Neural Network Pruning
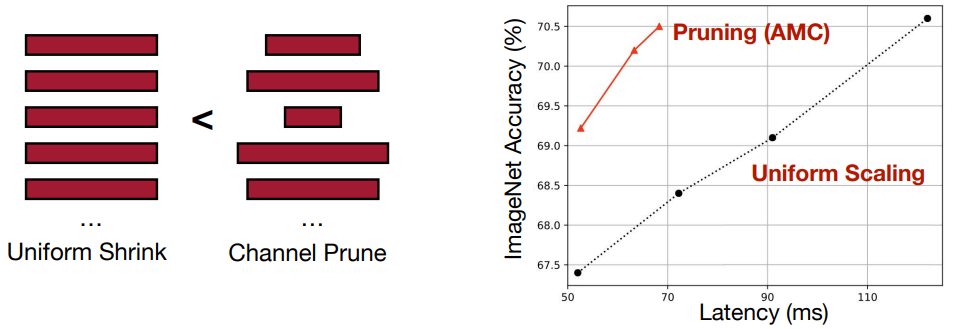
모든 layer에 동일한 비율로 pruning을 수행하는 것 보다 각 layer별로 영향력에 따라 비율을 달리하는 것이 더 성능이 좋다.
- 그래프에서 좌상단에 가까울 수록 좋은 것이다.
Determine the Pruning Ratio
Sensitivity analysis
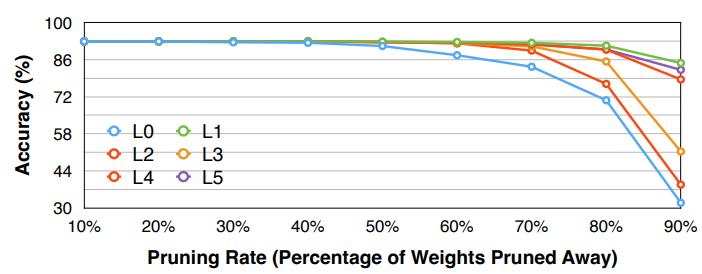
어떤 layer에서는 약간의 pruning만 해도 정확도가 매우 급격하게 떨어지고, 다른 layer에서는 많은 pruning을 해도 정확도가 유지되고 있다.
- fc layer는 고차원의 정보를 종합하는 것으로, 특정 노드가 pruning되더라도 다른 노드에 이미 정보가 포함되어 있을 수 있기 때문에 pruning 영향이 적다.
그래프를 살펴보면..
- pruning 비율이 높아질수록 accuracy 손실이 더욱 커진다.
- layer 중 pruning 비율을 높여도 손실이 적은 경우(L1 layer)에 대해 sensitivity가 낮다고 하며, 이 layer는 pruning 비율을 높게 설정할 수 있다.
- layer 중 pruning 비율을 높이면 손실이 많은 경우(L0 layer)에 대해 sensitivity가 높다고 하며, 이 layer는 pruning 비율을 높게 설정하는 것은 좋지 않다.
- 고려사항
- 각 layer는 독립적이다.
- pruning 비율이 같다고해서, pruning되는 수가 같진 않다.
- 그래프에서의 threshold에 맞춰서 pruning하더라도, 해당 threshold T를 보장할 순 없다. 실험은 각 layer 하나만 pruning했을 때의 결과를 겹쳐놓은 것고, 여러 layer에 대해 pruning했을 때, T가 유지될지/좋아질지/나빠질지는 해보기 전까지는 아무도 모른다.
Automatic Pruning
앞의 방법은 사용자가 직접 layer별 sensitivity를 분석하고, 각 layer 별로 pruning ratio를 적용하는 것이다. 많은 사람이 다양한 모델에 대해서 자동적으로 pruning을 수행할 수 있도록 하는 모델을 살펴보자.
