이 사이트에서

이거 다운로드 받기
다운 받아서 마지막에 체크 하는 부분에서 맨 아래 language 체크하고 넥스타하고 install 하고 finish
- 파일 경로 찾기
C:\Program Files\Tesseract-OCR
여기 안에

이게 있어야 함
# OCR(Optical Character Recongnition) : 광학 문자 인식
# 이미지에서 글자 찾기
# 문자 찾아내기 → 영영 속에서 문자 인식하기# tesseract : 1980년대 최초로 개발된 OCR 알고리즘 중 하나
## 빠르지만 성능이 별로다
## 외부 라이브러리
# EasyOCR : 간단하고 직관적인 OCR 알고리즘
## 결과를 bbox 좌표로 반환
## 파이썬 라이브러리
# PaddleOCR
## 텍스트 감지, 텍스트 방향 분류기 등 텍스트 인식 기능 제공
## 외부 라이브러리 → 환경설정이 필요함
# 구글 OCR API : https://cloud.google.com/vision/docs/quickstart
# Naver 클로버 OCR : https://clova.ai/ocr?lang=ko- install
!pip install pytesseract
import pytesseract
# r : 뒤에 오는 문자열을 그대로 기억
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract.exe"-r 빼고 print
print("C:\Program Files\Tesseract-OCR\tesseract.exe")
-r 넣고 print
print(r"C:\Program Files\Tesseract-OCR\tesseract.exe")
→ tap키 차이
- 이미지1

import cv2
img = cv2.imread('./data/text.png')
text = pytesseract.image_to_string(img, lang = 'eng')
print(text)- 결과

- 인식이 잘되는 조건
# 1. 가지런한 방향
# 2. 글씨와 배경의 뚜렷한 차이
# 3. 큰 글씨
# 사용자 : 사진의 형태를 제한시켜서 데이터를 받게하기
# 관리자
## 방향을 가지런하게 한다.
## 글씨와 배경의 차이를 만든다.
## 글씨를 키운다.- 이미지2

