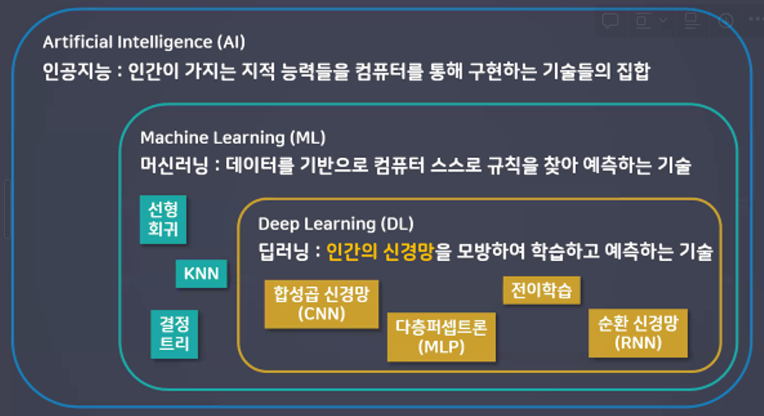
딥러닝이란?

- 딥러닝
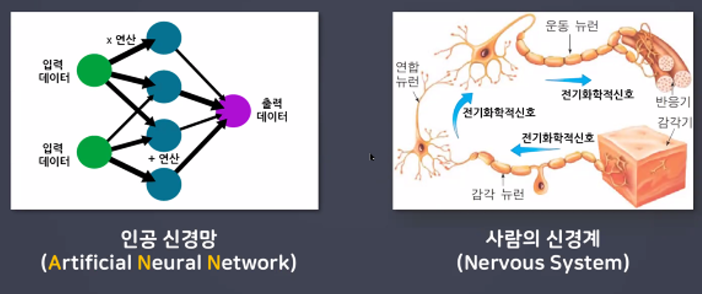
사람의 신경망을 모방하여 기계가 병렬적 다층 구조를 통해 학습하도록 만든 기술
(컴퓨터비젼, 음성인식, 자연어처리, 신호처리 등의 분야에 적용)
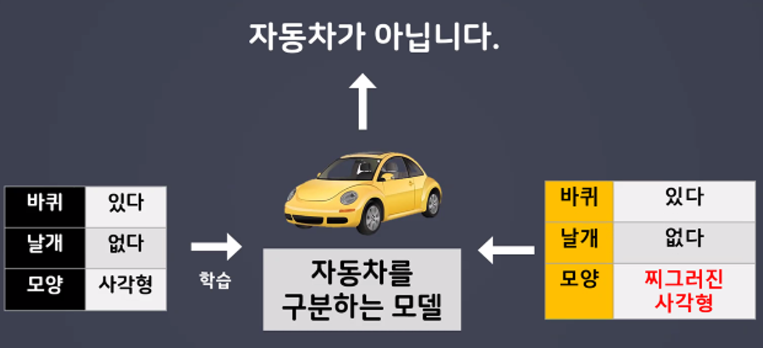
- 기계는 판단하는 기준이 명확히 정해져있다.
하지만 사람은 대상을 판단하는 경계가 느슨하다.(추상적 / 유연한 사고)
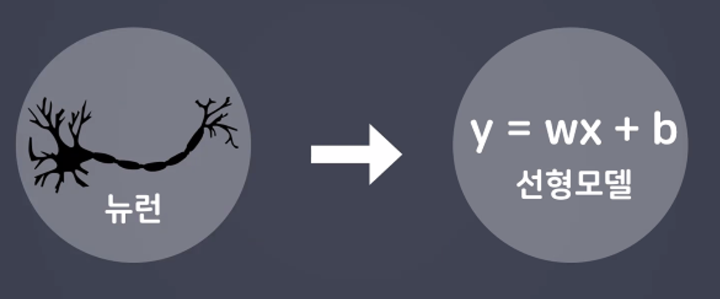
- 학습하고 예측하여 유연한 사고를 가지게 한다.
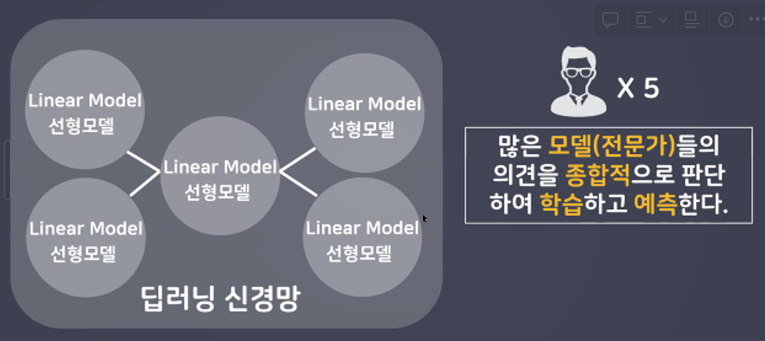
- 대량의 데이터에서 복잡한 패턴이나 규칙을 찾아내는 능력이 뛰어나다.
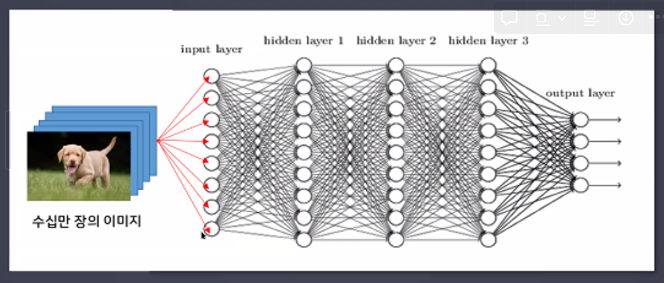
- 딥러닝 활용 사례


