Requests 라이브러리
접근할 웹 페이지의 데이터를 요청/응답 받기 위한 라이브러리
import requests as req- 수집할 웹 페이지의 주소 정의
url = 'https://www.naver.com'- 라이브러리를 이용해서 웹 페이지 요청
# HTTP 상태코드 # - 200 : 성공 # - 400 : 클라이언트 오류 # - 500 : 서버 오류 res = req.get(url)- 웹 페이지 확인하기
res.text
BeautifulSoup 라이브러리
웹 페이지에서 원하는 데이터를 추출하기 쉽게 Python객체로 변환해주는 라이브러리
from bs4 import BeautifulSoup as bs-
- 문자열로 된 웹 페이지 데이터를 객체로 변환
# bs(변환할 데이터, 변환방식) # - 변환할 데이터 : 응답받은 웹 페이지 데이터 # - 변환방식 : Python객체로 변환 lxml > html.parser > html5lib html = bs(res.text, 'lxml') html
type(res.text)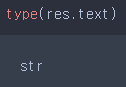
type(html)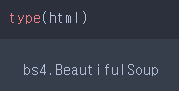
-
- 원하는 데이터 추출하기
html.select_one('title')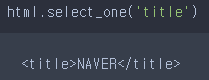
-
select_one(CSS선택자) : 선택자에 해당하는 하나의 요소를 반환하는 함수
# - 접근한 요소의 내용만 접근 html.select_one('title').text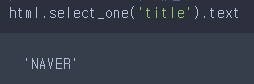
html.select('title')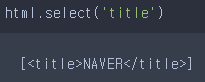
-
select(CSS선택자) : 선택자에 해당하는 모든 요소를 반환하는 함수
# - 요소의 내용 접근 시 인덱스를 통해 하나씩 접근해야 한다! html.select('title')[0].text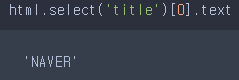
네이버 날씨 온도 가져오기
search_url = 'https://search.naver.com/search.naver?sm=tab_sug.asiw&where=nexearch&query=%EA%B4%91%EC%A3%BC+%EB%82%A0%EC%94%A8&oquery=%EB%82%A0%EC%94%A8&tqi=iguuSdp0J1sssZ7iaI0ssssstiC-424871&acq=%EA%B4%91%EC%A3%BC+%EB%82%A0%EC%94%A8&acr=1&qdt=0'res = req.get(search_url)
res
html = bs(res.text, 'lxml')
html
html.select_one('div.temperature_text > strong').text
뉴스 제목 가져오기 실습
news_list = html.select('a.news_tit')
for news in news_list :
print(news.text)
뉴스의 제목과 내용 가져오기 실습
news_url = 'https://n.news.naver.com/mnews/article/055/0001098485?sid=105'- 웹 페이지 요청
res = req.get(news_url)
res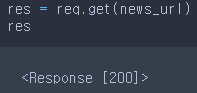
- 문자열 데이터 -> Python 객체로 변환
html = bs(res.text, 'lxml')
html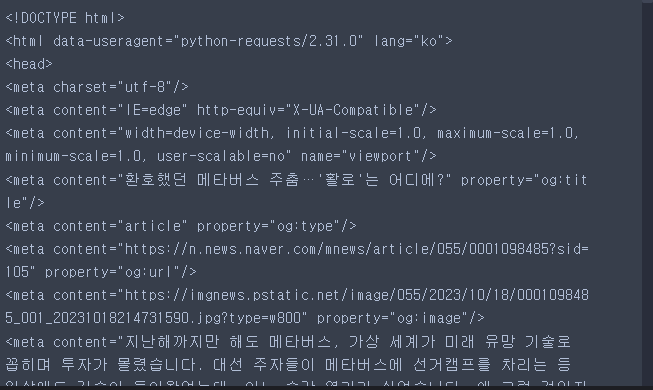
title = html.select_one('h2.media_end_head_headline')
print(title.text)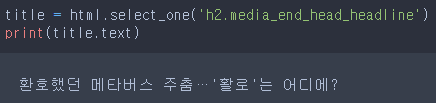
content = html.select_one('#dic_area')
print(content.text.strip().replace('\n',''))
네이버 뉴스 헤드라인 URL 가져오기
naver_news_url = 'https://news.naver.com/main/main.naver?mode=LSD&mid=shm&sid1=105'- RemoteDisconnected 오류 해결방법
# - 브라우저로 요청을 보냈다라는 것을 서버에서 인식할 수 있도록
# user-agent 값을 구성하고 보내줘야 한다!
header_option = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'
}
res = req.get(naver_news_url, headers = header_option)
res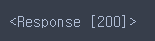
html = bs(res.text, 'lxml')
html
headline_list = html.select('a.sh_text_headline ')- 요소의 속성값 가져오기
# - 요소객체[속성명]
headline_list[0]['href']
- 각 헤드라인 기사의 url을 가져온 후 h_url_list에 추가하기
h_url_list = []
# for a in headline_list :
# h_url_list.append(a['href'])
for i in range(len(headline_list)) :
h_url_list.append(headline_list[i]['href'])
print(h_url_list)
수집된 헤드라인 url을 활용하여 뉴스제목, 내용 가져오기
for url in h_url_list :
res = req.get(url, headers = header_option)
html = bs(res.text, 'lxml')
title = html.select_one('h2.media_end_head_headline')
content = html.select_one('#dic_area')
print('제목 :', title.text)
print('내용 :', content.text.strip().replace('\n',''))
print()

노는게 제일 좋아~!