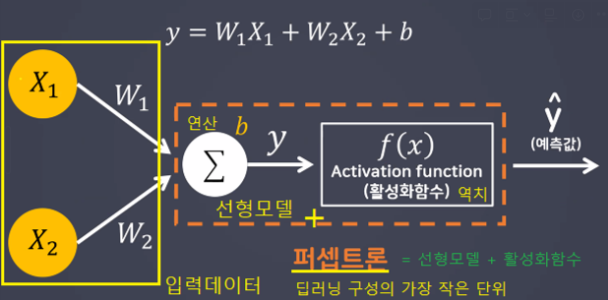
인공신경망 - 퍼셉트론(Perceptron)(선형모델 + 활성화 함수)
- 프랑크 로젠블라트가 1957년에 고안한 개념으로 초기형태의 인공신경망

-
인공신경망 구성요소 중 하나로 딥러닝 모델의 가장 작은 기본단위
-
뇌를 구성하는 신경세포인 뉴런의 동작과 유사하게 동작
→ 딥러닝 모델의 가장 작은 단위로 선형모델 + 활성화 함수
- 신경의 흥분이 전달되기 위해서는 뉴런에 전달되는 자극의 크기가 역치 이상이 되어야함
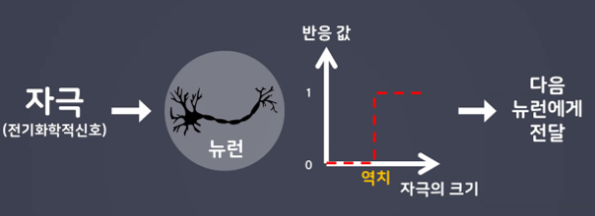

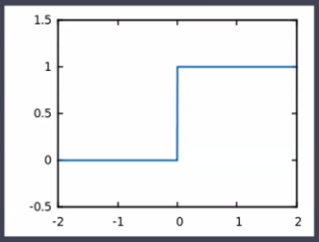
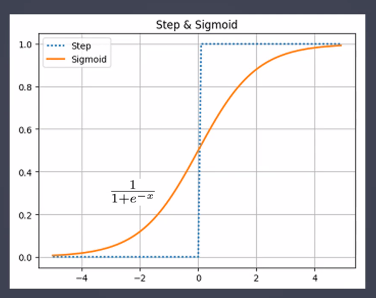
- Step function(계단함수)
인공신경망 - 다층 퍼셉트론(Multi Layer Perceptron)
- XOR 문제

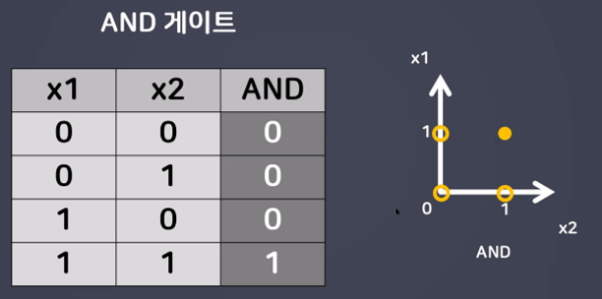
- AND 게이트
- OR 게이트
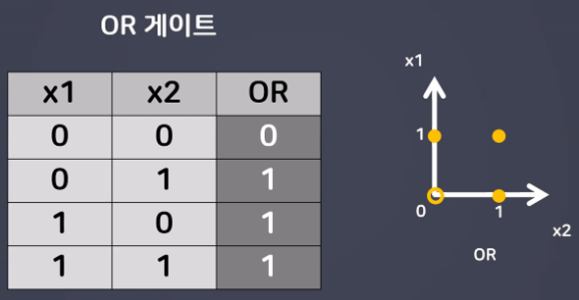
- XOR 게이트
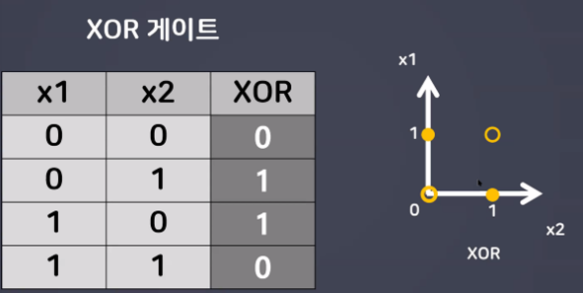
⇒ AND, OR는 해결이 가능하지만 간단한 XOR 문제를 해결 할 수 없었다…
- XOR 문제 해결(MLP)
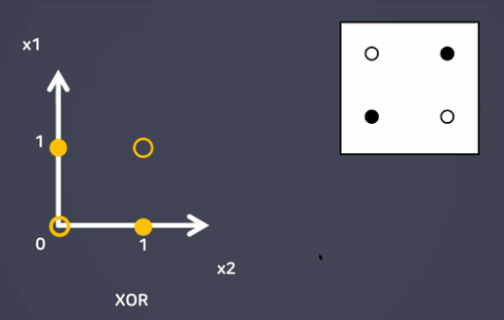
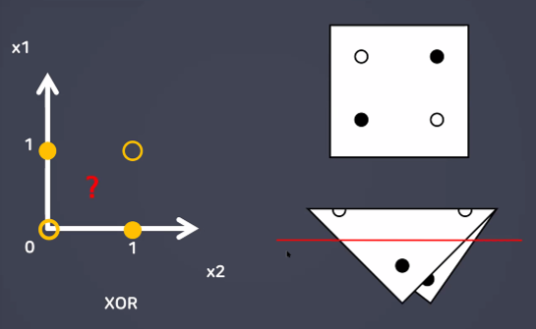 → 층을 다층으로 쌓게된다.