딥러닝 역사
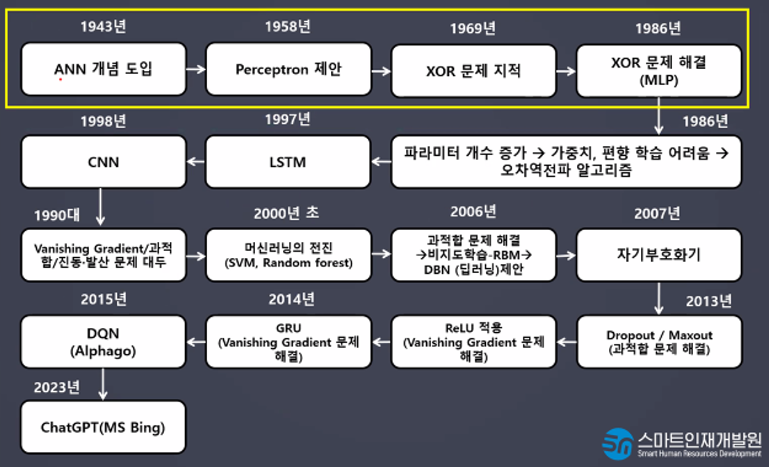
- 학습 로드맵
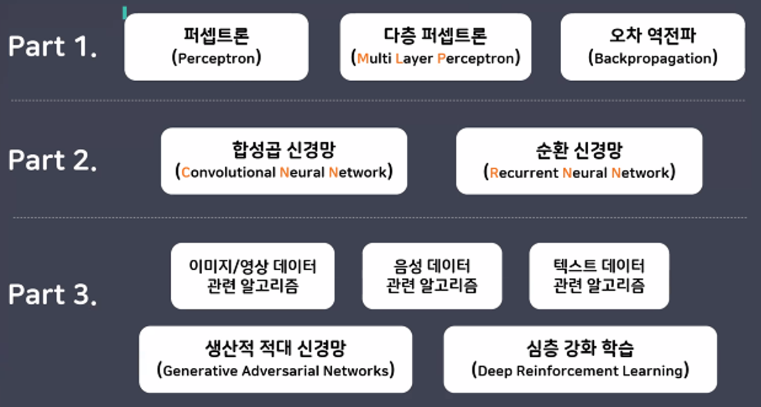
기존 머신러닝과의 비교
- 기존 머신러닝(선형모델)과 딥러닝의 공통점
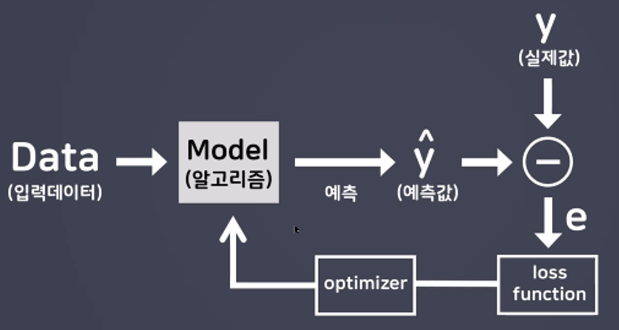
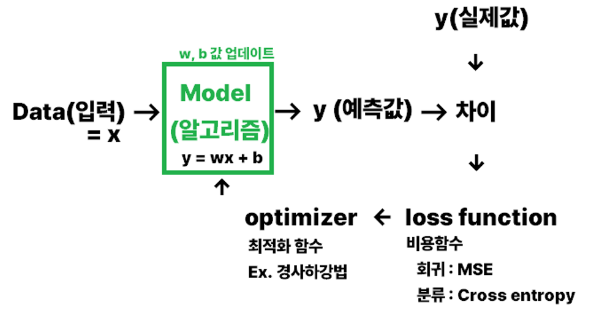
경사하강법 → optimizer의 방법 중 하나
- 기존 머신러닝과 딥러닝의 차이점
-규칙 기반 전문가 시스템(Rule-based expert system)

