Motivation
MLPerf (the Olympic Game for AI Computing)
MLPerf: Machine Learning + Performance, ML 도입 시스템을 평가하기 위한 타당하고 신뢰할 수 있는 벤치마크를 위해 업계와 학계의 연구진과 엔지니어가 모여 만든 벤치마크
- 벤치마크 규격 준수에 따라 구분
- Closed: 모든 규격을 지킨 벤치마크 (ex. 모델 구조, 데이터 전/후처리 등)로 주로 hw의 성능을 평가함
- Open: 정해진 특정 규격을 제외하고는 모두 변경 가능한 벤치마크로 hw와 sw의 성능을 평가함
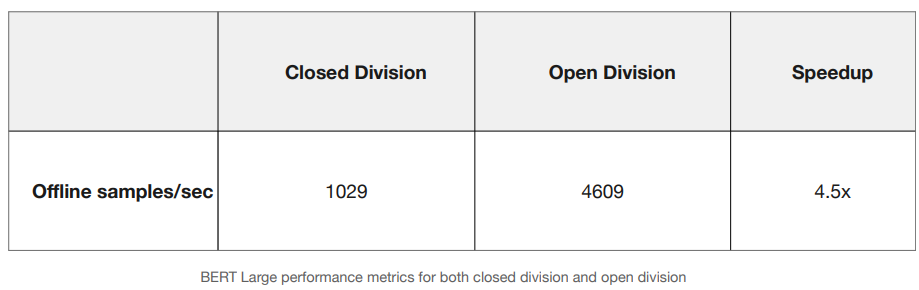
표를 보면, closed의 경우 1029이지만, open division의 경우 4609로 4.5배 더 빠르다. 이 sw 테크닉들에 대해서 공부할 예정이다.
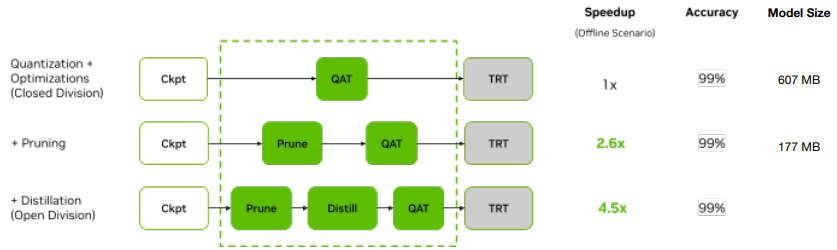
간단하게 nvidia는 이 성능 달성을 위해 크게 3개의 기법을 사용했다.
- quantization, pruning, distillation
Memory is Expensive
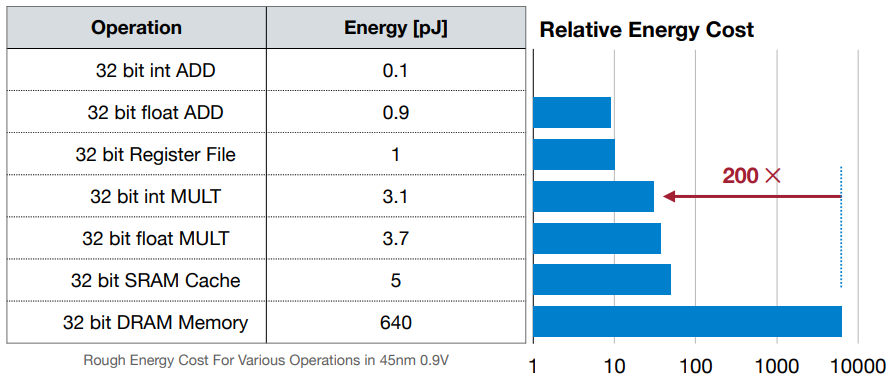
- 정수와 부동소수점 연산에서 add는 9배나 차이나지만, mul은 2배도 차이나지 않는다. 이는, 덧셈에서는 부동소수점 연산 자체의 복잡성 때문에 에너지 소모가 커서 차이가 많이 났지만, 곱셈의 경우에는 정수, 부동소수점 모두 복잡한 연산이므로 상대적으로 차이가 적은 것이다.
- 사칙연산에 비해 메모리 이동에서의 전력 소모량이 매우 높은 것을 확인할 수 있다. 이는 모델 추론에서도 큰 영향을 미친다. gpu 병렬 연산을 생각하면 한번에 병렬처리 된다고 생각하기 쉽지만, 사실은 gpu core가 바로 사용할 수 있는 메모리 영역은 크지 않아서, 한 layer의 가중치나 feature map이 모두 로드되지 못할 수 있다. 따라서 순차적으로 가중치와 feature map을 로드하여 병렬처리하게 되는 것이다.