→ 층을 다층으로 쌓게된다.
- 다층 퍼셉트론(Multi Layer Perceptron)
퍼셉트론을 여러 개의 층으로 구성하여 만든 신경망
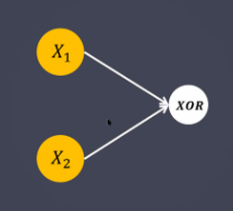
 → 하나의 층으로는 MLP를 해결 할 수가 없다.
→ 하나의 층으로는 MLP를 해결 할 수가 없다.
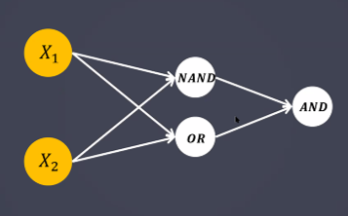 → 그래서 나온게 다층구조
→ 그래서 나온게 다층구조
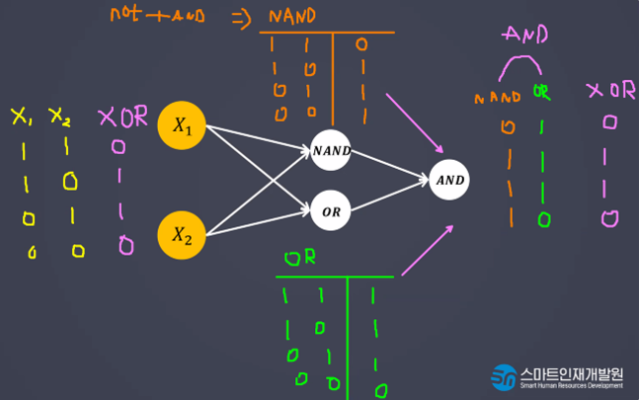
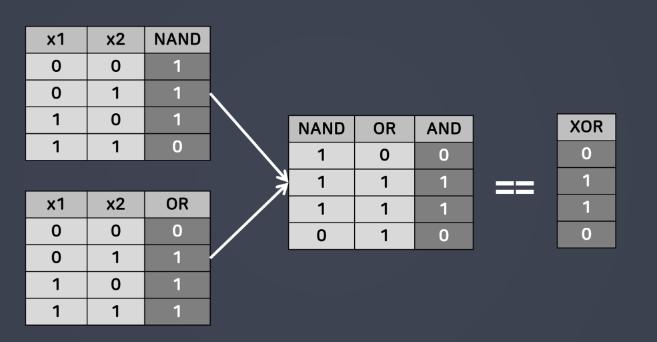
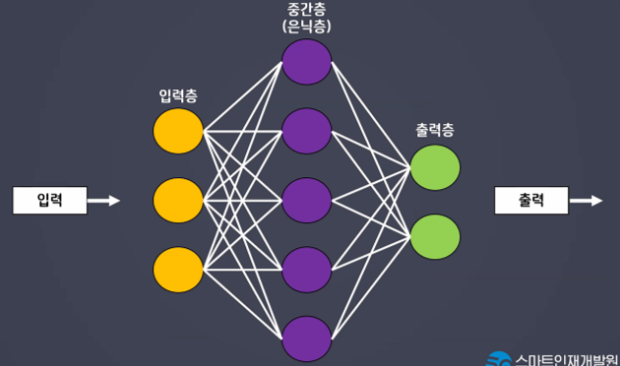
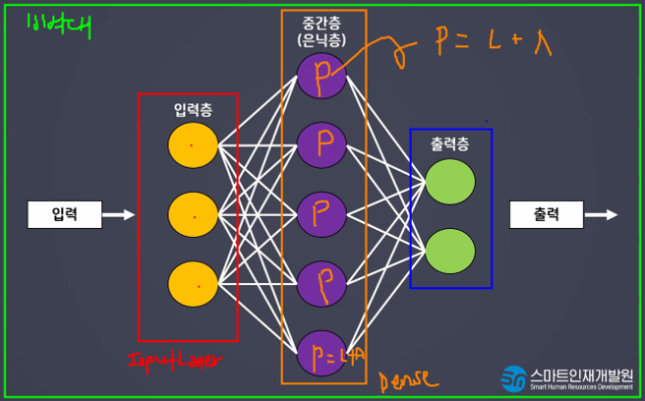
- 한 번의 연산으로 해결되지 않는 문제를 해결할 수 있다.
