Lightweight Challenge
1.[경량화 챌린지] 1일차

Hugging Face Hub이란?AI 관련 모델, 데이터셋, 데모를 공유할 수 있는 오픈소스 플랫폼.transformer 기반의 모델이 주를 이룸.Python 가상환경 생성pip install transformers torch accelerate bitsandbyte
2.[경량화 챌린지] 2일차
LLaMA3 모델이란?Meta에서 개발한 오픈 소스 대규모 언어 모델 (24년 4월)오픈소스로 되어 있어서, 최적화 테스트 하기 좋음.학습 데이터의 95%가 영어로 되어 있음Hugging Face 인증회원가입 (https://huggingface.co/join
3.[경량화 챌린지] 3일차
Tokenizer AI모델은 "안녕하세요" 단어를 이해하지 못함. 숫자만 이해할 수 있음. 따라서, 언어를 숫자로 변환해주는 도구를 tokenizer라고 함. tokenizer에서는 크게 2가지의 단계가 존재하는데, 먼저 "I am a student" 라는 문장이 있을
4.[경량화 챌린지] 4일차
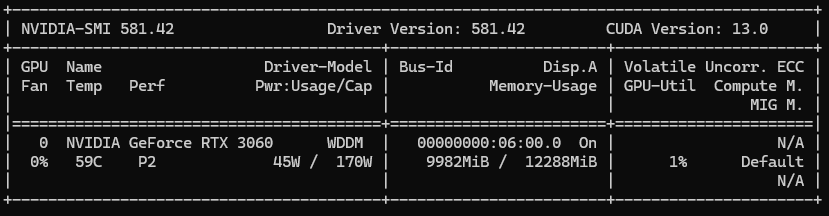
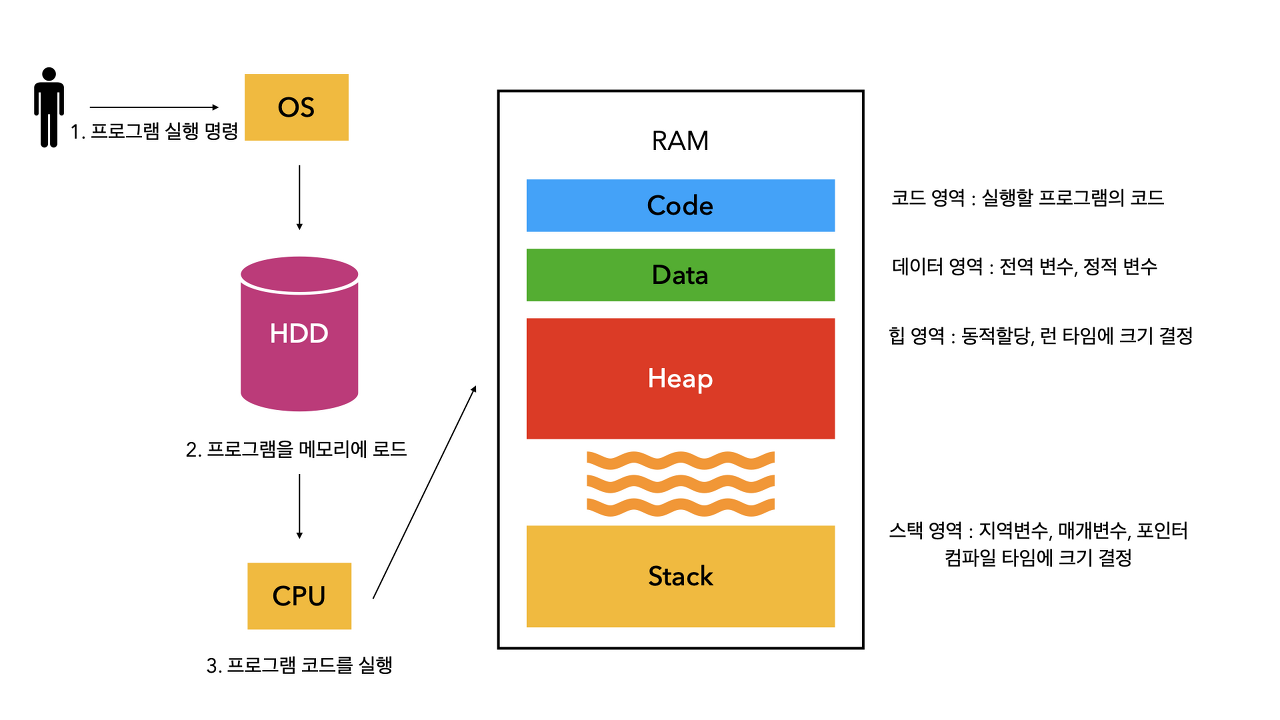
VCRM (GPU 메모리)GPU가 직접적으로 사용하는 메모리 영역AI모델을 돌리는 동안, 아래와 같은 시퀀스가 진행됨 1\. model.from_pretrained()실행 -> 하드디스크에 있던 모델을 RAM에 로드함. 2\. model.to("cuda") -> 모델을
