모델을 평가하는 요소는 모델의 예측값과 실제 정답값 사이의 관계로 정의를 내릴 수 있다.
Confusion Matrix (혼동행렬)
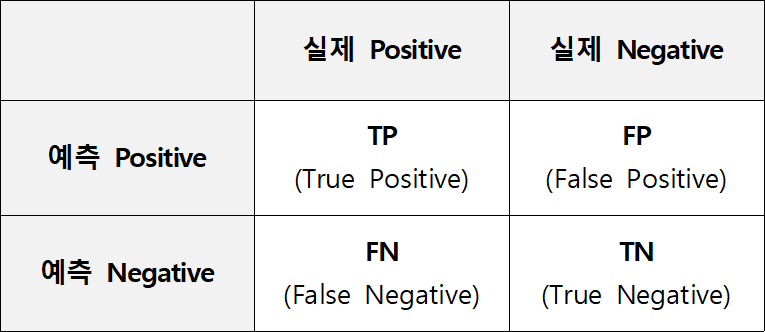
예측값과 실제값 사이의 관계를 행렬 형태로 표현한 것이 Confusion Matrix (혼동행렬) 이다.
- TP : Positive(양성)로 예측했는데, 실제로도 Positive인 경우
- FP : Positive(양성)로 예측했는데, 실제로는 Negative인 경우
- TN : Negative(음성)로 예측했는데, 실제로도 Negative인 경우
- FN : Negative(음성)로 예측했는데, 실제로는 Positive인 경우
TP, FP, TN, FN에서 뒤는 모델이 예측한 값, 앞은 정답 여부로 외웠다.
Positive로 예측했는데, 정답 (True)임 → TP
Positive로 예측했는데, 오답 (False)임 → FP → 그럼 실제 정답은 Negative란 소리
Negative로 예측했는데, 정답 (True)임 → TN
Negative로 예측했는데, 오답 (False)임 → FN → 그럼 실제 정답은 Positive란 소리
Positive(양성)란 무엇인가?
관심을 가지고 탐지하거나 예측하려는 목표를 말한다.
즉, 모델이 "찾고자 하는 값" 또는 "예측하고자 하는 상태"를 나타낸다.
Positive는 프로젝트의 목표와 관심사에 따라 개발자가 지정해야 한다.
스팸 메일 분류 모델을 만들고 싶다면, 스팸 메일을 Positive로 지정하게 된다.
암 진단 모델을 만들고 싶다면, 암이 있는 상태 (암인 경우)를 Positive로 지정하게 된다.
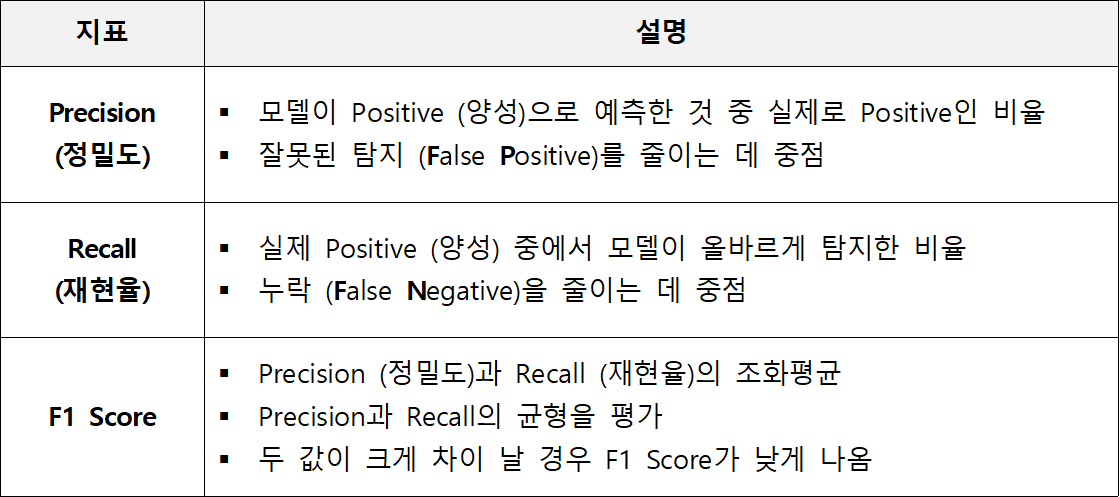
Precision (정밀도)
모델이 Positive로 예측한 데이터 중 실제로 Positive인 비율을 의미한다.