AMC
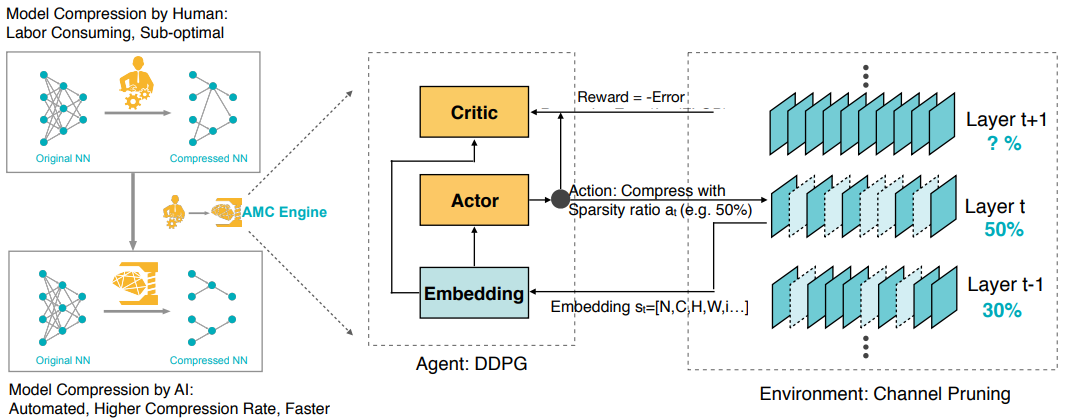
AMC: AutoML for Model Compression and Acceleration on Mobile Devices
- channel pruning
- 강화학습 actor/critic 모델 사용
- agent가 환경과 상호작용하며 reward를 최대화하는 action을 학습하는 과정
- actor로 DDPG model 이용
- DDPG(Deep Deterministic Policy Gradient)
- critic
- reward = -error * log(FLOP) 제공
- 정확도는 높이면서, 계산량은 줄이는 리워드 함수
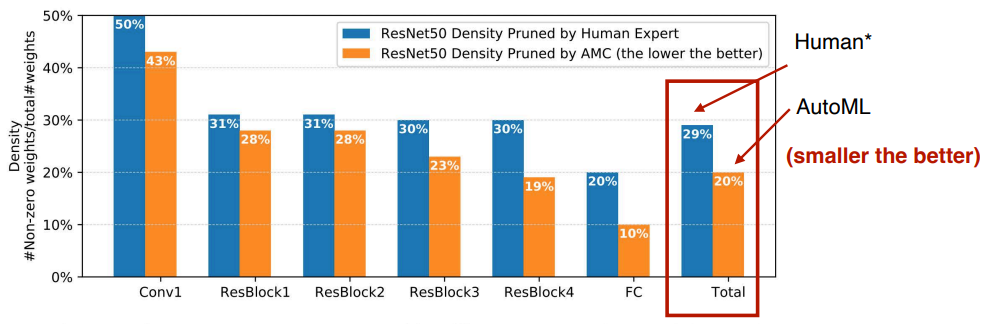
- vs Human
교수님께서 직접, 일주일 이상 model compression 수행ㅋㅋ
human은 29%, amc는 20%까지 pruning하였다.
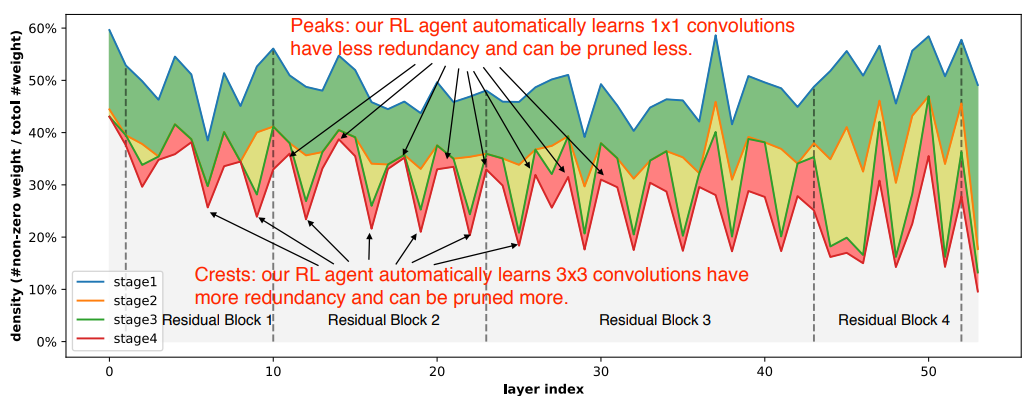
- iterative pruning을 수행한 결과이며, 각 layer 별로 pruning 비율의 특징을 확인할 수 있다.
- 공격적으로 pruning된 layer
- 3x3 convolution
- 똑같이 하나의 채널을 pruning하더라도 3x3에서는 9개 1x1에서는 1개를 제거하게 된다. 즉, 하나의 채널을 없애면 해당 채널에서 정보를 얻지 못하게 되는 것은 똑같은데, 더 많은 파라미터를 줄일 수 있는 3x3에서 많은 pruning이 이루어진 것이다.