-기존 머신러닝

-딥러닝 : feature engineering이 거의 필요 없음(사람의 개입 최소화)


딥러닝 프레임워크

-
Tensorflow
구글이 만든 딥러닝 라이브러리 -
Keras
-tensorflow 위에서 작동하는 라이브러리로 사용자 친화적 라이브러리
-tensorflow 기반 사용자 인터페이스 API

실습
딥러닝 맛보기
- 단축키 사용법

- tensorflow 불러오기
import tensorflow as tf- tensorflow 버전 확인하기
print(tf.__version__) # 언더바 두 개
# 설치 버전을 확인하는 이유는?
# 프로젝트 진행 시 이미 개발된 딥러닝 모델을 가져다 쓰는 경우
# 버전을 일치시켜줘야지 충동나지 않음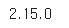
- 드라이브와 코랩 연결하기!
# 현재 파일의 위치 확인하기 (리눅스 명령어 사용 → 코랩은 리눅스 기반)
!pwd # print work directory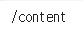
- 작업디렉토리 변경
# %cd : change directory (% 의미 : 영구적 실행)
%cd "/content/drive/MyDrive/Colab Notebooks/DeepLearning"
- 다시 한 번 현재 작업 위치 확인
!pwd

- 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt- 데이터 불러오기
data = pd.read_csv('data/student-mat.csv', delimiter= ';')
data
# 정답으로 사용할 컬럼 : G3 (3학년 성적)
# 학생 성적을 예측하는 모델링
# 하나의 특성만을 사용해서 성적 예측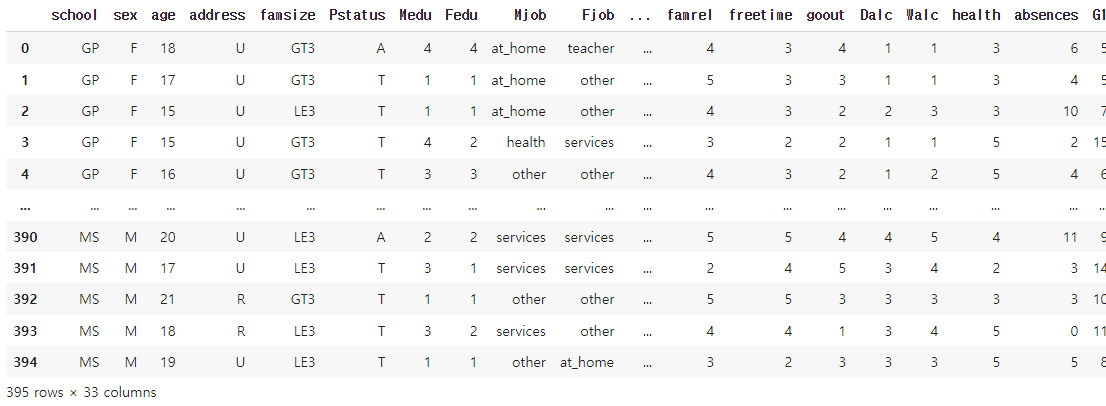
- 테이블 정보 확인
data.info()
# 결측치 유무
- 문제(X)와 정답(y)로 분리

