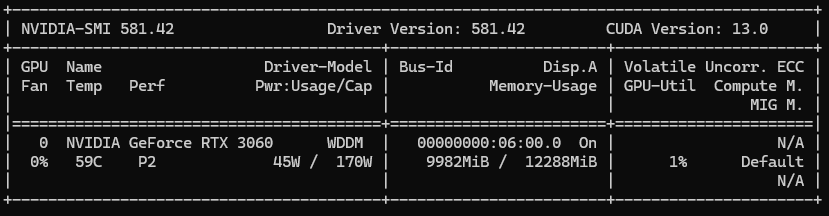
-
VCRM (GPU 메모리)
GPU가 직접적으로 사용하는 메모리 영역
AI모델을 돌리는 동안, 아래와 같은 시퀀스가 진행됨
1. model.from_pretrained()실행 -> 하드디스크에 있던 모델을 RAM에 로드함.
2. model.to("cuda") -> 모델을 VRAM에 로드함.
3. input = tokenize("안녕").to("cuda") -> input 데이터를 VRAM에 로드함.
4. GPU가 모델로 input을 추론함. 이때, 임시 메모리가 추가적으로 VRAM에 저장됨 (ex. activation map, kv cache)
하지만, VRAM은 비싸고, 작기 때문에 모델크기보다 VRAM이 작은 경우(EX. LLM모델)가 발생할 수 있음. 이는 경량화를 통해 해결해야함.- 종류: GDDR / HBM (GDDR보다 높은 대역폭을 제공함)
-
대역폭
대역폭이 높다 = 한번에 최대로 전송할 수 있는 데이터의 양이 많다
동일 시간 당, 옮기는 데이터의 양이 많다 라고 생각하면 됨.
GDDR은 대역폭은 낮지만, 전송 속도가 높음 (64차선에 300km/h) -> 총 데이터=19,200
HBM은 전송속도는 낮지만, 대역폭이 높음. (1024차선에 60km/h) -> 총 데이터=61,440
즉, HBM이 대역폭이 더 높음. -
모델 VRAM 로드
AutoModelForCausalLM.from_pretrained(...) 코드로 모델을 로드. (VRAM이 부족하면 load_in_8bit=True 옵션으로 임시 해결)
나는 VRAM이 12GB이고, 모델은 15GB 이다.
결론? VRAM크기에 따라서, 모델 사이즈도 정해진다. + quantization을 통해 로드가 불가능하던 모델도 가능하게끔 해준다.
- 1단계: FP16 결과
모드: 원본 (FP16) - 강제 GPU 로드 시도
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████| 4/4 [00:35<00:00, 8.98s/it]
🔥 CPU에서 GPU로 강제 이동!
💥 에러 발생! (실패)- 이유: CUDA out of memory. Tried to allocate 112.00 MiB. GPU 0 has a total capacity of 12.00 GiB of which 0 bytes is free. Of the allocated memory 11.84 GiB is allocated by PyTorch, and 109.58 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
- 2단계: INT8 결과 (load_in_8bit=True)
모드: 8-bit 양자화 (INT8)
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████| 4/4 [00:38<00:00, 9.63s/it]
🎉 성공! 모델이 로드되었습니다.
모델 위치: cuda:0
VRAM 사용량: 8.46 GB - 3단계: INT4 결과
모드: 4-bit 양자화 (INT4)
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████| 4/4 [00:17<00:00, 4.45s/it]
🎉 성공! 모델이 로드되었습니다.
모델 위치: cuda:0
VRAM 사용량: 5.64 GB
