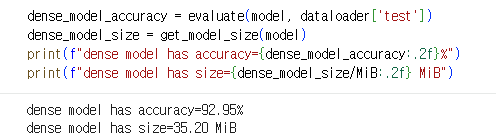
baseline 모델 성능 및 사이즈
VGG모델, CIFAR10 dataset
dense_model_accuracy = evaluate(model, dataloader['test'])
dense_model_size = get_model_size(model)
print(f"dense model has accuracy={dense_model_accuracy:.2f}%")
print(f"dense model has size={dense_model_size/MiB:.2f} MiB")dense model has accuracy=92.95%
dense model has size=35.20 MiB
가중치 분포
def plot_weight_distribution(model, bins=256, count_nonzero_only=False):
fig, axes = plt.subplots(3,3, figsize=(10, 6))
axes = axes.ravel()
plot_index = 0
for name, param in model.named_parameters():
if param.dim() > 1:
ax = axes[plot_index]
if count_nonzero_only:
param_cpu = param.detach().view(-1).cpu()
param_cpu = param_cpu[param_cpu != 0].view(-1)
ax.hist(param_cpu, bins=bins, density=True,
color = 'blue', alpha = 0.5)
else:
ax.hist(param.detach().view(-1).cpu(), bins=bins, density=True,
color = 'blue', alpha = 0.5)
ax.set_xlabel(name)
ax.set_ylabel('density')
plot_index += 1
fig.suptitle('Histogram of Weights')
fig.tight_layout()
fig.subplots_adjust(top=0.925)
plt.show()
plot_weight_distribution(model)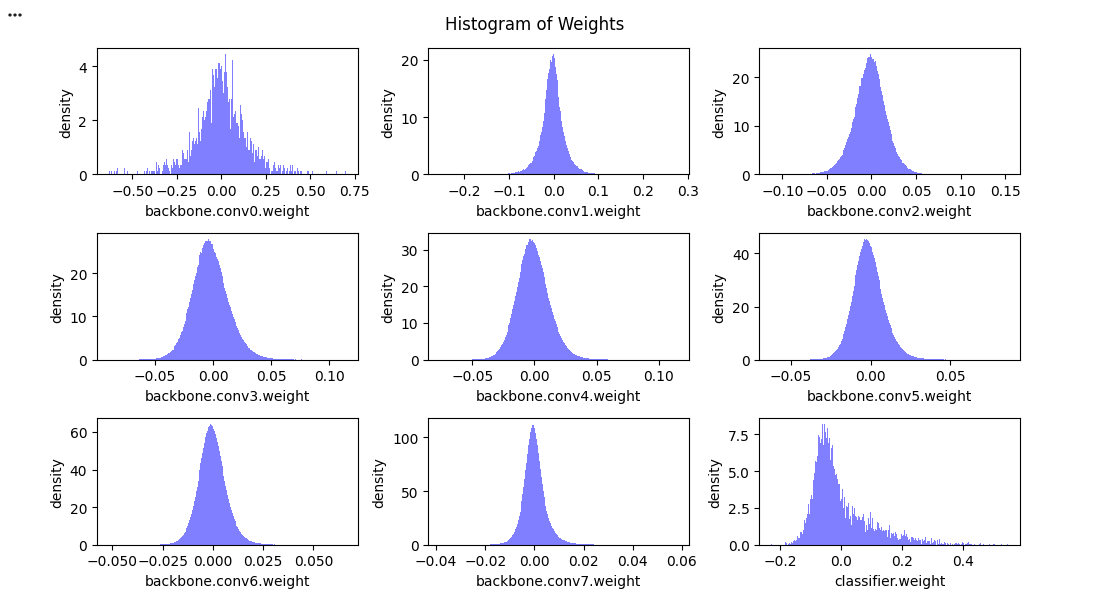
- Question 1) What are the common characteristics of the weight distribution in the different layers?
레이어마다 분포의 폭이나 스케일은 차이가 있지만, 대부분 0을 중심으로 한 정규분포 형태를 보인다. 즉, 0가까울수록 density가 높다.- 추가적으로, 절대값이 큰 가중치는 상대적으로 적게 분포한다.
- Question 2) How do these characteristics help pruning?
0에 가까운 가중치가 많아서, 크기 기반의 pruning을 수행하는 경우, 모델 성능에 큰 영향을 주지 않으면서 많은 수의 가중치를 제거할 수 있다.- 0에 가까운 가중치는 중요도가 낮다고 보는 이유는, 절댓값이 작은 가중치는 결과적으로 출력 변화에 미치는 영향이 작다. 100과 100.0001은 차이가 미미한것처럼 말이다. 그래서 중요도가 낮다고 말하는 것이다.

안녕하세요.