X = data['studytime']
y = data['G3']- train, test 분리(8:2)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=2024)- 크기 확인 (shape)
print('훈련용 문제 : ', X_train.shape)
print('훈련용 정답 : ', y_train.shape)
print('테스트용 문제 : ', X_test.shape)
print('테스트용 정답 : ', y_test.shape)
모델링 (LinearRegression) 선형회귀모델 가져와서 학습 및 예측 진행
- 모델 불러오기
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error # 회귀모델의 평가지표(MSE)# 머신러닝 모델은 입력특성을 2차원으로 받는다!!
# 1차원(Series) → 2차원(DataFrame)
X_train.values.reshape(-1, 1)- 모델 생성
linear_model = LinearRegression()- 모델 학습(학습용 문제, 학습용 정답) → 머신러닝 모델은 입력특성 반드시 2차원데이터
linear_model.fit(X_train.values.reshape(-1, 1), y_train)
- 모델 예측(테스트용 문제)
pre = linear_model.predict(X_test.values.reshape(-1, 1))
pre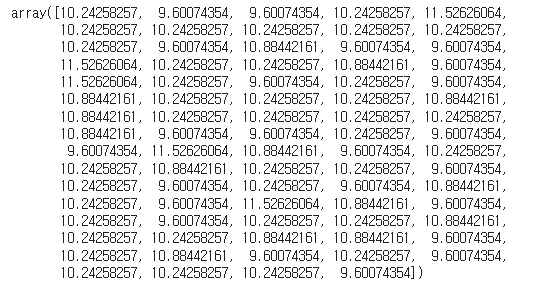
- 모델 평가(mse 출력),(실제값, 예측값)
error = mean_squared_error(y_test, pre)
print('linear_model_mse : ', error)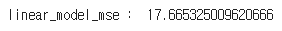
- 딥러닝 모델 설계하기