예측한 Positive가 얼마나 정확한지를 나타낸다.
FP를 줄이는 것이 중요한 경우 유용하다.
스팸 메일 분류 모델에서 정상 메일을 스팸 메일로 분류하는 경우를 생각해보자.
Positive (스팸 메일)로 예측했는데, 실제로는 Negative (정상 메일)인 상황이다.
즉, Positive로 예측했는데, 오답 (False)인 경우이다.
따라서 이런 경우는 FP에 속한다.
스팸 메일 분류에선 이런 잘못된 분류를 줄이는 것이 중요하다.
정상 메일이 스팸 메일함으로 잘못 분류되면 사용자가 중요한 정보를 놓칠 수 있기 때문이다.
Recall (재현율)
실제 Positive인 데이터 중 모델이 Positive로 예측한 비율을 의미한다.
실제 Positive를 얼마나 잘 놓치지 않고 탐지했는지를 나타낸다.
FN을 줄이는 것이 중요한 경우 유용하다.
암 진단 모델에서 암 환자를 암이 아닌 사람으로 잘못 예측한 경우를 생각해보자.
Negative (암 환자가 아님)로 예측했는데, 실제로는 Positive (암 환자)인 상황이다.
즉, Negative로 예측했는데, 오답 (False)인 경우이다.
따라서 이런 경우는 FN에 속한다.
암 진단 모델에선 이런 누락을 줄이는 것이 중요하다.
암 환자를 암이 아닌 사람으로 잘못 예측하고 집으로 돌려보내는 상황을 피해야 하기 때문이다.
F1 Score
Precision (정밀도)와 Recall (재현율)의 조화 평균
Precision과 Recall 사이의 균형을 평가한다.
0에서 1 사이의 값을 가지며, 1에 가까울 수록 좋다.
한쪽 지표만 높고 다른 쪽이 낮을 경우, F1 Score가 낮아진다.
데이터가 불균형할 때 특히 유용하다.
왜 조화 평균을 사용할까?
📌 Precision과 Recall은 서로 Trade-Off 관계에 있다.
Precision을 높이면 Recall이 낮아지고, Recall을 높이면 Precision이 낮아진다.
즉, 한 쪽이 높아지면 다른 한 쪽이 낮아지는 관계이다.
📌 조화 평균은 한쪽 값이 낮으면 전체 값이 낮아진다.
Precision 또는 Recall 중 하나라도 매우 낮다면 F1 Score도 낮게 나오는 것이다.
따라서 두 지표를 모두 고려하게 될 수 밖에 없다.
예를 들어Precision = 0.9,Recall = 0.1인 경우를 생각해보자.Recall 값이 매우 낮기 때문에 F1 Score도 낮은 값을 보인다.
이번엔Precision=0.8,Recall=0.8인 경우를 생각해보자.조화평균은 두 값이 가까울수록 평균이 커지므로, Precision과 Recall의 균형을 잘 반영한다.
💡 Arithmetic Mean (산술평균)은 안될까?
산술평균을 사용하면 Precision과 Recall이 한쪽으로 치우쳐도 높은 값을 반환할 수 있다.
Precision=0.9,Recall=0.1인 예시를 생각해보자.산술평균이 0.5로 높은 값을 가지지만, 실제로는 모델이 잘못된 예측을 많이 한다.
따라서 균형이 부족한 모델에도 지나치게 관대해질 수 있다.
즉, 모델 성능을 정확히 반영하지 못한다.
분류 성능 평가 지표 요약