
아래 영상을 보고 정리한 내용입니다.
웹서버 연동의 이유
1. 요청 분산
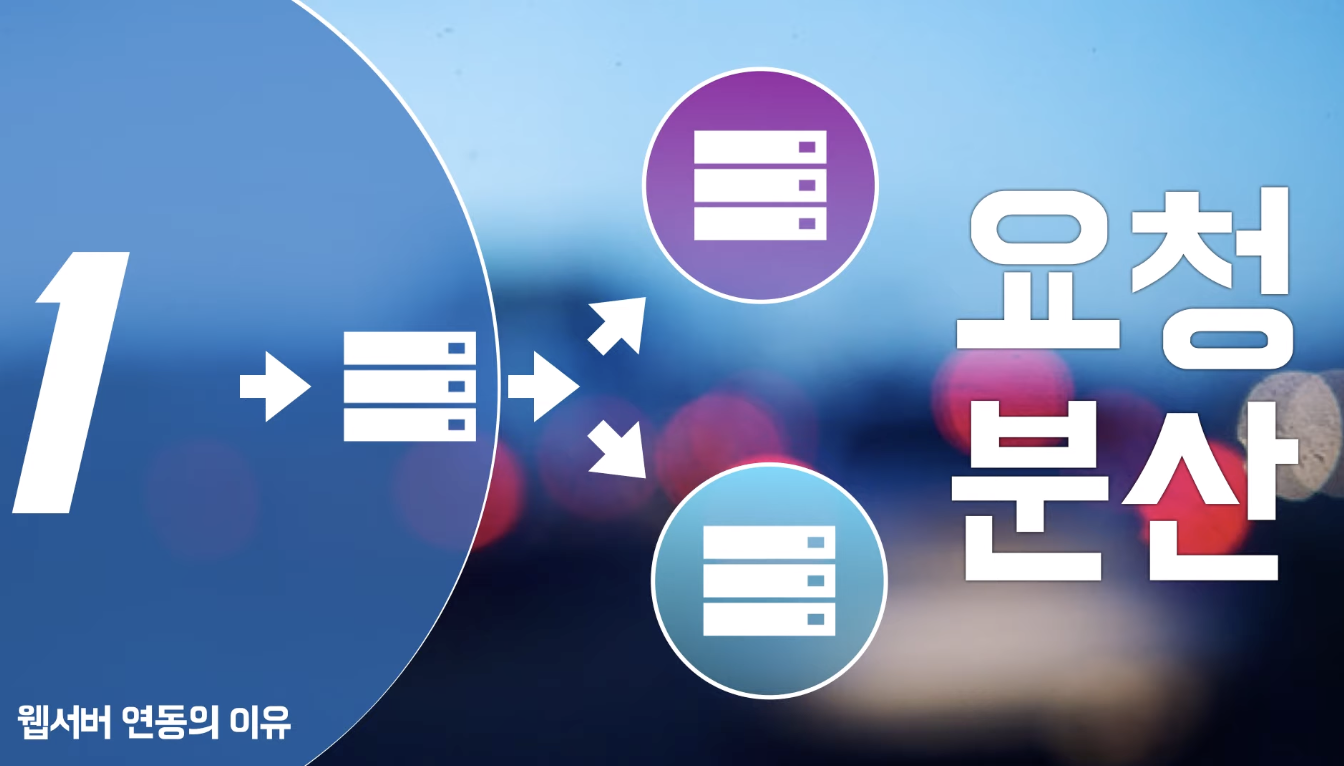
- 요청이 들어왔을 때, 그 요청을 여러개의 서버에 분산하여 처리할 수 있도록 하는 역할을 가진다.
- 동적처리가 대부분이거나 동적처리에서 부하가 자주 발생한다면, 이러한 부하를 서로 나눠서 동일 서버에 여러개의 톰캣을 두는 등의 동작 통해 요청 분산을 한다.
