
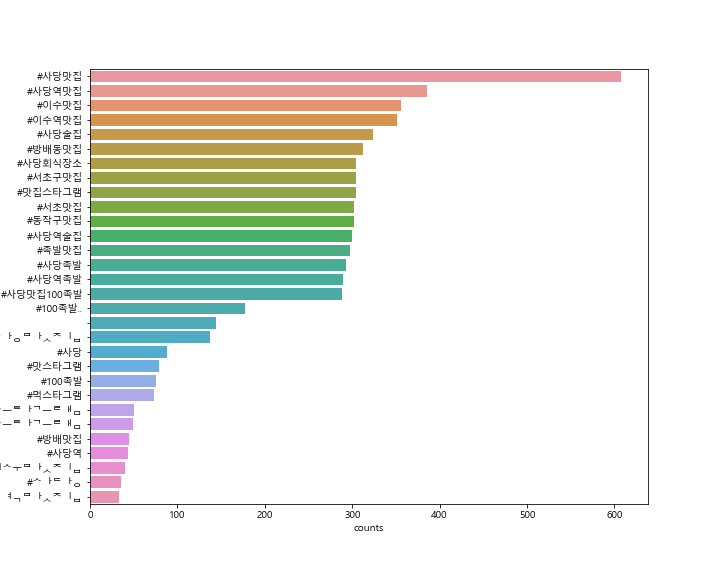
인스타그램 크롤링을 통해 현재 내가 거주하고 있는 사당의 맛집 데이터를 수집해 보았다.
검색어: '사당맛집'
추출데이터: 본문, 날짜, 좋아요 수, 위치, 해시태그
추출수: 1,000개
#함수 작성 def insta_searching(word): #word라는 매개변수를 받는 insta_searching 이라는 함수 생성 url = 'https://www.instagram.com/explore/tags/' + word return url
#열린 크롬으로 개발자 도구 활용하여 첫번째 게시물 태그 확인 (<div class="_9AhH0"></div>) #첫번째 게시물 찾아 클릭 함수 만들기
import time def select_first(driver): first = driver.find_element_by_css_selector('div._9AhH0') #find_element_by_css_selector 함수를 사용해 요소 찾기 first.click() time.sleep(3) #로딩을 위해 3초 대기
#본문 내용, 작성 일시, 위치 정보 및 해시태그(#) 추출 import re def get_content(driver): # 1. 현재 페이지의 HTML 정보 가져오기 html = driver.page_source soup = BeautifulSoup(html, 'lxml') # 2. 본문 내용 가져오기 try: #여러 태그중 첫번째([0]) 태그를 선택 content = soup.select('div.C4VMK > span')[0].text #첫 게시글 본문 내용이 <div class="C4VMK"> 임을 알 수 있다. #태그명이 div, class명이 C4VMK인 태그 아래에 있는 span 태그를 모두 선택. except: content = ' ' # 3. 본문 내용에서 해시태그 가져오기(정규표현식 활용) tags = re.findall(r'#[^\s#,\\]+', content) # content 변수의 본문 내용 중 #으로 시작하며, #뒤에 연속된 문자(공백이나 #, \ 기호가 아닌 경우)를 모두 찾아 tags 변수에 저장 # 4. 작성 일자 가져오기 try: date = soup.select('time._1o9PC.Nzb55')[0]['datetime'][:10] #앞에서부터 10자리 글자 except: date = '' # 5. 좋아요 수 가져오기 try: like = soup.select('div.Nm9Fw > button')[0].text[4:-1] except: like = 0 # 6. 위치 정보 가져오기 try: place = soup.select('div.JF9hh')[0].text except: place = ''
# 7. 수집한 정보 저장하기 data = [content, date, like, place, tags] return data def move_next(driver): right = driver.find_element_by_css_selector('a._65Bje.coreSpriteRightPaginationArrow') right.click() time.sleep(3)
from selenium import webdriver from bs4 import BeautifulSoup import time import re #1. 크롬으로 인스타그램 - '사당맛집' 검색 driver = webdriver.Chrome("C:\\Users\\KIM EUNKI\\anaconda3\\chromedriver.exe") word = '사당맛집' url = insta_searching(word) driver.get(url) time.sleep(4) #2. 로그인 하기 login_section = '//*[@id="react-root"]/section/nav/div[2]/div/div/div[3]/div/span/a[1]/button' driver.find_element_by_xpath(login_section).click() time.sleep(3) elem_login = driver.find_element_by_name("username") elem_login.clear() elem_login.send_keys('ID') elem_login = driver.find_element_by_name('password') elem_login.clear() elem_login.send_keys('PASSWORD') time.sleep(1) xpath = """//*[@id="react-root"]/section/main/div/article/div/div[1]/div/form/div[4]/button""" driver.find_element_by_xpath(xpath).click() time.sleep(4) xpath1 = """//*[@id="react-root"]/section/main/div/div/div/div/button""" driver.find_element_by_xpath(xpath1).click() time.sleep(4) #3. 검색페이지 접속하기 driver.get(url) time.sleep(4) #4. 첫번째 게시글 열기 select_first(driver) #5. 비어있는 변수(results) 만들기 results = [] #여러 게시물 크롤링하기 target = 1000 #크롤링할 게시물 수 for i in range(target): data = get_content(driver) #게시물 정보 가져오기 results.append(data) move_next(driver) print(results[:2]) Colored by Color Scripter cs
크롤링 후 엑셀 저장
import pandas as pd raw_total = pd.read_excel("C:\\Users\\KIM EUNKI\\Google 드라이브\\GitHub\\Practice\\Instagram_Crawling\\Insta_Sadang.xlsx") raw_total.head() Colored by Color Scripter



