기초부터 다지는 Elasticsearch 운영 노하우
11장 내용 정리 및 관련 내용 정리
1. Elasticsearch 캐시의 종류와 특성
ElasticSearch로 요청되는 다양한 검색 쿼리는 동일한 요청에 대해 좀 더 빠른 응답을 주기 위해 해당 쿼리의 결과를 메모리에 저장한다. 결과 를 메모리에 저장해 두는 것을 메모리 캐싱이라고 하며 이때 사용하는 메모리 영역을 캐시 메모리라고 한다.
다음은 Elasticsearch에서 제공하는 대표적인 캐시 영역의 종류이다.

Node query cache
Node query cache는 filter context에 의해 검색된 문서의 결과가 캐싱되는 영역이다.
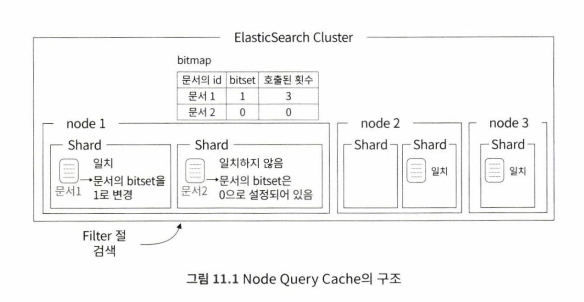
위의 그림 처럼 사용자가 filter context로 구성된 쿼리로 검색하면 내부적으로 각 문서에 0과 1로 설정할 수 있는 bitset을 설정한다. filter context로 호출한 적이 있는 문서는 bitset을 1로 설정하여 사용자가 호출한 적이 있다는 것을 문서에 표시해둔다. elasticsearch는 문서별로 bitset을 설정하면서, bitset이 1인 문서들 중에 자주 호출되었다고 판단한 문서들을 노드의 메모리에 캐싱한다.
세그먼트 하나의 저장된 문서의 수가 10,000개 미만이거나, 검색쿼리가 인입되고 있는 인덱스가 전체 인덱스 사이즈의 3% 미만일 경우에는 filter context를 사용하더라도 캐싱되지 않는다.
Query Cache Memory의 용량을 확인하는 방법
curl -s -X GET "localhost: 9200/_cat/nodes?v&h=name,qcmO?v&pretty"인덱스의 세그먼트 개수 확인하는 방법
curl -s -X GET "localhost:9200/_cat/segments/nodequerycache?v&h=index,shard,segment,do cs.count"filter context로 구성된 검색 쿼리로 여러번 요청하게 되면 캐싱되는 것을 볼 수 있다.
동일한 쿼리를 여러 번 받은 노드들은 Query cache memory에 해당 문서를 캐싱하고, 이후에는 메모리 영역에서 데이터를 리턴한다.
Node Query Cache 비활성화 방법
- Node query cache 설정은 dynamic setting이 아니기 때문에 인덱스를 close한다.
curl -X POST "localhost:9200/nodequerycache/_close?pretty"- false로 비활성화 한다.
curl -X PUT "localhost:9200/ nodequerycache/_settings?pretty" -H 'Content-Type: application/json'
-d'
{
"index.queries.cache.enabled": false
}'- 다시 인덱스 open
curl -X POST "localhost:9200/nodequerycache/_open?pretty" 캐싱되어 허용된 캐시 메모리 영역이 가득차면 LRU알고리즘(가장 오래된 내용을 지우는)에 의해 캐싱된 문서를 삭제한다. 각 노드의 elasticsearch.yml 파일에서 Node Query Cache 영역을 조정할 수 있다.
elasticsearch.yml
indices.queries.cache.size: 10%위 설정을 적용하기 위해서는 노드 재시작이 필요하면 비율로 할 수도 있고 512mb와 같은 절대값을 주어서 설정할 수 있다.
검색시 filter context를 활용하면 더 빠른 검색이 가능해진다.
Shard Request Cache
Shard Request Cache 는 샤드를 대상으로 캐싱되는 영역이며,특정 필드에 의한 검색이기 때문에 전체 샤드에 캐싱된다. Shard Request Cache는 ElasticSearch 클러스터에 기본적으로 활성화되어 있는 캐시이다.
Shard Request Cache는 앞서 살펴본 Node Query Cache 영역과 달리 문서 의 내용을 캐싱하는 것이 아니라,집계 쿼리의 집계 결과 혹은 RequestBody의 파라미터 중 size를 0으로 설정했을 때의 쿼리 응답 결과에 포함되는 매칭된 문서의 수에 대해서만 캐싱한다.
