- model Warm-up
모델을 처음 추론할때에 warm up이 존재한다. 근데 이미 모델은 VRAM에 올라가 있는데, 왜 처음에만 오래걸리는 걸까?
그리고 딱 첫번째만 제외하면 되는걸까?
첫 추론 시, 내부적으로는 아래와 같은 동작이 이루어진다.- 메모리 할당
VRAM에는 모델을 올라가 있지만, 모델의 중간 결과인 activation map이나 KV cache같은 값을 저장할 VRAM 영역이 할당되어 있지 않다. 이 영역을 할당하는 과정이 첫번째 추론때 이루어진다.
이후부터는 미리 할당된 영역을 사용한다. - 커널 컴파일 및 오토튜닝
말 그대로 gpu위에서 실행되는 최적의 함수를 선택하는 과정이다.
예를들어, GPU 제조사에는 내부적으로 행렬곱셈을 하는 방법을 여러가지를 구현해 놓았다. (메모리는 적고 속도는 느린방법, 메모리가 많고 속도가 빠른 방법, 작은 행렬에 유리한 방법 등)
그러면 특정 size에서 어떤 방법이 제일 빠른지 첫번째에 확인하고 기록해 놓는다. (근데, llm 특성상, input size가 바뀔수 있음.그래서 고정된 길이로 맞춰서 넣기도한다! 근데, 낭비가 심해서 안그러는 추세임..)
이후부터는 미리 기록되어 있는 방법을 사용한다. - lazy loading
파이썬과 딥러닝 라이브러리는 효율성을 위해 실제 실행할때까지는 로드되지 않는 특징이 있다.
자잘한 옵션, 설정들이 첫번째 실행때에 실행된다.
이후부터는 미리 세팅된 설정으로 사용한다. - GPU 클럭 부스트
첫번째에서 이미 앞에 3개와 같은 소프트웨어 준비는 끝난다. 하지만, 하드웨어는 클럭 속도를 최고 속도까지 높여야 하는데, 첫번째 실행 안에 최고 속도까지 올라가지 않을 수 있다.
따라서, 3~5번째 이후부터 제대로된 실행 속도를 측정할 수 있다.
- 메모리 할당
-
model.generate() 실행 코드 정리
import torch import time from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig model_id = "meta-llama/Meta-Llama-3-8B" print("모델 로드 (int8)\n") bnb_config = BitsAndBytesConfig(load_in_8bit=True)- 여기서 BitsAndByesConfig가 뭐냐면, 모델 압축을 위한 옵션 설정이다. Automodel을 통해 모델을 불러올때, 모델을 이렇게 압축해서 VRAM에 올려줘! 라고 설정하는 부분이다. 옵션은 다음과 같다.
- 모델 로드 타입
모델을 몇비트로 로드할지 설정.
load_in_8bit/load_in_4bit =True - 8비트 전용 세부 설정
- cpu 사용 허용 옵션: llm_int8_enable_fp32_cpu_offload (vram이 모자랄때 일부를 cpu ram으로 넘기는 것을 허용하는 옵션) 이거를 true로 하면, 추론할때, oom가 발생하지 않고, 느리게라도 추론이 됨!
- 이상치 임계값 설정: llm_int8_threshold (숫자의 크기가 특정값을 넘어가면 압축하지 않고 원본으로 유지하는 옵션)
- 4비트 전용 세부 설정
- 압축 데이터 타입: bnb_4bit_quant_type (quantize할때, 그냥 동일한 간격: fp4 / 혹은 분포에 따라 간격 설정: nf4 을 하냐의 차이임. nf4가 일반적으로 더 성능이 좋음)
- 이중 압축: bnb_4bit_use_double_quant
- 계산용 데이터 타입: bnb_4bit_compute_dtype (설정 안하면 float32로 됨! 보통 float16으로 설정함)
- 모델 로드 타입
tokenizer = AutoTokenizer.from_pretrained(model_id) model = AutoModelForCausalLM.from_pretrained( model_id, quantization_config = bnb_config, device_map = "auto" ) print("모델 로드 완료\n")- AutoTokenizer, AutoModelForCausalLM 이거는 각각 토크나이저, 모델을 담을 수 있는 깡통이라고 생각하면 된다.
