데이터 모델링
1. 데이터 모델링이란?
업무 내용을 분석하여 이해하고 표기범에 의해 표현하는 것
2. 데이터 모델링 순서 절차
1) 업무 파악(요구사항 수집 및 분석)
무엇을 만들어야하는지 파악해 본다.
2) 개념적 데이터 모델링
일의 데이터 간의 관계를 구상하고 ERD 다이어그램을 생성
피터첸 표 표기법

3) 논리적 데이터 모델링
구체화된 업무 중심의 데이터 모델을 만들어 낸다. 이 단계에성 업무에 대한 Key, 속성, 관계 등을 표시하며 정규화 활동을 수행한다. 정규화는 데이터 모델의 일관성을 확보하고 중복을 제거하여 신뢰성 있는 데이터 구조를 얻는데 목적이 있다.
개념적 ERD 다이어 그램을 정보 공학 표기법인 테이블 형식으로 표시한다면 다음과 같다.
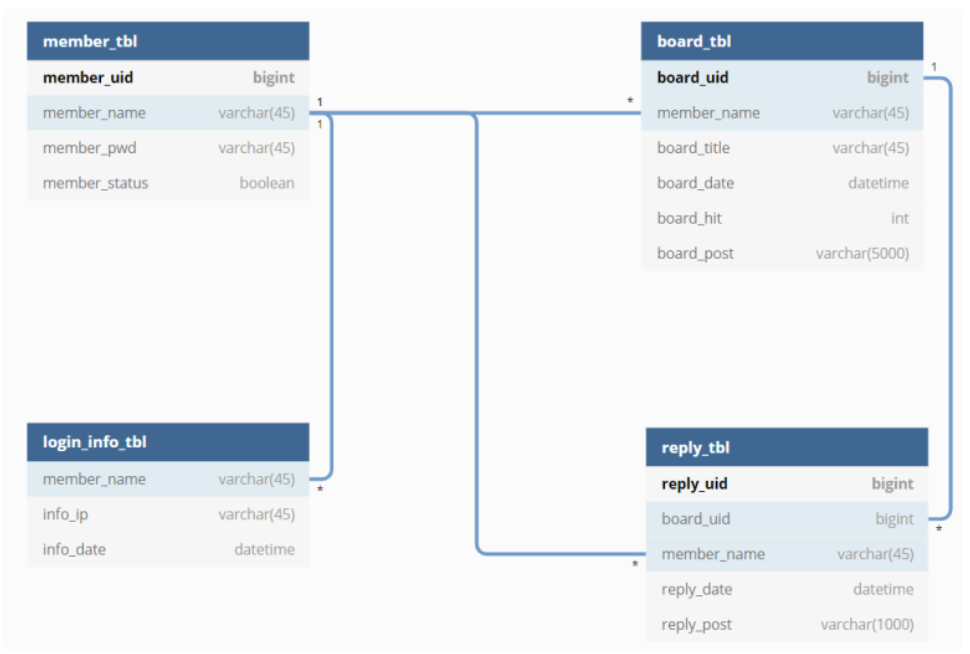
4) 물리적 데이터 모델링
최종적으로 데이터를 관리할 데이터 베이스를 선태갛고, 선택한 데이터베이스에 실제 테이블을 만드는 작업
ERD(Entity Relationship Diagram)
1. 엔티티 표기법
1) Entity: 정의 가능한 사물 또는 개념을 의미한다
테이블일아고 생각하면 된다.
2) Attribute: 엔티티 개체의 속성은 테이블의 각 컬럼들이라고 생각하면된다.
3) Domain: Attribute의 데이터 타입을 의미하며 생략이 가능하다.
2. 엔티티 분류