20개의 댓글

안녕하세요! 제공해주신 게시글 덕분에 공부할 수 있었습니다. 너무 감사합니다!
제가 사용중에 계속 500개 정도 넘어가면
NoSuchElementException: Message: no such element: Unable to locate element: {"method":"css selector","selector":"a._65Bje.coreSpriteRightPaginationArrow"}
(Session info: chrome=86.0.4240.75)
이런 에러가 뜨는데 어떤 문제인지 알수 있을까요 ?

안녕하세요 주신 글 참고하여 실행중인데
xpath = """//[@id="react-root"]/section/main/div/article/div/div[1]/div/form/div[4]/button"""
driver.find_element_by_xpath(xpath).click()
time.sleep(4)
xpath1 = """//[@id="react-root"]/section/main/div/div/div/div/button"""
driver.find_element_by_xpath(xpath1).click()
time.sleep(4)
이 아이디 비밀번호 입력이 잘 되고 로그인 부분에서 오류가 떠서 그런데
혹시 해결방법이 있을까요?

안녕하세요 덕분에 잘 공부하고있습니다 감사합니다 ㅠㅠ 에러가 떠서그런데 왜이런지 알 수 있을까요?
NameError Traceback (most recent call last)
in ()
1 # 7. 수집한 정보 저장하기
----> 2 data = [content, date, like, place, tags]
3 return data
4 def move_next(driver):
5 right = driver.find_element_by_css_selector('a._65Bje.coreSpriteRightPaginationArrow')
NameError: name 'content' is not defined

마지막 그래프와 워드클라우드는 어떤 모듈/프로그램을 사용해서 만든건가요??
스크래퍼의 기본 형태 익히는데 도움이 많이 됐습니다!

안녕하세요! 글 너무 재밌게 읽었습니다 ㅎㅎㅎ 크롤링이 재밌네요
혹시 배포환경에서 크롤링이 안되지 않나요?
로컬에서는 잘 되는데 ec2에서는 가져오는 html이 다르더라구요
게시글 참고 잘했습니다. 감사합니다 !
저 근데 엑셀 저장이 안되는데 이럴경우 어떻게하면되나요 ? ㅠ