- autodevice_map은 남은 VRAM에 따라, 모델을 로드할 영역을 결정한다. 근데 이 옵션은 enable_fp32_cpu_offload=True 이 cpu에 갈수 있게끔 설정이 되어 잇는 경우에만 유의미하다. 8bit 한정?
# input data text ="Hello, please introduce yourself briefly." print(f"질문: {text}") # token화 -> VRAM으로 이동 inputs = tokenizer(text, return_tensors="pt").to("cuda")- return_tensors="pt"
결과물을 '파이토치 텐서(PyTorch Tensor)' 형식으로 포장해서 주도록 설정하는 옵션- 옵션을 사용하는 경우
inputs = tokenizer("Hello")
#결과: {'input_ids': [128000, 9906]} - 옵션을 안 사용하는 경우
inputs = tokenizer("Hello", return_tensors="pt")
#결과: {'input_ids': tensor([[128000, 9906]])}
- 옵션을 사용하는 경우
# 추론 print("답변 생성 시작\n") start_time = time.time() outputs = model.generate( **inputs, max_new_tokens=50, pad_token_id = tokenizer.eos_token_id ) end_time = time.time() duration = end_time - start_time- inputs 딕셔너리 가변인자
inputs 변수는 {'input_ids': [...], 'attention_mask': [...]} 처럼 생긴 딕셔너리(Dictionary)다. 따라서, 딕셔너리 가변인자를 input으로 넣어주는 것이다. - max_new_tokens=50
값을 설정한다고 해서, 추론 결과에 영향을 주진 않음. 즉, "안녕하세요. 제 이름은" 여기서 끝날 수 있는것 뿐! 강제종료하는 옵션임. - pad_token_id = tokenizer.eos_token_id
패딩이 필요하면, 문장 끝 기호를 패딩으로 쓰는 옵션 (앞에서 말했던 오토튜닝때문에 필요할 수 있음. 혹은 여러 사용자가 있는 서버에서는 동시에 배치 처리하기 위해서 패딩처리를 함.)
input_len = inputs.input_ids.shape[1] total_len = outputs.shape[1] generated_tokens= total_len - input_len tps = generated_tokens / duration print(f"걸린 시간: {duration:.2f}초") print(f"생성된 토큰: {generated_tokens}개") print(f"속도 (TPS): {tps:.2f} tokens/sec\n") decoded_text = tokenizer.decode(outputs[0], skip_special_tokens=True) print(f"AI 답변:\n{decoded_text}")- skip_special_tokens
문장 시작 끝에 있는 기호를 없애는 옵션
- 여기서 BitsAndByesConfig가 뭐냐면, 모델 압축을 위한 옵션 설정이다. Automodel을 통해 모델을 불러올때, 모델을 이렇게 압축해서 VRAM에 올려줘! 라고 설정하는 부분이다. 옵션은 다음과 같다.
-
model.generate() 여러번 호출 및 시간 측정
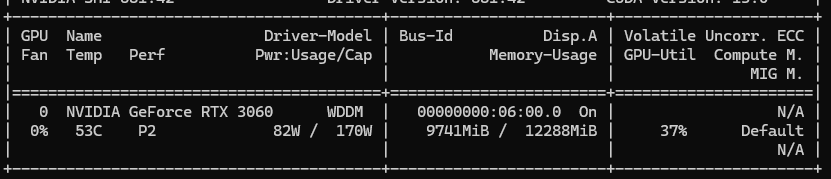
근데 확인해보니까, gpu 사용률이 max로 안올라가고 있다. 근데 P2가 찍혀있는것은 gpu의 rpm은 이미 최고 속도로 돌고 있다는 것을 의미한다. 이는, 데이터가 오는데, 기다리는 시간이 60%라는 것을 의미한다. Memory-Bound (메모리 대역폭 한계로 인한 병목)으로 인해 발생한 현상이다.
이는 구조적으로도 해결할 수 있다! llm 생성은 결국 추론할때에는 순차적으로 추론하기 때문에, 연산 밀도가 매우 낮다. 이를 해결하기 위해 아래와 같은 기술들이 있다. 나중에 꼭 공부하자!
