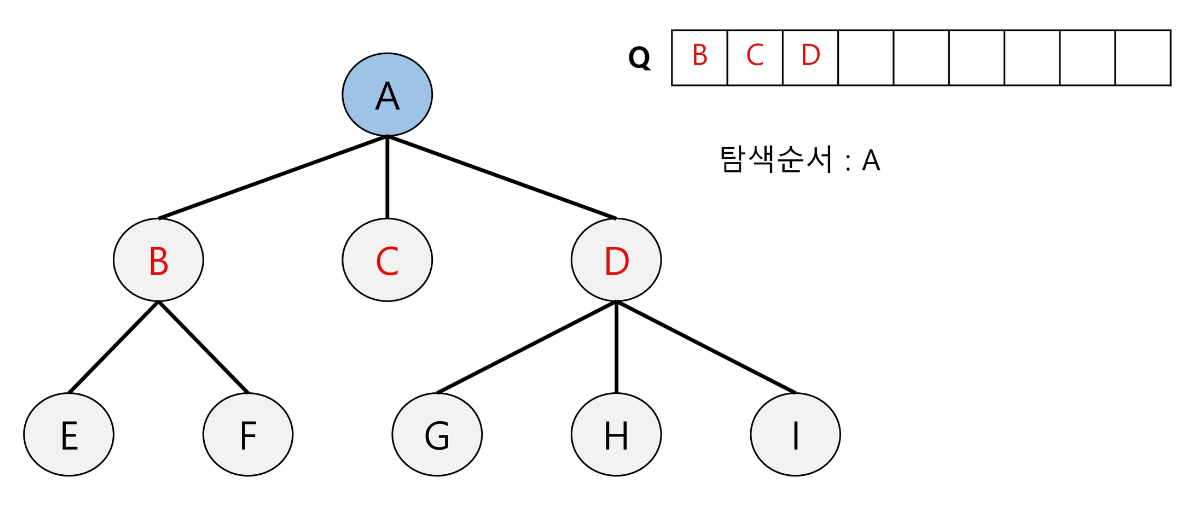
-
1과 2의 방법을 반복하면서 큐가 빌 때까지 진행하며 탑색을 완료한다.
코드
완전이진트리를 가정으로 코드를 작성해보자.
public class CompleteBinaryTree<E> {
private Object[] nodes;
private int lastIndex;
private final int MAX_SIZE;
public CompleteBinaryTree(int maxSize) {
super();
MAX_SIZE = maxSize;
nodes = new Object[MAX_SIZE + 1];
}
public boolean isFull() {
return lastIndex == MAX_SIZE;
}
public void add(E e) {
if(isFull()) throw new RuntimeException("트리가 노드로 가득 찼습니다.");
nodes[++lastIndex] = e;
}
public void bfs() {
// 1. 순서를 관리할 큐 준비
Queue<Integer> queue = new ArrayDeque<>();
// 2. 처음 탐색의 대상이 될 대상을 큐에 넣기
queue.offer(1);
// 3. 큐에 저장되어 있는 탐색 대상들을 차례대로 꺼내어 방문
while(!queue.isEmpty()) {
// 4. 탐색 대상 꺼내기
int cur = queue.poll();
// 5. 탐색 대상 탐색하기 (대상으로 해야 할 작업들 수행)
System.out.print(nodes[cur] + "\t");
// 6. 탐색 대상과 관계를 맺고 있는 대상들을 다음에 방문하기 위해 순서를 결정하는 큐에 넣기
if(cur*2 <= lastIndex) queue.offer(cur * 2);
if(cur*2 + 1 <= lastIndex) queue.offer(cur*2+1);
}
}
public void bfs2() {
// 1. 순서를 관리할 큐 준비
Queue<int[]> queue = new ArrayDeque<>();
// 2. 처음 탐색의 대상이 될 대상을 큐에 넣기
queue.offer(new int[] {1, 0}); // 루트 노드 인덱스, 너비 넣기
// 3. 큐에 저장되어 있는 탐색 대상들을 차례대로 꺼내어 방문
while(!queue.isEmpty()) {
// 4. 탐색 대상 꺼내기
int[] info = queue.poll();
int cur = info[0];
int breadth = info[1];
// 5. 탐색 대상 탐색하기 (대상으로 해야 할 작업들 수행)
System.out.print(nodes[cur] + "(" + breadth + ")\t");
// 6. 탐색 대상과 관계를 맺고 있는 대상들을 다음에 방문하기 위해 순서를 결정하는 큐에 넣기
if(cur*2 <= lastIndex) queue.offer(new int[] {cur * 2, breadth + 1});
if(cur*2 + 1 <= lastIndex) queue.offer(new int[] {cur*2+1, breadth + 1});
}
}
}bfs()와 bfs2()의 차이는 너비를 입력해주는 것 외엔 차이가 없다.