- 모델 로드: cpu의 dram에 있던, 모델의 가중치와 구조를 gpu dram으로 로드함
- 입력 데이터 로드: cpu dram에 있던, 입력 데이터를 gpu dram으로 로드함
- 가중치 밒 입력 데이터 로드: gpu core에서 필요한만큼의 가중치 및 데이터를 온칩 메모리(gpu 레지스터, 캐시)로 로드함
- 연산 수행: gpu core에서 로드된 데이터들을 사용하여 연산 수행
- 여튼, 그래서 모델을 경량화하면, 연산량이 줄어든다는 점에서도 이점이 있지만, 메모리를 로드하는 것을 줄이는것도 매우 큰 이점이 있다. 추가적으로, gpu/npu 컴파일러 단에서는 메모리를 로드하는 것을 최적화한다.
Neural Network Pruning
Introduction to pruning
What is pruning?
pruning은 여분의 노드를 제거함으로써 dense한 신경망을 sparse한 신경망으로 바꾸는 방법이다.
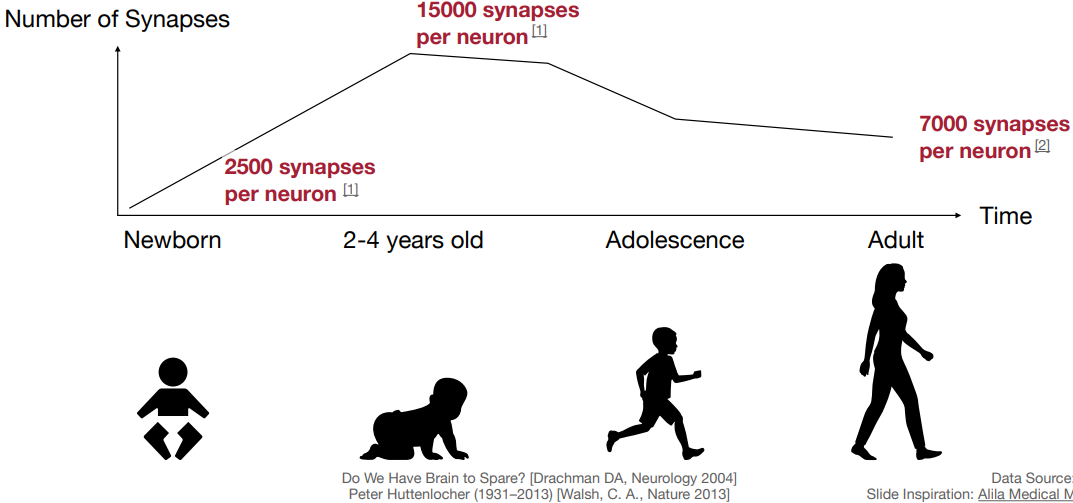
사람은 시간이 지남에 따라 하나의 뉴런에 연결된 시냅스 개수가 달라진다.
- 초기: 2500
- 2~4살: 15000
- 청소년기: 감소 (대부분의 지식을 배우는 시기)
- 성인: 7000 유지
이 과정은 인간의 뇌에서 자연적으로 이루어진다. 2~4살일 때보다 성인인 지금에 시냅스는 로 줄었고, 이는 퇴화가 아닌 필요한 시냅스만 유지되게 된 것이다. 이 개념을 모델에도 적용할 수 있다.
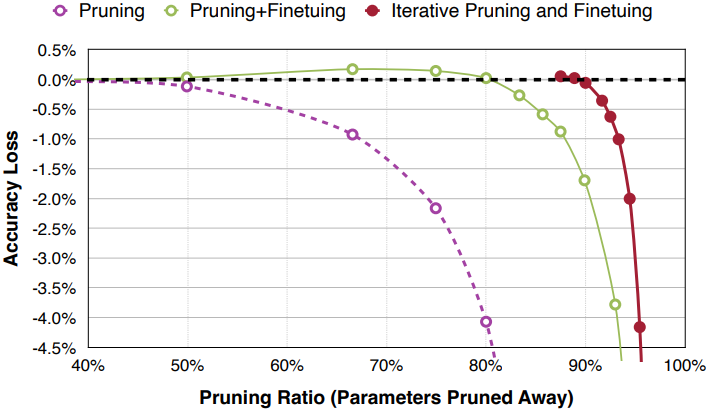
- pruning만 하는 경우
- 그래프에서 볼 수 있듯이 단순히 pruning만 하게 되면, 많은 정확도 손실이 발생한다.