2. 소스 분산
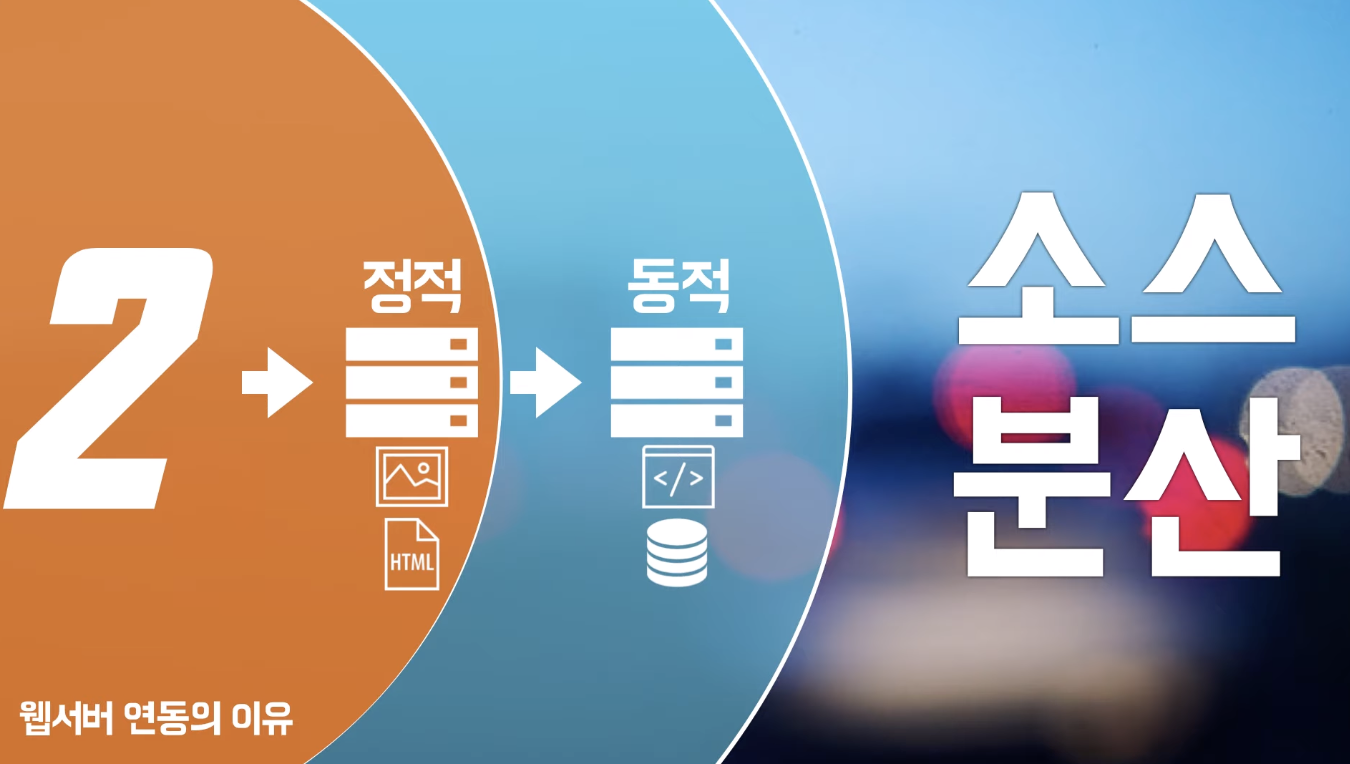
- 아파치가 처리하는 것과 톰캣이 처리하는 어플리케이션을 별도로 분산시켜 놓는다.
- 정적 - 아파치
- 동적 - 톰캣
- 일반적으로 아파치가 정적 소스 처리 (이미지, html) 가 톰캣보다 훨씬 빠르다.
- 처리하는 주최도 나눠 부하를 더 나눌 수 있다.
mod_jk
톰캣과 연동하는 대표적인 모듈
- mod_jk를 사용하여 아파치에 들어온 요청을 톰캣으로 연결해주는 역할을 한다.
- mod_jk 외에도 mod_proxy, mod_proxy_balance 등도 존재한다.
사용방법
- mod_jk 모듈을 설정한다.
- worker를 정의한다. (== tomcat 정의를 worker로 한다)
- 톰캣이 처리할 요청을 정의한다.
1. mod_jk 모듈을 설정한다.