5.[경량화 챌린지] 5일차
model.generate()torch에서는 추론을 하려면, output = model(input) 이런식이다. 근데, transformers에서는 model.generate()라는 별도의 함수를 사용한다 (Hugging Face 전용의 편의 함수).왜냐면, model
6. [경량화 챌린지] 6일차
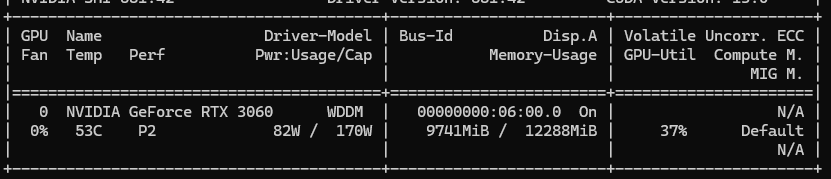
model Warm-up 모델을 처음 추론할때에 warm up이 존재한다. 근데 이미 모델은 VRAM에 올라가 있는데, 왜 처음에만 오래걸리는 걸까? 그리고 딱 첫번째만 제외하면 되는걸까? 첫 추론 시, 내부적으로는 아래와 같은 동작이 이루어진다. 메모리 할당
7.[경량화 챌린지] 7일차 - VRAM memory 측정
Peak Memory모델이 순간적으로 최대로 사용한 VRAMPeak Memory때 OOM가 발생함.근데, 이미 첫 실행때, 중간 결과를 저장할 공간까지 다 할당된다고 했는데, peak memory때문에 oom이 발생하는 거는 첫번째 실행때만 발생하는 건가 했는데, ll
8.[경량화 챌린지] 8일차 - Perplexity
Perplexity (PPL)모델의 헷갈림 점수이다. confidence의 역수라고 생각하면 될것같다. PPL이 높으면, 엄청 헷갈리는거, 낮으면 안헷갈리는거! 정답으로 고민하고 있는 후보의 수? 라고 생각하면 됨. 그래서 PPL은 최소가 1이고, 최대는 무한대이다.