- 단층에 비해 학습시간이 오래 걸린다.
- 모델(신경망)이 복잡해지면서 학습시 과대적합되기 쉽다.
활성화 함수

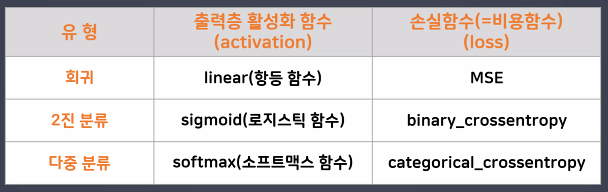
- 활성화 함수(Activation Function) 정리
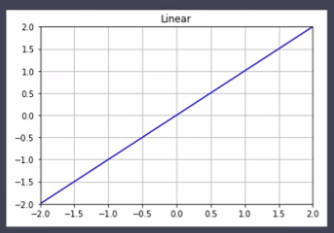
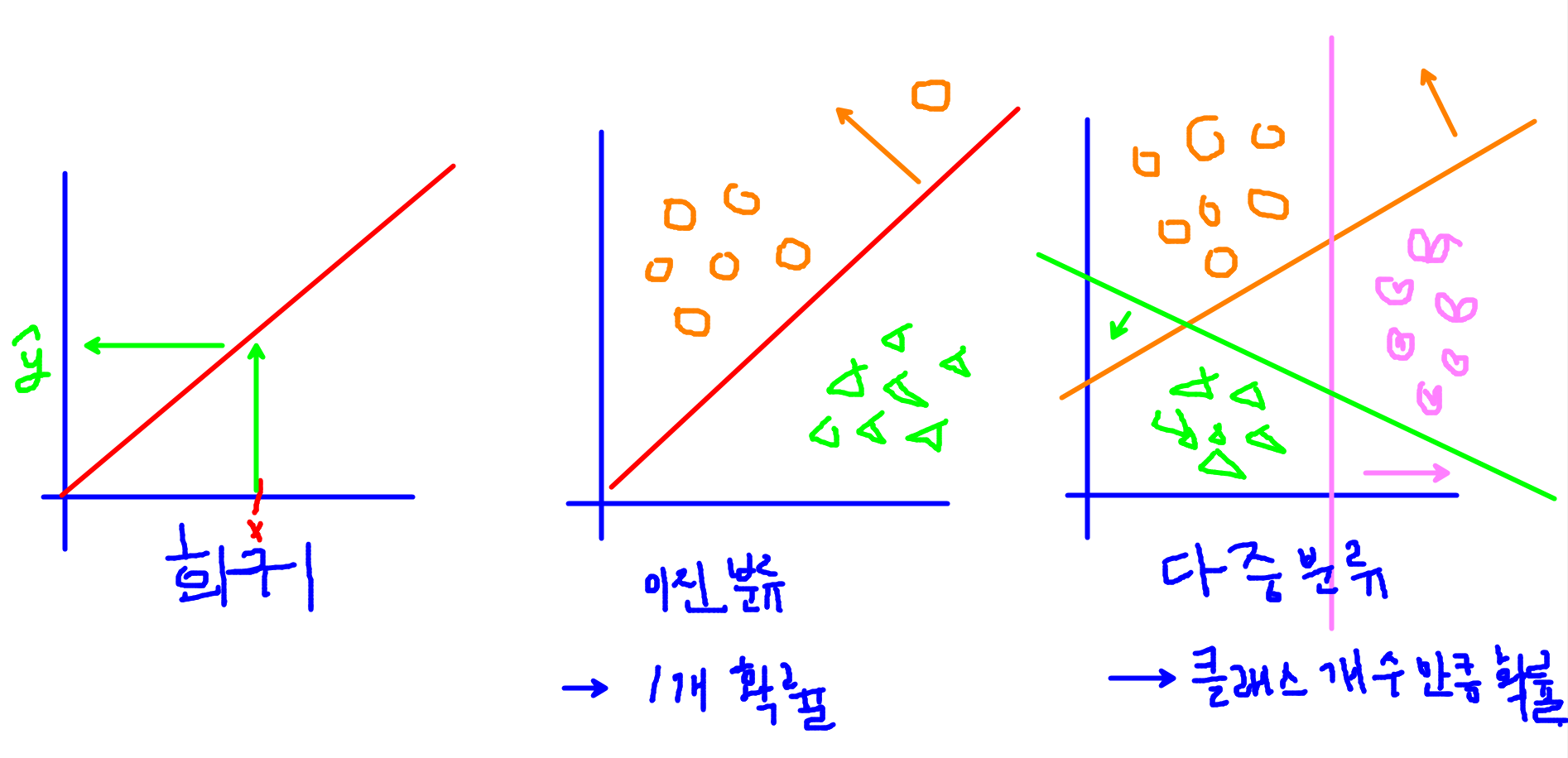
- Linear function(선형함수 = 항등함수) → 회귀
- Sigmoid 함수 → 이진분류
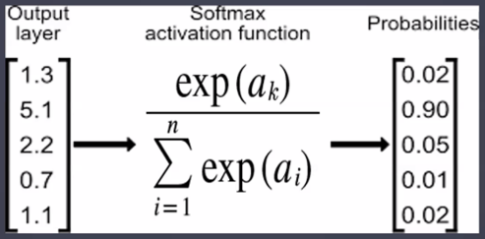
- 소프트맥스(softmax) 함수 → 다중분류
- 다중분류에서 레이블 값에 대한 각 퍼셉트론의 예측 확률의 합을 1로 설정
- sigmoid에 비해 예측 오차의 평균을 줄여주는 효과
- 문제 유형에 따른 활성화 함수와 손실함수의 종류
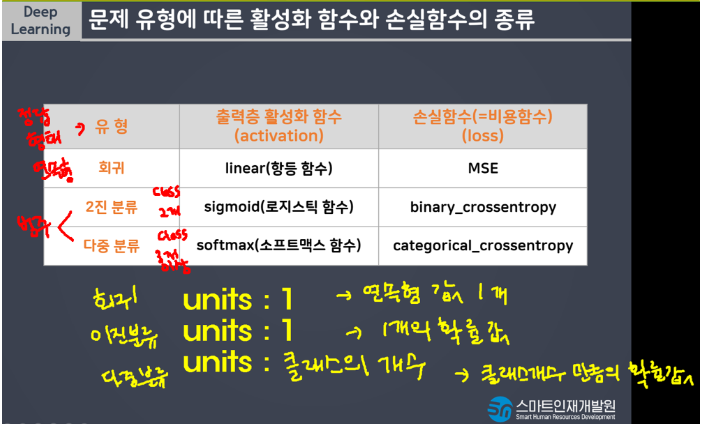
이진분류
실습

- 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer # 사이킷런 내장 유방암 데이터data = load_breast_cancer()
data
# 번치객체(사이킷런 데이터 타입 중 하나) → 딕셔너리 형태로서 딕셔너리처럼 사용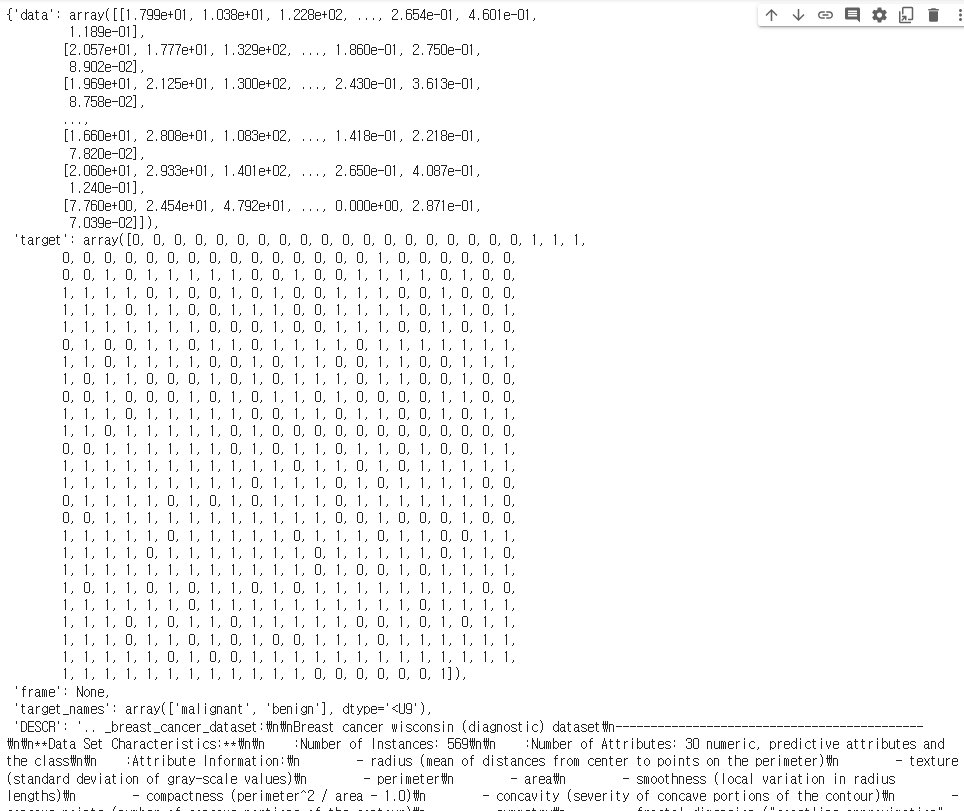
- 데이터 확인
data.keys()
# data : 문제 데이터, 입력특성
# target : 정답 데이터
# target_names : 정답 데이터의 이름
# feature_names : 특성의 이름(컬럼명)
# DESCR : 데이터 설명
print(data['DESCR'])