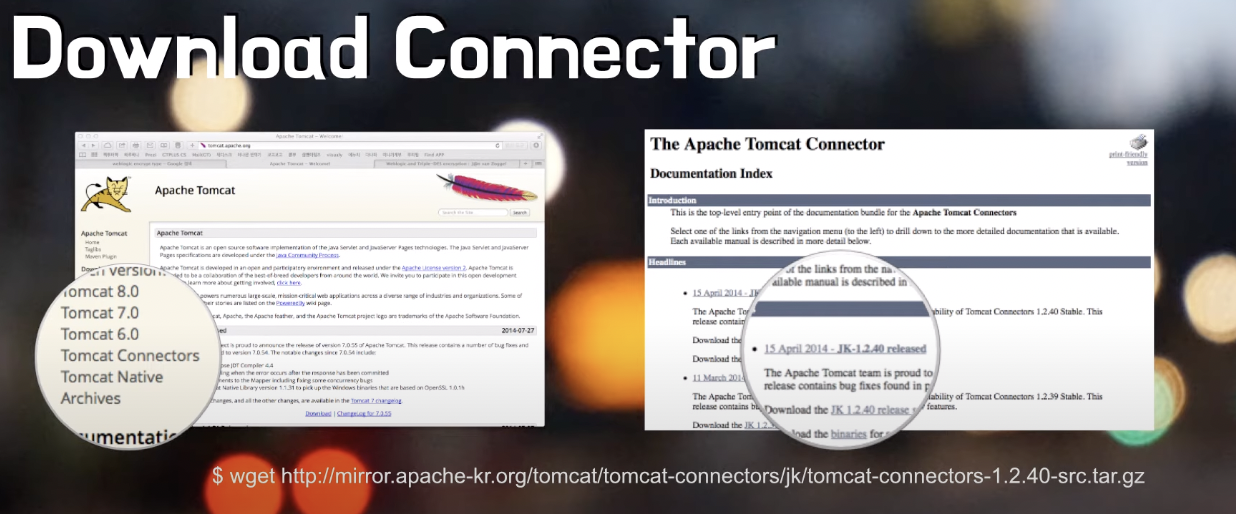

- 다운을 받은 후, 압축 풀고 컴파일을 하면 mod_jk.so 파일이 생성된다.
윈도우
- 컴파일을 하기 위해 visual studio 가 있어야 한다.
- 바이너리로 제공된다. 따라서 DLL 파일을 받으면 된다.
리눅스/유닉스
- 소스파일을 받는다.
- version-src.tar.gz 파일을 다운 받는다.
- 아파치가 미리 설치되어 있어야 한다.
- 해당 아파치가 빈 디렉터리 안에 apxs 라는 바이너리 파일이 있는데, 이 톰캣 커넥터를 컴파일 하기 위해서
./configure -with-apxs=APACHE_HOME_DIR/bin/apxs명령어로 디렉토리 지정을 해준다.
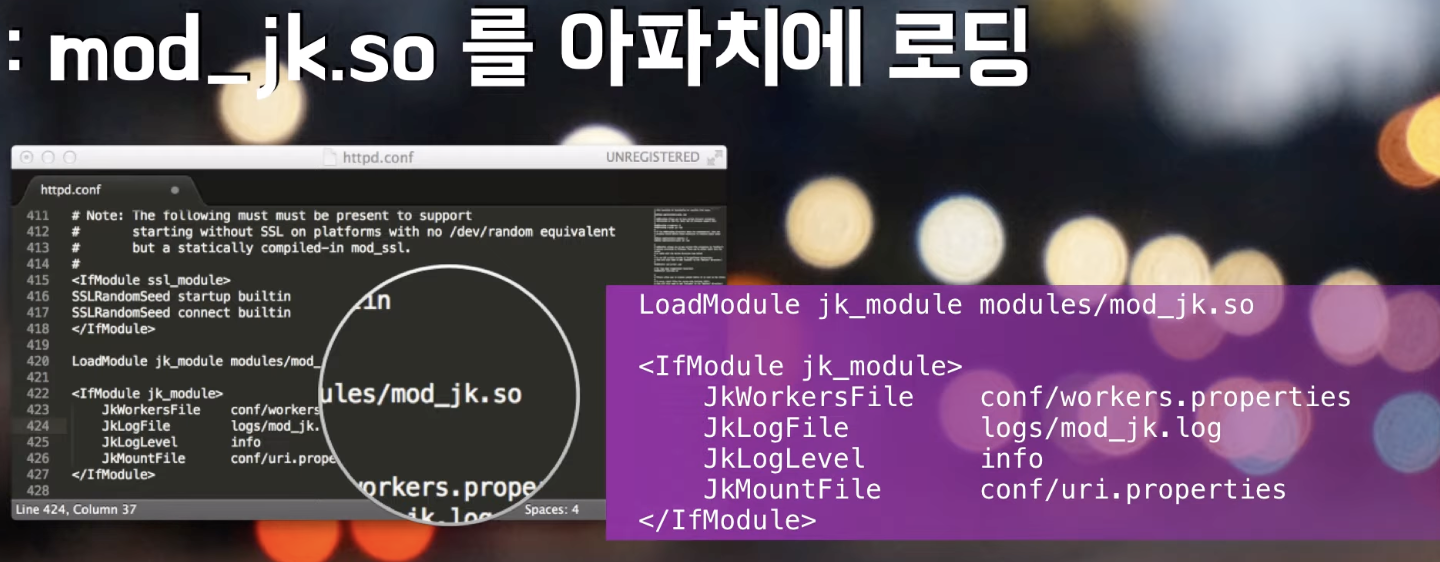
- 모듈로 설정해주는 과정을 거친다.