이러한 과정으로 완전 이진 트리를 탐색할 수 있다.
DFS
이번엔 너비가 우선이 아닌 깊이를 우선으로 탐색해 보자.
깊이 우선 탐색의 개념은
루트 노드에서 출발하여 리프 노드까지 한 방향으로 쭉 간다.
리프 노드를 만나면 다시 돌아가 바로 위(부모)노드에서 다른 갈림길로 가며 다시 한 방향으로 쭉 탐색한다.
이를 반복하여 모든 노드를 탐색하는 것이 깊이 우선 탐색이다.
이러한 방식은 재귀적으로 구현하거나 스택으로 구현이 가능하다.
예시
-
루트 노드(A)를 방문한다.
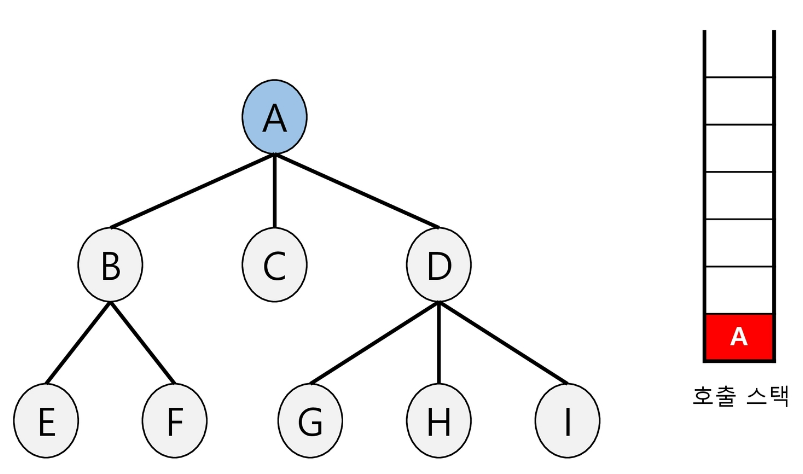
-
왼쪽부터 A의 자식인 B를 호출한다.
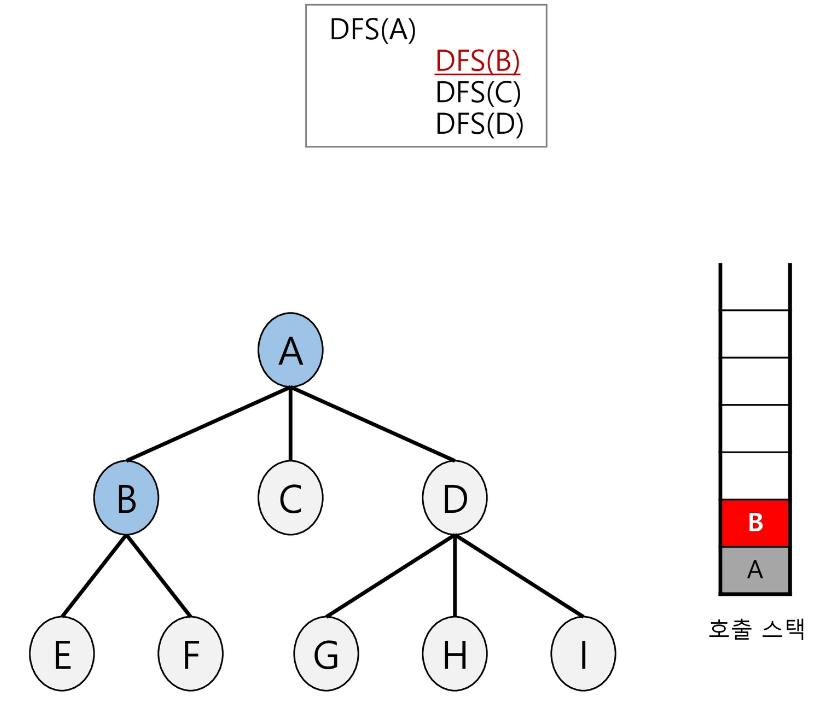
-
2와 같이 E를 호출한다.