9.[경량화 챌린지] 9일차 - FP16 모델 측정
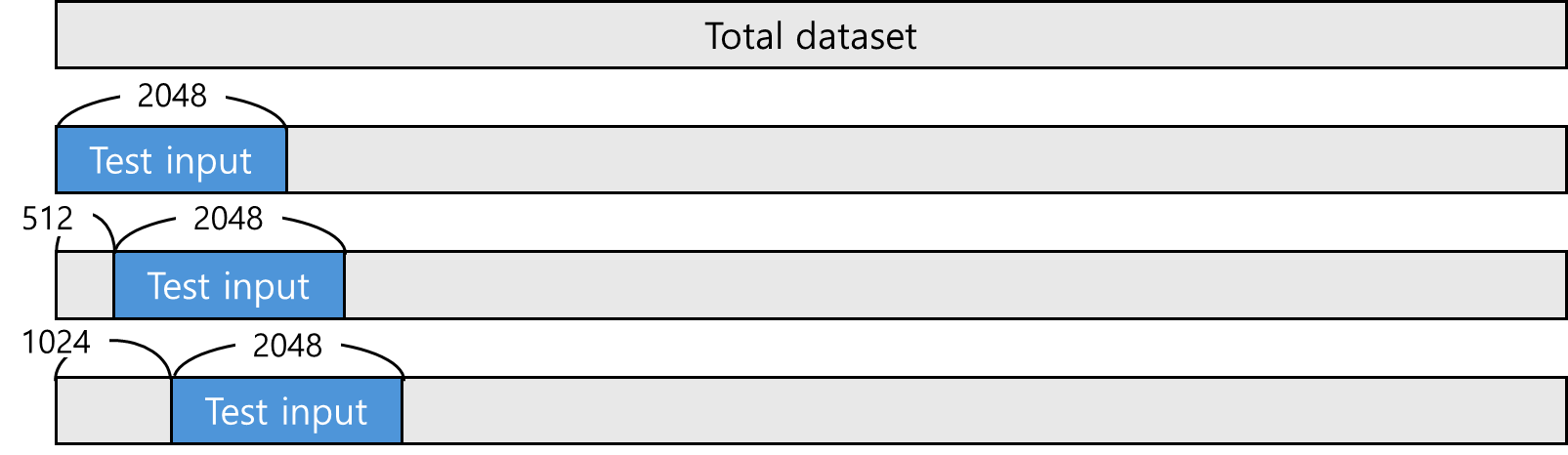
원본 모델 PPL 측정 모델 로드 시, torch_dtype = torch.float16으로 설정함. 실험 결과 beomi/Llama-3-Open-Ko-8B 모델로 테스트 한 결과이고 PPL이 6.86이였다. (보통 10PPL이하면, 좋은 모델이라고 한다.) 이 값을 기준으로 경량화를 했을때, 속도/성능이 얼마나 변화되는지 확인해보자. 시간이 5...
10.[경량화 챌린지] 10일차 - Affine Quantization
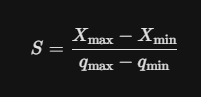
Affine Quantization X: 실테 데이터 q: quantization된 목표 데이터 1. Scale(S) 구하기 X의 전체 범위를 q의 칸수로 나눈다. (예를 들어, X의 최대가 80, 최소가 -120이고, q가 uint4라면, Xmax=80, Xmin=-
11.[경량화 챌린지] 11일차 - Asymmetric vs Symmetric
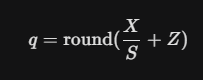
핵심은 Zero-point(Z) 사용 여부이다!어제 Affine Quantization에서와 같이 Z를 사용하는 방법이 Asymmetric(비대칭) 방법이다.반면 symmetric(대칭) 방법에서는 Z를 0으로 두고, |X|\_max, 즉, 최대 절대값이 뭔지 찾는다.
12.[경량화 챌린지] 12일차 - Block-wise Quantization
Quantization을 간단히 공부한적은 있지만, Block-wise Quantization에 대해서는 처음 들었다.어제 Quantization을 공부할때 당시에 나머지는 -10~10에 몰려있는데, 하나의 값만 1000에 있는 경우, 나머지 값들이 분별력이 없어진다는
13.[경량화 챌린지] 13일차 - Normal Float 4
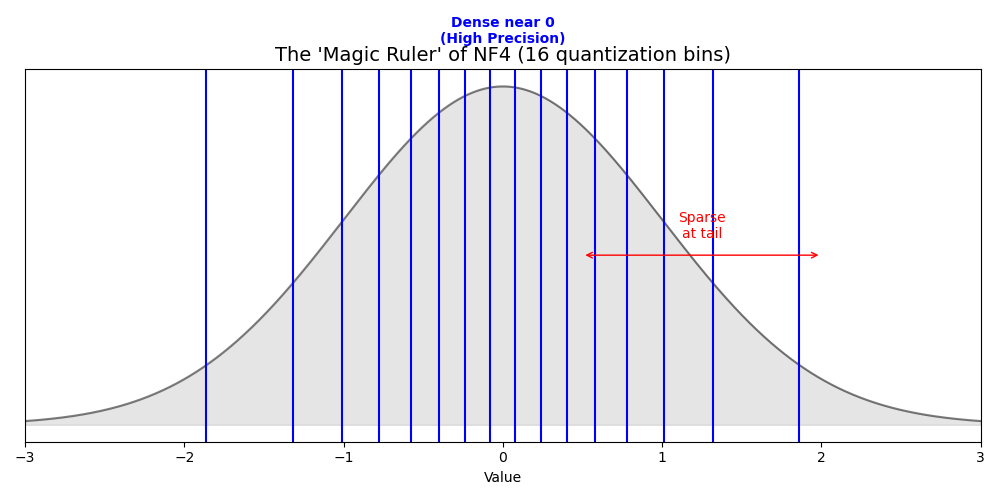
일반적으로 학습된 AI 모델의 가중치는 0을 중심으로 한 정규분포를 따른다. 근데, 이거를 그냥 동일한 간격으로 quantization하게 되면, 0에 가까운 값들은 분별력없이 같은 값으로 매핑되게 된다. 하지만, NF4는 아래 그림과 같이 데이터가 몰려있는 곳은 촘촘
14.[경량화 챌린지] 14일차 - Double Quantization
Block wise Quantization을 하게 되는 경우, 원본 가중치의 메모리는 줄어들지만, S는 그만큼 늘어나게 된다.가중치를 4비트로 양자화 하더라도 S는 fp32로, 가중치 대비 12.5% (=32/(64\*4))나 차지하게 된다.이 오버헤드를 줄이기 위해
15.[경량화 챌린지] 15일차 - PagedAttention