JKWorkersFile에서 어떤 톰캣에다 요청을 넘길지 지정하는 부분인데 대부분workers.properties로 정의한다.- 영상에서는
JKMountFile를 특정 파일에서 마운트하는 파일을 관리할 수 있도록 uri.properties로 설정하였다.
2. worker를 정의한다.
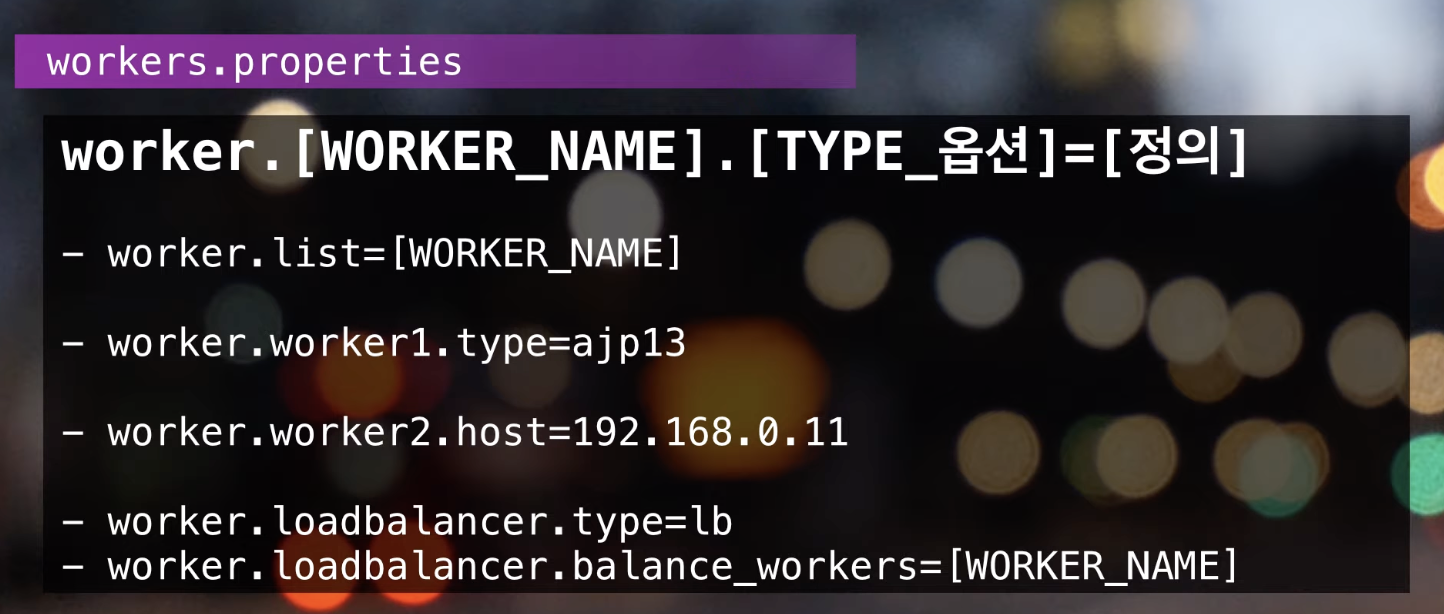
설정 예시 )
worker.list=[WORKER_NAME]: 요청을 처리하는 워커를 나열합니다.worker.worker1.type=ajp13: worker1 워커의 형태를 정의합니다.worker.worker2.host=192.168.0.11: worker2 워커의 address를 정의합니다.worker.loadbalancer.type=lb: loadbalancer 워커의 형태를 정의합니다.worker.loadbalancer.balance_workers=[WORKER_NAME]: lb 형태인 loadbalancer 워커에서 요청을 분산시킬 워커를 나열합니다.