현재 Shard Request Cache 현황 확인하는 법
- Shard Request Cache Memory의 용량을 확인
curl -s -X GET "locaIhost: 9200/_cat/nodes?v&h=name,rcm?v&pretty"- 노드의 request_cache 항목 확인
GET _nodes/k4-node-1/stats
curl -s -X GET "locaIhost: 9200/_nodes/nodename/stats?pretty"Shard Request Cache는 샤드에 refresh 동작을 수행하면 캐싱된 내용이 사라진다. 즉, 문서 색인이나 업데이트를 한 이후 refresh를 통해 샤드의 내용이 변경되면 기존에 캐싱된 결과가 초기화 된다. 따라서 계속해서 색인이 일어나고 있는 인덱스에는 크게 효과가 없다.
Shard Request Cache 비활성화 방법
Shard Request Cache 활성/비활성화 설정은 dynamic setting에 속해 운영 중에 바로 변경이 가능하다. 또한,검색 시에도 활성/비활성화를 설정할 수 있다.
비활성화 방법
curl -X PUT "localhost:9200/nodequerycache/_settings?pretty" -H 'Content-Type: application/json' -d'
{
"index.requests.cache.enable": false
}
'
검색 시 비활성화 방법
curl -X GET "localhost:9200/nodequerycache/_search?request_cache=false&pretty" -H 'Content-Type: application/json' -d'
{
"size": 0, "aggs" : {
"cityaggs" : {
"terms" : { "field" : ••c丄ty.keyword" }
} }
}
'활용 방법
- 색인이 종료 된 과거 인덱스는 request_cache를 true로 집계하고 색인이 한참 진행 중인 인덱스는 false로 집계하는 방식으로 사용하면,과거 인덱스에 대해서는 캐싱 데이터를 리턴해서 빠르게 결과를 전달받고,색인이 빈번하게 진행 중이어서 캐싱이 어려운 인덱스는 불필요하게 캐싱하는 낭비를 막을 수 있다.
Field Data Cache
Field Data Cache는 인덱스를 구성하는 필드에 대한 캐싱이다.
Field Data Cache 영역은 주로 검색 결과를 정렬하거나 집계 쿼리를 수행할 때 지정한 필드만을 대상으로 해당 필드의 모든 데이터를 메모리에 저장하는 캐싱 영역이다.
Field Data Cache 메모리 사용 현황 확인 방법
curl -s -X GET "localhost :9200/_cat/nodes?v&h=name,fm?v&pretty"Field Data Cache 영역은 text 필드 데이터 타입에 대해서는 기본적으로 캐싱을 허용하지 않는다. text 필드 데이터 타입은 다른 필드 데이터 타입에 비해 캐시 메모리에 큰 데이터가 저장되기 때문에 메모리를 과도하게 사용하게 된다. 이런 부작용을 막기 위해 text 필드 데이터 타입은 기본 적으로 Field Data Cache에 캐싱되지 않는다.
Field Data Cache 영역은 집계를 수행한 필드의 모든 데이터를 메모리에 로딩하기 때문에 집계 시에 불러들일 데이터의 양을 고려하여 사용해야 한다. Field Data Cache 영역도 캐시 사이즈를 별도로 설정할 수 있으며, elasticsearch.yml 파일에 설정해야 한다.
elasticsearch.yml
indices.fielddata.cache.size: 10%💡 참고
위의 세개의 캐시 영역들은 모두 메모리에 할당한 힙 메모리 영역을 사용한다.
예를 들어 메모리 16G를 힙 메모리로 할당한 노드에서 10%를 특정 캐시 영역에 할당했다면 약 1.6G 정도의 데이터를 캐싱할 수 있으며,이후부터는 LRU 알고리즘에 의해 삭제되니 클러스터의 캐싱 환경에 따라 적절히 설정하도록 하자.
캐시 영역 클리어
각 캐시 영역을 인덱스 별로 클리어하는 방법에 대해 알아보자.
#Node query cache
curl -X POST "localhost:9200/nodequerycache/_cache/clear?query=true&pretty" -H 'Content-Type: application/json'
#Shard Request Cache
curl -X POST "localhost:9200/nodequerycache/_cache/clear?request=true&pretty" -H 'Content-Type: application/json'
#Field Data Cache
curl -X POST "localhost:9200/nodequerycache/_cache/clear?fielddata=true&pretty" -H 'Content-Type: application/json'인덱스 이름 대신 _all 사용 시 전체 대상으로 캐시를 클리어 할 수 있다.
2. 검색 쿼리 튜닝하기
검색 성능을 떨어트리는 요인 중 하나는 너무 많은 필드를 사용하는 것이다.
match 쿼리는 Query context에 속하는 쿼리이다.
Query context는 analyzer를 통해 검색어를 분석하는 과정이 포함되기 때문에 분석을 위한 추가 시간이 필요하다. 반면에 Filter context에 속하는 term쿼리는 검색어를 분석하는 과정을 거치지 않는다. 그렇기 때문에 성능은 term > match.
- 회원번호나 계좌번호 같은 수치계산이 없는 숫자형 데이터는 keyword 필드로 색인하고 term 쿼리를 활용한다.
3. 샤드 배치 결정하기
샤드의 개수를 한번 설정하면 변경할 수 없기 때문에 처음 샤드 개수를 설정할 때 신중하게 설정해야 한다. 아래는 클러스터의 샤드 배치를 잘못 설정했을 때 발생할 수 있는 이슈들이다.