- 타겟 이름 확인(정답 데이터 이름 확인)
data['target_names']
# 클래스 2개 → 이진분류
# 0 - 'malignant' 악성, 1 - 'benign' 양성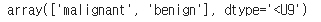
- 문제(X), 정답(y) 추출하기
X = data['data']
y = data['target']- train, test로 분리(75:25 비율로 분리, 랜덤 고정수 104)
from sklearn.model_selection import train_test_split
X_train, y_train, X_test, y_test = train_test_split(X, y, test_size=0.25, random_state=104)- 데이터 크기 확인
X_train.shape, y_train.shape, X_test.shape, y_test.shape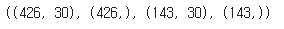

- 도구 불러오기
from tensorflow.keras import Sequential # 뼈대
from tensorflow.keras.layers import InputLayer, Dense- 모델 구조 설계
# 뼈대
model = Sequential()
# 입력층
model.add(InputLayer(input_shape = (30,))) # 입력특성의 개수를 정확하게 입력
# 중간층(다층구조) 1번째 층 16개 뉴런, 2번째 층 8개 뉴런
model.add(Dense(units = 16, activation = 'sigmoid')) # 활성화함수를 함께 작성 가능
model.add(Dense(units = 8, activation = 'sigmoid'))