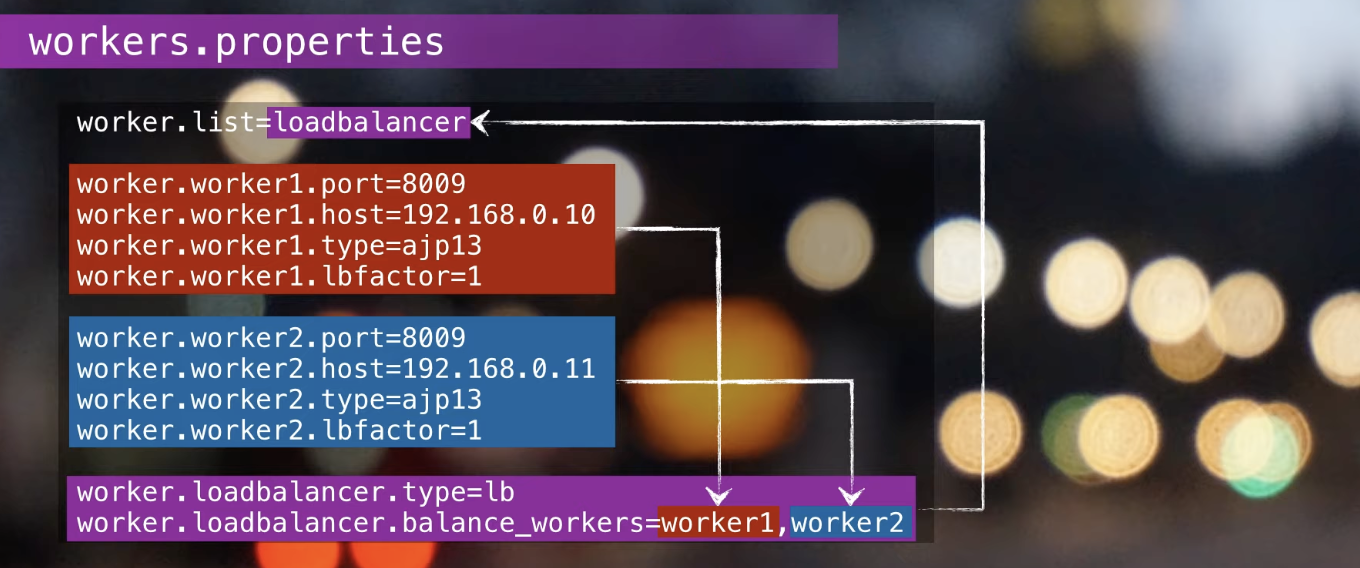
- worker1, worker2 정의하는 과정이다.
- LB 타입을 갖는
loadbalancer라는 워커에workers로 포함을 시킨다. - 따라서
balance_workers에 worker1, 2가 들어가게 된다. worker.list에 있는loadbalancer라는 워커가 실제로 요청을 받는 역할을 할 수 있게 정의가 된다.
3. 톰캣이 처리할 요청을 정의한다.

- /*.do는 worker1에서 할꺼다.
- /*.jsp는 worker2에서 할꺼다. 등의 정의이다.
클러스터
아까 웹서버 연동의 이유 중 이어서 3번째 추가적인 이유이다.
3. 장애 극복
- 장애가 난 쪽에는 요청을 전달하지 않고, 살아있는 톰캣에만 요청을 전달하여 사용자가 서비스를 계속하여 사용할 수 있도록 하는 Failover 기능을 제공한다.
클러스터가 필요한 이유
- 그러나 그냥 페이로버만 되면 http 세션이 같이 삭제가 되며 세션의 단절로 인해 기존 사용자의 세션이 날라간다. (서버에 존재하지 않게 된다)
- 즉, 이런 장애처리 동작시 기존 처리중이던 HTTP Session 정보는 장애가 발생한 톰캣이 가지고 있었기 때문에 없어지게 되는 것이다.