- tensorflow 도구 불러오기
from tensorflow.keras.models import Sequential # 뼈대
# 레고 시작 할 때 바닥의 큰 판이라고 생각하기! 기준이 있어야함!
from tensorflow.keras.layers import InputLayer, Dense, Activation
# 신경망 구성요소(조립)
# InputLayer : 입력층
# Dense : 중간층의 밀집도
# Activation : 활성화 함수(인간을 모방하기 위해서 사용하는 함수)- 신경망 구조 설계
# 뼈대 생성
model = Sequential()
# add 기능을 사용해서 층을 하나씩 더해나가보자!
# 입력층
model.add(InputLayer(input_shape = (1,))) # 입력특성의 개수 입력
# 중간층(은닉층)
model.add(Dense(units = 10)) # 뉴런 10개를 연결 → 학습능력을 결정
# Dense : 신경망의 핵심파트
model.add(Activation('sigmoid')) # 활성화 함수
# 출력층
model.add(Dense(units = 1)) # 출력되는 데이터의 형태 설계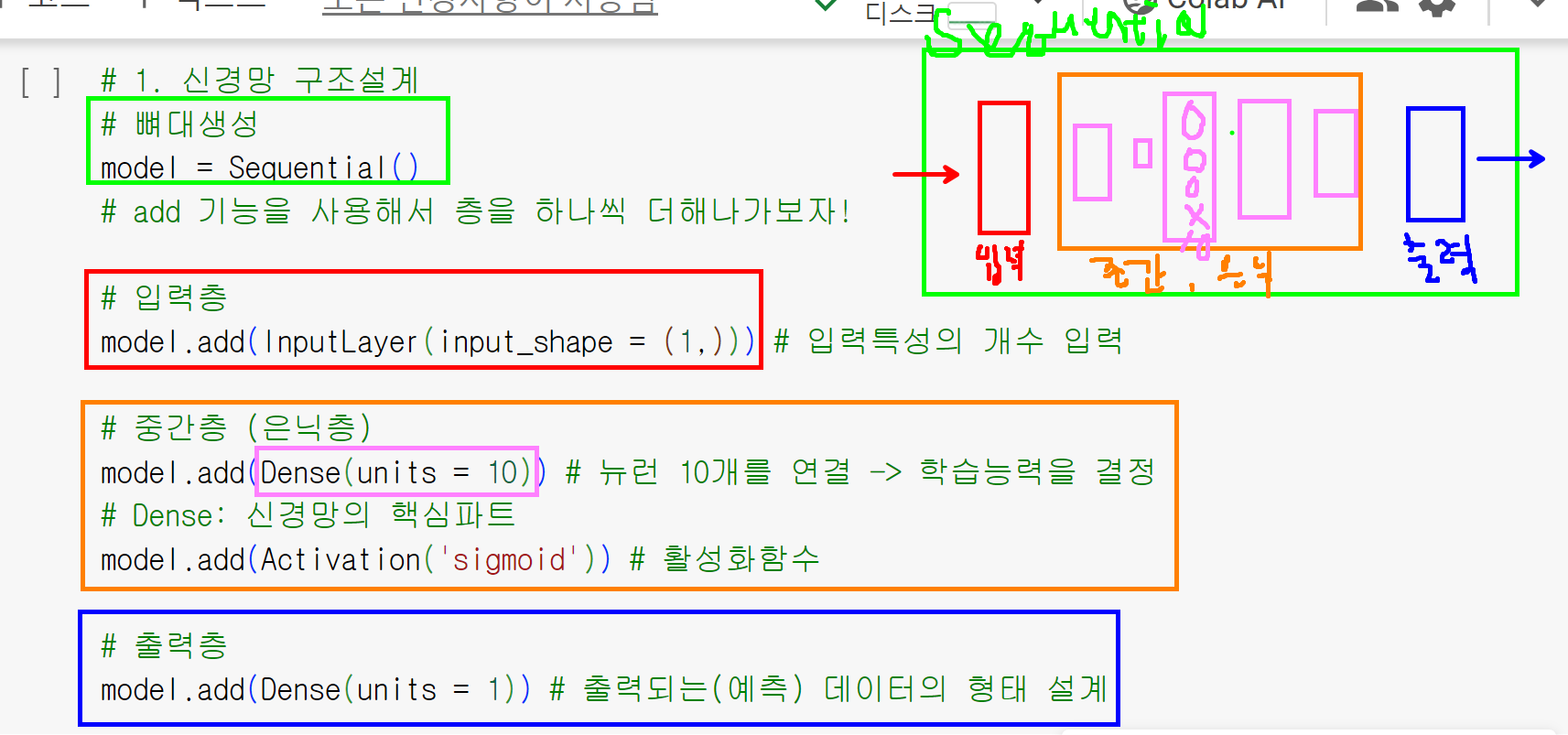
- 신경망 학습방법 및 평가방법 설정
model.compile(loss = 'mean_squared_error', # 모델의 잘못된 정도를 측정하는 알고리즘
optimizer = 'SGD', metrics = ['mse'])
# loss : 모델이 얼마나 틀렸는지 정도를 알려준다.
# 회귀모델은 mse, 분류모델은 crossentropy 사용
# optimizer : 최적화방법 → 경사하강법
# metrics : 최종 평가 방법(회귀 : mse)- 모델 학습
h1 = model.fit(X_train, y_train, validation_split=0.2, epochs=20)
# validation_split : 훈련데이터 내부에서 20%를 검증데이터로 사용하겠다.
# epochs : 모델의 최적화 횟수(w,b 값의 업데이트 횟수)
# h1에 담아주는 이유 : 학습 history 출력을 위함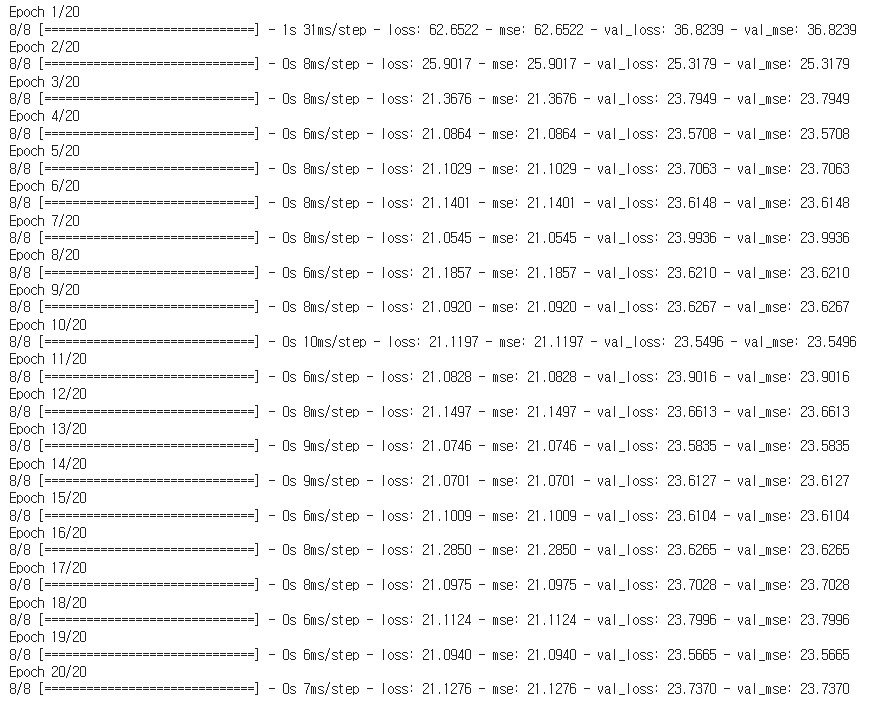
- 모델 평가
model.evaluate(X_test, y_test)
# 머신러닝에서 score와 같은 기능
→ 머신러닝과 별로 차이가 안난다.