# 출력층 : 출력하고자하는 데이터의 형태를 지정
model.add(Dense(units = 1, activation = 'sigmoid'))
# 이진분류에서는 출력층에 왜 1개의 선형을 더해줬을까?
# 분류는 확률값을 출력받는데 양성인지 아닌지에 대한 확률값을 출력 받아야한다.
# 이진분류이기 때문에 1개의 확률값만 필요로 함(0~1)- 모델 학습방법 및 평가방법 설정
# 이진분류에 맞도록 변경
model.compile(loss = 'binary_crossentropy', # 오차 : 이진분류 > binary_crossentropy
optimizer = 'SGD', # 최적화 방법(경사하강법)
metrics = ['accuracy']) # 평가방법(분류 : 정확도/accuracy)- 모델 학습
h1 = model.fit(X_train, y_train, validation_split=0.2, epochs=100)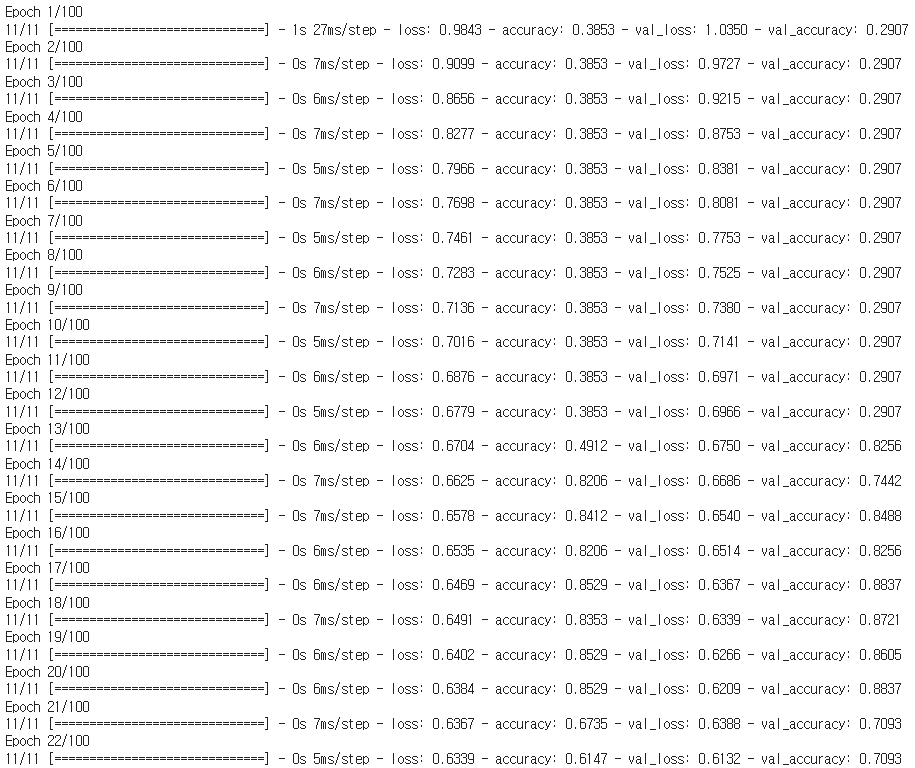
- 모델 평가
model.evaluate(X_test, y_test)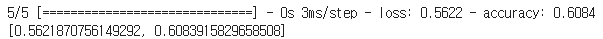
h1.history['loss']
시각화
plt.figure(figsize = (15,5))
plt.plot(h1.history['loss'], label = 'train_loss')
plt.plot(h1.history['val_loss'], label = 'validation_loss')
plt.legend() # 범례
plt.show()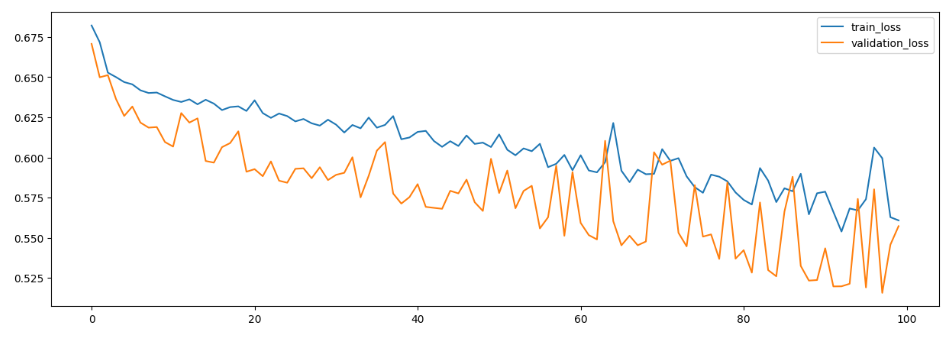
- 모델에 대한 전체적인 내부 구조 확인
model.summary()