클러스터의 역할
- HTTP Session을 순간순간마다 다른 톰캣 멤버에 복제를 해준다.
- 그러므로 인해 어떠한 장애 발생 시나 특정 톰캣이 죽거나 등의 문제가 생겼을 때, 해당 세션이 다른 톰캣에 있기 때문에 사용자는 자신의 세션에 중단 없이 이용이 가능하다.
클러스터 사용법
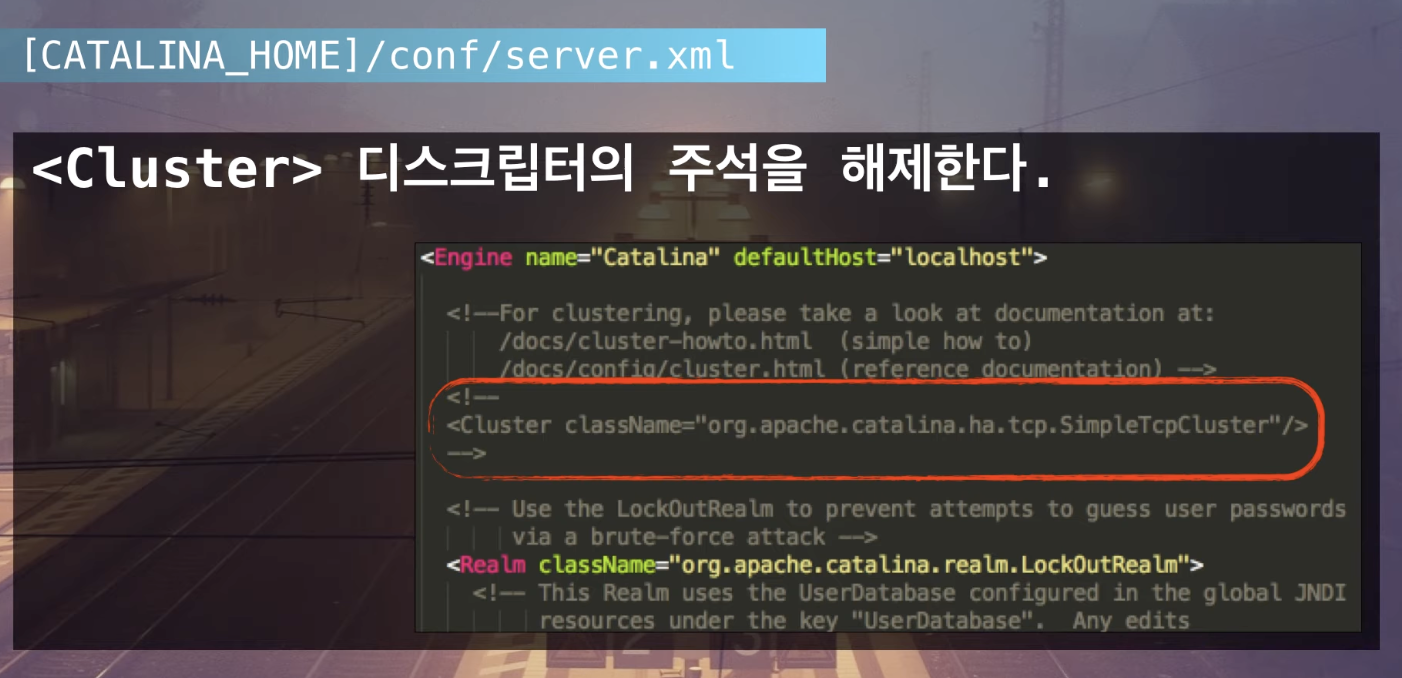
server.xml의Cluster디스크립터의 주석을 해제하는 것으로 클러스터 사용이 가능하다.- 그러나 동일 장비에서 기동되는 톰캣들이나 혹은 서비스가 다른 톰캣이 여럿 기동중인 경우에는 설정값들이 중복되어 톰캣 기동이나 서비스 처리시 문제가 발생할 수 있다.
- 따라서 이에 대한 팁이 존재한다.
- 톰캣 5.5의 디스크립터를 참고하면 쉽게 상세 옵션을 적용할 수 있다. (다른 버전은 딱 한줄인데 5.5는 상세히 나와있음)

- 누가 내 클러스터 멤버인지 알아보기 위해서는 멀티캐스트 ip와 멀티캐스트 port가 동일해야 한다.
