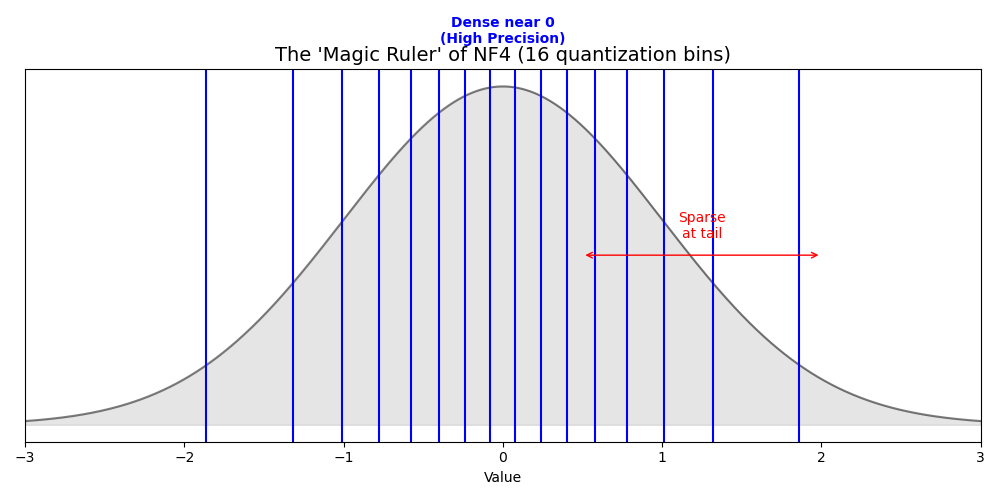
Normal Float 4
일반적으로 학습된 AI 모델의 가중치는 0을 중심으로 한 정규분포를 따른다. 근데, 이거를 그냥 동일한 간격으로 quantization하게 되면, 0에 가까운 값들은 분별력없이 같은 값으로 매핑되게 된다. 하지만, NF4는 아래 그림과 같이 데이터가 몰려있는 곳은 촘촘하게, 몰려있지 않는 영역은 헐렁하게? 구간을 나누는 방식이다.
Roofline model
컴퓨팅 성능은 크게 메모리 대역폭과 연산능력에 영향을 받는데, 이를 하나의 그래프에 시각화한 것이 roofline model이다.
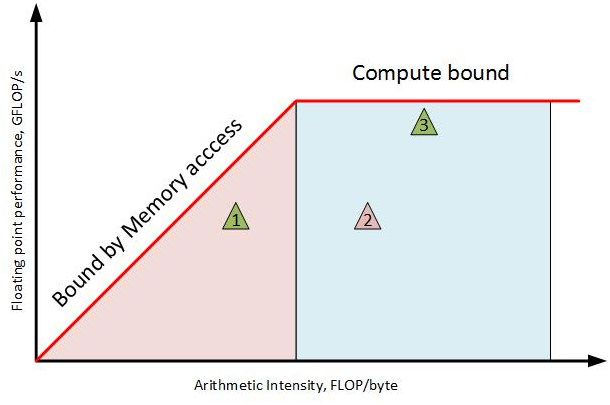
x축은 데이터 대비 연산량, y축은 부동소수점 연산 성능이다. 데이터 대비 연산량이 적을 때에는 메모리 대역폭에 따라 성능 제약이 있고, 연산량이 일정 수준을 넘으면 연산능력 제약이 발생한다. 즉, 너무 데이터 대비 연산량이 적으면 오히려 메모리 가져오는데, 시간이 오래걸려서 연산능력을 100%사용을 못하고, 데이터 대비 연산량이 많으면 메모리에서 빠르게 가져와도 연산능력을 100%써도 부족한것이다.

안녕하세요.