What is Quantization
연속적으로 큰 값인 input을 이산적인 값의 집합으로 변환하는 프로세스임. 이렇게 변환할때에 input과 quantization결과의 차이를 quantization error라고 하며, 이 error를 최소화하는 quantization을 하는 것이 목표이다.
Weight Quantization
- 가중치 quantization
int형 가중치와 fp code book이 존재
int형 가중치로 메모리를 적게 쓰고 있지만, 결국 연산은 fp로 이루어진다.
예시로는 k-means quantization이 있다.
수정중,,,
K-means-based quantization
- 기본 network는 fp 가중치 + fp 연산을 수행한다.
- k-means에서는 int 가중치(label) + fp 코드북(centroid) + fp 연산을 수행한다.
- int 가중치를 통해 storage는 감소하지만, fp 연산이기 때문에 연산량은 그대로임. 그리고, decode 까지 추가됨. (아마도 int label로 centroid를 찾는?거를 말하는 듯?)
- k-means quantization은 말 그대로 k-means clutering 처럼 초기 값에 가까운 값으로 그룹핑하고, 그 오류가 최소가 될때에 값으로 설정하는 것 같다. (각 그룹에 속해있는 가중치의 개수가 다를 수 있음.) 각 가중치는 더이상 fp가 아닌 int값을 갖는다. 각 값은 어떤 centroids에 속하는지를 나타내는 값이다. (강의 예제에서는 그룹을 4개로 나눴기 때문에 4개의 int값만 있으면 됨으로, 각 가중치는 2bit int이다)
- k-means는 보통 layer/channel 단위로 한다. (layer 가 더 압축률은 높지만 정확도가 떨어짐. 채널 단위를 많이 사용함)
- 메모리
- 기존 메모리: 32bit 44 = 512bit=64byte
- k-means이후 메모리: 2bit 44 + 32bit*4 = 160bit=20byte (3.2배 작음)
- N-bit로 quantization하고, 파라미터의 수 M이 2^N보다 훨씬 크다고 가정하면, 32M/(NM+32*2^N) ~= 32/N으로 32/N배로 줄어든다.
- 업데이트
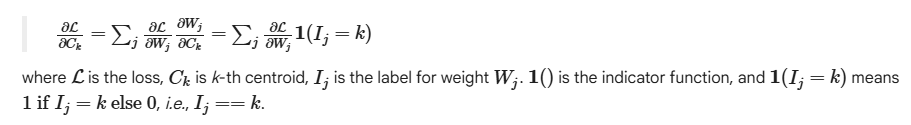
- 이게 보니까, 가중치에 대해서만 별도로 뭘 수행하는게 아니라, quantization한 거로 계속 모델을 학습 시켜서 가장 최적의 centroid를 찾는거임. 결국 QAT였음ㄷㄷ (quantization-aware training)
- 논문에서는 sum을 사용하는데, mean으로 해도 된다고 함. (이 방법말고 개선된 방법은 없을까?? 있을거같은데..)
quantization / pruning 중에 뭐를 먼저 해야할까?
- pruning -> quantization: 이게 낫지 않을까? 왜냐면, quantization을 하고, pruning을 하게 되면, 사용되지 않을 가중치도 고려한 상태로 quantization이 되게 되어서, 필요없는 가중치까지 고려한 상태로 quantization이 되기 때문에,, 정확도가 더 낮을거같은?
- pruning을 먼저 제거해야함!! 중복된 불필요한 가중치를 먼저 제거하는게 좋음. 이거를 먼저 줄이면, quntization error도 줄어들 수 있음!
기타
- ? 크기 기반의 pruning을 하게 되면, 미세 조정? 이 어려울 것 같은데, 그래도 크기 기반의 pruning이 성능이 제일 좋은건가? 아니면 그냥 제일 단순할뿐?
가성비가 제일 좋기 때문ㅋㅋ - ? 초기 centroid를 정하는게 안나왔는데, k-means clustering이랑 똑같은가? (lab에서 확인 필요)
- ? FC lasyer랑 Conv layer에서의 bit 가 다른데, 왜지? 그리고 transformer에서도 Conv layer랑 똑같은 bit에서 좋은감?
FC layer는 파라미터 수가 엄청 많지만, 그만큼 모두 연결되어 있기 때문에 redundancy가 크다. 반면, Conv layer는 파라미터 수는 적지만 특징을 추출하는 layer이기 때문에 민감함.

안녕하세요.