- 아래의 NioReceiver에는 클러스터에 NioReceiver 역할으르 하는 포트가 또 추가로 생성된다. 얘는 TCP로 뜨기 때문에 겹치면 안된다. 같은 장비에 있는 톰캣 두개 이상이 클러스터로 묶인다면, 해당 NioReceiver의 포트 정보는 반드시 다르게 설정이 되어야 한다. (그래야 TCP 포트가 겹치지 않는다) 멀티캐스트는 같게, NioReceiver의 TCP값은 다르게 설정해야 하는걸 주의해야 한다.
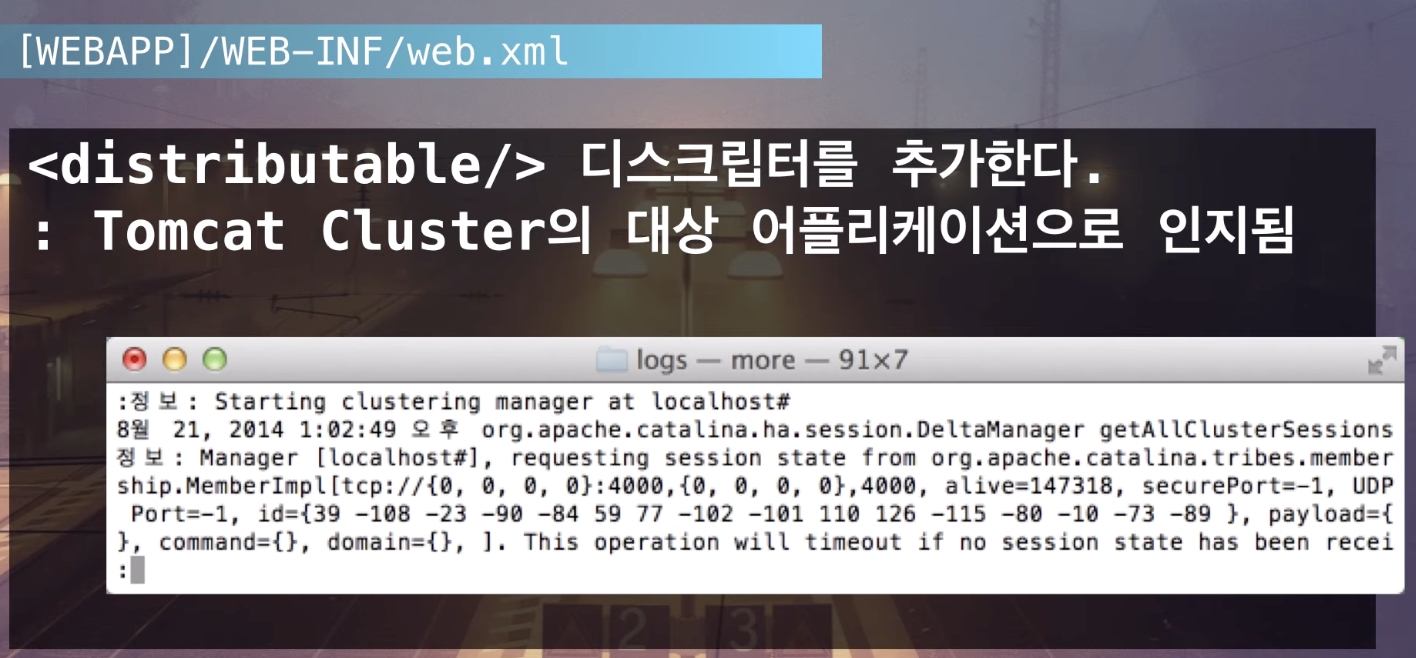
- 어떤 어플리케이션이 HTTP Session을 distribute 할껀지 정의해주어야 한다.
- 그러기 위해서는 어플리케이션 안에
web.xml에<distributable/>디스크립터를 한줄 추가해준다. - 기본값이 True이기 때문에 바로 True로 동작하여 톰캣 클러스터의 대상 어플리케이션으로 자동 인지 된다.
- 그렇게 되면 클러스터가 뜨면서 세션을 서로 복제하며 클러스터 동작을 하게 된다.

데굴데굴