- 비교적 덜 공격적으로 pruning된 layer
- 1x1 convolution
- 공격적으로 pruning된 layer
Netadapt
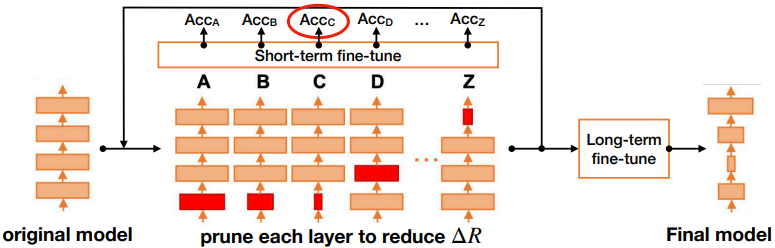
- 수행 방법
- 먼저 리소스 제약 조건을 설정한다.
- 각 레이어가 성능에 얼마나 기여하는지, 중요도를 미리 평가한다.
- 2번에서 평가한 중요도에 따라 가장 최적의 layer를 선택하고, 학습(short-term)하는 과정을 반복한다.
- 리소스 제약 조건에 도달 시, 마지막 학습을 수행한다 (long-term).
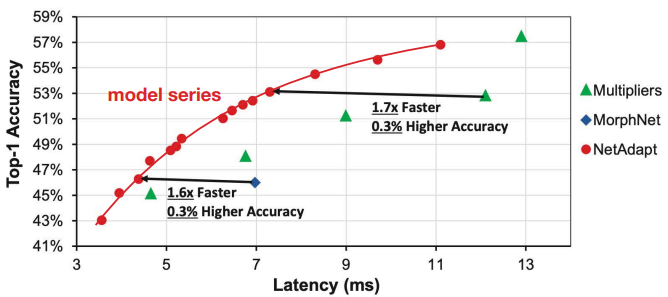
- 실험 결과
multiplier보다 1.7배 빠르고, 0.3% 정확도가 높았다.
(multiplier는 모든 layer에 동일한 pruning 비율을 적용한 것)
Fine-tune/Train Pruned Neural Network
pruning ratio가 증가할수록 정확도가 많이 떨어지게 되는데, fine-tuning이 pruning된 모델의 정확도 회복에 도움을 준다.
Iterative Pruning
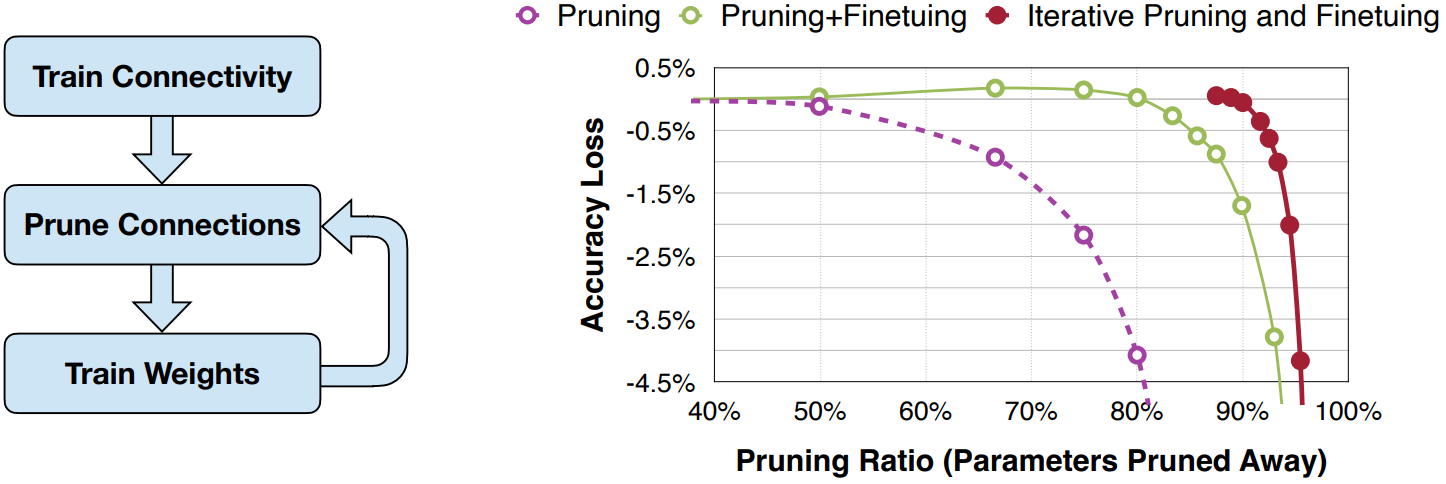
- 당연하게도, iterative pruning에서 성능이 제일 높다.
- 말 그대로, 한번에 목표 pruning ratio까지 도달하는 것이 아닌, step별로 pruning을 수행하는 것이다.