- pruning+fine tuning
- 80%까지 pruning해도 기준 모델과 정확도가 유사하며, 오히려 그 전에는 generalization 효과로 더 높은 성능을 보인다.
- iterative pruning+fine tuning
- iterative는 한번에 목표 비율까지 pruning하는 것이 아니라, 점진적으로 (30->50->70->90%) pruning을 하는 것이다.
- 90%까지 pruning을 해도 정확도가 유지된다.
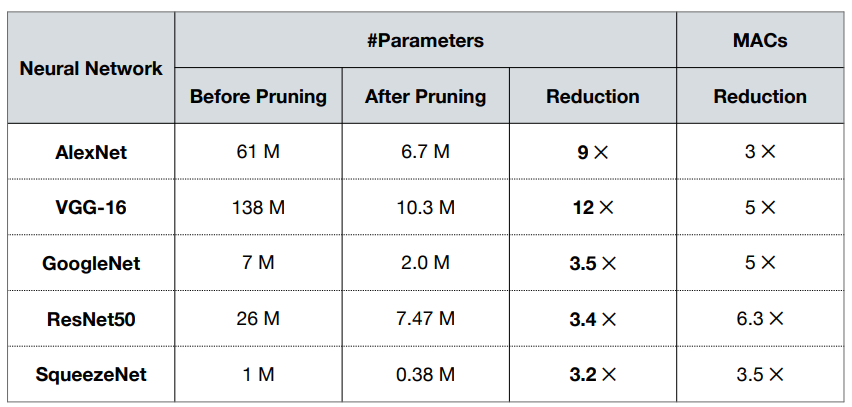
sqeezenet과 같이 엄청 작은 네트워크에서도 pruning을 수행할 수 있다.
- 여기서 vgg-16은 파라미터가 12배나 줄었지만, 연산량은 5배만 줄었고, resnet50은 파라미터가 3.4배 줄었지만, 연산량은 6.3배나 줄었다. 이는 네트워크 구조때문인데, vgg-16은 fc layer가 3개 있고 (약 17%), resnet50은 fc layer가 1개만 있다 (1% 미만). fc layer는 sparsity가 어렵기 때문에 fc layer에서의 pruning을 연산량 감소에 많은 영향을 끼치지 못한다.
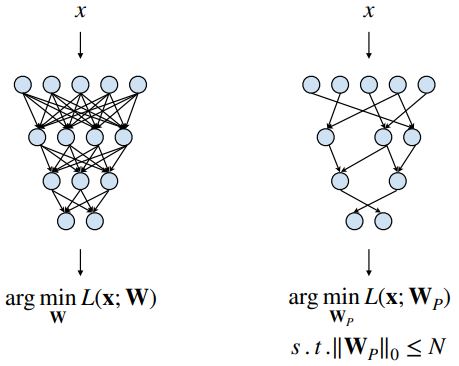
원래 네트워크의 목표는 손실함수를 최소로 하는 를 찾는 것이다. pruning된 네트워크에서도 손실함수를 최소화 하는 를 찾는 것이다. 이때, 중 0이 아닌 파라미터의 수를 N보다 적게 한다는 제약사항이 있다. 즉, loss는 기존과 같이 낮추면서, 0인 파라미터의 수를 설정하는 것이다.
- input:
- 가중치:
- pruning 이후의 가중치:
- N: 목표 non-zero params
Determine the Pruning Granularity
종류
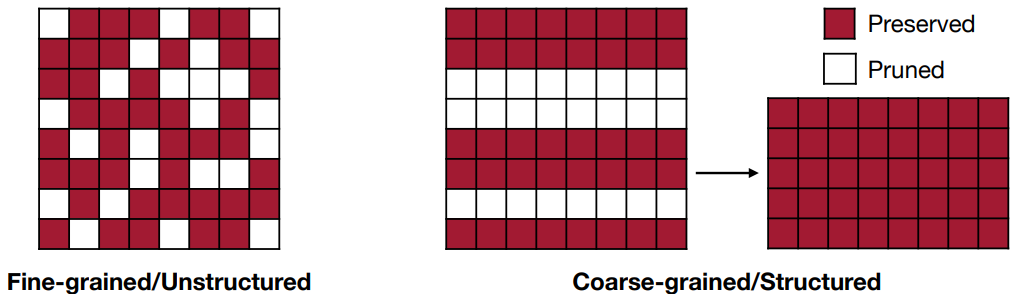
- structured pruning
pruning을 한 이후에도 여전히 dense한 가중치를 가질 수 있기 때문에, HW적으로 효율이 높을 순 있지만 중요한 가중치도 같이 pruning될 수 있다는 단점이 있다. - unstructured pruning
유연하게 원하는 파라미터만 pruning할 수 있지만, 불규칙하게 pruning되기 때문에 병렬처리를 위한 HW 가속이 매우 어렵다.