PagedAttention vLLM 같은 최신 엔진들은 같은 GPU에서도 10~20배 더 많은 처리를 한다. 어떻게 이게 가능한걸까? 기존에는 input이 어느정도 길이로 들어올지 모르니, 메모리에 input 영역을 최대치로 예약해 놓는다. 실제로는 "안녕" 한단어가
16.[경량화 챌린지] 16일차 - affine quantization 구현
기존 이론만으로 공부했던 양자화 공식 $q = round(X/S+Z)$ 을 실제 pytorch를 사용해 quantization하는 코드를 구현해보았다.핵심 로직은 다음과 같다.1\. Affine mapping: X를 quantization을 위한 좌표계로 변환2\. R
17.[경량화 챌린지] 17일차 - DeQuantization
quantization은 fp32 -> int8로 압축하는 과정이고, dequantizatino은 압축된 int8 -> fp32로 다시 복원하는 과정이다. 예상했다싶이, dequantization값과 원본은 완전히 같을 가능성이 매우 낮다.기존 quantization
18.[경량화 챌린지] 18일차 - DeQuantization 구현
어제 dequantization을 개념으로만 공부했는데, 오늘은 실제 dequantization 코드를 구현해봤다.dequantization하고 난 이후에 원본값과 얼마나 달라지는지 확인한다.quantize 함수는 16일차에 코드 있음.혹시, quantization e
19.[경량화 챌린지] 19일차 - nn.Linear
양자화 코드를 직접 구현해보기 전에, 먼저 정확히 알아야함! * 만약, (1024,512) 크기의 weight가 있다면, 이걸 int8로 양자화 하기 위한 Scale Factor의 shape은 뭘까?* 이거에 답변할 수 있어야, 정확히 이해한거임! nn.Linear
20.[경량화 챌린지] 20일차 - quantization layer 구현
구현 도중 겪은 문제는 아래와 같다.🚨 문제 1: quantization 대상 실수이전에 이론적으로 quantization을 배울때는 그냥 data가 들어오면, quantization하면 되겠지 생각하고, forward에서도 그냥 들어온 data에 대해서, param
21.[다시경량화] 자료형
again&again... 또다시 처음부터다생각하고 행동하자=== datatype size check ===int size: 4double size: 8char size: 1=== memory address check ===int address: 0x61ff0cdoub
22.[다시경량화] cudaGetDeviceProperties
오늘은 기본적으로 환경설정 하면서, 간단하게 gpu 하드웨어 속성을 확인한다.Device count: 1\---- Device 0 ----Name: NVIDIA GeForce RTX 3060Compute capability: 8.6Global memory: 12.00