- EX) 30% pruning -> train -> 50% -> train -> 70% -> train
- fine-tuning을 할 때의 lr는 보통 혹은 로 줄인다.
- 왜 똑같이 lr을 줄여야 하는 것인가 생각해보면, 모델은 pruning되었더라도 학습되지 않은 모델에 비해 충분히 학습되어 수렴된 상태다. 이때 lr을 크게 설정하면, 기존에 가지고 있던 정보는 잃으면서, 가중치가 적은 상태로 다시 학습을 하는 것과 마찬가지이다. 이는 pruning을 통해 얻고자 했던 장점 (모델 경량화+기존 정보의 보존)을 얻지 못하는 것이다.
Regularization
Regularization에는 크게 Batch norm, dropout, early stopping, weight decay가 있다. 이 중 weight decay를 pruing 학습 시에 적용한다.
- weight decay
- 모델의 손실함수 값이 너무 작아지지 않도록 특정한 값을 추가하는 방법으로, 특정한 weight값이 과도하게 커져서 일부 특징에 의존하는 현상을 방지하고, 데이터의 일반적인 특징을 잘 반영할 수 있도록 한다. (l1, l2 regularization)
- 원래 weight decay의 목표는 위와 같지만, pruning에서는 0이 아닌 가중치에 패널티를 주기 위해 weight decay를 사용함으로써 가능한 많은 가중치가 0이 되도록 한다. 이는 다음 iteration에서 pruning될 수 있는 가중치들인데, 0에 가까운 가중치가 많으면 최적의 선택을 할 수 있게되니까..?
- drop out
- dropout vs pruning
dropout은 오버피팅을 막는 것을 목표로 하며, 각 iteration마다 랜덤한 가중치를 제거한다. 실제로 추론할 때에는 모든 가중치를 사용한다.
반면 pruning은 추론 속도를 높이는 것을 목표로 하며, 실제 추론할 때에도 pruning된 가중치는 사용되지 않는다. dropout과 유사한 작업으로, 일반화 효과도 존재한다.
- dropout vs pruning
The Lottery Ticket Hypothesis
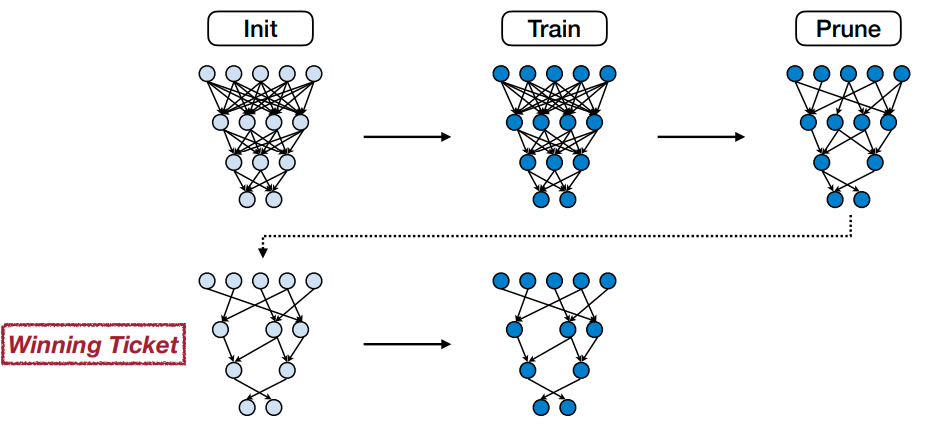
랜덤하게 초기화된 dense 신경망에 대해서, 유사한 accuracy를 갖는 sparse한 신경망이 존재한다는 가설이다. 이 sparse한 신경망을 winning ticket이라 한다.
- 재밌는 내용은 "초기 모델 가중치 랜덤 초기화 -> 학습 -> pruning" 다음에 학습된 가중치를 사용하지 않고, 초기 모델에 가중치를 랜덤 초기화 한 값을 그대로 가져와서 학습해도 pruning하지 않은 모델 만큼 정확도를 얻을 수 있다는 것이다. 이게 학습된 가중치를 사용하는 것보다 안하는게 성능이 좋다는 말은 아니다. 이미 모델은 많은 파라미터를 가지고 있고, 파라미터를 줄일 수 있는 가능성이 많다? 정도로만 봐도 될 것 같다.
- 또한, 이 모델에 반박하는 연구들도 존재하는데, 이 가설이 모든 경우에 해당하지 않을 수 있고, 네트워크가 깊거나, 데이터에 따라 어떠한 경우에는 sparse한 신경망이 제대로 학습되지 않을 수 있다고 지적한다. 실제로 lth에서 사용한 모델은 lenet과 같이 작은 모델을 사용해서 수행되었다.