# Layer 파라미터 확인 가능!
# 총 3개의 층으로 구성되어있는 모델임을 확인할 수 있다.
# 중간층 2개, 출력층 1개
# 첫 번째 레이어 통과 후 16개의 데이터를 출력
# 두 번째 레이어 통과 후 8개의 데이터를 출력
다중분류
실습

- 기본 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
- keras에서 제공해주는 손글씨 데이터 불러오기
from tensorflow.keras.datasets import mnist# 내부적으로 훈련용 데이터, 테스트용 데이터로 구분해서 담겨있음
# 문제와 정답도 나뉘어있음
(X_train, y_train), (X_test, y_test) = mnist.load_data()
- 데이터 크기 확인
X_train.shape, y_train.shape, X_test.shape, y_test.shape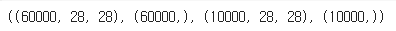
- 데이터 확인
# 훈련용 데이터 6만장, 테스트용 데이터 1만장
# 28 * 28 픽셀을 가지는 데이터
# 픽셀 : 사진의 정보를 가지는 단위- 분류, 회귀? → 정답 데이터 확인
# 중복되지 않는 유일한 값 출력
np.unique(y_train)
# 10개의 클래스를 가지는 다중분류
# 0~9까지의 손글씨 데이터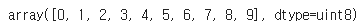
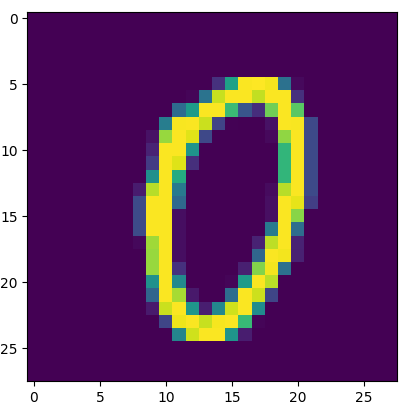
- 손글씨 데이터 확인
plt.imshow(X_train[1000])
X_train[1000]
# 흑백사진 데이터 : 얼마나 검정색인지 정도를 숫자로 가짐(0~255)
# 0(가까울수록) : 검정색, 255(가까울수록) : 흰색
# matplotlib에서 기본 색상 팔레트가 노란색, 흑백으로 바꿔주고 싶으면 cmap 속성 변경
plt.imshow(X_train[1000], cmap='gray')
# X_train[1000]
# 흑백사진 데이터 : 얼마나 검정색인지 정도를 숫자로 가짐(0~255)
# 0(가까울수록) : 검정색, 255(가까울수록) : 흰색
# matplotlib에서 기본 색상 팔레트가 노란색, 흑백으로 바꿔주고 싶으면 cmap 속성 변경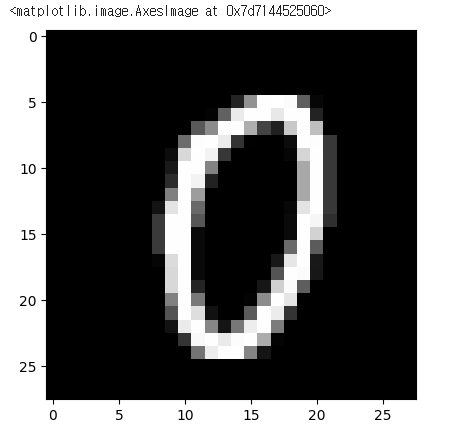

- 라이브러리 불러오기
from tensorflow.keras import Sequential # 뼈대 클래스
# Layer 불러오기
from tensorflow.keras.layers import Dense, InputLayer, Flatten
# Flatten : 2차원의 사진데이터(28 * 28)를 1차원으로 표현해주기 위한 클래스
# 선형 모델 분석을 위해 1차원으로 변경해주어야 한다.- 신경망 모델 설계
# 뼈대
model = Sequential()
# 입력층 (28 * 28)
model.add(InputLayer(input_shape = (28, 28))) # 행, 열
# 중간층(은닉층) 첫 번째층 16개, 두 번째층 8개
model.add(Flatten()) # 입력받은 2차원의 사진데이터를 1차원으로 변경(선형 모델 분석을 위함)
model.add(Dense(units = 16, activation = 'sigmoid'))
model.add(Dense(units = 8, activation = 'sigmoid'))
# 출력층(다중분류 → 클래스 10개)
model.add(Dense(units = 10, activation = 'softmax'))
