Symmetric vs Asymmetric
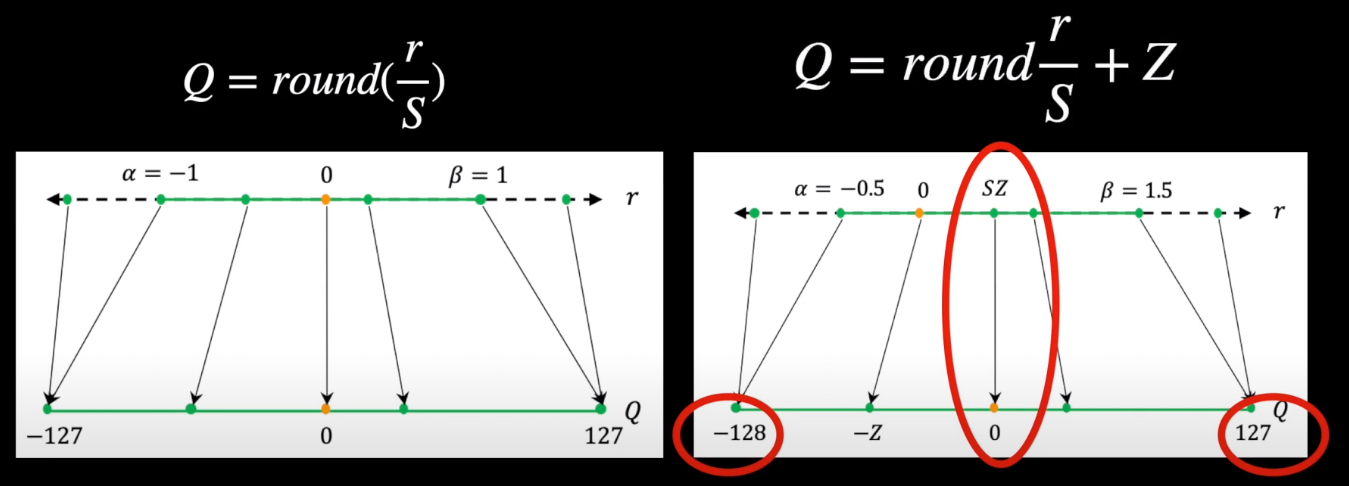
핵심은 Zero-point(Z) 사용 여부이다!
어제 Affine Quantization에서와 같이 Z를 사용하는 방법이 Asymmetric(비대칭) 방법이다.
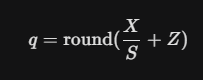
반면 symmetric(대칭) 방법에서는 Z를 0으로 두고, |X|_max, 즉, 최대 절대값이 뭔지 찾는다. 그리고 ,X_max = |X|_max, X_min = -|X|_max로 설정한다. (예를 들어, -80~120 데이터 인 경우, X_max=120, X_min=-120) 이렇게 하게 되면,
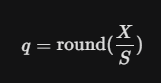
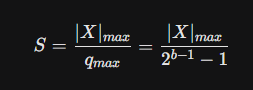
q_min=round(X_min/S)=round(-120/(120/7))=round(-7)=-7
q_max=round(X_max/S)=round(120/(120/7))=round(7)=7
위와 같이, z_min이 -7이 되게 되는데, -8은 사용하지 못하게 된다.
하지만, q가 범위를 넘는 경우가 발생할 수가 있다.
- 반올림 오차
q=round(7.5) 이렇게 되는 경우, 8이 되어 overflow가 발생하게 된다. - 참고했던 데이터의 범위를 넘는 새로운 값
기존에는 -120~120만 있었는데, 새로운 데이터에 -130이 들어올 수가 있다.
이를 해결하기 위해 clip을 사용한다. clip은 q의 최대, 최소값을 제한해주는 연산이다.
최종 대칭 quantization 수식은 다음과 같다.
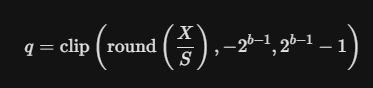
- b: 비트 수 (예: INT4면 4, INT8이면 8)
BitsAndBytesConfig
여기서 사용하는 방식은 Symmetric이다. Symmetric은 Z를 구하지 않기 때문에 속도 측면에서 더 빠르기 때문에 사용한다. 근데, 대칭 방식은 이상치가 하나만 있어도 S가 커져버려서, 나머지 멀쩡한 데이터들이 전부 0으로 뭉개버린다. 이를 해결하기 위해 Block-wise와 NF4를 사용하는데, 이거는 내일 공부할 예정이다!
(앞에서 clip을 말했는데, 이상치를 얘가 해결해주진 못한다. 왜냐면, S를 구할때에 이상치가 있어버리면, S가 업청 큰값이 되어버리고, 0에 가까운 값들은 분별력이 사라져 버린다. 그래서 quantization의 S,Z를 구하는 초기 데이터도 중요하다. 근데, 가중치만 quantization하는 경우는 사실 무관하다! 왜냐면 가중치는 이미 정해져있는 값이기 때문!)
참고사이트
https://www.ai-bites.net/model-quantization-in-deep-learning/