- Speculative Decoding (추측형 디코딩)
- KV Cache 최적화 (PagedAttention, vLLM)
- Flash Attention-
추론 시간
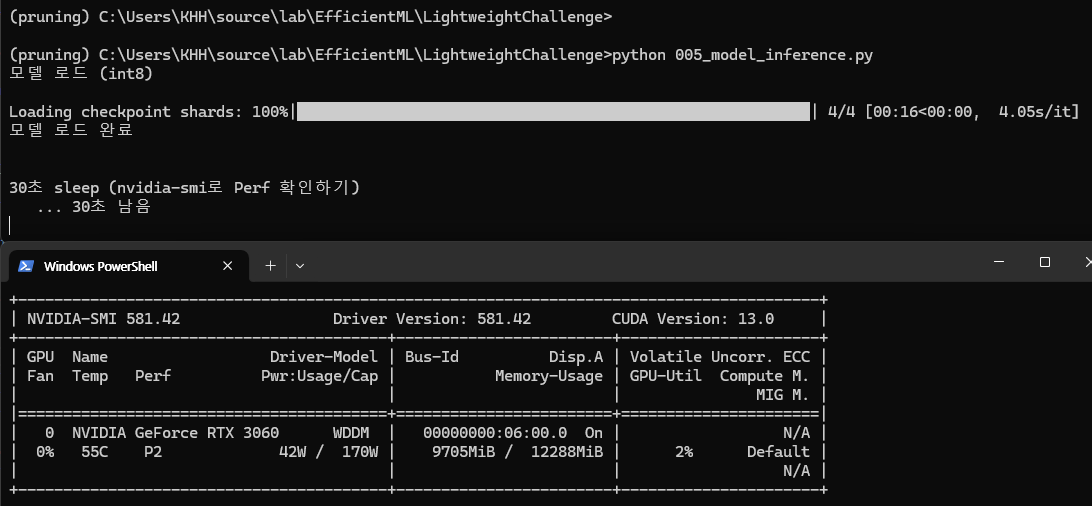
웜업을 확인하고 싶었는데, 모델 로드할때 이미 gpu가 활성화 되어 있는것을 확인했다. (P2)
그래서, 60초 대기하고, 실행해봄!!
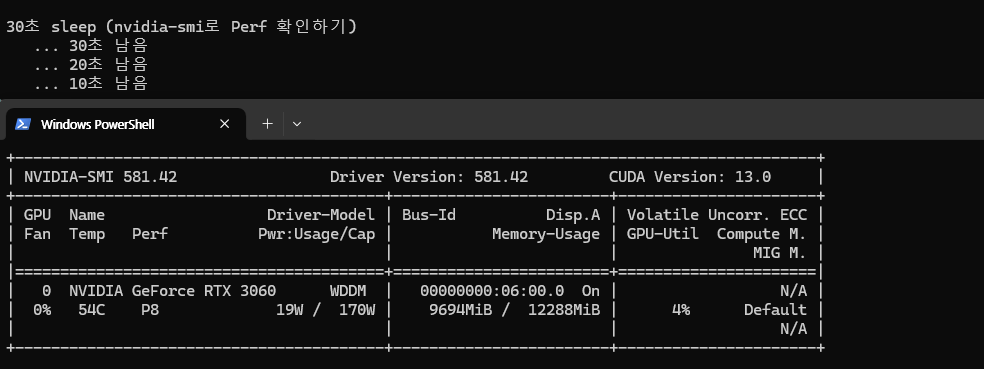
P8까지 떨어짐! 하지만, 결론적으로는 별차이ㅣ가 없었음.ㅠ -
추론속도
1번째 추론 속도 (TPS): 7.63 tokens/sec
2번째 추론 속도 (TPS): 6.94 tokens/sec (최저)
3번째 추론 속도 (TPS): 8.20 tokens/sec
4번째 추론 속도 (TPS): 8.76 tokens/sec (최고)
5번째 추론 속도 (TPS): 7.61 tokens/sec
6번째 추론 속도 (TPS): 7.31 tokens/sec
7번째 추론 속도 (TPS): 8.31 tokens/sec
8번째 추론 속도 (TPS): 7.09 tokens/sec
9번째 추론 속도 (TPS): 7.69 tokens/sec
10번째 추론 속도 (TPS): 8.58 tokens/sec -
전체 로그
(pruning) C:\Users\KHH\source\lab\EfficientML\LightweightChallenge>python 005_model_inference.py
모델 로드 (int8)Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████| 4/4 [00:16<00:00, 4.05s/it]
모델 로드 완료60초 sleep (nvidia-smi로 Perf 확인하기)
... 60초 남음
... 50초 남음
... 40초 남음
... 30초 남음
... 20초 남음
... 10초 남음
1번째 답변 생성 시작
C:\Users\KHH.conda\envs\pruning\lib\site-packages\transformers\models\llama\modeling_llama.py:602: UserWarning: 1Torch was not compiled with flash attention. (Triggered internally at C:\actions-runner_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\native\transformers\cuda\sdp_utils.cpp:555.)