- 데이터 노드 간 디스크 사용량 불균형
- 색인/검색 성능 부족
- 데이터 노드 증설 후에도 검색 성능이 나아지지 않음
- 클러스터 전체의 샤드 개수가 지나치게 많음
노드간 볼륨 사용량 불균형 문제
노드의 개수에 맞게 인덱스의 샤드 개수를 설정해야 클러스터 성능에 유리하다.
하지만 이후에 노드를 추가했을 경우를 대비하여 딱맞게 샤드 개수를 설정 하지말고 n배수로 설정하는 것이 증설 효과를 볼 수 있는 샤드 계획 방법 중 하나이다.
하지만 n배수로 설정해도 노드간 샤드 볼륨 사용량의 불균형이 발생할 수 있으므로 증설될 노드의 예측과 설계를 잘해서 증설된 이후 노드의 개수와 현재 노드의 최소 공배수로 샤드의 개수를 설정하여 불균형 문제 또한 해결할 수 있다.
클러스터 내 샤드 많아지는 문제 방지
데이터 노드의 사용량에 큰 문제가 없는데 클러스터의 성능이 제대로 나오지 않는다면 마스터 노드의 성능을 확인해 보아야 한다. ElasticSearch는 이렇게 클러스터 내에 샤드가 너무 많아져서 클러스터 전체 성능이 저하되는 것을 막기 위해 하나의 노드에서 조회할 수 있는 샤드의 개수를 제한하는 설정이 있다.
노드 당 샤드 조회 제한 설정
curl -X PUT "localhost:9200/_ cluster/settings?pretty" -H 'Content-Type: application/json' -d'
{
"transient": { "cluster.max_shards_per_node": 2000}
}
'노드당 검색 요청에 응답할 수 있는 최대 샤드 개수를 2,000개로 설정.
마스터 노드로 설정된 노드의 사용량을 모니터링해가며 클러스터에 적절한 전체 샤드 개수를 설정해야 한다.
4. forcemerge API
인덱스는 샤드로 나뉘고,샤드는 다시 세그먼트로 나눌 수 있다. 사용자가 색인한 문서는 최종적으로 가장 작은 단위인 세그먼트에 저장된다. 또한,세그먼트는 작은 단위로 시작했다가 특정 시점이 되면 다수의 세그먼트들을 하나의 세그먼트로 합친다. 세그먼트가 잘 병합되어 있으면 검색 성능도 올라간다.

샤드에 여러 개의 세그먼트가 있으면 해당 세그먼트들이 모두 검색요청에 대한 응답을 줘야함.
하지만 하나로 합쳐져 있다면, 사용자의 검색 요청에 응답해야 하는 세그먼트가 하나이기 때문에 성능이 더 좋아질 수 있다. forcemerge API는 이 렇게 세그먼트를 강제로 병합할 때 사용하는 API이다.
샤드 내 세그먼트를 강제로 병합하는 방법
세그먼트의 현황 확인
curl -X GET "localhost:9200/_cat/segments/forcemerge?v&h=index,shard,prirep,segment,docs,count,size&pretty" 병합
curl -X POST "localhost:9200/forcemerge/_forcemerge?max_num_segments=l&pretty"이렇게 하나의 샤드에 하나의 세그먼트로 병합된 인덱스는 검색 시 훨씬 적은 파일에 접근하게 된다. 하지만 무조건 세그먼트가 적다고 좋은 것은 아니다. 예를 들어,샤드 하나의 크기가 100GB 정도인데 세그먼트가 하나라면 작은 크기의 문서를 찾을 때에도 100GB의 크기 전체를 대상으로 검색해야 해서 세그먼트 병합 전보다 성능이 떨어질 수 있다. 이런 경우는 애초에 샤드 계획을 잘못 잡은 케이스로 볼 수 있다.
병합 이후에 색인이 발생되면 병합 효과를 보기 힘들기 때문에 readonly 모드로 설정하여 더 이상 세그먼트가 생성되지 못하게 하는 것이 좋다.
5. 그 외의 검색 성능을 확보하는 방법들
- Elasticsearch에서는 Parent/Child 구조의 join 구성이나 nested 타입같이 문서를 처리할 때 문서 간의 연결 관계 처리를 필요로 하는 구성은 권장하지 않는다.
- ElasticSearch는 레플리카 샤드를 가능한 한 충분히 둘 것을 권고한다.
동시에 들어온 검색 요청에 서로 다른 노드가 응답해 줄 수 있기 때문에 더 좋은 검색 성능을 보여준다. 레플리카 샤드가 많을수록 검색 성능은 더욱 좋아지게 된다. 다만,레플리카 샤드는 인덱싱 성능과 볼륨 사용량의 낭비가 발생하니 클러스터의 용량을 고려해서 추가하는 것이 좋다.