# 다중분류 : 클래스의 개수만큼의 확률값을 필요로한다.
# 0번 손글씨일 확률 ~ 9번 손글씨일 확률까지 총 10개의 확률값이 출력되어야 한다!
# 다중분류의 활성화함수 : softmax(클래스 개수만큼의 확률값을 총합 1로 변환해주는 함수)
# 그 중 가장 높은 확률의 클래스를 정답 데이터로 예측해나가는 원리~- 모델 학습방법 및 평가방법 설정
model.compile(loss = 'categorical_crossentropy', # 다중분류 : categorical_crossentropy
optimizer = 'SGD',
metrics = ['accuracy'])- 모델 학습
model.fit(X_train, y_train,
validation_split=0.2,
epochs = 20)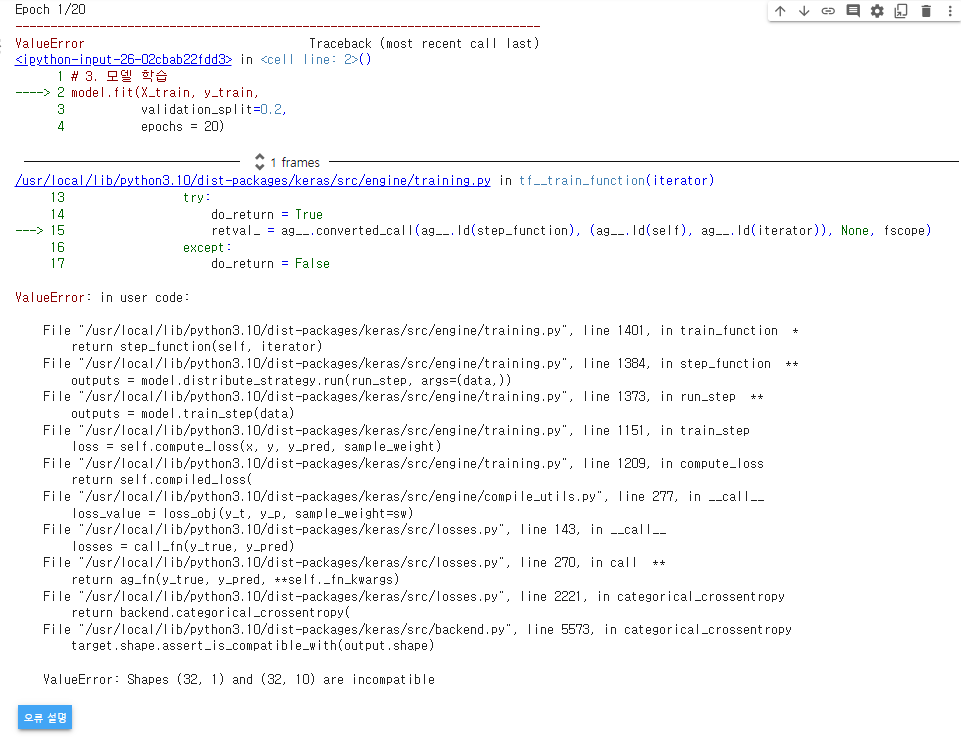
→ 문제 발생!
- 오류확인 → 정답 데이터의 shape가 일치하지 않음!
- 학습시 y_train 형태를 보니 실제 데이터 1개(클래스 중 1개 값)
- 모델링 출력 결과는 : 10개 클래스에 대한 각각의 확률값
- 1개와 10개는 비교가 불가능
- 개수 및 형태를 맞춰주자!