attn_output = torch.nn.functional.scaled_dot_product_attention(
걸린 시간: 6.56초
생성된 토큰: 50개
1번째 추론 속도 (TPS): 7.63 tokens/sec
AI 답변:Hello, please introduce yourself briefly. What are you working on at the moment?
My name is Paulina, I am 27 years old and I am originally from Poland. I am currently working as a freelance graphic designer in Berlin. I am working on a project called, The Art2번째 답변 생성 시작
걸린 시간: 7.21초
생성된 토큰: 50개
2번째 추론 속도 (TPS): 6.94 tokens/sec
AI 답변:Hello, please introduce yourself briefly. What is your role at the University of Hohenheim?
I am a professor of Agricultural Economics and Management at the University of Hohenheim. I am also the director of the Centre for Development Research (ZEF) at the University of Bonn3번째 답변 생성 시작
걸린 시간: 6.10초
생성된 토큰: 50개
3번째 추론 속도 (TPS): 8.20 tokens/sec
AI 답변:Hello, please introduce yourself briefly. I am a professional musician and composer. I have been playing in bands for many years and have also been composing for many years. I have a very wide range of experience, having played in many different bands, and have a very diverse musical background.4번째 답변 생성 시작
걸린 시간: 5.71초
생성된 토큰: 50개
4번째 추론 속도 (TPS): 8.76 tokens/sec
AI 답변:Hello, please introduce yourself briefly. What are you doing at the moment?
I’m a 24 year old photographer based in London. I work for a variety of publications and clients, but my main focus is on my personal projects. I’m currently working on a project called ‘The5번째 답변 생성 시작
걸린 시간: 6.57초
생성된 토큰: 50개
5번째 추론 속도 (TPS): 7.61 tokens/sec
AI 답변:Hello, please introduce yourself briefly. What is your name, what do you do and where are you from?
My name is Alex and I am 24 years old. I am from Germany and I am a photographer.
How did you get into photography? What was the trigger?
I6번째 답변 생성 시작
걸린 시간: 6.84초
생성된 토큰: 50개
6번째 추론 속도 (TPS): 7.31 tokens/sec
AI 답변:Hello, please introduce yourself briefly. My name is Thomas Biermann. I live in the state of Baden-Württemberg, in the district of Heidenheim, in the city of Herbrechtingen, where I was born and raised. I am a7번째 답변 생성 시작
걸린 시간: 6.02초
생성된 토큰: 50개
7번째 추론 속도 (TPS): 8.31 tokens/sec
AI 답변:Hello, please introduce yourself briefly. What is your name, where do you come from and what do you do?
I’m Yannick, 26 years old, born and raised in the south of Germany. I’m a freelance photographer and I’m currently living in Berlin.
What8번째 답변 생성 시작
걸린 시간: 7.05초
생성된 토큰: 50개
8번째 추론 속도 (TPS): 7.09 tokens/sec
AI 답변:Hello, please introduce yourself briefly. Who are you, what do you do and what is your background?
I am a 24 year old woman who lives in Berlin, Germany. I studied social sciences and political science and now work as a social worker in a refugee shelter. I am9번째 답변 생성 시작
걸린 시간: 6.50초
생성된 토큰: 50개
9번째 추론 속도 (TPS): 7.69 tokens/sec
AI 답변:Hello, please introduce yourself briefly. Who are you, what do you do, what do you like to do?
I am a 26-year-old software developer. I live in Berlin and work at a tech company in the city. I like to play video games, read, write10번째 답변 생성 시작
걸린 시간: 5.83초
생성된 토큰: 50개
10번째 추론 속도 (TPS): 8.58 tokens/sec
AI 답변:Hello, please introduce yourself briefly. Who are you?
My name is David H. W. van der Wolk, I am 43 years old and live in the Netherlands. I am a full-time photographer. I have been working as a photographer since 2002, and since
메모리를 비우기
청소 완료! VRAM clear
-