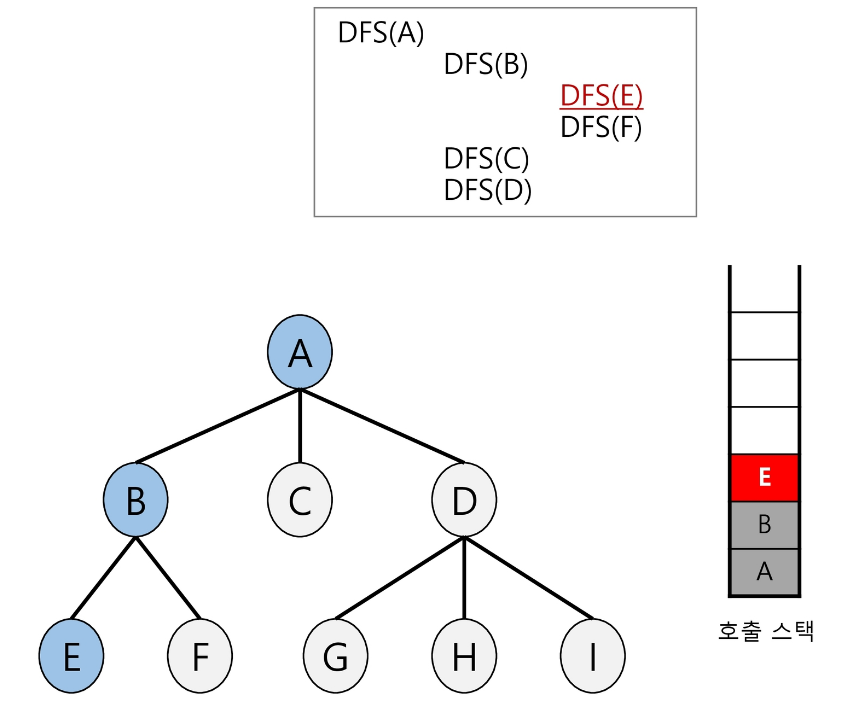
-
E는 더이상 자식이 없으므로 되돌아가며, 형제인 F를 호출한다.
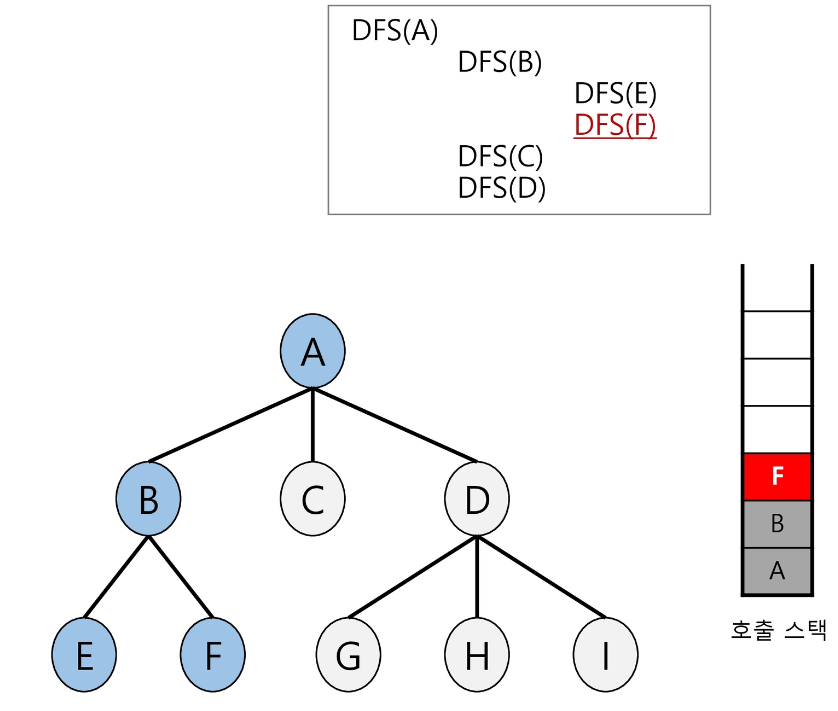
-
이와 같은 과정을 반복하여 I까지 탐색(호출)을 마친다.