import cv2
img = cv2.imread('./data/story.png')
text = pytesseract.image_to_string(img, lang = 'kor')
print(text)
- 이미지3
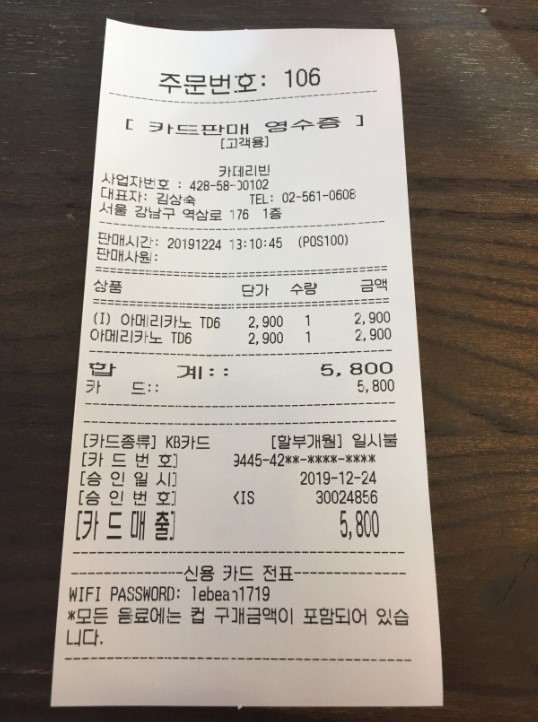
import cv2
img = cv2.imread('./data/ocr1.jpg')
text = pytesseract.image_to_string(img, lang = 'kor')
print(text)
→ 값을 가져올 수가 없다.
- 이미지 인식하기
import cv2
img = cv2.imread('./data/ocr1.jpg')
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 흑백으로 만들기
# 2. 글씨와 배경의 뚜렷한 차이
# 흑백으로 만들기
import cv2
img = cv2.imread('./data/ocr1.jpg')
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv2.imshow('img', img)
cv2.imshow('img_gray', img_gray)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 이진화
# 2. 글씨와 배경의 뚜렷한 차이
# 흑백으로 만들기
import cv2
img = cv2.imread('./data/ocr1.jpg')
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_, img_binary = cv2.threshold(img_gray, 150, 255, cv2.THRESH_BINARY)
cv2.imshow('img', img)
cv2.imshow('img_gray', img_gray)
cv2.imshow('img_binary', img_binary)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 이진화 하고 나서 출력
# 2. 글씨와 배경의 뚜렷한 차이
# 흑백으로 만들기
import cv2
img = cv2.imread('./data/ocr1.jpg')
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_, img_binary = cv2.threshold(img_gray, 150, 255, cv2.THRESH_BINARY)
text = pytesseract.image_to_string(img_binary, lang = 'kor')
cv2.imshow('img', img)
cv2.imshow('img_gray', img_gray)
cv2.imshow('img_binary', img_binary)
cv2.waitKey(0)
cv2.destroyAllWindows()
print(text)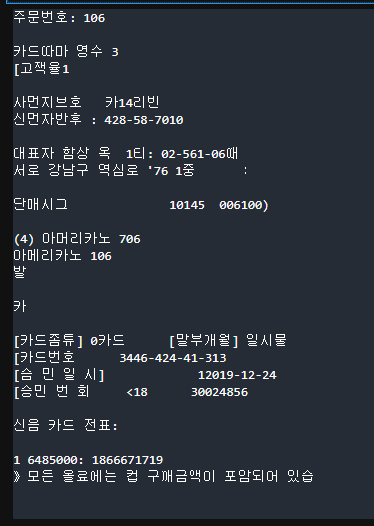
- 이진화 업그레이드
# 이진화 업그레이드
import cv2
img = cv2.imread('./data/sudoku.png')
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_, img_binary = cv2.threshold(img_gray, 127, 255, cv2.THRESH_BINARY)
cv2.imshow('img', img)
cv2.imshow('img_gray', img_gray)
cv2.imshow('img_binary', img_binary)
cv2.waitKey(0)
cv2.destroyAllWindows()
- 이진화 업그레이드
# 이진화 업그레이드 = 적응형 이진화 방법
# 빛에 의해서 이미지의 값이 균일하지 않을 때 사용하는 방법
# 영역을 나눠서 영역별로 이진화를 진행 → 문턱값(임계값)을 알아서 계산
import cv2
img = cv2.imread('./data/sudoku.png')
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_, img_binary = cv2.threshold(img_gray, 127, 255, cv2.THRESH_BINARY)
binary = cv2.adaptiveThreshold(img_gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
# 이진화의 정도
cv2.THRESH_BINARY, 9, 5)
cv2.imshow('img', img)
cv2.imshow('img_gray', img_gray)
cv2.imshow('img_binary', img_binary)
cv2.imshow('binary', binary)
cv2.waitKey(0)
cv2.destroyAllWindows()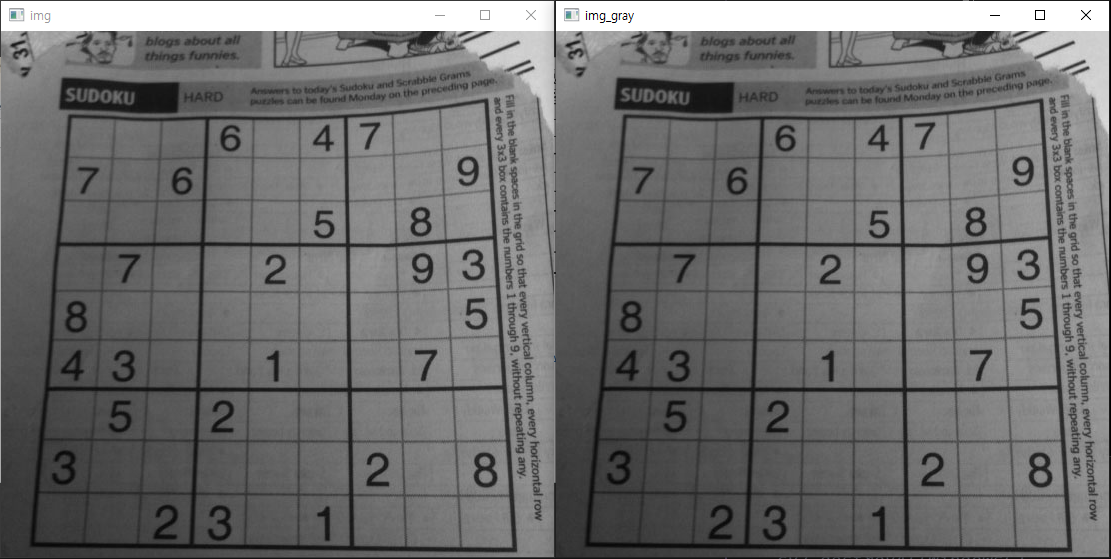