그러면 머신러닝을 사용하는게 더 낫다.
시각화
- 매 회차마다의 오차(loss)값 시각화
h1.history['loss']
plt.figure(figsize = (10,5))
plt.plot(h1.history['loss'], label = 'train_loss')
plt.plot(h1.history['val_loss'], label = 'validation_loss')
plt.legend() # 범례
plt.show()
# 학습 epoch가 늘어날수록 loss 값이 떨어지는 것을 확인
# 과적합을 확인하기 위해서 검증데이터도 시각화
# train, validation 데이터 둘 다 오차가 줄어드는 것을 확인(일반화 가능성 있음)
# 일반화 확인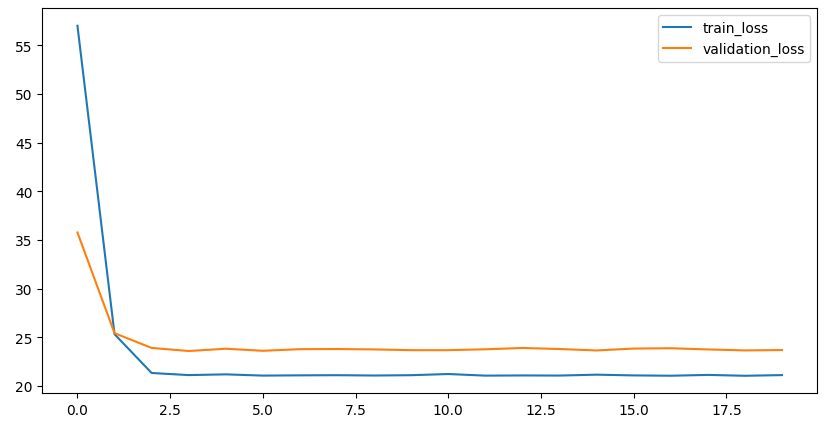
혼자해보기

- 4개의 특성을 골라 X(문제 데이터 만들어주기)
# 데이터를 살펴보기(숫자형태의 데이터, 결측치 없는지)
X = data[['age', 'traveltime', 'studytime', 'freetime']]
y = data['G3']- train, test 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=2024)- 확인하기
X_train.shape, X_test.shape, y_train.shape, y_test.shape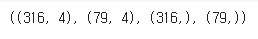
- 신경망 구조 설계
# 뼈대 생성
model = Sequential()
# 입력층
model.add(InputLayer(input_shape = (4,)))
# 중간층(은닉층)
model.add(Dense(units = 10))
model.add(Activation('sigmoid'))
# 출력층
model.add(Dense(units = 1))- 신경망 학습방법 및 평가방법 설정(compile)
# loss, optimizer, metrics
model.compile(loss = 'mean_squared_error',
optimizer = 'SGD', metrics = ['mse'])- 모델 학습
h2 = model.fit(X_train, y_train, validation_split=0.2, epochs=20)
- 모델 평가
model.evaluate(X_test, y_test)

노는게 제일 좋아~!