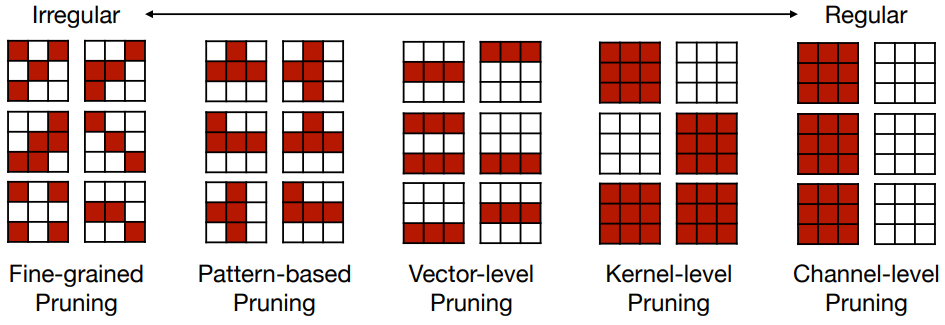
Flexibility: Fine-grained > ... > Channel-level
Accelerating: Channel-level > ... > Fine-grained
이 중, nvidia ampere gpu 아키텍처에서 지원하고 있는 pattern-based pruning 예시를 살펴보자
Pattern-based pruning: N:M sparsity
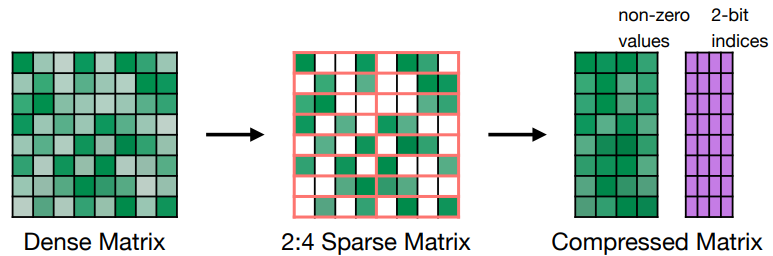
연속되는 M개의 요소 중 N개를 pruning하는 방식이다.
- 정확도는 유지하며, 속도는 2배까지 높일 수 있다.
- 2:4 sparse matrix를 compressed matrix로 표현하면서, 가중치 값 + 위치 정보를 별도로 저장해야하기 때문에 가중치 메모리는 딱 절반으로 줄 순 없다.
- 8x8:
- 8x4 + 2bit 8x4:
- 8x8 + 3bit 8x4:
유연성을 늘리면, 메모리가 같이 늘어난다.
Channel-level pruning
매우 규칙적이고 가속화하기 쉽기 때문에 실제 현업에서 가장 많이 사용하는 방식이다. 당연하게도, 모두 동일한 비율로 pruning하는 것보다, 각 layer 별로 pruning 비율을 다르게 하는 것이 좋다.
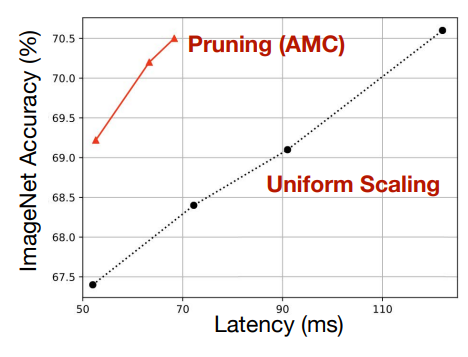
amc는 자동으로 layer pruning 비율을 탐색해서 channel pruning을 하는 방법이다.
Determine the Pruning Criterion
그렇다면 과연 어떤 가중치를 제거하는 것이 타당한가 생각해보면 절댓값이 가장 작은, 즉, 출력에 가장 작은 영향을 끼치는 가중치를 제거하는 것이 가장 타당하다.
Magnitude-based pruning
가중치의 크기에 따라 pruning을 하는 방식이다.

- elemenet-wise pruning, l1-norm
- row-wixe pruning, l1-norm
- row-wise pruning, l2-norm
- lp-norm
위의 그림은 row-wise+l2-norm의 예시이며, 정규화, pruning 단위에 따라 설정할 수 있다.