# 카메라에 사각형 담기
# 사각형 영역 안에 들어왔을 때 캡쳐하기
# 캡쳐된 이미지에서 사각형 영역 안에 있는 값만 가져오기import cv2
video = cv2.VideoCapture(0)
while video.isOpened() :
ret, img = video.read()
if not ret :
break
k = cv2.waitKey(30)
if k == 49 :
break
cv2.imshow('img', img)
video.release()
cv2.destroyAllWindows()- 중앙을 제외한 영역을 blur 처리
import cv2
video = cv2.VideoCapture(0)
while video.isOpened() :
ret, img = video.read()
if not ret :
break
w = img.shape[1]
h = img.shape[0]
img = cv2.flip(img, 1)
# 사각형 안쪽 영역의 값
tmp = img[int(h/6) :int(h/6*5),int(w/3): int(w/3*2)]
# 이미지 전체 blur 처리
img = cv2.blur(img, (20,20))
k = cv2.waitKey(30)
if k == 49 :
break
cv2.imshow('img', img)
video.release()
cv2.destroyAllWindows()
import cv2
video = cv2.VideoCapture(0)
while video.isOpened() :
ret, img = video.read()
if not ret :
break
w = img.shape[1]
h = img.shape[0]
img = cv2.flip(img, 1)
# 사각형 안쪽 영역의 값
tmp = img[int(h/6) :int(h/6*5),int(w/3): int(w/3*2)]
# 이미지 전체 blur 처리
img = cv2.blur(img, (20,20))
# 중앙 영역에 blur 처리되기 전 값 집어넣기
img[int(h/6) :int(h/6*5),int(w/3): int(w/3*2)] = tmp
k = cv2.waitKey(30)
if k == 49 :
break
cv2.imshow('img', img)
video.release()
cv2.destroyAllWindows()
- blur 영역 테두리 표시하기
import cv2
video = cv2.VideoCapture(0)
while video.isOpened() :
ret, img = video.read()
if not ret :
break
w = img.shape[1]
h = img.shape[0]
img = cv2.flip(img, 1)
# 사각형 안쪽 영역의 값
tmp = img[int(h/6) :int(h/6*5),int(w/3): int(w/3*2)]
# 이미지 전체 blur 처리
img = cv2.blur(img, (20,20))
# 중앙 영역에 blur 처리되기 전 값 집어넣기
img[int(h/6) :int(h/6*5),int(w/3): int(w/3*2)] = tmp
# blur 영역 테두리 표시하기
cv2.rectangle(img, (int(w/3), int(h/6)), # 좌상단
(int(w/3*2), int(h/6*5)), # 우하단
(255, 255, 255), 2) # 색상, 두께
k = cv2.waitKey(30)
if k == 49 :
break
cv2.imshow('img', img)
video.release()
cv2.destroyAllWindows()
- 영역 안에서 인식하기
import cv2
import numpy as np
video = cv2.VideoCapture(0)
while video.isOpened() :
ret, img = video.read()
if not ret :
break
w = img.shape[1]
h = img.shape[0]
# img = cv2.flip(img, 1)
# 사각형 안쪽 영역의 값
tmp = img[int(h/6) :int(h/6*5),int(w/3): int(w/3*2)]
# 이미지 전체 blur 처리
img = cv2.blur(img, (20,20))
# 중앙 영역에 blur 처리되기 전 값 집어넣기
img[int(h/6) :int(h/6*5),int(w/3): int(w/3*2)] = tmp
# blur 영역 테두리 표시하기
cv2.rectangle(img, (int(w/3), int(h/6)), # 좌상단
(int(w/3*2), int(h/6*5)), # 우하단
(255, 255, 255), 2) # 색상, 두께
k = cv2.waitKey(30)
if k == 49 :
break
elif k == 50 :
# 1. 영역 안에 있는 값을 사용해서 OCR 하기
# 이진화를 하기 위해서 흑백으로 변환하기
gray = cv2.cvtColor(tmp, cv2.COLOR_BGR2GRAY)
# 적응형 이진화 하기
binary = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
# 이진화의 정도
cv2.THRESH_BINARY, 9, 5)
kernel = np.ones((2,2), np.uint8)
# 흰 부분 팽창 → 검은 노이즈 부분 줄이기 → 글씨 굵기가 줄어듦
dilation = cv2.dilate(binary, kernel, iterations = 1)
# 흰 부분 침식 → 검은 글씨가 굵어짐
erosion = cv2.erode(dilation, kernel, iterations = 2)
text = pytesseract.image_to_string(close, lang = 'kor')
print(text)
# 2. 원하는 값(이름)이 있으면 카메라 종료하기
if '안녕' in text :
break
cv2.imshow('img', img)
video.release()
cv2.destroyAllWindows()
 → 인식이 잘 안됨
→ 인식이 잘 안됨

노는게 제일 좋아~!