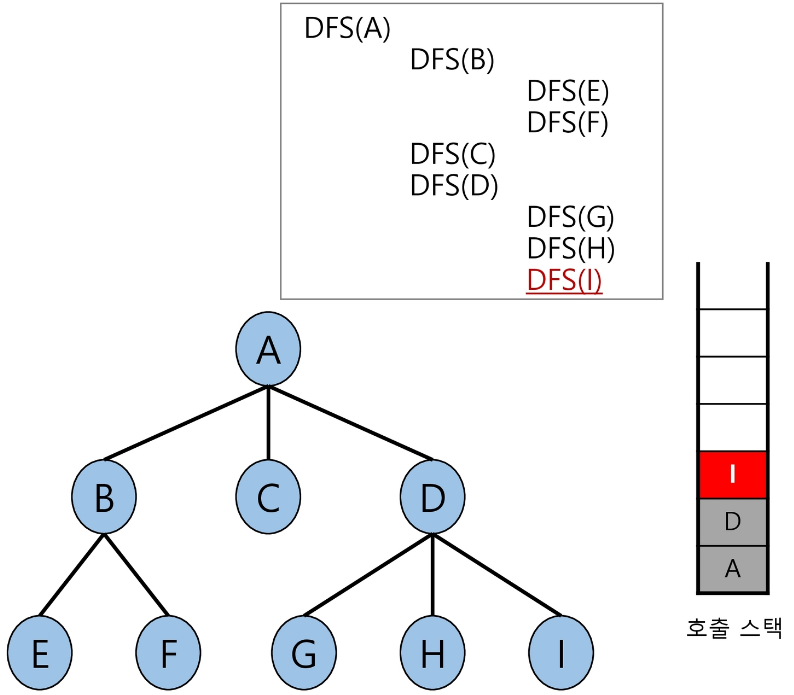
탐색 순서
A → B → E → F → C → D → G → H → I
방문은 I가 마지막이지만, 함수 호출의 종료는 A가 마지막이 된다.
코드
bfs에서 했던 코드에 1가지 메서드만 추가해보자.
전위 순회를 기준으로 작성했다.
public void dfsByPreOrder(int cur) {
// 1. 탐색 대상 탐색하기 (대상으로 해야 할 작업들 수행)
System.out.print(nodes[cur] + "\t");
// 2. 탐색 대상과 관계를 맺고 있는 대상들을 다음에 방문하기 위해 노드 탐색 시키기
if(cur*2 <= lastIndex) dfsByPreOrder(cur * 2);
if(cur*2 + 1 <= lastIndex) dfsByPreOrder(cur * 2 + 1);
}재귀로 구현한 DFS이며, 전위순회를 하기 때문에, 왼쪽과 오른쪽 자식을 호출하기 전 방문 했다는 출력문을 먼저 실행하면 DFS가 끝이 난다.
완전 이진 트리에서 완전 탐색을 해야 한다면 DfS와 BFS가 같은 성능을 보이지만
상황에 따라 사용할 탐색을 다르게 해야 한다.
또한, 굳이 완전 이진 트리가 아니더라도 BFS와 DFS를 사용할 수 있는 상황이 있다.