System Support for Sparsity
EIE: Efficient Inference Engine
weight sparsity + activation sparsity
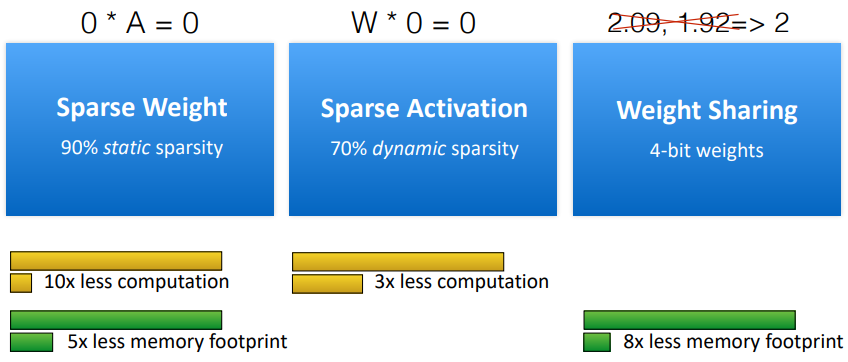
- sparse weight에서는 10x배 연산량이 줄었지만, sparse activation에서는 3x배 연산량이 줄었다. 이는 activation 결과에 따라 유동적으로 적용되는 것이기 때문이다.
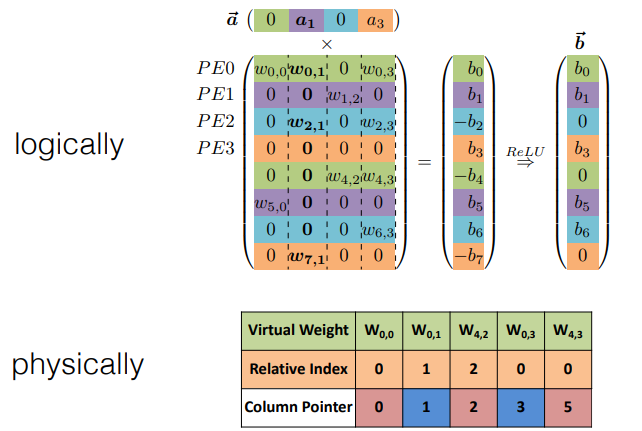
가중치 메모리 저장 방법은 다음과 같다. - virtual weight는 실제 0이 아닌 가중치를 저장하는 것
- relative index는 이전 virtual weight와 현재 virtual weight 사이의 0의 개수
- column pointer는 뭐지?
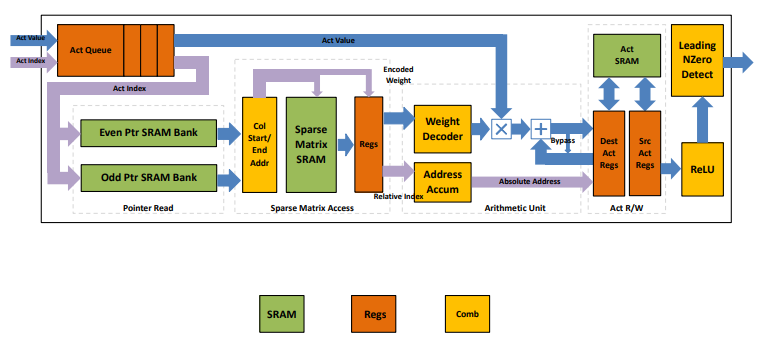
N:M Sparsity
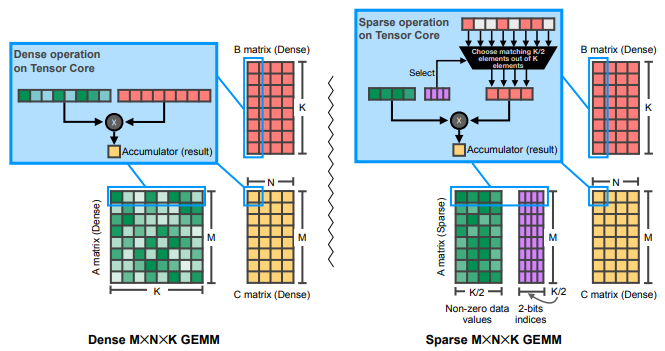
0이 아닌 가중치만 가져오고, 그 index로 activation에서 해당되는 값들만 가져와서 연산을 수행한다. 기존에 비해 1.8배 빠르다.
TorchSparse & PointAcc