Scaling-based pruning (channel pruning)
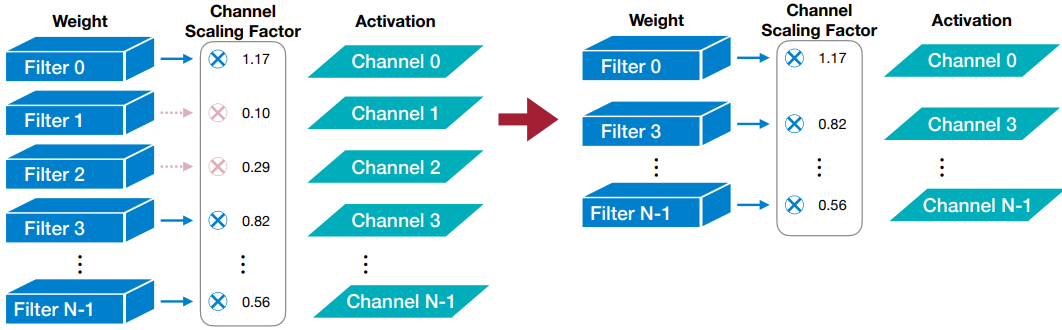
각 채널마다 scaling factor를 통해, importance를 학습하고, scaling factor값이 작은 채널을 pruning하는 방식이다.
이때, 파라미터를 새로 추가하지 않고, batch norm의 scaling factor를 재사용하는 것도 가능하다.
Taylor Expansion Analysis on Pruning error
수식적으로 풀어내는 방식도 있다.
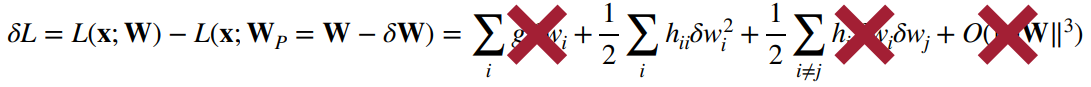
second-order based pruning은 2차항까지 유지하는 방법으로 위와 같이 수식이 정리될 수 있다.
- loss function은 대부분 quadratic이기 때문에 4번째 항은 무시할 수 있음
- 학습 후 수렴된 네트워크의 gradient는 거의 0에 가깝기 때문에 첫번째 항은 무시할 수 있음
- 각 파라미터가 독립적이므로 3번째 항은 무시할 수 있음
이제 나오는 방법들은 단순히 가중치를 pruning하는 것이 아닌, output을 활용하여 가중치와 activation을 pruning하는 것이다.
Percentage of zero based pruning
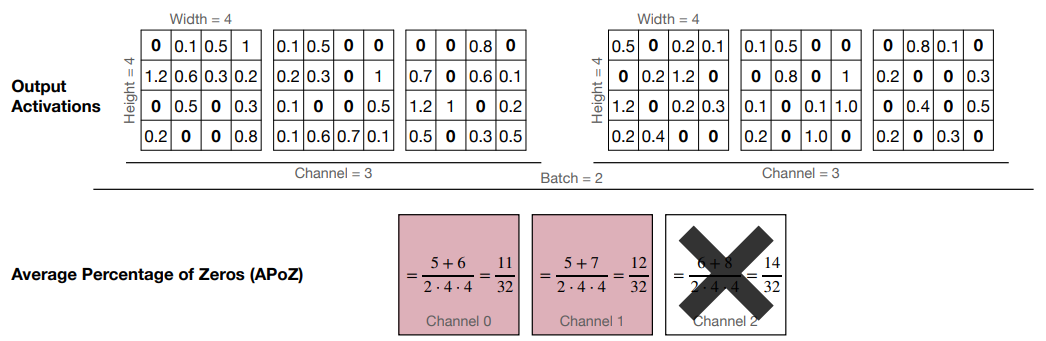
output에서 0이 가장 많은 채널을 pruning하는 방법이다.
Regression-based pruning
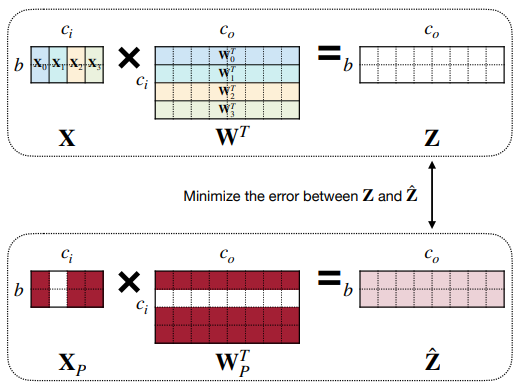
전체가 아닌 각 layer에서의 원래의 output과 pruning된 이후의 output의 차이를 최소화하는 방식이다.