고객 정보 같은 실제로 물리적인 형태로 있는 정보와 구매 이력같은 무형적이고 개념적인 정보가 있다. 예를 들어 학생의 정보를 담은 테이블은 유형 엔티티이고 그 학생의 취미를 담은 엔티티는 무형으로 분류할 수 있다.
3. ERD 키와 제약 조건 표기법
1) 주식별자 (PK)
- Primary Key를 의미
- 중복 X, NULL X인 유일한 식별자
- 다이아몬드 또는 열쇠로 표기되곤 한다.
2) NOT NULL
- Null값이 허용 되지 않는다면 'N' 또는 'NN'을 표기한다.
3) 외래 식별자(Foreign Key)
- Foreign Key를 표현
- 열쇠로 표기되니만, 선을 이어주어 개체와의 관계를 따져 표시해야한다.
4. ERD 엔티티 관계 표기법
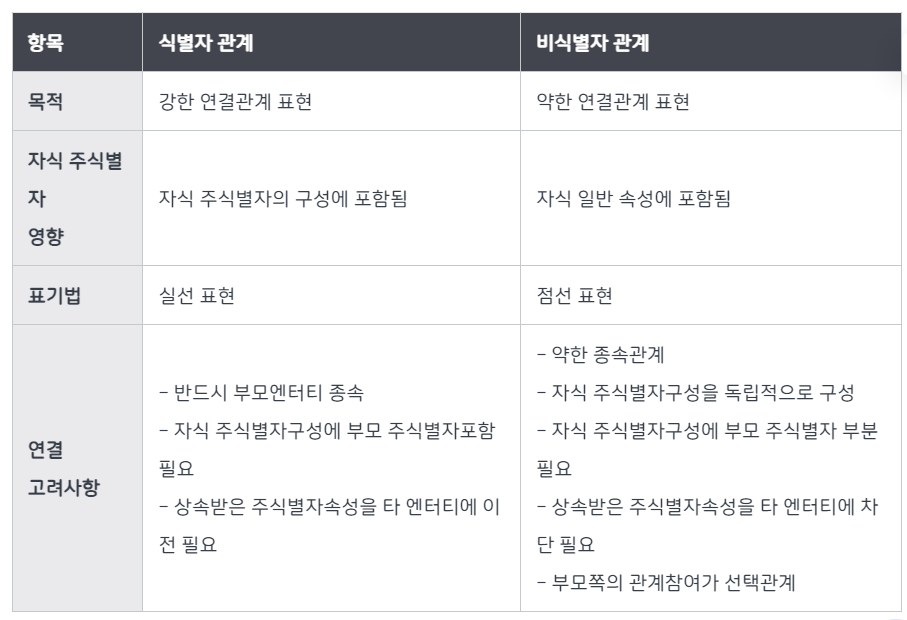
1) 식별자 관계: 실선으로 표기하며 강한 관계를 의미
- 부모 자식 관계에서 자식이 부모의 주 식별자를 외래 식별자로 참조해서 자신의 주 식별자로 설정
2) 비식별자 관계: 점선으로 표기하며 약한 관계를 의미
- 부모 자식 관계에서 자식이 부모의 주 식별자를 외래 식별자로 참조해서 일반 속성으로 사용
5. ERD 관계의 카디널리티
1) Cardinality: 한 개체에서 발생할 수 있는 발생 횟수를 정의하며, 다른 개체에서 발생할 수 있는 발생횟수와 연관된다.
- 대표적으로 Mapping Cardinality가 사용된다.
- One to one: 1 대 1 대응
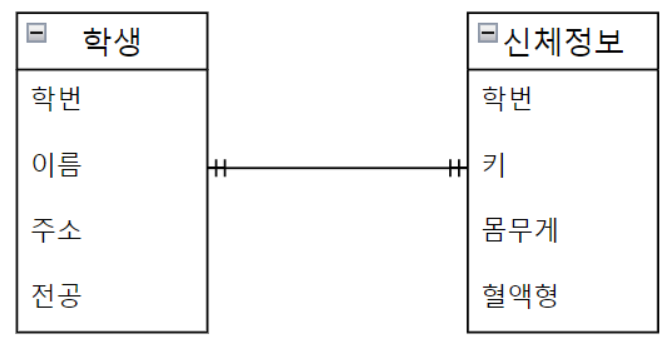
- One to many: 1 대 다 대응 or Many to one: 다 대 1 대응
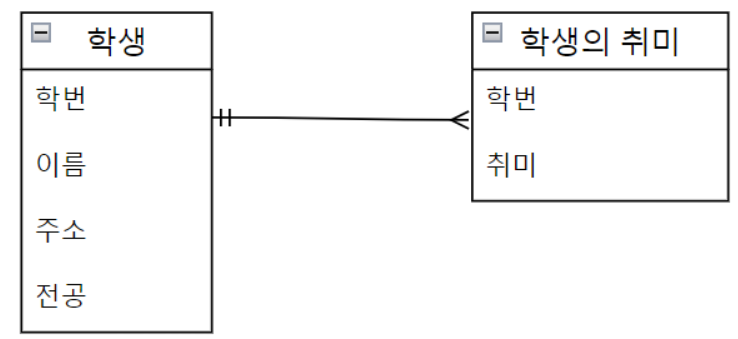
- Many to many: 다 대 다 대응
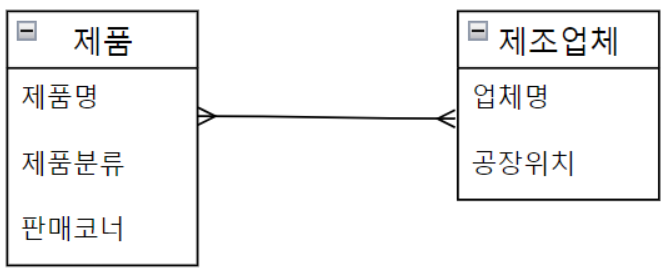
- One to one: 1 대 1 대응
!! Many-to-Many Cardinality 관계에 있는 경우, 두 개의 엔티티만으로는 서로를 표현하는데 부족하다. 아래과 같이 자동 조정 작업이 행해진다.
6. ERD 관계의 참여도
- 관계선 각 측의 끝자락에 기호를 표시한다.
- '|' 표시가 있는 곳은 반드시 있어야 하는 개체이다
- 'O' 표시가 있다면 없어도 되는 개체이다.
결론
데이터 모델링을 함으로써 요구분석에 맞는 데이터 모델링을 사전에 계획할 수 있으며 ERD를 그림으로서 데이터를 엔티티, 속성, 도메인, 관계를 표현되어 개발 과정에서의 오류를 개발 후의 이해와 유지보수를 효과적으로 이루어 낼 수 있다.
Reference

좋은 지식 나누어요