- 오류를 해결할 수 있는 2가지 방법
- [방법1] 정답 데이터(y_train)의 형태를 10개의 확률값으로 변경
- [방법2] complie 진행 시 loss 값을 'categorical_crossentropy' → 'sparse_categorical_crossentropy' 로 변경
(keras에서 지원하는 자동으로 정답 데이터를 알아서 확률로 계산할 수 있도록 해줌)
[방법1. 정답 데이터를 확률값으로 변경하기]
from tensorflow.keras.utils import to_categorical
# 범주형 데이터(정답) 확률값으로 변경해주는 역할
y_train_onehot = to_categorical(y_train)
y_train_onehot[1]
# 마치 원핫인코딩을 하듯이 확률값으로 변경해준다.
# 5일 확률 100%, 나머지 0%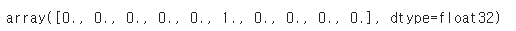
- 문제 해결 후 재학습
model.fit(X_train, y_train_onehot,
validation_split=0.2,
epochs = 20)
[방법2. loss 함수를 sparse_categorical_crossentropy로 변경]
# 1. 신경망 모델 설계
# 뼈대
model = Sequential()
# 입력층 (28 * 28)
model.add(InputLayer(input_shape = (28, 28))) # 행, 열
# 중간층(은닉층) 첫 번째층 16개, 두 번째층 8개
model.add(Flatten()) # 입력받은 2차원의 사진데이터를 1차원으로 변경(선형 모델 분석을 위함)
model.add(Dense(units = 16, activation = 'sigmoid'))
model.add(Dense(units = 8, activation = 'sigmoid'))
# 출력층(다중분류 → 클래스 10개)
model.add(Dense(units = 10, activation = 'softmax'))
# 학습방법 및 평가방법 설정
model.compile(loss = 'sparse_categorical_crossentropy',
optimizer = 'SGD',
metrics = ['accuracy'])
# 스스로 내부에서 범주값을 확률값으로 변경하여 오차를 계산한다.- 이걸 추가
# 학습방법 및 평가방법 설정
model.compile(loss = 'sparse_categorical_crossentropy',
optimizer = 'SGD',
metrics = ['accuracy'])
# 스스로 내부에서 범주값을 확률값으로 변경하여 오차를 계산한다.- 학습
h1 = model.fit(X_train, y_train,
validation_split = 0.2,
epochs = 20)
- 시각화
plt.figure(figsize = (15,5))
plt.plot(h1.history['loss'], label = 'train_loss')
plt.plot(h1.history['val_loss'], label = 'validation_loss')
plt.legend() # 범례
plt.show()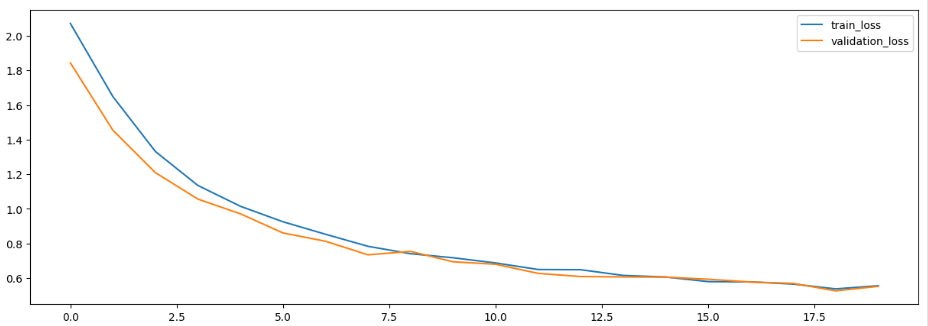
- 모델 평가
model.evaluate(X_test, y_test)
# 정확도 : 약 87%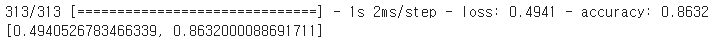
활성화 함수(Relu) 사용해보기
# 1. 신경망 모델 설계
# 뼈대
model = Sequential()
# 입력층 (28 * 28)
model.add(InputLayer(input_shape = (28, 28))) # 행, 열
# 중간층(은닉층)
model.add(Flatten()) # 입력받은 2차원의 사진데이터를 1차원으로 변경(선형 모델 분석을 위함)
model.add(Dense(units = 64, activation = 'sigmoid'))
model.add(Dense(units = 128, activation = 'sigmoid'))
model.add(Dense(units = 256, activation = 'sigmoid'))
model.add(Dense(units = 256, activation = 'sigmoid'))
model.add(Dense(units = 128, activation = 'sigmoid'))
model.add(Dense(units = 64, activation = 'sigmoid'))
# 출력층
model.add(Dense(units = 10, activation = 'softmax'))
# 학습 방법 및 평가 방법 설정
model.compile(loss = 'sparse_categorical_crossentropy',
optimizer = 'SGD',
metrics = ['accuracy'])
# 학습
h1 = model.fit(X_train, y_train,
validation_split = 0.2,
epochs = 20)
# 평가
model.evaluate(X_test, y_test)
# 가설 : 층을 깊게 쌓으면 모델 성능이 좋아질것이다!
# 결과 : 층을 깊게 쌓았더니 성능이 더 떨어진 것을 확인
# 이유 : sigmoid 함수를 활성화함수로 사용하면서 층을 깊게 쌓았을 때 기울기 소실 문제가 발생!
# 해결 : 중간층의 활성화함수를 Relu로 변경!
노는게 제일 좋아~!